Apache Kafka(九)- Kafka Consumer 消费行为
1. Poll Messages
在Kafka Consumer 中消费messages时,使用的是poll模型,也就是主动去Kafka端取数据。其他消息管道也有的是push模型,也就是服务端向consumer推送数据,consumer仅需等待即可。
Kafka Consumer的poll模型使得consumer可以控制从log的指定offset去消费数据、消费数据的速度、以及replay events的能力。
Kafka Consumer 的poll模型工作如下图:

- · Consumer 调用.poll(Duration timeout) 方法,向broker请求数据
- · 若是broker端有数据则立即返回;否则在timeout时间后返回empty
我们可以通过参数控制 Kafka Consumer 行为,主要有:
- · Fetch.min.bytes(默认值是1)
o 控制在每个请求中,至少拉取多少数据
o 增加此参数可以提高吞吐并降低请求的数目,但是代价是增加延时
- · Max.poll.records(默认是500)
o 控制在每个请求中,接收多少条records
o 如果消息普遍都比较小而consumer端又有较大的内存,则可以考虑增大此参数
o 最好是监控在每个请求中poll了多少条消息
- · Max.partitions.fetch.bytes(默认为1MB)
o Broker中每个partition可返回的最多字节
o 如果目标端有100多个partitions,则需要较多内存
- · Fetch.max.bytes(默认50MB)
o 对每个fetch 请求,可以返回的最大数据量(一个fetch请求可以覆盖多个partitions)
o Consumer并行执行多个fetch操作
默认情况下,一般不建议手动调整以上参数,除非我们的consumer已经达到了默认配置下的最高的吞吐,且需要达到更高的吞吐。
2. Consumer Offset Commit 策略
在一个consumer 应用中,有两种常见的committing offsets的策略,分别为:
- · (较为简单)enable.auto.commit = true:自动commit offsets,但必须使用同步的方式处理数据
- · (进阶)enable.auto.commit = false:手动commit offsets
在设置enable.auto.commit = true时,考虑以下代码:
while(true) {
List<Records> batch = consumer.poll(Duration.ofMillis(100));
doSomethingSynchronous(batch);
}
一个Consumer 每隔100ms poll一次消息,然后以同步地方式处理这个batch的数据。此时offsets 会定期自动被commit,此定期时间由 auto.commit.interval.ms 决定,默认为 5000,也就是在每次调用 .poll() 方法 5 秒后,会自动commit offsets。
但是如果在处理数据时用的是异步的方式,则会导致“at-most-once”的行为。因为offsets可能会在数据被处理前就被commit。
所以对于新手来说,使用 enable.auto.commit = true 可能是有风险的,所以不建议一开始就使用这种方式 。
若设置 enable.auto.commit = false,考虑以下代码:
while(true) {
List<Records> batch = consumer.poll(Duration.ofMillis(100));
if isReady(batch){
doSomethingSynchronous(batch);
consumer.commitSync();
}
}
此例子明确指示了在同步地处理了数据后,再主动commit offsets。这样我们可以控制在什么条件下,去commit offsets。一个比较典型的场景为:将接收的数据读入缓存,然后flush 缓存到一个数据库中,最后再commit offsets。
3. 手动Commit Offset 示例
首先我们关闭自动commit offsets :
// disable auto commit of offsets
properties.setProperty(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false"); 指定每个请求最多接收10条records,便于测试:
properties.setProperty(ConsumerConfig.MAX_POLL_RECORDS_CONFIG, "10");
添加以下代码逻辑:
public static void main(String[] args) throws IOException {
Logger logger = LoggerFactory.getLogger(ElasticSearchConsumer.class.getName());
RestHighLevelClient client = createClient();
// create Kafka consumer
KafkaConsumer<String, String> consumer = createConsumer("kafka_demo");
// poll for new data
while(true){
ConsumerRecords<String, String> records =
consumer.poll(Duration.ofMinutes(100));
logger.info("received " + records.count() + "records");
for(ConsumerRecord record : records) {
// construct a kafka generic ID
String kafka_generic_id = record.topic() + "_" + record.partition() + "_" + record.offset();
// where we insert data into ElasticSearch
IndexRequest indexRequest = new IndexRequest(
"kafkademo"
).id(kafka_generic_id).source(record.value(), XContentType.JSON);
IndexResponse indexResponse = client.index(indexRequest, RequestOptions.DEFAULT);
String id = indexResponse.getId();
logger.info(id);
try {
Thread.sleep(10); // introduce a small delay
} catch (InterruptedException e) {
e.printStackTrace();
}
}
logger.info("Committing offsets...");
consumer.commitSync(); // commit offsets manually
logger.info("Offsets have been committed");
}
}
这里我们在处理每次获取的10条records后(也就是for 循环完整执行一次),手动执行一次offsets commit。打印日志记录为:
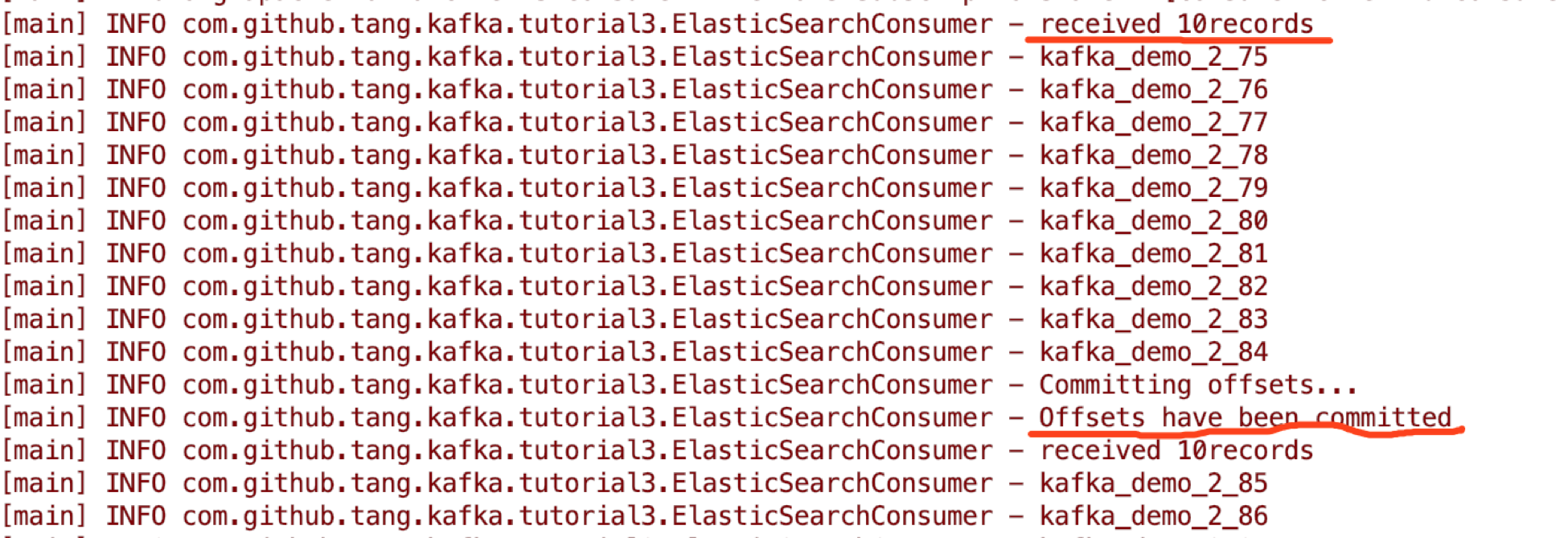
手动停止consumer 程序后,可以看到最后的committed offsets为165:
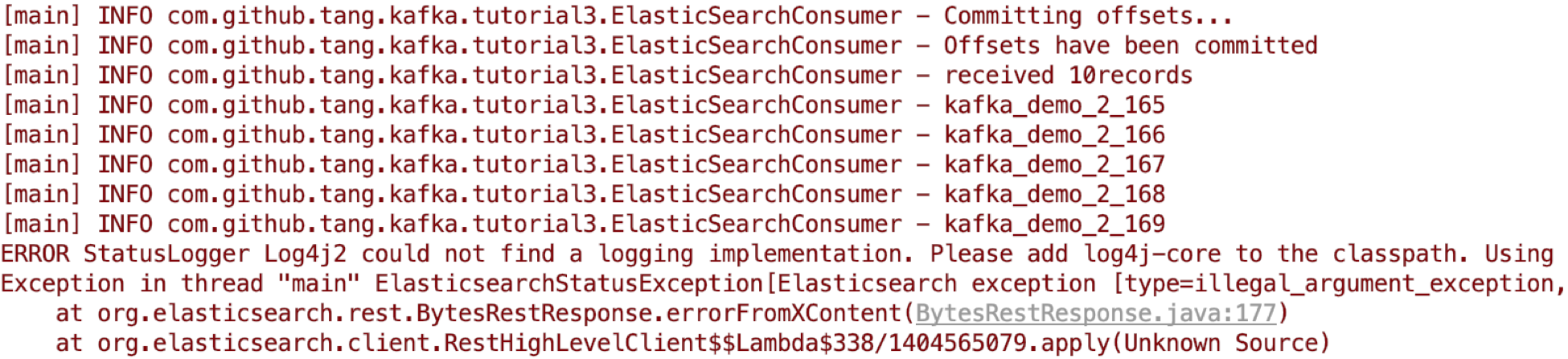
使用consumer-group cli 也可以验证当前committed offsets为165:

4. Performance Improvement using Batching
在这个例子中,consumer 限制每次poll 10条数据,然后每条依次处理(插入elastic search)。此方法效率较低,我们可以通过使用 batching 的方式增加吞吐。这里实现的方式是使用 elastic search API 提供的BulkRequest,基于之前的代码,修改如下:
public static void main(String[] args) throws IOException {
Logger logger = LoggerFactory.getLogger(ElasticSearchConsumer.class.getName());
RestHighLevelClient client = createClient();
// create Kafka consumer
KafkaConsumer<String, String> consumer = createConsumer("kafka_demo");
// poll for new data
while(true){
ConsumerRecords<String, String> records =
consumer.poll(Duration.ofMinutes(100));
// bulk request
BulkRequest bulkRequest = new BulkRequest();
logger.info("received " + records.count() + "records");
for(ConsumerRecord record : records) {
// construct a kafka generic ID
String kafka_generic_id = record.topic() + "_" + record.partition() + "_" + record.offset();
// where we insert data into ElasticSearch
IndexRequest indexRequest = new IndexRequest(
"kafkademo"
).id(kafka_generic_id).source(record.value(), XContentType.JSON);
IndexResponse indexResponse = client.index(indexRequest, RequestOptions.DEFAULT);
// add to our bulk request (takes no time)
bulkRequest.add(indexRequest);
//String id = indexResponse.getId();
//logger.info(id);
try {
Thread.sleep(10); // introduce a small delay
} catch (InterruptedException e) {
e.printStackTrace();
}
}
// bulk response
BulkResponse bulkItemResponses = client.bulk(bulkRequest, RequestOptions.DEFAULT);
logger.info("Committing offsets...");
consumer.commitSync(); // commit offsets manually
logger.info("Offsets have been committed");
}
}
可以看到,consumer在poll到记录后,并不会一条条的向elastic search 发送,而是将它们放入一个BulkRequest,并在for循环结束后发送。在发送完毕后,再手动commit offsets。
执行结果为:

Apache Kafka(九)- Kafka Consumer 消费行为的更多相关文章
- 11:57:24 [org.springframework.kafka.KafkaListenerEndpointContainer#0-0-C-1] WARN o.apache.kafka.clients.NetworkClient - [Consumer clientId=consumer-2, groupId=jiatian_api] 3 partitions have leader……
错误如下: 11:57:24 [org.springframework.kafka.KafkaListenerEndpointContainer#0-0-C-1] WARN o.apache.kaf ...
- 分布式系列九: kafka
分布式系列九: kafka概念 官网上的介绍是kafka是apache的一种分布式流处理平台. 最初由Linkedin开发, 使用Scala编写. 具有高性能,高吞吐量的特定. 包含三个关键能力: 发 ...
- Apache ZooKeeper在Kafka中的角色 - 监控和配置
1.目标 今天,我们将看到Zookeeper在Kafka中的角色.本文包含Kafka中需要ZooKeeper的原因.我们可以说,ZooKeeper是Apache Kafka不可分割的一部分.在了解Zo ...
- Kafka 0.8 Consumer设计解析
摘要 本文主要介绍了Kafka High Level Consumer,Consumer Group,Consumer Rebalance,Low Level Consumer实现的语义,以及适用场景 ...
- Kafka设计解析(十三)Kafka消费组(consumer group)
转载自 huxihx,原文链接 Kafka消费组(consumer group) 一直以来都想写一点关于kafka consumer的东西,特别是关于新版consumer的中文资料很少.最近Kafka ...
- Kafka 0.8 Consumer处理逻辑
0.前言 客户端用法: kafka.javaapi.consumer.ConsumerConnector consumer = kafka.consumer.Consumer.createJavaCo ...
- Apache Kafka安全| Kafka的需求和组成部分
1.目标 - 卡夫卡安全 今天,在这个Kafka教程中,我们将看到Apache Kafka Security 的概念 .Kafka Security教程包括我们需要安全性的原因,详细介绍加密.有了这 ...
- Spark Streaming + Kafka整合(Kafka broker版本0.8.2.1+)
这篇博客是基于Spark Streaming整合Kafka-0.8.2.1官方文档. 本文主要讲解了Spark Streaming如何从Kafka接收数据.Spark Streaming从Kafka接 ...
- 【Kafka】Kafka简单介绍
目录 基本介绍 概述 优点 主要应用场景 Kafka的架构 四大核心API 架构内部细节 基本介绍 概述 Kafka官网网站:http://kafka.apache.org/ Kafka是由Apach ...
- kafka实战教程(python操作kafka),kafka配置文件详解
kafka实战教程(python操作kafka),kafka配置文件详解 应用往Kafka写数据的原因有很多:用户行为分析.日志存储.异步通信等.多样化的使用场景带来了多样化的需求:消息是否能丢失?是 ...
随机推荐
- xctf-ics-07
首先管理页面进入到云平台项目管理中心 发现下面可以查看源码,点击view-source: 这个直接就绕过去了 看第二个 第二个需要满足$_SESSION['admin']==true才行,因此看看第三 ...
- vue.js父组件引入子组件,父组件向子组件传值
先看看目录结构app.vue为父组件,components里面的文件为子组件 下面这张图是父组件app.vue中的内容 下面这张图是子组件student.vue中的内容 这样父组件中的sdt数据就传入 ...
- C语言实现链式二叉树静态创建,(先序遍历),(中序遍历),(后续遍历)
#include <stdio.h>#include <stdlib.h> struct BTNode{ char data ; struct BTNode * pLchild ...
- afl-fuzz技术初探
afl-fuzz技术初探 转载请注明出处:http://www.cnblogs.com/WangAoBo/p/8280352.html 参考了: http://pwn4.fun/2017/09/21/ ...
- 给静态网站的链接添加nofollow属性
给网站的链接添加nofollow属性对SEO非常有效,如果是动态网站,实现的方法比较多,但是对于静态网站来说只能借助CSS或者JS来实现,单纯的CSS实现需要覆盖所有的链接出现位置:JS与CSS结合则 ...
- Unable to open debugger port (127.0.0.1:13249): java.net.BindException "Address already in use: JVM_Bind"
这个问题比较简单一点,Tomcat的端口被占用了,我使用的是IDEA里的一个热部署插件JReble,更新了IDEA之后就发现端口被占用了,可能我电脑没有重启过吧, 一直被占用着,所以解决方法就是更换一 ...
- 2018ICPC南京站Problem G. Pyramid
题意: 找有多少个等边三角形 解析: 首先打标找规律,然后对式子求差分 0,1,5,15,35,70,126,210... 1,4,10,20,35,56... 3,6,10,15,21... 3,4 ...
- LaTeX绘图
http://math.uchicago.edu/~weinan/programs/tex_diagrams/diagrams.html 给大家分享下这个,用鼠标画diagrams,然后可以一键复制l ...
- ajax从jsp向servlet传值
function Delete(s){ xmlHttp=new XMLHttpRequest(); var url = "/emp/FindSpecial?selcol=" +s; ...
- [SDOI2008] 校门外的区间 - 线段树
U T 即将区间 \(T\) 范围赋值为 \(1\) I T 即将区间 \(U - T\) 范围赋值为 \(0\) D T 即将区间 \(T\) 赋值为 \(0\) C T 由于 \(S=T-S=T( ...