Python:使用pymssql批量插入csv文件到数据库测试
并行进程怎么使用?
import os
import sys
import time def processFunc(i):
time.sleep(10-i)
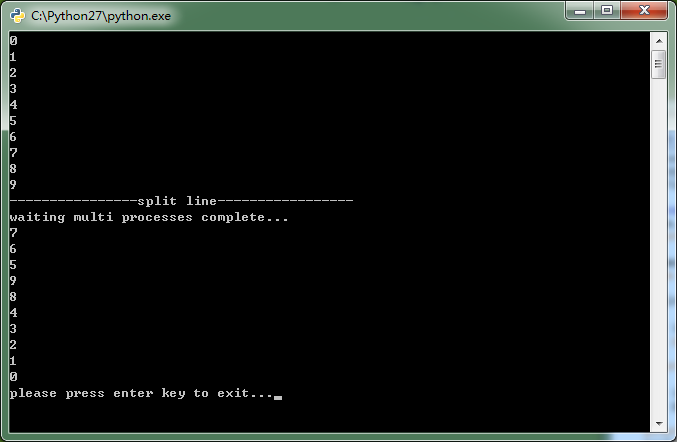
print i if __name__=='__main__':
from multiprocessing import Pool pool=Pool() for i in range(0,10):
print i print '----------------split line-----------------' for i in range(0,10):
pool.apply_async(processFunc,args=(i,)) print 'waiting multi processes complete...'
pool.close()
pool.join() s = raw_input("please press enter key to exit...")
print s
怎么确定我们使用的是多进程呢?

实现批量入库:
import os
import sys
import pymssql server="172.21.111.222"
user="Nuser"
password="NDb"
database="iNek_TestWithPython" def connectonSqlServer():
conn=pymssql.connect(server,user,password,database)
cursor=conn.cursor()
cursor.execute("""select getdate()""")
row=cursor.fetchone()
while row:
print("sqlserver version:%s"%(row[0]))
row=cursor.fetchone() conn.close() def getCreateTableScript(enodebid):
script="""IF NOT EXISTS (SELECT * FROM sys.objects WHERE object_id = OBJECT_ID(N'[dbo].[rFile{0}]') AND type in (N'U'))
BEGIN
CREATE TABLE [dbo].[rFile{0}](
[OID] [bigint] IDENTITY(1,1) NOT NULL,
[TimeStamp] [datetime] NULL,
[rTime] [datetime] NOT NULL,
[bTime] [datetime] NOT NULL,
[eTim] [datetime] NOT NULL,
[rid] [int] NOT NULL,
[s] [int] NOT NULL,
[c] [int] NOT NULL,
[muid] [decimal](18, 2) NULL,
[lsa] [decimal](18, 2) NULL,
[lsrip] [int] NULL,
[lcOID] [int] NULL,
[lcrq] [decimal](18, 2) NULL,
[gc2c1] [int] NULL,
[tdcCP] [decimal](18, 2) NULL,
...
...
CONSTRAINT [PK_rFile{0}] PRIMARY KEY NONCLUSTERED
(
[OID] ASC,
[rTime] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PS_OnrTime]([rTime])
) ON [PS_OnrTime]([rTime])
END IF NOT EXISTS (SELECT * FROM sys.indexes WHERE object_id = OBJECT_ID(N'[dbo].[rFile{0}]') AND name = N'IX_rFile_c{0}') BEGIN
CREATE NONCLUSTERED INDEX [IX_rFile_c{0}] ON [dbo].[rFile{0}] ([c] ASC)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
End
...
...
""".format(enodebid)
return script def getBulkInsertScript(enodebid,csvFilePath,formatFilePath):
script="""BULK INSERT [dbo].[rFile{0}]
FROM '{1}'
WITH
(
BATCHSIZE=10000,
FIELDTERMINATOR='\\t',
ROWTERMINATOR ='\\r\\n',
FORMATFILE ='{2}'
)""".format(enodebid,csvFilePath,formatFilePath)
return script def batchInsertToDB(enodebid,filePath):
from time import time
start=time()
fileExt=os.path.splitext(filePath)[1]
#print fileExt
if os.path.isfile(filePath) and (fileExt=='.gz' or fileExt=='.zip' or fileExt=='.xml' or fileExt==".csv"):
# 1)create table with index
conn=pymssql.connect(server,user,password,database)
cursor=conn.cursor()
cursor.execute(getCreateTableScript(enodebid))
conn.commit()
# 2)load csv file to db
cursor.execute(getBulkInsertScript(enodebid=enodebid,csvFilePath=filePath,formatFilePath="D:\\python_program\\rFileTableFormat.xml"))
conn.commit()
conn.close()
end=time()
print 'file:%s |size:%0.2fMB |timeuse:%0.1fs' % (os.path.basename(filePath),os.path.getsize(filePath)/1024/1024,end-start) if __name__=="__main__":
from time import time
#it's mutilple pro2cess not mutilple thread.
from multiprocessing import Pool start=time()
pool=Pool() rootDir="D:\\python_program\\csv"
for dirName in os.listdir(rootDir):
for fileName in os.listdir(rootDir+'\\'+dirName):
pool.apply_async(batchInsertToDB,args=(dirName,rootDir+'\\'+dirName+'\\'+fileName,))
#single pool apply
#batchInsertToDB(dirName,rootDir+'\\'+dirName+'\\'+fileName) print 'Waiting for all subprocesses done.....'
pool.close()
pool.join()
end=time()
print 'use time: %.1fs' %(end-start)
测试环境:
2.22服务器,CPU:E54620,Memory:64,磁盘SAS/万转以上。
测试速度:41分钟,处理200个ENB,一共4749个csv文件,一共19.1G,入库记录1 1491 1843条记录,每条记录30个字段左右,平均每秒入库46712条记录(每条记录32列)。
Python是8个进程运行。
监控图:
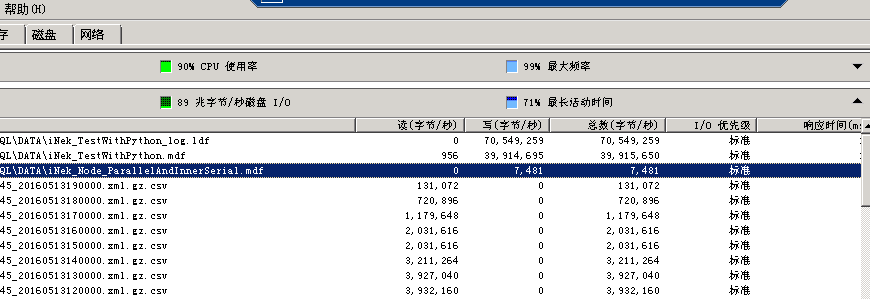
平均数据库日志文件写入速度:70M/S
平均数据库 文件写入速度:30M/S~40M/S
.net 并行多进程操作:
-- 2016-08-02 00:06:19.567 2016-08-01 23:37:14.067
-- 16parallel task :10s/enb
-- 2016-08-02 00:29:42.083 2016-08-02 00:09:29.297
-- 8 parallel task : 7s/enb
select (20*60+13)/160
Python:使用pymssql批量插入csv文件到数据库测试的更多相关文章
- python脚本-excel批量转换为csv文件
pandas和SQL数据分析实战视频教程 https://study.163.com/course/courseMain.htm?courseId=1006383008&share=2& ...
- C# ASP.NET CSV文件导入数据库
原文:C# ASP.NET CSV文件导入数据库 using System; using System.Collections.Generic; using System.Text; using Sy ...
- Java使用iBatis批量插入数据到Oracle数据库
Java使用iBatis批量插入数据到Oracle数据库 因为我们的数据跨库(mysql,oracle),单独取数据的话需要遍历好多遍,所以就想着先从mysql数据库中取出来的数据然后在oracle数 ...
- 基于CentOS的MySQL学习补充四--使用Shell批量从CSV文件里插入数据到数据表
本文出处:http://blog.csdn.net/u012377333/article/details/47022699 从上面的几篇文章中,能够知道怎样使用Shell创建数据库.使用Shell创建 ...
- Linux 用 shell 脚本 批量 导入 csv 文件 到 mysql 数据库
前提: 每个csv文件第一行为字段名 创建的数据库字段名同csv 文件的字段名 1. 批量导入 多个 csv 文件 for file in ./*.csv;do mv $file tablename. ...
- python之读取和写入csv文件
写入csv文件源码: #输出数据写入CSV文件 import csv data = [ ("Mike", "male", 24), ("Lee&quo ...
- 将文件夹下的所有csv文件存入数据库
# 股票的多因子分层回测代码实现 import os import pymysql # import datetime, time # from config import * database_ta ...
- 将csv文件读入数据库
USE LHJTest create table #temp6//创建临时表 ( A nvarchar(max) NOT NULL, B nvarchar(max), C nvarchar(max ...
- Android 批量插入数据到SQLite数据库
Android中在sqlite插入数据的时候默认一条语句就是一个事务,因此如果存在上万条数据插入的话,那就需要执行上万次插入操作,操作速度可想而知.因此在Android中插入数据时,使用批量插入的方式 ...
随机推荐
- 浏览器 user-agent 字符串的故事
你是否好奇标识浏览器身份的User-Agent,为什么每个浏览器都有Mozilla字样? 故事还得从头说起,最初的主角叫NCSA Mosaic,简称Mosaic(马赛克),是1992年末位于伊利诺伊大 ...
- 二进制流 最后一段数据是最后一次读取的byte数组没填满造成的
while(in.read(temp)!=-1){ out.write(temp); } 改成: int len; while((len=in.read(temp))!=-1){out.write(t ...
- Mschat控件示例升级错误处理方法
将具有 3.5 版图表控件的 ASP.NET 3.5 网站升级到 ASP.NET 4 需要更改 web.config 和注册指令 将具有 3.5 版图表控件的 ASP.NET 3.5 网站升级到 AS ...
- 用Java操作树莓派!pi4j简介与安装
简介 对C不熟?习惯了使用java不想换语言,但又想操作树莓派?想一边喝咖啡,一边吃树莓派蛋糕?快来使用pi4j吧! pi4j旨在为java开发者提供面友好的面向对象的API,来操控树莓派.pi4j对 ...
- mssql 常用SQL语句或函数
按 OrderDate 的顺序计算 SalesOrderHeader 表中所有行的行号,并只返回行 50 到 60(含). WITH OrderedOrders AS ( SELECT SalesOr ...
- 设计模式:中介者模式(Mediator)
定 义:用一个中介对象来封装一系列对象的交互.中介者使各个对象不需要显示地相互作用,从而耦合松散,而且可以独立的改变他们之间的交互. 结构图: Mediator类,抽象中介者类 abstract ...
- TCP 协议中MSS的理解
在介绍MSS之前我们必须要理解下面的几个重要的概念.MTU: Maxitum Transmission Unit 最大传输单元MSS: Maxitum Segment Size 最大分段大小PPPoE ...
- mysqlnd cannot connect to MySQL 4.1+ using the old insecure authentication解决办法
mysqlnd是个好东西.不仅可以提高与mysql数据库通信的效率,而且也可以方便的设置一些超时.如,连接超时,查询超时.但是,使用mysqlnd的时候,有个地方需要注意.就是服务端的密码格式不能使用 ...
- Introducing shard translator
Introducing shard translator by Krutika Dhananjay on December 23, 2015 GlusterFS-3.7.0 saw the relea ...
- iOS面试题 02
在面试的时候,面试官问我,“你对内存管理了解的多吗?” 我忘了当时是怎么回答的了,但是,肯定是一时没想起来怎么回答. 1.谁创建谁释放 2.autoreleasepool 3.retain,copy, ...