Hadoop入门程序WordCount的执行过程
首先编写WordCount.java源文件,分别通过map和reduce方法统计文本中每个单词出现的次数,然后按照字母的顺序排列输出,
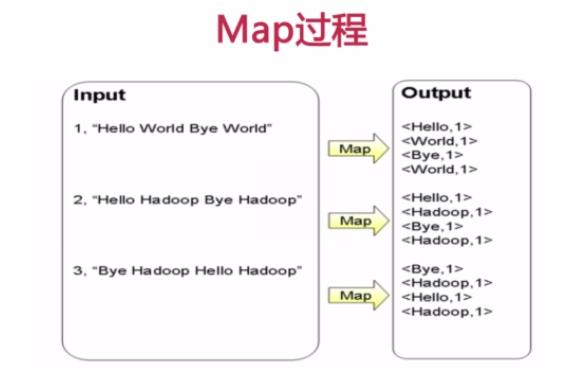
Map过程首先是多个map并行提取多个句子里面的单词然后分别列出来每个单词,出现次数为1,全部列举出来
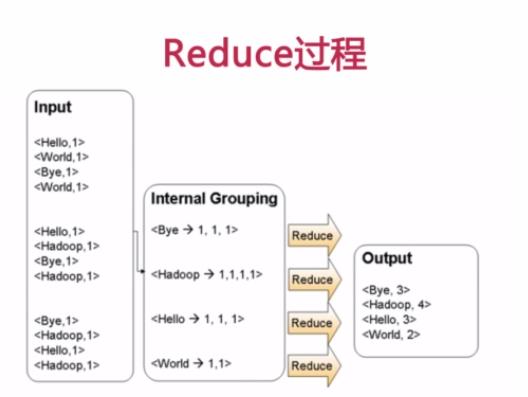
Reduce过程首先将相同key的数据进行查找分组然后合并,比如对于key为Hello的数据分组为:<Hello, 1>、<Hello,1>、<Hello,1>,合并之后就是<Hello,1+1+1>,分组也可以理解为reduce的操作,合并减少数据时reduce的主要任务,叠加运算之后就是<Hello, 3>所以最后可以输出Hello 3,这样就完成了一轮MapReduce处理
WordCount.java代码如下:
import java.io.IOException;
import java.util.Iterator;
import java.util.StringTokenizer; import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.FileInputFormat;
import org.apache.hadoop.mapred.FileOutputFormat;
import org.apache.hadoop.mapred.JobClient;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapred.MapReduceBase;
import org.apache.hadoop.mapred.Mapper;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.Reducer;
import org.apache.hadoop.mapred.Reporter;
import org.apache.hadoop.mapred.TextInputFormat;
import org.apache.hadoop.mapred.TextOutputFormat; public class WordCount { public static class Map extends MapReduceBase implements
Mapper<LongWritable, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text(); public void map(LongWritable key, Text value,
OutputCollector<Text, IntWritable> output, Reporter reporter)
throws IOException {
String line = value.toString();
StringTokenizer tokenizer = new StringTokenizer(line);
while (tokenizer.hasMoreTokens()) {
word.set(tokenizer.nextToken());
output.collect(word, one);
}
}
} public static class Reduce extends MapReduceBase implements
Reducer<Text, IntWritable, Text, IntWritable> {
public void reduce(Text key, Iterator<IntWritable> values,
OutputCollector<Text, IntWritable> output, Reporter reporter)
throws IOException {
int sum = 0;
while (values.hasNext()) {
sum += values.next().get();
}
output.collect(key, new IntWritable(sum));
}
} public static void main(String[] args) throws Exception {
JobConf conf = new JobConf(WordCount.class);
conf.setJobName("wordcount"); conf.setOutputKeyClass(Text.class);
conf.setOutputValueClass(IntWritable.class); conf.setMapperClass(Map.class);
conf.setCombinerClass(Reduce.class);
conf.setReducerClass(Reduce.class); conf.setInputFormat(TextInputFormat.class);
conf.setOutputFormat(TextOutputFormat.class); FileInputFormat.setInputPaths(conf, new Path(args[0]));
FileOutputFormat.setOutputPath(conf, new Path(args[1])); JobClient.runJob(conf);
}
}
将此java文件上传到服务器后,首先要进行编译,如果是eclipse会自动完成,如果没有配置开发环境需要手动对源文件进行编译,命令如下:
javac -classpath /hadoop/hadoop-1.2./hadoop-core-1.2..jar:/hadoop/hadoop-1.2./lib/commons-cli-1.2.jar WordCount.java
编译的时候需要制定上面两个jar包,编译完成之后除了生成WordCount.class字节码之外还有WordCount$Map.class和WordCount$Reduce.class,我们知道这两个文件是内部类Map和Reduce生成的
然后开始对class文件打包生成wordcount.jar
jar -cvf wordcount.jar *.class

现在就打包生成了wordcount.jar文件
接下来可以通过传给main方法参数执行参数是两个字符串,分别为args[0]和args[1],可以把它放到文件中进行输入,那么可以在hdfs文件系统中建立两个文件file01和file02并写入内容,依次执行命令:
$ echo "Hello World Hello Java" > file01
$ echo "Hello World Hello Hadoop" > file02
$ hadoop fs -mkdir input
$ hadoop fs -put file0* input/
现在hdfs文件系统中/user/用户名/input下就有两个文件file01和file02,同样我们可以用命令查看文件的存在性和内容
接下来就可以提交任务用hadoop来运行jar包中的函数进行数据处理了
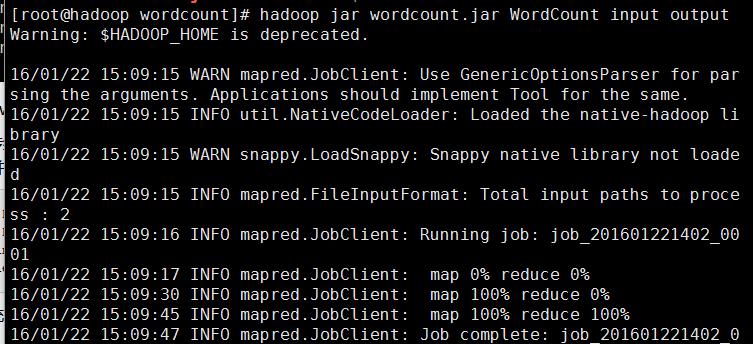
hadoop jar wordcount.jar WordCount input output
WordCount代码jar包里的主类,input是传入的文件作为参数,output参数就是hadoop作业完毕之后结果存放目录,开始执行会看到map和reduce的处理进度
处理完毕后,通过hadoop fs -ls output/ 查看生成的结果文件是否存在
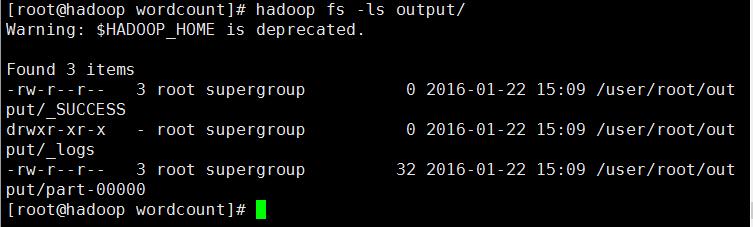
通过结果可以看到任务执行正常并输出了结果文件,可以用hadoop fs -get output localdata将文件传到本地查看,也可以执行下面命令查看文件的内容
hadoop fs -cat output/part-
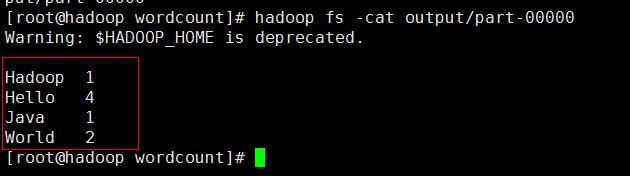
可以看到结果按顺序统计出来了,到这里一个简单的WordCount程序就手动开发成功了
Hadoop入门程序WordCount的执行过程的更多相关文章
- Hadoop入门经典:WordCount
转:http://blog.csdn.net/jediael_lu/article/details/38705371 以下程序在hadoop1.2.1上测试成功. 本例先将源代码呈现,然后详细说明执行 ...
- (转载)Hadoop示例程序WordCount详解
最近在学习云计算,研究Haddop框架,费了一整天时间将Hadoop在Linux下完全运行起来,看到官方的map-reduce的demo程序WordCount,仔细研究了一下,算做入门了. 其实Wor ...
- Hadoop入门经典:WordCount 分类: A1_HADOOP 2014-08-20 14:43 2514人阅读 评论(0) 收藏
以下程序在hadoop1.2.1上测试成功. 本例先将源代码呈现,然后详细说明执行步骤,最后对源代码及执行过程进行分析. 一.源代码 package org.jediael.hadoopdemo.wo ...
- 第02讲:Flink 入门程序 WordCount 和 SQL 实现
我们右键运行时相当于在本地启动了一个单机版本.生产中都是集群环境,并且是高可用的,生产上提交任务需要用到flink run 命令,指定必要的参数. 本课时我们主要介绍 Flink 的入门程序以及 SQ ...
- Hadoop示例程序WordCount详解及实例(转)
1.图解MapReduce 2.简历过程: Input: Hello World Bye World Hello Hadoop Bye Hadoop Bye Hadoop Hello Hadoop M ...
- Hadoop示例程序WordCount编译运行
首先确保Hadoop已正确安装及运行. 将WordCount.java拷贝出来 $ cp ./src/examples/org/apache/hadoop/examples/WordCount.jav ...
- MFC程序开始的执行过程详述
1)我们知道在WIN32API程序当中,程序的入口为WinMain函数,在这个函数当中我们完成注册窗口类,创建窗口,进入消息循环,最后由操作系统根据发送到程序窗口的消息调用程序的窗口函数.而在MFC程 ...
- Hadoop入门实例——WordCount统计单词
首先要说明的是运行Hadoop需要jdk1.6或以上版本,如果你还没有搭建好Hadoop集群,请参考我的另一篇文章: Linux环境搭建Hadoop伪分布模式 马上进入正题. 1.启动Hadoop集群 ...
- 2、flink入门程序Wordcount和sql实现
一.DataStream Wordcount 代码地址:https://gitee.com/nltxwz_xxd/abc_bigdata 基于scala实现 maven依赖如下: <depend ...
随机推荐
- HashMap和Hashtable及HashSet的区别
相关文章1:HashSet,TreeSet和LinkedHashSet的区别 相关文章2:HashSet和TreeSet的区别 Hashtable类 Hashtable继承Map接口,实现一个 ...
- phpstudy2016最新版本mysql无法使用innodb的问题解决
这里顺便记录一下今天遇见的神奇问题,在使用官方最新版本的phpstudy中,其它组件一切正常,但是奇怪的发现mysql是无法开启innodb的,以下为最新的下载地址: http://www.phpst ...
- groovy-集合
Lists 你能使用下面的方法创建一个lists,注意[]是一个空list. 1 def list = [5, 6, 7, 8] 2 assert list.get(2) == 7 3 assert ...
- <jsp:invoke fragment=""/>的理解和使用
在传统 JSP 中,想要实现页面布局管理比较麻烦,为了解决在 JSP 中布局的问题,出现了很多开源软件,比如 Apache Tiles 和 SiteMesh 就是其中比较优秀的.但是使用开源软件实现布 ...
- The C Programming Language (second edition) 实践代码(置于此以作备份)
1. #include <stdio.h> #include <stdlib.h> #include <math.h> #include<time.h> ...
- Web应用程序或者WinForm程序 调用 控制台应用程序及参数传递
有时候在项目中,会调用一个控制台应用程序去处理一些工作.那在我们的程序中要怎么样做才能调用一个控制台应用程序并将参数传递过去,控制台程序执行完后,我们的程序又怎样获取返回值?代码如下:调用代码: ...
- python numpy 教程
http://blog.chinaunix.net/uid-21633169-id-4408596.html
- mappedBy reference an unknown target entity property解决方法
Exception in thread "main" org.springframework.beans.factory.BeanCreationException: Error ...
- 使用sql server2005全文检索
SQL Server 2005的全文检索采用类似Lucece的技术, 为文本检索做index, 尤其适合大文本字段的检索, 性能比Lucece差一些. 著名的stackoverflow网站也使用过SQ ...
- Borg Maze(MST & bfs)
Borg Maze Time Limit: 1000MS Memory Limit: 65536K Total Submissions: 9220 Accepted: 3087 Descrip ...