【Hadoop学习之六】MapReduce原理
一、概念
MapReduce:
"相同"的key为一组,调用一次reduce方法,方法内迭代这一组数据进行计算
块、分片、map、reduce、分组、分区之间对应关系
block > split
1:1:1个block可以切成1个分片
N:1:多个block可以以切成1个分片
1:N:1个block可以切成多个分片
split > map
1:1:一个分片只能产生一个map
map > reduce
N:1:多个Map可以对应一次reduce
N:N:多个Map可以对应多次reduce
1:1:1个Map可以对应1次reduce
1:N:1个Map可以对应多次reduce
group(key)>partition
1:1:1次分组可以对应1个分区
N:1:多个分组可以对应一个分区
N:N:多个分组可以对应多个分区
1:N? >违背了原语
partition > outputfile

MapTAsk:
(1)对于一个分片,加载到内存进行Map处理,
(2)Map业务逻辑将分片中数据处理成一个个的K,V键值对
(3)将Map输出的K,V键值对加工,生成含有分区partition的K,V,P键值对
(4)经过一段时间的处理,将生成的KVP数据放到缓存里(默认100M),然后按照分区P,键key排序,最终形成一个内部有序外部无序的100M文件
(5)将这个100M缓存输出到本地文件系统里,经过map处理完成后,最终生成一堆这样的小文件
(6)将这一堆小文件进行归并形成一个内部有序外部无序的大文件

ReduceTask:
(1)将各个节点归并后的大文件中拉取(shuffler)属于同一分区的文件
这个地方会产生网络IO,map之后的文件如果很大会影响性能,因此可以对map之后的数据进行简单统计 降低拉取文件的大小
(2)将拉过来的小文件进行归并,reduce的归并强依赖map的排序结果
(3)将合并的文件调用reduce
二、Hadoop整体协作
Hadoop 1.x
1、客户端clients先启动,计算切片清单,
2、客户端将MR jar包、切片清单、配置文件等作业资源上传HDFS;
3、客户端提交任务给Job Tracker
4、Job Tracker从HDFS获取切片清单,参考Task Tracker上的资源负载情况,规划Map、Reduce任务去到的节点
5、Task Tracker通过与Job Tracker心跳,获取属于自己的任务清单
6、Task Tracker从HDFS上获取切片清单、jar、配置,map运行map任务,Reduce运行Reduce任务,
7、Reduce任务将生成结果文件返回给HDFS
8、客户端通过HDFS下载文件 查看结果
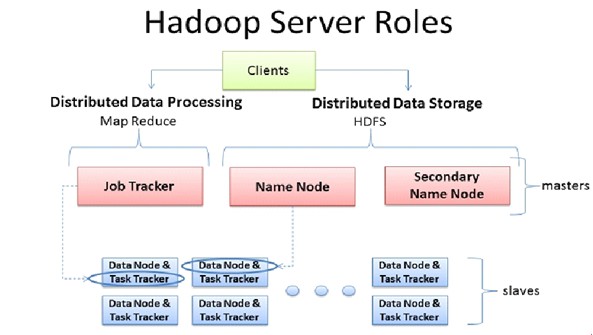

弊端:Job Tracker有两件事:任务调度和监控整个集群资源负载,存在单点故障、负载过重、资源管理和计算调度强耦合
因此有了Hadoop 2.x的YARN
【Hadoop学习之六】MapReduce原理的更多相关文章
- hadoop学习(七)----mapReduce原理以及操作过程
前面我们使用HDFS进行了相关的操作,也了解了HDFS的原理和机制,有了分布式文件系统我们如何去处理文件呢,这就的提到hadoop的第二个组成部分-MapReduce. MapReduce充分借鉴了分 ...
- hadoop笔记之MapReduce原理
MapReduce原理 MapReduce原理 简单来说就是,一个大任务分成多个小的子任务(map),并行执行后,合并结果(reduce). 例子: 100GB的网站访问日志文件,找出访问次数最多的I ...
- [Hadoop]浅谈MapReduce原理及执行流程
MapReduce MapReduce原理非常重要,hive与spark都是基于MR原理 MapReduce采用多进程,方便对每个任务资源控制和调配,但是进程消耗更多的启动时间,因此MR时效性不高.适 ...
- Hadoop学习笔记—MapReduce的理解
我不喜欢照搬书上的东西,我觉得那样写个blog没多大意义,不如直接把那本书那一页告诉大家,来得省事.我喜欢将我自己的理解.所以我会说说我对于Hadoop对大量数据进行处理的理解.如果有理解不对欢迎批评 ...
- Hadoop学习之Mapreduce执行过程详解
一.MapReduce执行过程 MapReduce运行时,首先通过Map读取HDFS中的数据,然后经过拆分,将每个文件中的每行数据分拆成键值对,最后输出作为Reduce的输入,大体执行流程如下图所示: ...
- 【尚学堂·Hadoop学习】MapReduce案例2--好友推荐
案例描述 根据好友列表,推荐好友的好友 数据集 tom hello hadoop cat world hadoop hello hive cat tom hive mr hive hello hive ...
- 【尚学堂·Hadoop学习】MapReduce案例1--天气
案例描述 找出每个月气温最高的2天 数据集 -- :: 34c -- :: 38c -- :: 36c -- :: 32c -- :: 37c -- :: 23c -- :: 41c -- :: 27 ...
- hadoop学习day3 mapreduce笔记
1.对于要处理的文件集合会根据设定大小将文件分块,每个文件分成多块,不是把所有文件合并再根据大小分块,每个文件的最后一块都可能比设定的大小要小 块大小128m a.txt 120m 1个块 b.txt ...
- Hadoop学习(3)-mapreduce快速入门加yarn的安装
mapreduce是一个运算框架,让多台机器进行并行进行运算, 他把所有的计算都分为两个阶段,一个是map阶段,一个是reduce阶段 map阶段:读取hdfs中的文件,分给多个机器上的maptask ...
随机推荐
- Eclipse实用小插件
MyBatipse插件 描述 用于mybatis的Dao层或者mapper层的方法直接跳到对应的xml文件对应的方法 安装 进入IDE(eclipse)的Help——>Install New S ...
- 【Python基础】Pycharm默认快捷键
PyCharm常用快捷键和设置 代码快速运行: Alt+Shift+F10 编辑代码的时候经常的要换下一行,但是光标没有在行末,可以用这个命令直接换行: Shift+Enter 行注释/取消行注释: ...
- 01.jupyter环境安装
jupyter notebook环境安装 一.什么是Jupyter Notebook? 1. 简介 Jupyter Notebook是基于网页的用于交互计算的应用程序.其可被应用于全过程计算:开发.文 ...
- [转载]智能科普:VR、AR、MR的区别
智能科普:VR.AR.MR的区别 http://news.zol.com.cn/553/5534833.html news.zol.com.cn 2015-11-23 16:00 近日, 获得谷歌5亿 ...
- 字符集更改步骤,mysql乱码
关键字:Mysql乱码,mysql字符集修改 #字符集更改步骤~
- mysql 权限管理 目录
mysql 权限管理介绍 mysql 权限管理 记录 mysql 权限管理 grant 命令 mysql 权限管理 revoke 回收权限 命令 mysql 权限管理 针对库 授权 db.* mysq ...
- [MySQL优化2]不用SELECT * FROM table;
假设有一张employees表,它有8列:员工人数,姓氏,名字,分机,电子邮件,办公室代码,报告,职位等.如果要仅查看员工的名字,姓氏和职位,请使用以下查询:SELECT lastname, firs ...
- Scala的apply unapply unapplySeq 语法糖
apply 可以理解为注入 unapply unapplySeq 可以理解为提取 apply 与 unapply 虽然名字相近,但是使用起来区别挺大.apply有点像构造函数unapply主要是结合模 ...
- [LeetCode] 1. Two Sum_Easy
Given an array of integers, return indices of the two numbers such that they add up to a specific ta ...
- zyb的面试(广工14届比赛)
这道题目在上半年ZOJ模拟上年青岛赛区ACM题的时候就已经出现了.当时我不会写,本来想着赛后补题的最后因为懒惰又没补. 现在这道题又出现了.这是上天对我的惩罚啊!!! 所以这次铁了心也要补这题.然后我 ...