python实现简易数据库之三——join多表连接和group by分组
上一篇里面我们实现了单表查询和top N查询,这一篇我们来讲述如何实现多表连接和group by分组。
一、多表连接
多表连接的时间是数据库一个非常耗时的操作,因为连接的时间复杂度是M*N(M,N是要连接的表的记录数),如果不对进行优化,连接的产生的临时表可能非常大,需要写入磁盘,分多趟进行处理。
1、双表等值join
我们看这样一个连接sql:
select PS_AVAILQTY,PS_SUPPLYCOST,S_NAME
from SUPPLIER,PARTSUPP
where PS_SUPPKEY = S_SUPPKEY and PS_AVAILQTY > 2000and S_NATIONKEY = 1;
可以把这个sql理解为在SUPPLIER表的S_SUPPKEY属性和PARTSUPP表的PS_SUPPKEY属性上作等值连接,并塞选出满足PS_AVAILQTY > 2000和 S_NATIONKEY = 1的记录,输入满足条件记录的PS_AVAILQTY,PS_SUPPLYCOST,S_NAME属性。这样的理解对我们人来说是很明了的,但数据库不能照这样的方式执行,上面的PS_SUPPKEY其实是PARTSUPP的外键,两个表进行等值连接,得到的连接结果是很大的。所以我们应该先从单表查询条件入手,在单表查询过滤之后再进行等值连接,这样需要连接的记录数会少很多。
首先根据PS_AVAILQTY > 2000找出满足条件的PARTSUPP表的记录行号集A,然后根据S_NATIONKEY = 1找出SUPPLIER表找出相应的记录行号集B,在记录集A、B上进行等值连接,看图很简单:

依次扫描的时间复杂度为max(m,n),加上折半查找,总的时间复杂度为max(m,n)*(log(m1)+log(n1)),其中m1、n1表示where条件塞选出的记录数。
来看一下执行的结果:
Input SQL:
select PS_AVAILQTY,PS_SUPPLYCOST,S_NAME
from SUPPLIER,PARTSUPP
where PS_SUPPKEY = S_SUPPKEY
and PS_AVAILQTY > 2000
and S_NATIONKEY = 1;
{'FROM': ['SUPPLIER', 'PARTSUPP'],
'GROUP': None,
'ORDER': None,
'SELECT': [['PARTSUPP.PS_AVAILQTY', None, None],
['PARTSUPP.PS_SUPPLYCOST', None, None],
['SUPPLIER.S_NAME', None, None]],
'WHERE': [['PARTSUPP.PS_AVAILQTY', '>', '2000'],
['SUPPLIER.S_NATIONKEY', '=', '1'],
['PARTSUPP.PS_SUPPKEY', '=', 'SUPPLIER.S_SUPPKEY']]}
Quering: PARTSUPP.PS_AVAILQTY > 2000
Quering: SUPPLIER.S_NATIONKEY = 1
Quering: PARTSUPP.PS_SUPPKEY = SUPPLIER.S_SUPPKEY Output:
The result hava 26322 rows, here is the fisrt 10 rows:
-------------------------------------------------
rows PARTSUPP.PS_AVAILQTY PARTSUPP.PS_SUPPLYCOST SUPPLIER.S_NAME
-------------------------------------------------
1 8895 378.49 Supplier#000000003
2 4286 502.00 Supplier#000000003
3 6996 739.71 Supplier#000000003
4 4436 377.80 Supplier#000000003
5 6728 529.58 Supplier#000000003
6 8646 722.34 Supplier#000000003
7 9975 841.19 Supplier#000000003
8 5401 139.06 Supplier#000000003
9 6858 786.94 Supplier#000000003
10 8268 444.21 Supplier#000000003
-------------------------------------------------
Take 26.58 seconds.
从Quering后面的信息可以看到我们处理where子条件的顺序,先处理单表查询,再处理多表连接。
2、多表join
处理完双表join后,我们看一下怎么实现三个的join,示例sql:
select PS_AVAILQTY,PS_SUPPLYCOST,S_NAME
from SUPPLIER,PART,PARTSUPP
where PS_PARTKEY = P_PARTKEY
and PS_SUPPKEY = S_SUPPKEY
and PS_AVAILQTY > 2000
and P_BRAND = 'Brand#12'
and S_NATIONKEY = 1;
这里进行三个表的连接,三个表连接得到的应该是三个表的记录合并的结果,那根据where条件选出的记录行号应当包含三列,每一列是一个表的行号:
三个表的连接事实上建立在两个表连接的基础上的,先进行两个表的连接后,得到两组行号表,再将这两组行号表合并:
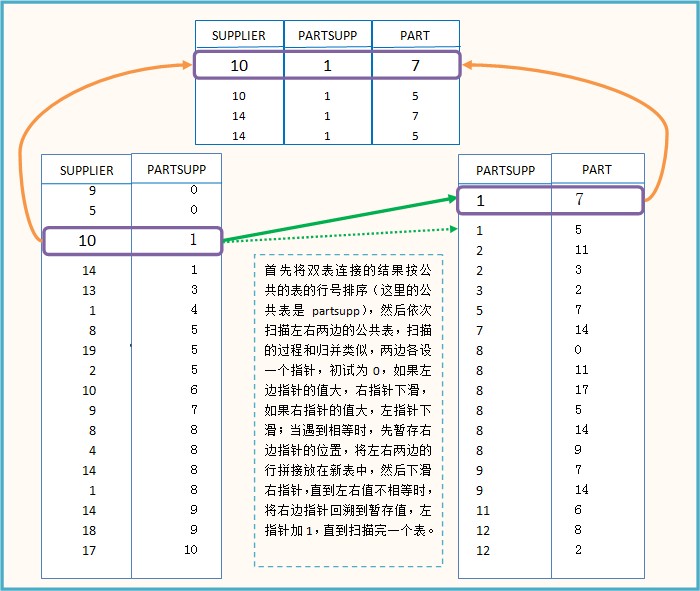
主要代码如下:
sortJoin(joina,cloumi)#cloumi表示公共表在joina的列号
sortJoin(joinb,cloumj)#cloumj表示公共表在joinb的列号
i = j = 0#左右指针初试为0
while i < len(joina) and j < len(joinb):
if joina[i][cloumi] < joinb[j][cloumj]:
i += 1
elif joina[i][cloumi] > joinb[j][cloumj]:
j += 1
else:#相等,进行连接
lastj = j
while j < len(joinb) and joina[i][cloumi] == joinb[j][cloumj]:
temp = joina[i] + joinb[j]
temp.remove(joina[i][cloumi])#删掉重复的元素
mergeResult.append(temp)
j += 1
j = lastj#右指针回滚
i += 1
我们分析一下这个算法的时间复杂度,首先要对两个表排序,复杂度为O(m1log(m1)),在扫描的过程中,右边指针会回溯,所以不再是O(max(m1,n1)),我们可以认为是k*O(m1*n1),这个系数k应该是很小的,因为一般右指针不会回溯太远,总的时间复杂度是O(m1log(m1))+k*O(m1*n1),应该是小于N方的复杂度。
看一下执行的结果:
Input SQL:
select PS_AVAILQTY,PS_SUPPLYCOST,S_NAME
from SUPPLIER,PART,PARTSUPP
where PS_PARTKEY = P_PARTKEY
and PS_SUPPKEY = S_SUPPKEY
and PS_AVAILQTY > 2000
and P_BRAND = 'Brand#12'
and S_NATIONKEY = 1;
{'FROM': ['SUPPLIER', 'PART', 'PARTSUPP'],
'GROUP': None,
'ORDER': None,
'SELECT': [['PARTSUPP.PS_AVAILQTY', None, None],
['PARTSUPP.PS_SUPPLYCOST', None, None],
['SUPPLIER.S_NAME', None, None]],
'WHERE': [['PARTSUPP.PS_AVAILQTY', '>', ''],
['PART.P_BRAND', '=', 'Brand#12'],
['SUPPLIER.S_NATIONKEY', '=', ''],
['PARTSUPP.PS_PARTKEY', '=', 'PART.P_PARTKEY'],
['PARTSUPP.PS_SUPPKEY', '=', 'SUPPLIER.S_SUPPKEY']]}
Quering: PARTSUPP.PS_AVAILQTY > 2000
Quering: PART.P_BRAND = Brand#
Quering: SUPPLIER.S_NATIONKEY = 1
Quering: PARTSUPP.PS_PARTKEY = PART.P_PARTKEY
Quering: PARTSUPP.PS_SUPPKEY = SUPPLIER.S_SUPPKEY Output:
The result hava 1022 rows, here is the fisrt 10 rows:
-------------------------------------------------
rows PARTSUPP.PS_AVAILQTY PARTSUPP.PS_SUPPLYCOST SUPPLIER.S_NAME
-------------------------------------------------
1 4925 854.19 Supplier#
2 4588 455.04 Supplier#
3 8830 852.13 Supplier#
4 8948 689.89 Supplier#
5 3870 488.38 Supplier#
6 6968 579.03 Supplier#
7 9269 228.31 Supplier#
8 8818 180.32 Supplier#
9 9343 785.01 Supplier#
10 3364 545.25 Supplier#
-------------------------------------------------
Take 50.42 seconds.
这个查询的时间比Mysql快了很多,在mysql上运行这个查询需要10分钟(建立了索引),想想也是合理的,我们的设计已经大大简化了,完全不考虑表的修改,牺牲这么的实用性必然能提升在查询上的效率。
二、group by分组
在执行完where条件后,读取原始记录,然后可以按group by的属性分组,分组的属性可能有多条,比如这样一个查询:
select PS_AVAILQTY,PS_SUPPLYCOST,S_NAME,COUNT(*)
from SUPPLIER,PART,PARTSUPP
where PS_PARTKEY = P_PARTKEY
and PS_SUPPKEY = S_SUPPKEY
and PS_AVAILQTY > 2000
and P_BRAND = 'Brand#12'
and S_NATIONKEY = 1;
group by PS_AVAILQTY,PS_SUPPLYCOST,S_NAME;
按 PS_AVAILQTY,PS_SUPPLYCOST,S_NAME这三个属性分组,我们实现时使用了一个技巧,将每个候选记录的这三个字段按字符串格式拼接成一个新的属性,拼接的示例如下:
"4925" "854.19" "Supplier#000002515" -->> "4925+854.19+Supplier#000002515"
注意中间加了一个加号“+”,这个加号是必须的,如果没有加号,"105","201"与"10","5201"的拼接结果都是"105201",这样得到的group by结果将会出错,而添加一个加号它们两的拼接结果是不同的。
拼接后,我们只需要按新的属性进行分组,可以使用map来实现,map的key为新的属性值,value为新属性值key的后续记录。再在组上进行聚集函数的运算。
这个小项目就写到这里了,或许这压根只是一个数据处理,谈不上数据库实现,不过通过这个小项目我对数据库底层的实现还是了解了很多,以后做数据库优化理解起来也容易一些。
谢谢关注,欢迎评论。
作者:MyDetail
出处:http://www.cnblogs.com/fengfenggirl/
本文版权归作者MyDetail和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
python实现简易数据库之三——join多表连接和group by分组的更多相关文章
- join多表连接和group by分组
join多表连接和group by分组 上一篇里面我们实现了单表查询和top N查询,这一篇我们来讲述如何实现多表连接和group by分组. 一.多表连接 多表连接的时间是数据库一个非常耗时的操作, ...
- python实现简易数据库之二——单表查询和top N实现
上一篇中,介绍了我们的存储和索引建立过程,这篇将介绍SQL查询.单表查询和TOPN实现. 一.SQL解析 正规的sql解析是用语法分析器,但是我找了好久,只知道可以用YACC.BISON等,sqlit ...
- MySQL JOIN 多表连接
除了常用的两个表连接之外,SQL(MySQL) JOIN 语法还支持多表连接.多表连接基本语法如下: 1 ... FROM table1 INNER|LEFT|RIGHT JOIN table2 ON ...
- Oracle数据库,join多表关联方式、union结果集合并
join on : 多表关联 内连接 :与其他表连接 from 表1 t join 表2 s on t.字段1 =s.字段2 join 表3 n on n.字段3=t.字段1 或 from 表1 ...
- MySql left join 多表连接查询优化语句
先过滤条件然后再根据表连接 同时在表中建立相关查询字段的索引这样在大数据多表联合查询的情况下速度相当快 创建索引: create index ix_register_year ON dbo.selec ...
- sql之表连接和group by +组函数的分析
1.首先我们来先看一个简单的例子: 有[Sales.Orders]订单表和[Sales.Customers]顾客表,表的机构如下 业务要求:筛选 来自“按时打算”国家的用户以及所下的订单数 sele ...
- python实现简易数据库之一——存储和索引建立
最近没事做了一个数据库project,要求实现一个简单的数据库,能满足几个特定的查询,这里主要介绍一下我们的实现过程,代码放在过ithub,可参看这里.都说python的运行速度很慢,但因为时间比较急 ...
- c# DataTable join 两表连接
转:https://www.cnblogs.com/xuxiaona/p/4000344.html JlrInfodt和dtsource是两个datatable,通过[姓名]和[lqry]进行关联 v ...
- 数据库多表连接方式介绍-HASH-JOIN
1.概述 hash join是一种数据库在进行多表连接时的处理算法,对于多表连接还有两种比较常用的方式:sort merge-join 和 nested loop. 为了比较清楚的介绍hash joi ...
随机推荐
- 关于EditText的一点深入的了解
最近在开发android下的记事本程序时,频繁的使用EditText控件,折腾来折腾去,算是对其的了解更深入了一些.特将这些收获记录如下: 一.几个属性的介绍 android:gravity=&quo ...
- 《大话移动APP测试:Android与iOS应用测试指南》
<大话移动app测试:android与ios应用测试指南> 基本信息 作者: 陈晔 出版社:清华大学出版社 ISBN:9787302368793 上架时间:2014-7-7 出版日期:20 ...
- org.dom4j.documentexception异常
org.dom4j.documentexception 解决: 设置xml文件编码格式:<?xml version="1.0" encoding="UTF-8&qu ...
- cmd常用命令 和 sql server相关基础
在Java开发中 ms sql server 接触算是比较少的,本文记录一些ms sql server的基础知识. 1. 为表字段增加索引:create index user_openid on us ...
- Support for AMD usage of jwplayer (require js)
使用require js 模块化代码时,其中播放器用的是jwplayer7.x 然后载入jwplayer.js后总是报license无效(license已经加入),最后在jwplayer官网论坛里找到 ...
- Python中的库使用之一 PIL
先上代码:本文主要工给自己参考,在需要的时候直接搜索查找就行了,不想看没有实际运行例子的文档,当参考完这部分还哦未能解决问题在参考PIL的相关文档! Skip to content This repo ...
- 小结getBytes()默认编码导致的xml字符串中出现乱码
遇到乱码第一印象想到的是如何统一编码,很少注意到这期间穿插的某些过程也是一大隐患.. sae上部署了一个spring写的微信小程序,手机总关注测试号点击菜单得到的文本消息却是乱码.. 聚焦发送消息的部 ...
- TEZ安装试用
下载地址:http://pan.baidu.com/s/1ZNpyI 第一次使用maven编译 tez的时候到tez ui部分报错,google后发现有人遇到类似问题是因为maven版本的问题, 当时 ...
- elastic search查询命令集合
Technorati 标签: elastic search,query,commands 基本查询:最简单的查询方式 query:{"term":{"title" ...
- ZOJ 2674 Strange Limit
欧拉函数. #include<iostream> #include<stdio.h> #include<string.h> #include<algorith ...