吴裕雄--天生自然HADOOP操作实验学习笔记:hbase学生选课案例
实验目的
复习hbase的shell操作和javaAPI操作
了解javaWeb项目的MVC设计
学会dao(数据库访问对象)和service层的代码编写规范
学会设计hbase表格
实验原理
前面我们已经了解hbase的shell操作、javaAPI操作,并且能够使用hive操作hbase表格(实际上是转化为mapreduce操作),本次实验我们就是利用hbase实现一个简单的学生选课案例。实现学生选课首先是要学会设计表格,然后根据设计的表格进行各种逻辑实现。
1.设计表格
hbase表格设计需要注意,由于hbase查询只能通过rowkey或者rowkey的范围,不适用其他工具的条件下不能通过其他的方式查询,所以我们最后查询的效率全都取决于rowkey的设计。所以说一开始我们就需要将rowkey设计的比较完美,但是我们最后还是很难完全满足业务的需要,这时候可能需要配合搜索引擎进行操作(具体内容大家可以参见Lucene、solr、elastic search的内容)。我们今天要实现选课的案例,首先需要学生表、课程表。这两个表格的设计除了rowkey以外还需要再加一个info的列族,里面具体的列就是各种信息。剩下的部分就是学生和课程的关系,一个学生可以选择很多个课程,一个课程也可以被很多学生选择,所以我们可以设计一个中间表来保存学生选课信息,但是这样有一个问题,中间表的rowkey怎么设计,如果中间表的rowkey通过两个的rowkey组合,后续我们需要查询选择了某一个课程的所有学生,或者某一个学生所有的课程,总会有一个不方便。我们可以通过在学生表加一个列族记录选课,同时在课程表加一个列族记录选课的学生,这个列族的每一列的列名直接和列值取一样的。例如学生选择了一个课程,我们就在学生的课程列族下添加一个列,列名和值都为课程id,同时在课程的选课列族下添加一列,列名和值都为学生id。可能你会觉得这样的设计不符合关系型数据库的设计规范,因为数据重复了,但是我们在hbase表格设计的时候,查询效率才是第一个应当考虑的。
最后设计的表格有两个:学生表两个列族,分别为学生信息和选课信息,课程表有两个列族,分别为课程信息和选课学生。
2.业务逻辑
表格设计好了我们会创建表格,我们需要设计好业务逻辑对应的表格操作。
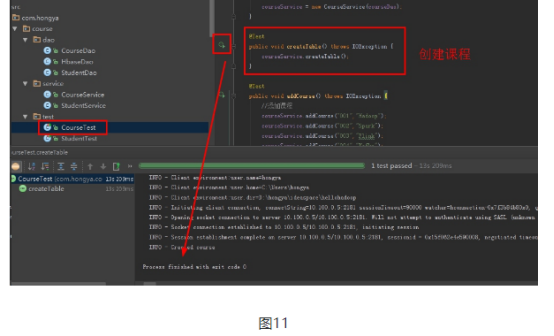
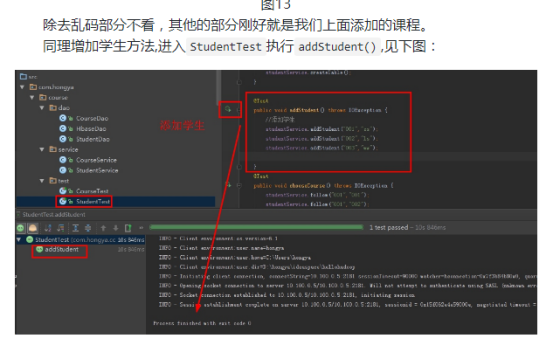
第一,添加选课信息和学生等。插入数据的操作一般是在业务的管理员负责,可以通过hbase的shell直接完成,也可以通过javaAPI完成。另外学生的密码的信息会保存在关系型数据库里面,登陆等操作一般会通过连接mysql等数据库完成。
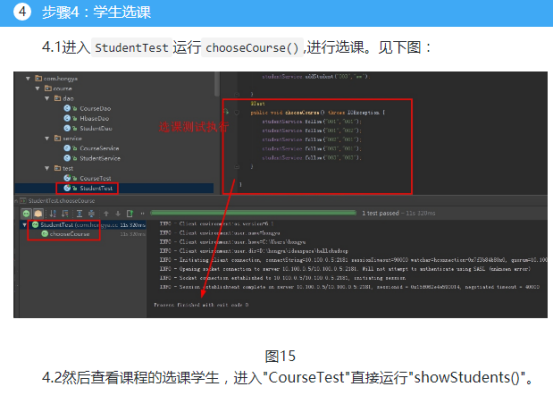
第二,删除课程和选课。选课的时候我们需要学生id添加到课程的学生列族里,同时需要将课程添加到学生的课程列族里。删除课程的逻辑类似,两边都要删除。
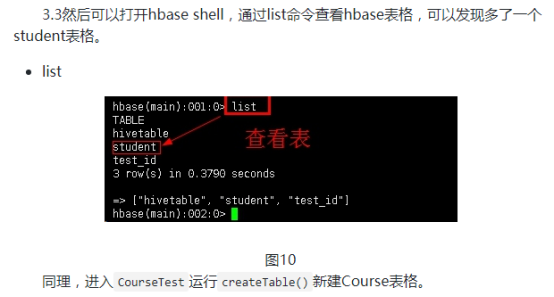
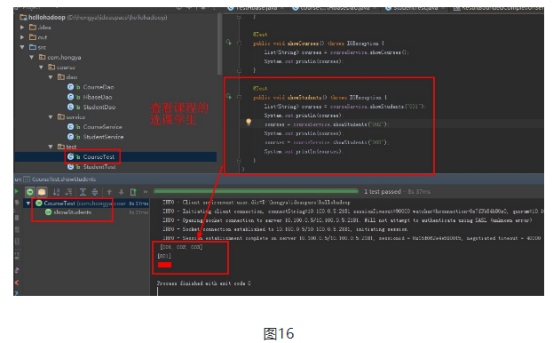
第三,查询选课信息。无论是学生的选课信息查询还是课程的选课学生都直接通过扫描列族就能得到。
3.dao层的实现
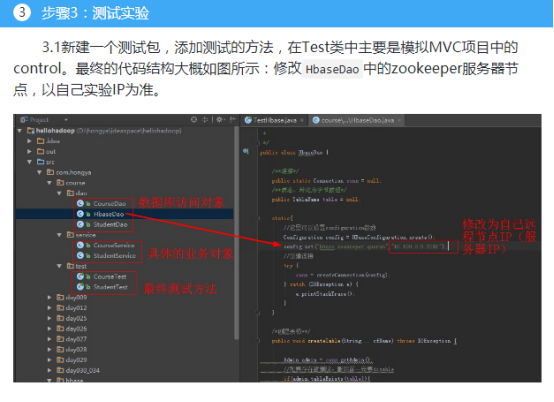
本次实验的代码放在hellohadoop的com.hongya的course下。熟悉javaweb开发的同学应该比较清楚dao层的开发方法,本次实验我们先开发几个最常见的功能。
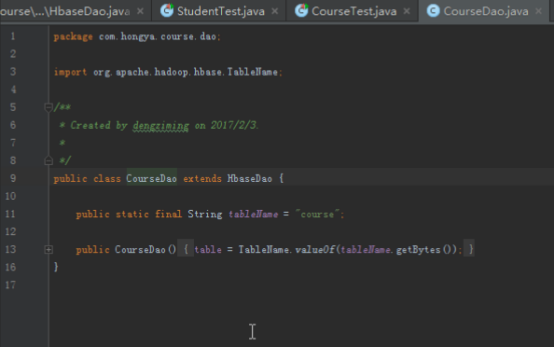
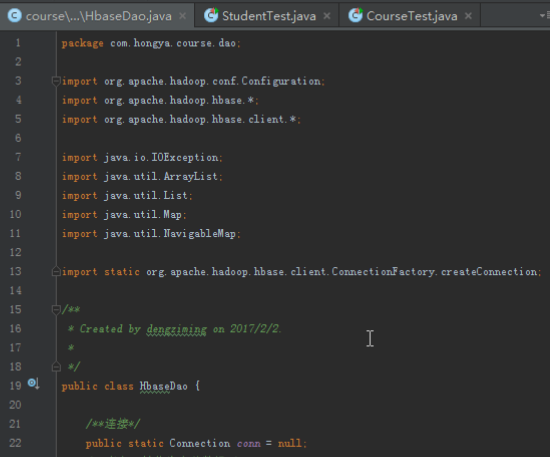
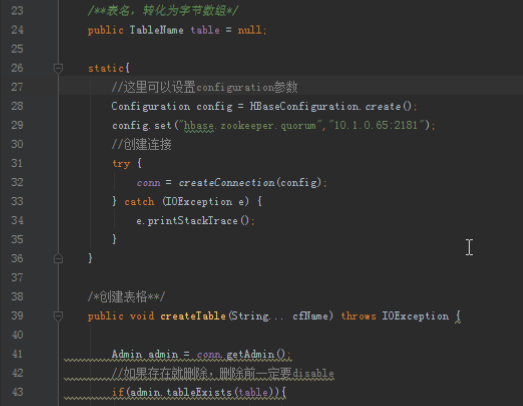
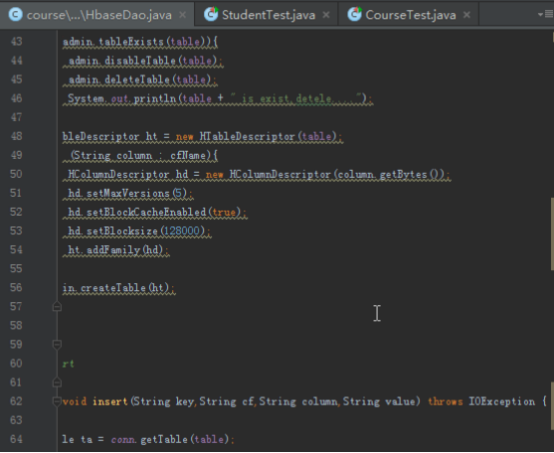
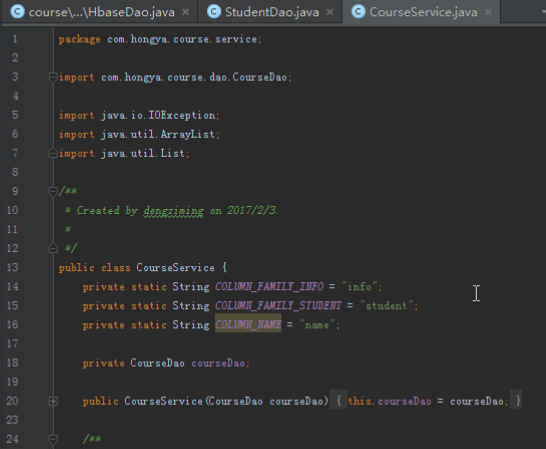
HbaseDao类可以作为一个公共的Dao父类,需要有获得连接的方法,还要有创建、删除表格,根据业务的实际情况,还需要添加增删改查的具体方法。最后HbaseDao类大概如下:
public class HbaseDao {
static{
conn = createConnection(config);
}
/*创建表格**/
public void createTable(String... cfName)
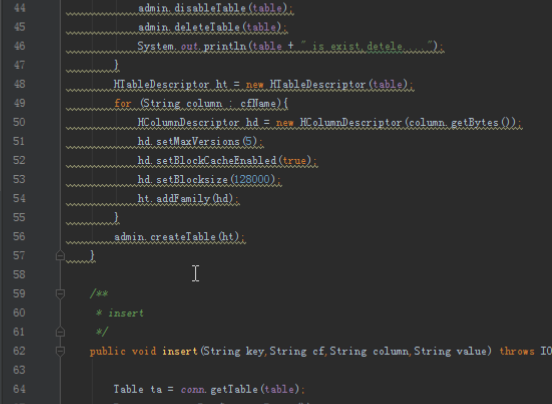
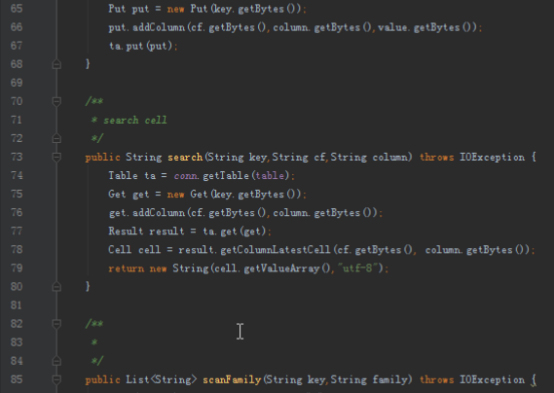
/*** insert*/
public void insert(String key,String cf,String column,String value)
/*** search cell*/
public String search(String key,String cf,String column)
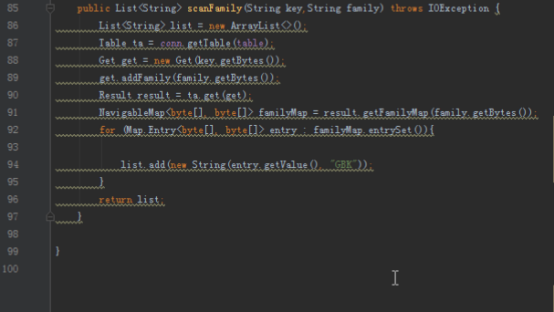
/**扫描列族*/
public List<String> scanFamily(String key,String family)
}
具体实现参见代码。
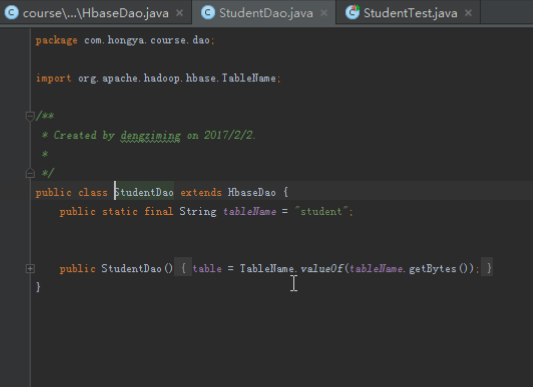
而StudentDao和CourseDao直接继承自HbaseDao,修改表名即可。
4.service层实现
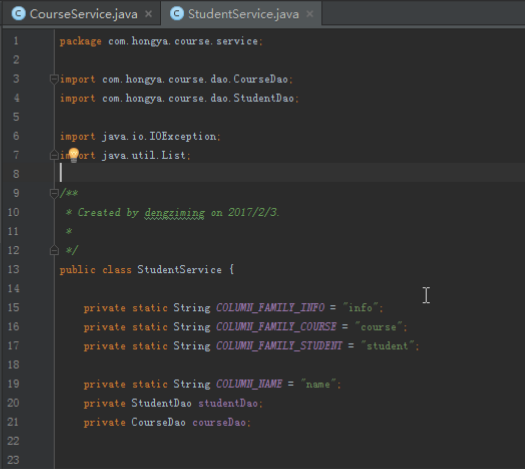
StudentService和CourseService的实现方式不一样
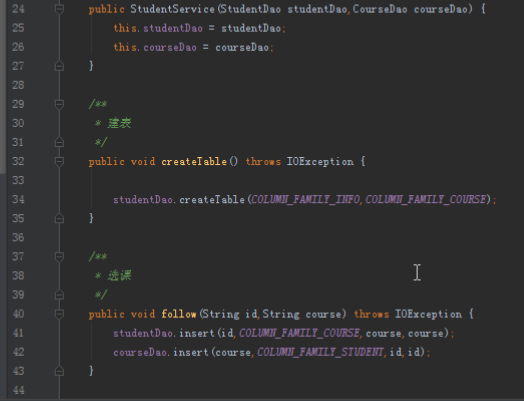
StudentService的实现如下,首先需要有studentdao的引用,有必要的话还需要有coursedao的引用,具体的业务则是通过调用dao的方法实现。
public class StudentService {
private StudentDao studentDao;
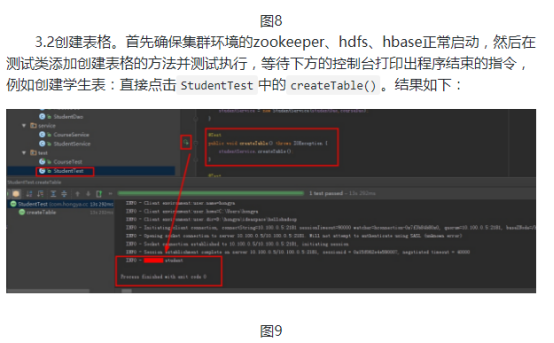
/*** 建表*/
public void createTable()
/*** 选课 */
public void follow(String id,String course)
/*** 查看选课*/
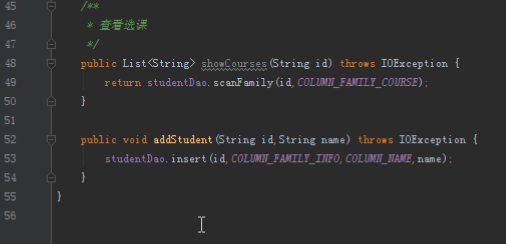
public List<String> showCourses(String id)
}
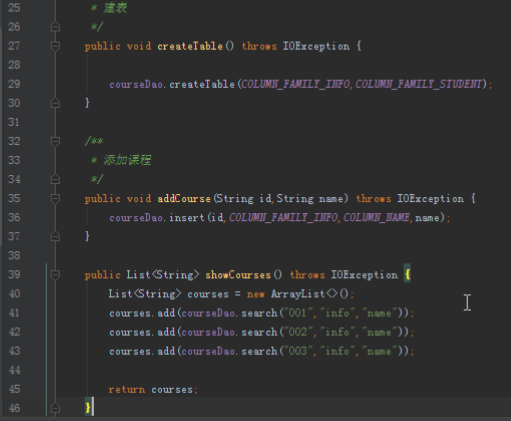
CourseService的实现如下,首先需要有coursedao的引用,具体的业务则是通过调用dao的方法实现。
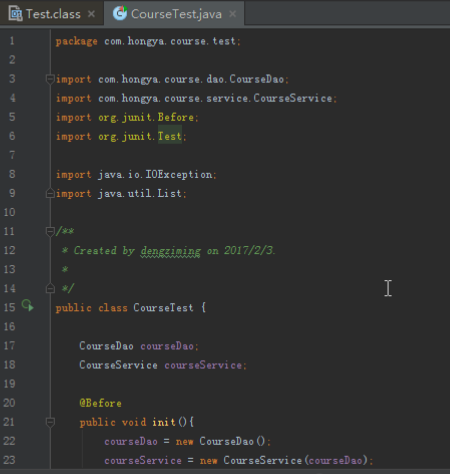
public class CourseService {
private CourseDao courseDao;
/*** 建表*/
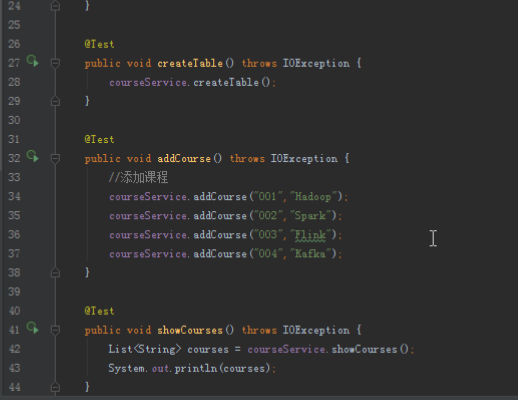
public void createTable()
/*** 添加课程*/
public void addCourse(String id,String name)
/**查看课程*/
public List<String> showCourses()
/*** 查看课程的选课人员*/
public List<String> showStudents(String id)
}
实验环境
1.操作系统
服务器:Linux_Centos
操作机:Windows_7
服务器默认用户名:root,密码:123456
操作机默认用户名:hongya,密码:123456
2.实验工具
1.Xshell

Xshell是一个强大的安全终端模拟软件,它支持SSH1, SSH2, 以及Microsoft Windows 平台的TELNET 协议。Xshell 通过互联网到远程主机的安全连接以及它创新性的设计和特色帮助用户在复杂的网络环境中享受他们的工作。 Xshell可以在Windows界面下用来访问远端不同系统下的服务器,从而比较好的达到远程控制终端的目的。实验中我们用到XShell5,其新增功能有:
1.有效保护信息安全性;Xshell支持各种安全功能,如SSH1/SSH2协议,密码,和DSA和RSA公开密钥的用户认证方法,并加密所有流量的各种加密算法。重要的是要保持用户的数据安全与内置Xshell安全功能,因为像Telnet和Rlogin这样的传统连接协议很容易让用户的网络流量受到任何有网络知识的人的窃取。Xshell将帮助用户保护数据免受黑客攻击。
2.最好的终端用户体验;终端用户需要经常在任何给定的时间中运用多个终端会话,以及与不同主机比较终端输出或者给不同主机发送同一组命令。Xshell则可以解决这些问题。此外还有方便用户的功能,如标签环境,广泛拆分窗口,同步输入和会话管理,用户可以节省时间做其他的工作。
3.代替不安全的Telnet客户端;Xshell支持VT100,VT220,VT320,Xterm,Linux,Scoansi和ANSI终端仿真和提供各种终端外观选项取代传统的Telnet客户端。
4. Xshell在单一屏幕实现多语言;Xshell中的UTF-8在同类终端软件中是第一个运用的。用Xshell,可以将多种语言显示在一个屏幕上,无需切换不同的语言编码。越来越多的企业需要用到UTF-8格式的数据库和应用程序,有一个支持UTF-8编码终端模拟器的需求在不断增加。Xshell可以帮助用户处理多语言环境。 5. 支持安全连接的TCP/IP应用的X11和任意;在SSH隧道机制中,Xshell支持端口转发功能,无需修改任何程序,它可以使所有的TCP/IP应用程序共享一个安全的连接。
2.Hadoop

Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。 Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,则MapReduce为海量的数据提供了计算
3.Hbase

HBase是一个分布式的、面向列的开源数据库,该技术来源于 Fay Chang 所撰写的Google论文“Bigtable:一个结构化数据的分布式存储系统”。就像Bigtable利用了Google文件系统(File System)所提供的分布式数据存储一样,HBase在Hadoop之上提供了类似于Bigtable的能力。HBase是Apache的Hadoop项目的子项目。HBase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。另一个不同的是HBase基于列的而不是基于行的模式。 HBase – Hadoop Database,是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用HBase技术可在廉价PC Server上搭建起大规模结构化存储集群。
4.IntelliJ IDEA

IDEA全称IntelliJ IDEA,是java语言开发的集成环境,IntelliJ在业界被公认为最好的java开发工具之一,尤其在智能代码助手、代码自动提示、重构、J2EE支持、Ant、JUnit、CVS整合、代码审查、创新的GUI设计等方面的功能可以说是超常的。IDEA是JetBrains公司的产品,这家公司总部位于捷克共和国的首都布拉格,开发人员以严谨著称的东欧程序员为主。
步骤1:实验环境介绍
实验中已经安装了hbase的集群(可能是伪分布式或者完全分布式),基于这个集群进行实验。
首先打开IDEA,按照以前的方式新建项目,添加jar包依赖,本次实验的代码已经放在hellohadoop的com.hongya的course下,实验中我们以这个代码为例进行学习。然后打开xshell,连上集群后,按照前面的学习内容,依次启动zookeeper、hadoop、hbase。
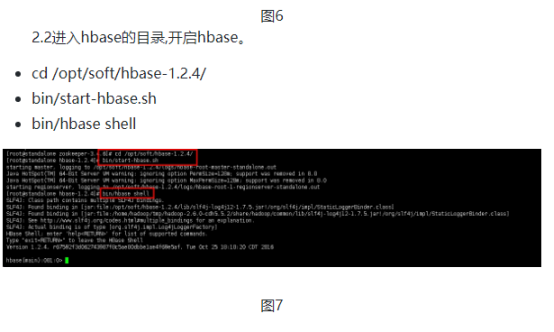
1.1编辑操作机本地hosts文件(C:\Windows\System32\drivers\etc下),修改服务器和操作机IP,以实验为准



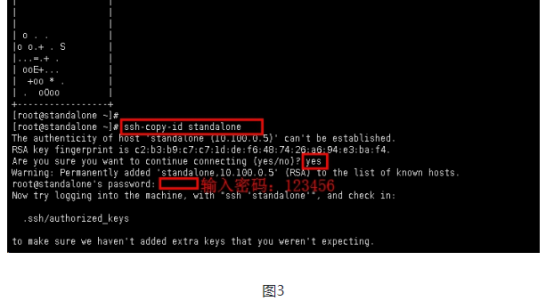
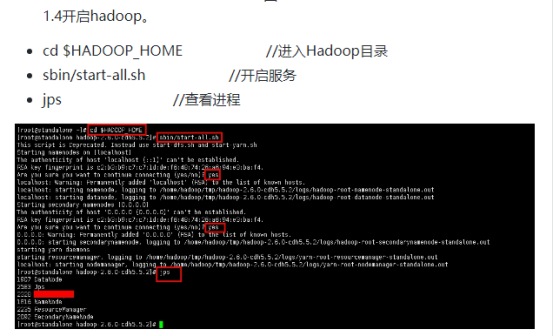
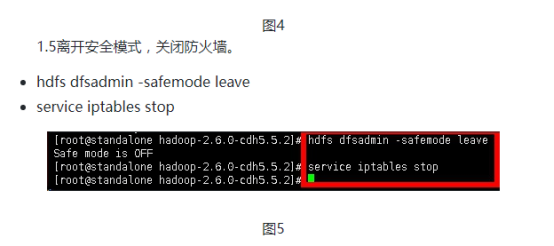
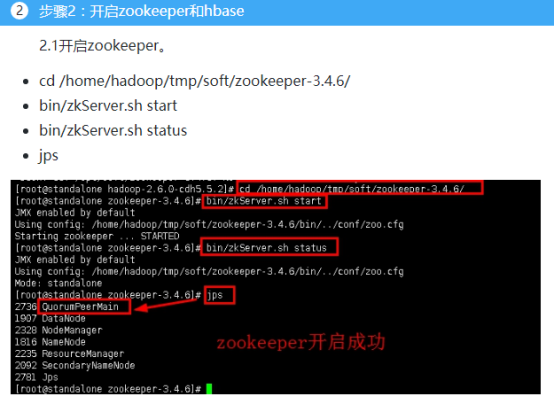





吴裕雄--天生自然HADOOP操作实验学习笔记:hbase学生选课案例的更多相关文章
- 吴裕雄--天生自然HADOOP操作实验学习笔记:pvuv统计案例理论
实验目的 复习pv.uv的概念和原理 了解pv.uv的实际意义和获取方法 实验原理 前面我们已经基于mapreduce进行数据的etl处理,实验有很多不足之处,这次实验我们是基于url数据进行pv和u ...
- 吴裕雄--天生自然HADOOP操作实验学习笔记:hbase微博案例
实验目的 熟悉hbase表格设计的方法 熟悉hbase的javaAPI 通过API理解掌握hbase的数据的逻辑视图 了解MVC的服务端设计方式 实验原理 上次我们已经初步设计了学生选课案例的,具体功 ...
- 吴裕雄--天生自然HADOOP操作实验学习笔记:使用hive操作hbase
实验目的 熟悉hive和hbase的操作 熟悉hadoop.hbase.hive.zookeeper的关系 熟练大数据环境的搭建 学会分析日志排除问题 实验原理 1.hive整合hbase原理 前面大 ...
- 吴裕雄--天生自然HADOOP操作实验学习笔记:mapreduce代码编程
实验目的 深入了解mapreduce的底层 了解IDEA的使用 学会通过本地和集群环境提交程序 实验原理 1.回忆mapreduce模型 前面进行了很多基础工作,本次实验是使用mapreduce的AP ...
- 吴裕雄--天生自然HADOOP操作实验学习笔记:分布式及RPC通信简介
实验目的 掌握GOF设计模式的代理模式 了解掌握socket编程.java反射.动态代理 了解NIO.多线程 掌握hadoop的RPC框架使用API 实验原理 1.什么是RPC 在hadoop出现以前 ...
- 吴裕雄--天生自然HADOOP操作实验学习笔记:hbase的javaAPI应用
实验目的 进一步了解hbase的操作 熟悉使用IDEA进行java开发 熟悉hbase的javaAPI 实验原理 前面已经了解通过hbase的shell操作hbase,确实比较难以使用,另外通过hiv ...
- 吴裕雄--天生自然HADOOP操作实验学习笔记:hbase的shell应用v2.0
HRegion 当表的大小超过设置值的时候,HBase会自动地将表划分为不同的区域,每个区域包含所有行的一个子集.对用户来说,每个表是一堆数据的集合,靠主键来区分.从物理上来说,一张表被拆分成了多块, ...
- 吴裕雄--天生自然HADOOP操作实验学习笔记:hive DDL
实验目的 了解hive DDL的基本格式 了解hive和hdfs的关系 学习hive在hdfs中的保存方式 学习一些典型常用的hiveDDL 实验原理 有关hive的安装和原理我们已经了解,这次实验我 ...
- 吴裕雄--天生自然HADOOP操作实验学习笔记:mapreduce和yarn命令
实验目的 了解集群运行的原理 学习mapred和yarn脚本原理 学习使用Hadoop命令提交mapreduce程序 学习对mapred.yarn脚本进行基本操作 实验原理 1.hadoop的shel ...
随机推荐
- 自学Java第二章——《Java的基础语法》
2.1 标识符 简单的说,凡是程序员自己命名的部分都可以称为标识符. 即给类.变量.方法.包等命名的字符序列,称为标识符. 1.标识符的命名规则 (1)Java的标识符只能使用26个英文字母大小写,0 ...
- C++零食:WTL中使用双缓冲避免闪烁
双缓冲的原理可以这样形象的理解:把电脑屏幕看作一块黑板.首先我们在内存环境中建立一个"虚拟"的黑板,然后在这块黑板上绘制复杂的图形,等图形全部绘制完毕的时候,再一次性的把内存中绘制 ...
- VS2013下OpenCV2.48配置
VS2013+OpenCV2.48配置 一.下载OpenCV OpenCV下载地址http://opencv.org/ SDK下载链接在页面右侧 根据平台选择相应的SDK下载.在Windows开发下开 ...
- 开源镜像站-Android镜像
mirrors.neusoft.edu.cn www.opencas.org ubuntu.buct.edu.cn Android developer 最新国内镜像:http://wear.techb ...
- Go语言之路—博客目录
Go语言介绍 为什么你应该学习Go语言? 开发环境准备 从零开始搭建Go语言开发环境 VS Code配置Go语言开发环境 Go语言基础 Go语言基础之变量和常量 Go语言基础之基本数据类型 Go语言基 ...
- IPsecVPN:阿里云VPN网关和深信服防火墙打通公有云和公司内网
简介 目前许多公司网络环境为混合云(私有云,IDC,公司内网融合)的状态,通过内网ip的访问使得工作更加方便,需求也更为迫切,而本文介绍的即是实现私有云和公司内网互通的一种方法,希望对有此需求的小伙伴 ...
- linux命令之---ping
1)命令简介 ping命令用来测试主机之间网络的连通性.执行ping指令会使用ICMP传输协议,发出要求回应的信息,若远端主机的网络功能没有问题,就会回应该信息,因而得知该主机运作正常. 2)命令参数 ...
- JVM性能优化系列-(4) 编写高效Java程序
4. 编写高效Java程序 4.1 面向对象 构造器参数太多怎么办? 正常情况下,如果构造器参数过多,可能会考虑重写多个不同参数的构造函数,如下面的例子所示: public class FoodNor ...
- 20200115--python学习第九天
今日内容 三元运算 函数 考试题 1.三元运算(又称三目运算) v= 前面 if 条件 else 后面 if 条件: v = '前面' else: v ='后面' 示例:让用户输入值,如果值是整数,则 ...
- 一键安装php5.6.40脚本(LAMP环境)
#!/bin/bash #安装依赖软件 yum -y install libxml2-devel curl-devel libjpeg libjpeg-devel libpng libpng-deve ...