关于Latch争用
Latch是什么
- Buffer Latch:当工作线程访问缓冲池中的某个页之前,必须要先获得此页的Latch。主要用于保护用户对象和系统对象的页。等待类型表现为PAGELATCH_*
- I/O Latch:当工作线程请求访问的页未在缓冲池中时,就会发一个异步I/O从存储系统将对应的页加载到缓冲池中。这个过程会获取相应页上 I/O Latch,避免其它线程使用不兼容的Latch加载同一页到缓冲池中。等待类型表现为PAGEIOLATCH_*
- Non-Buffer Latch:保护缓冲池页之外的内部内存结构时使用。等待类型表现为LATCH_XX。
- KP – Keep Latch 保证引用的结构不能被破坏
- SH – Shared Latch, 读数据页的时候需要
- UP – Update Latch 更改数据页的时候需要
- EX – Exclusive Latch 独占模式,主要用于写数据页的时候需要
- DT – Destroy Latch 在破坏引用的数据结构时所需要
| KP | SH | UP | EX | DT |
| Y | Y | Y | Y | N |
| Y | Y | Y | N | N |
| Y | Y | N | N | N |
| Y | N | N | N | N |
| N | N | N | N | N |
- 影响Latch争用的因素
|
因素
|
明说 |
|
使用过多的逻辑CPU
|
任何多核的系统都会出现Latch争用。Latch争用超过可接受程度的系统,多数使用16个或者以上的核心数。 |
|
架构设计和访问模式
|
B树深度,索引的大小、页密度和设计,数据操作的访问模式都可能会导致过多的Latch争用
|
|
应用层的并发度过高
|
多数Latch争用都会伴有应用层的高并发请求。
|
|
数据库逻辑文件的布局
|
逻辑文件布局影响着分配单元结构(如PFS,GAM,SGAM,IAM等)的布局,从而影响Latch争用程度。最著名的例子就是:频繁创建和删除时临表,导致tempdb的PFS页争用
|
|
I/O子系统性能
|
大量的PAGEIOLATCH等待就说明SQL Server在等待I/O子系统。
|
- 观察性能监视器的CPU利用率和SQL Server等待时间,判断两者是否具有关联性。
- 通过DMV获取引起Latch争用的具体类型和资源。
- 诊断某些Non-Buffer Latch争用,可能还需要获取SQL Server进程的内存转储文件并结合Window调试工具一起分析。
- 使用“Query sys.dm_os_waiting_tasks Ordered by Session ID”脚本或者“Calculate Waits Over a Time Period”脚本观察当前的等待任务和平均Latch等待时间情况。
- 使用“QueryBufferDescriptorsToDetermineObjectsCausingLatch”脚本确定争用发生的位置(索引和表)。
- 使用性能计数器观察MSSQL%InstanceName%\Wait Statistics\Page Latch Waits\Average Wait Time或者查询sys.dm_os_wait_stats观察页平均Latch等待时间。
SELECT wt.session_id, wt.wait_type
, er.last_wait_type AS last_wait_type
, wt.wait_duration_ms
, wt.blocking_session_id, wt.blocking_exec_context_id, resource_description
FROM sys.dm_os_waiting_tasks wt
JOIN sys.dm_exec_sessions es ON wt.session_id = es.session_id
JOIN sys.dm_exec_requests er ON wt.session_id = er.session_id
WHERE es.is_user_process = 1
AND wt.wait_type <> 'SLEEP_TASK'
ORDER BY wt.wait_duration_ms desc
|
列
|
说明
|
|
Session_id
|
task所属的session id
|
|
Wait_type
|
当前的等待类型 |
|
Last_wait_type
|
上次发生等待时的等待类型 |
|
Wait_duration_ms
|
此等待类型的等待时间总和(毫秒) |
| Blocking_session_id |
当前被阻塞的session id
|
|
Blocking_exec_context_id
|
当前task的ID |
|
Resource_description
|
具体等待的资源 |
| 列 |
说明
|
|
Latch_class
|
Latch类型
|
|
Waiting_requests_count
|
当前Latch类型发生的等待次数
|
|
Wait_time_ms
|
当前Latch类型发生等待的时间总和
|
|
Max_wait_time_ms
|
当前Latch类型发生等待最长时间
|
- 高并发的INSERT,DELETE,UPDATE和SELECT操作
- 页密度较大,行较窄
- 表的行数较少,所以B树也较浅,索引深度在2~3级。
select o.name as [table], i.name as [index],
indexProperty(object_id(o.name), i.name, 'indexDepth')
+ indexProperty(object_id(o.name), i.name, 'isClustered') as depth, --clustered index depth reported doesn't count leaf level
i.[rows] as [rows], i.origFillFactor as [fillFactor],
case (indexProperty(object_id(o.name), i.name, 'isClustered'))
when 1 then 'clustered'
when 0 then 'nonclustered'
else 'statistic'
end as type
from sysIndexes i
join sysObjects o on o.id = i.id
where o.type = 'u'
and indexProperty(object_id(o.name), i.name, 'isHypothetical') = 0 --filter out hypothetical indexes
and indexProperty(object_id(o.name), i.name, 'isStatistics') = 0 --filter out statistics
order by o.name
view index depth
- 增加Tempdb的数据文件个数,个数=CPU的核心数
- 启用跟踪标记TF 1118
create table table1
(
TransactionID bigint not null,
UserID int not null,
SomeInt int not null
)
go
alter table table1
add constraint pk_table1
primary key clustered (TransactionID, UserID)
go
方式1.:使用UserID做为索引首键,将INSERT操作分布到所有数据页上。需要注意的是:索引修改后,所有SELECT的WHERE等式中需要同时指定UserID和TransactionID。
create table table1
(
TransactionID bigint not null,
UserID int not null,
SomeInt int not null
)
go
alter table table1
add constraint pk_table1
primary key clustered (UserID, TransactionID)
go
方式2:使用TransactionID对CPU核数取模做为索引首键,将INSERT操作较均匀分布到表上。
create table table1
(
TransactionID bigint not null,
UserID int not null,
SomeInt int not null
)
go
-- Consider using bulk loading techniques to speed it up
ALTER TABLE table1
ADD [HashValue] AS (CONVERT([tinyint], abs([TransactionID])%(32))) PERSISTED NOT NULL
alter table table1
add constraint pk_table1
primary key clustered (HashValue, TransactionID, UserID)
go
- 新建或者使用现有的文件组承载各分区
- 如果使用新文件组,需要考虑IO子系统的优化和文件组中数据文件的合理布局。如果INSERT负载占比较高,则文件组的数据文件个数建议为物理CPU核心数的1/4(或者1/2,或者相等,视情况而定)。
- 使用CREATE PARTITION FUNCTION将表分成N个分区。N值等于上一步的数据文件的个数。
- 使用CREATE PARTITION SCHEME绑定分区函数到文件组,然后再添加一个smallint或者tinyint类型的Hash列,再计算出合适的Hash分布值(例如HashBytes值取模 或者取Binary_Checksum值)。
--Create the partition scheme and function, align this to the number of CPU cores 1:1 up
to 32 core computer
-- so for below this is aligned to 16 core system
CREATE PARTITION FUNCTION [pf_hash16] (tinyint) AS RANGE LEFT FOR VALUES
(0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15)
CREATE PARTITION SCHEME [ps_hash16] AS PARTITION [pf_hash16] ALL TO ( [ALL_DATA] ) -- Add the computed column to the existing table (this is an OFFLINE operation)
-- Consider using bulk loading techniques to speed it up
ALTER TABLE [dbo].[latch_contention_table]
ADD [HashValue] AS (CONVERT([tinyint], abs(binary_checksum([hash_col])%(16)),(0)))
PERSISTED NOT NULL
--Create the index on the new partitioning scheme
CREATE UNIQUE CLUSTERED INDEX [IX_Transaction_ID]
ON [dbo].[latch_contention_table]([T_ID] ASC, [HashValue])
ON ps_hash16(HashValue)

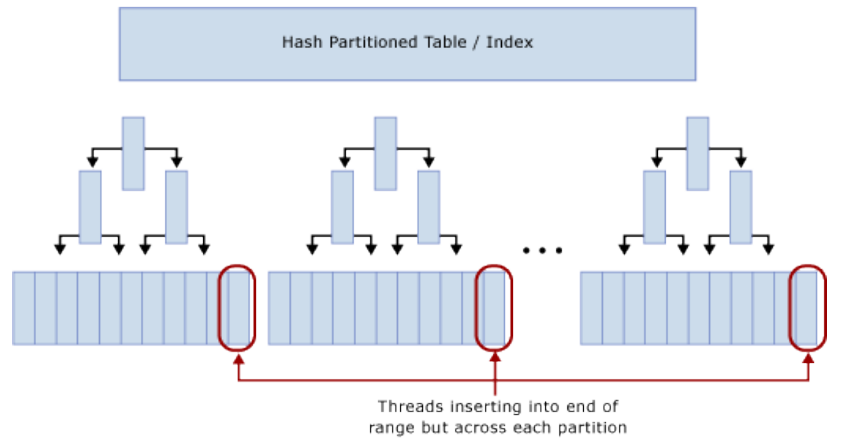
- 通常SELECT语句的查询谓词部分需要修改,使其包含Hash分区列。这会导致查询计划的分区消除不可用。
- 某些其它查询(如基于范围查询的报表)也不能使用分区消除。
- 当分区表与另一个表JOIN时,如果使用分区消除,则另一个表需要在同样的键上实现Hash分区并且Hash键需要包括在JOIN条件里。
- Hash分区会使滑动窗口归档和分区归档功能不可用。
总结
1. 本文以SQLCAT的Latch Contention白皮书为基础,结合Paul Randal关于Latch的博文,以及本人的经验而成。
2. Buffer Latch Contention较容易定位和处理。Non-Buffer Latch 是较为棘手的,因为太少关于此类型Latch的说明资料,造成有时定位到类型,也不知道它是什么意思,无从下手。
附加代码:
关于Latch争用的更多相关文章
- 关于MySQL latch争用深入分析与判断
1.latch锁是什么锁? 2.latch锁是如何保护list? 3.latch争用的现象和过程? 4.latch什么时候会产生严重的争用? 5.如何监控latch争用情况? 6.如何确认latch争 ...
- [转载】——故障排除:Shared Pool优化和Library Cache Latch冲突优化 (文档 ID 1523934.1)
原文链接:https://support.oracle.com/epmos/faces/DocumentDisplay?_adf.ctrlstate=23w4l35u5_4&id=152393 ...
- Oracle Latch的学习【原创】
Latch详解 - MaxChou 本文以学习为目的,大部分内容来自网络转载. 什么是Latch 串行化 数据库系统本身是一个多用户并发处理系统,在同一个时间点上,可能会有多个用户同时操作数据库.多个 ...
- latch: cache buffers chains故障处理总结(转载)
一大早就接到开发商的电话,说数据库的CPU使用率为100%,应用相应迟缓.急匆匆的赶到现场发现进行了基本的检查后发现是latch: cache buffers chains 作祟,处理过程还算顺利,当 ...
- latch: cache buffers chains故障处理总结
一大早就接到开发商的电话,说数据库的CPU使用率为100%,应用相应迟缓.急匆匆的赶到现场发现进行了基本的检查后发现是latch: cache buffers chains 作祟,处理过程还算顺利,当 ...
- latch介绍
latch是一种锁,用来实现对Oracle所有共享数据结构的串行化访问.共享池就是这样一个例子, 这是系统全局区中一个庞大的共享数据结构,Oracle正是在这里存储已解析,已编译的SQL. 修改这个共 ...
- latch:library cache
一:硬解析造成的shared pool latch 争用: 每一个sql被执行之前,先要到library cache中根据hash_value查找parent cursor,这就需要先获得librar ...
- cache buffers chains latch
cache buffers chains latch 从 Oracle 8i Database 开始, 散列锁存器<-------(1:m)------>hash bucket<-- ...
- 热点块引发的cache buffers cahins latch
热点块引发的Cache buffer Chains latch: SQL语句即便适当进行了调优,有时也无法解决cache buffers cahins latch,若在编写SQL语句时的SQL工作方式 ...
随机推荐
- 八卦一下黄晓明和Angelababy的电话号码
最新一期20150605的<奔跑吧兄弟>真是太搞笑了,邓超被大家整的... 但这一期有个细节引起了我的注意,就是Angelababy在现场打电话给黄晓明,而拨键声音十分清晰.一些拥有“绝对 ...
- JAVA中取子字符串的几种方式
有这样一串字符串:String s = "共 100 页, 1 2 3 4..."; 假如我想把"100"给取出来,该如何做? 方法一: 采用split的方式 ...
- CROC 2016 - Final Round [Private, For Onsite Finalists Only] C. Binary Table FWT
C. Binary Table 题目连接: http://codeforces.com/problemset/problem/662/C Description You are given a tab ...
- Code First 中使用 ForeignKey指定外键时总是显示未引用
Code First 中使用 ForeignKey指定外键时总是显示未引用 原因是:开发环境是在.NET 4.0 修改项目,改为.net 4.5
- Thinkpad X240使用U盘安装Win7系统
更改BIOS设置 不同电脑的进入BIOS的方式可能不太一样,Thinkpad X240的进入方式是在电脑启动的时候按下回车键,然后按F1进入BIOS. 1. 修改secure boot为Disable ...
- win10 Enable developer Mode
经过漫长的安装过程 win10终于装上了vs2015 rc- 写个小程序试试 结果提示: 根据提示打开 设置--更新--for developer 据说应该有这么个界面: 但是这个界面根本 ...
- ECSHOP后台SQL查询提示错误 this sql May contain UPDATE,DELETE,TRUNCATE,ALTER,DROP,FLUSH,INSERT
一).首先说一下错误现象:市面上流行的绝大部分ECSHOP模板,安装的时候都需要执行一段或几段SQL语句来修改数据结构或者初始化一些数据.大多数ECSHOP管理员为了省事,都会通过 “ECSHOP后台 ...
- WP-PostViews的安装和设置方法
wordpress本身并没有文章浏览统计功能,必须借助插件.想要知道自己的文章被多数访客浏览,或者访客对哪些文章或者哪类文章更加有兴趣,这就是文章统计的重要性了.WP-PostViews插件是哥不错的 ...
- C#新开一个线程取到数据,如何更新到主线程UI上面
一:问题 之前有被面试官问过,在WinForm中,要去网络上获取数据,由于网络环境等原因,不能很快的完成,因此会发生进程阻塞,造成主进程假死的现象,需要怎么解决? 二:思路 因此,往往是新 ...
- mac或linux下xampp的mysql配置
在mac 下安装好xampp后,需要在终端命令行操作时,比如输入:mysql -u root -p,未正确配置前不会出现想要的输入密码提示,而是会提示: command not found 原来当你输 ...