【Java】XML解析之DOM
DOM介绍
DOM(Document Object Model)解析是官方提供的XML解析方式之一,使用时无需引入第三方包,代码编写简单,方便修改树结构,但是由于DOM解析时是将整个XML文件加载到内存中进行解析,因此当XML文件较大时,使用DOM解析效率会降低,而且可能造成内存溢出。
XML生成
代码如下:
public static void write() {
//文档构建工厂
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
try {
//文档构建器
DocumentBuilder builder = dbf.newDocumentBuilder();
//文档
Document doc = builder.newDocument();
//设置xml文件是否独立
doc.setXmlStandalone(true);
//设置xml文件版本,默认1.0
doc.setXmlVersion("1.1");
//创建根目录节点
Element root = doc.createElement("conpany");
//设置节点属性
root.setAttribute("name", "hd");
//添加根节点
doc.appendChild(root);
Element department = doc.createElement("department");
department.setAttribute("name", "test");
//设置节点文本
department.setTextContent("123456");
//添加到根节点
root.appendChild(department);
// 工厂类,用来获取转换对象
TransformerFactory transFactory = TransformerFactory.newInstance();
//转化对象
Transformer transFormer = transFactory.newTransformer();
// 设置文档自动换行
transFormer.setOutputProperty(OutputKeys.INDENT, "yes");
//设置编码方式,默认UTF-8
//transFormer.setOutputProperty(OutputKeys.ENCODING, "GB2312");
//文件源
DOMSource domSource = new DOMSource(doc);
File file = new File("src/doc-write.xml");
if (file.exists()) {
file.delete();
}
file.createNewFile();
//输出文件流
FileOutputStream out = new FileOutputStream(file);
//结果流
StreamResult xmlResult = new StreamResult(out);
//转化
transFormer.transform(domSource, xmlResult);
System.out.println("创建生成文件位置===========" + file.getAbsolutePath());
} catch (Exception e) {
e.printStackTrace();
}
}
输出:创建生成文件位置===========D:\workspace\test-xml\src\doc-write.xml
doc-write.xml的内容:
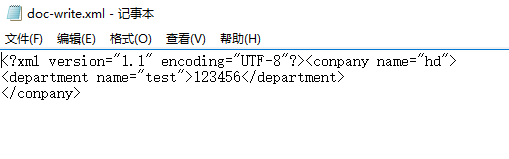
XML解析
需要在src目录中,先存放一个test.xml文件
<?xml version="1.0" encoding="UTF-8"?>
<conpany name="hd">
<department name="department1">
<employee name="employee1" id="1">123</employee>
</department>
<department name="department2">
<employee name="employee2" id="2">321</employee>
<employee name="employee3" id="3"></employee>
</department>
<department name="department3">
</department>
</conpany>
新建一个TestDom的java类,里面写一个read方法,代码如下:
public static void read() {
DocumentBuilderFactory builderFactory = DocumentBuilderFactory.newInstance();
try {
DocumentBuilder builder = builderFactory.newDocumentBuilder();
//输入流
InputStream is = TestDom.class.getClassLoader().getResourceAsStream("test.xml");
//文档构建器解析,得到文档
Document doc = builder.parse(is);
//获取根目录,元素
Element root = doc.getDocumentElement();
if (root == null) return;
//获取元素名字
System.out.print(root.getNodeName());
//获取元素属性name的值
System.out.println("\t" + root.getAttribute("name"));
//获取根元素下的子节点,此方法获取节点(节点包括:标签间的文本,和空白部分)
NodeList departmentNodes = root.getChildNodes();
if (departmentNodes == null) return;
//遍历节点
for (int i = 0; i < departmentNodes.getLength(); i++) {
Node department = departmentNodes.item(i);
if (department != null && department.getNodeType() == Node.ELEMENT_NODE) {//非空白文本标签
//获取节点名字
System.out.print("\t" + department.getNodeName());
//先获取节点属性集,再获取属性name的值
System.out.println("\t" + department.getAttributes().getNamedItem("name").getNodeValue());
//获取节点下面的所有子节点
NodeList employees = department.getChildNodes();
if (employees == null) continue;
for (int j = 0; j < employees.getLength(); j++) {
Node employee = employees.item(j);
if (employee != null && employee.getNodeType() == Node.ELEMENT_NODE) {
System.out.print("\t" + "\t" + employee.getNodeName());
System.out.print("\t" + employee.getAttributes().getNamedItem("id").getNodeValue());
System.out.print("\t" + employee.getAttributes().getNamedItem("name").getNodeValue());
System.out.println("\t" + employee.getTextContent().trim());
}
}
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
XML修改
新建一个TestDom的java类,里面写一个update方法,代码如下:
public static void update() {
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
try {
DocumentBuilder builder = dbf.newDocumentBuilder();
InputStream is = TestDom.class.getClassLoader().getResourceAsStream("test.xml");
Document doc = builder.parse(is);
Element root = doc.getDocumentElement();
if (root == null) return;
// 修改属性
root.setAttribute("name", "hd2");
NodeList departmentNodes = root.getChildNodes();
if (departmentNodes != null) {
for (int i = 0; i < departmentNodes.getLength() - 1; i++) {
Node department = departmentNodes.item(i);
if (department.getNodeType() == Node.ELEMENT_NODE) {
String departmentName = department.getAttributes().getNamedItem("name").getNodeValue();
if ("department3".equals(departmentName)) {
// 删除节点
root.removeChild(department);
} else if ("department2".equals(departmentName)) {
//新增节点
Element newChild = doc.createElement("employee");
newChild.setAttribute("name", "employee4");
newChild.setTextContent("44444");
department.appendChild(newChild);
}
}
}
}
TransformerFactory transFactory = TransformerFactory.newInstance();
Transformer transFormer = transFactory.newTransformer();
transFormer.setOutputProperty(OutputKeys.INDENT, "yes");
DOMSource domSource = new DOMSource(doc);
File file = new File("src/dom-test.xml");
if (file.exists()) {
file.delete();
}
file.createNewFile();
FileOutputStream out = new FileOutputStream(file);
StreamResult xmlResult = new StreamResult(out);
transFormer.transform(domSource, xmlResult);
System.out.println("修改生成文件位置===========" + file.getAbsolutePath());
} catch (Exception e) {
e.printStackTrace();
}
}
}
输出:修改生成文件位置===========D:\workspace\test-xml\src\dom-test.xml
doc-test.xml的内容:

【Java】XML解析之DOM的更多相关文章
- java xml解析方式(DOM、SAX、JDOM、DOM4J)
XML值可扩展标记语言,是用来传输和存储数据的. XMl的特定: XMl文档必须包含根元素.该元素是所有其他元素的父元素.XML文档中的元素形成了一颗文档树,树中的每个元素都可存在子元素. 所有XML ...
- Java XML解析工具 dom4j介绍及使用实例
Java XML解析工具 dom4j介绍及使用实例 dom4j介绍 dom4j的项目地址:http://sourceforge.net/projects/dom4j/?source=directory ...
- Java XML解析器
使用Apache Xerces解析XML文档 一.技术概述 在用Java解析XML时候,一般都使用现成XML解析器来完成,自己编码解析是一件很棘手的问题,对程序员要求很高,一般也没有专业厂商或者开源组 ...
- - XML 解析 总结 DOM SAX PULL MD
目录 目录 XML 解析 总结 DOM SAX PULL MD 几种解析方式简介 要解析的内容 DOM 解析 代码 输出 SAX 解析 代码 输出 JDOM 解析 代码 输出 DOM4J 解析 代码 ...
- XML概念定义以及如何定义xml文件编写约束条件java解析xml DTD XML Schema JAXP java xml解析 dom4j 解析 xpath dom sax
本文主要涉及:xml概念描述,xml的约束文件,dtd,xsd文件的定义使用,如何在xml中引用xsd文件,如何使用java解析xml,解析xml方式dom sax,dom4j解析xml文件 XML来 ...
- Java数据库编程及Java XML解析技术
1.JDBC概述 A. 什么是JDBC? Java DataBase Connectivity:是一种用于执行SQL语句的Java API,它由一组用Java语言编写的类和接口组成.通过这些类和接口 ...
- XML解析之DOM详解及与SAX解析方法的比较
XML解析(DOM) XML文件解析方法介绍 我们所用到的NSXMLParser是采用SAX方法解析 SAX(Simple API for XML) 只能读,不能修改,只能顺序访问,适合解析大型XML ...
- Python XML解析之DOM
DOM说明: DOM:Document Object Model API DOM是一种跨语言的XML解析机制,DOM把整个XML文件或字符串在内存中解析为树型结构方便访问. https://docs. ...
- XML解析(一) DOM解析
XML解析技术主要有三种: (1)DOM(Document Object Model)文档对象模型:是 W3C 组织推荐的解析XML 的一种方式,即官方的XML解析技术. (2)SAX(Simple ...
随机推荐
- hbase shell 基本命令总结
访问hbase,以及操作hbase,命令不用使用分号hbase shell 进入hbase list 查看表hbase shell -d hbase(main):024:0> scan '.ME ...
- go 的 protoc 插件调用逻辑
要让protoc使用插件,需要做下面事情: Place the plugin binary somewhere in the PATH and give it the name "proto ...
- nginx/Windows-1.9.3启动脚本
启动nginx.bat @echo off D: cd D:\Program Files\nginx-1.9.3 tasklist | findstr /i "nginx.exe" ...
- spring mvc定时任务的简单使用
版权声明:本文为楼主原创文章,未经楼主允许不得转载,如要转载请注明来源. 说起定时任务,开发的小伙伴们肯定不陌生了.有些事总是需要计算机去完成的,而不是傻傻的靠我们自己去.可是好多人对定时器总感觉很陌 ...
- Linux 相关基础笔记
html,body { } .CodeMirror { height: auto } .CodeMirror-scroll { } .CodeMirror-lines { padding: 4px 0 ...
- MVC Actionlink 参数说明
Html.ActionLink用于输出链接,以下是带参数的例子: @Html.ActionLink("编辑", "Edit", new {id= "1 ...
- teamviewer现在无法捕捉屏幕,这可能是由于快速的用户切换或远程桌面会话已经断开
解决方法: 不用远程连接过去开启teamview,直接在在电脑本机上手动开启teamview就可以了 即:如果是mstsc远程过去开启,则会有这个错误提示,需要让服务器连接显示器,手动去登录 ...
- C# 读取Excel内容
一.方法 1.OleD方法实现该功能. 2.本次随笔内容只包含读取Excel内容,并另存为. 二.代码 (1)找到文档代码 OpenFileDialog openFile = new OpenFile ...
- Python学习笔记(三)数据类型
在内存中存储的数据可以有多种类型,在Python中,能够直接处理的数据类型有以下几种: 数字(Numbers) 字符串(String) 列表(List) 元组(Tuple) 字典(Dictionary ...
- SQL 中 SELECT 语句的执行顺序
好像自已在书写 SQL 语句时由于不清楚各个关键字的执行顺序, 往往组织的 SQL 语句缺少很好的逻辑, 凭感觉 "拼凑" ( 不好意思, 如果您的 SQL 语句也经常 " ...