Structured Streaming教程(1) —— 基本概念与使用
近年来,大数据的计算引擎越来越受到关注,spark作为最受欢迎的大数据计算框架,也在不断的学习和完善中。在Spark2.x中,新开放了一个基于DataFrame的无下限的流式处理组件——Structured Streaming,它也是本系列的主角,废话不多说,进入正题吧!
简单介绍
在有过1.6的streaming和2.x的streaming开发体验之后,再来使用Structured Streaming会有一种完全不同的体验,尤其是在代码设计上。
在过去使用streaming时,我们很容易的理解为一次处理是当前batch的所有数据,只要针对这波数据进行各种处理即可。如果要做一些类似pv uv的统计,那就得借助有状态的state的DStream,或者借助一些分布式缓存系统,如Redis、Alluxio都能实现。需要关注的就是尽量快速的处理完当前的batch数据,以及7*24小时的运行即可。
可以看到想要去做一些类似Group by的操作,Streaming是非常不便的。Structured Streaming则完美的解决了这个问题。
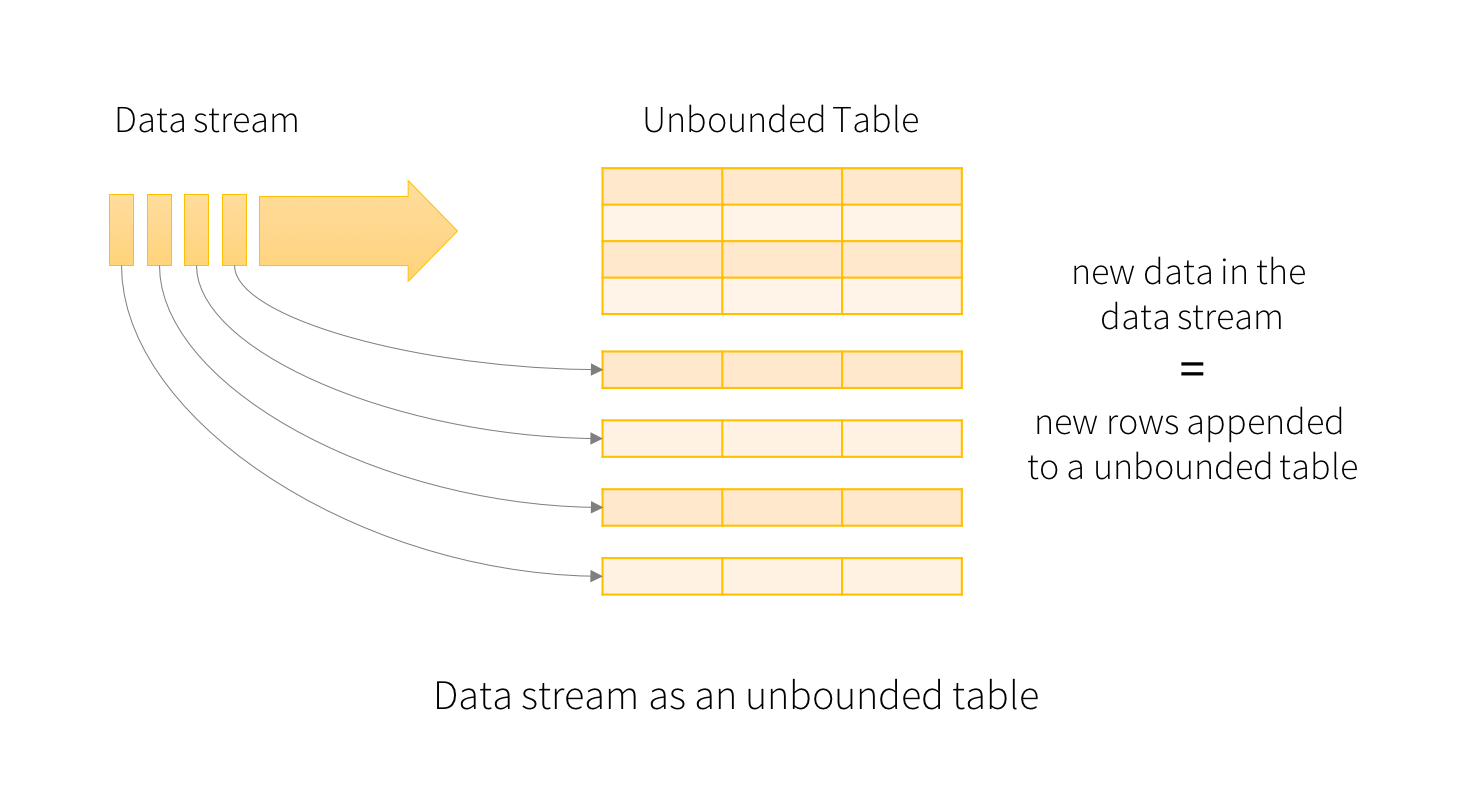
在Structured Streaming中,把源源不断到来的数据通过固定的模式“追加”或者“更新”到了上面无下限的DataFrame中。剩余的工作则跟普通的DataFrame一样,可以去map、filter,也可以去groupby().count()。甚至还可以把流处理的dataframe跟其他的“静态”DataFrame进行join。另外,还提供了基于window时间的流式处理。总之,Structured Streaming提供了快速、可扩展、高可用、高可靠的流式处理。
小栗子
在大数据开发中,Word Count就是基本的演示示例,所以这里也模仿官网的例子,做一下演示。
直接看一下完整的例子:
package xingoo.sstreaming
import org.apache.spark.sql.SparkSession
object WordCount {
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder
.master("local")
.appName("StructuredNetworkWordCount")
.getOrCreate()
spark.sparkContext.setLogLevel("WARN")
import spark.implicits._
// 创建DataFrame
// Create DataFrame representing the stream of input lines from connection to localhost:9999
val lines = spark.readStream
.format("socket")
.option("host", "localhost")
.option("port", 9999)
.load()
// Split the lines into words
val words = lines.as[String].flatMap(_.split(" "))
// Generate running word count
val wordCounts = words.groupBy("value").count()
// Start running the query that prints the running counts to the console
// 三种模式:
// 1 complete 所有内容都输出
// 2 append 新增的行才输出
// 3 update 更新的行才输出
val query = wordCounts.writeStream
.outputMode("complete")
.format("console")
.start()
query.awaitTermination()
}
}
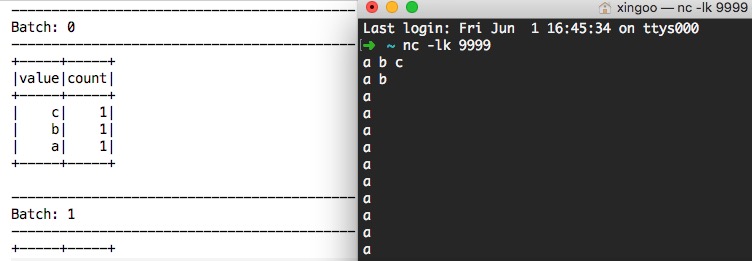
效果就是在控制台输入nc -lk 9999,然后输入一大堆的字符,控制台就输出了对应的结果:
然后来详细看一下代码:
val spark = SparkSession
.builder
.master("local")
.appName("StructuredNetworkWordCount")
.getOrCreate()
spark.sparkContext.setLogLevel("WARN")
import spark.implicits._
上面就不用太多解释了吧,创建一个本地的sparkSession,设置日志的级别为WARN,要不控制台太乱。然后引入spark sql必要的方法(如果没有import spark.implicits._,基本类型是无法直接转化成DataFrame的)。
val lines = spark.readStream
.format("socket")
.option("host", "localhost")
.option("port", 9999)
.load()
创建了一个Socket连接的DataStream,并通过load()方法获取当前批次的DataFrame。
val words = lines.as[String].flatMap(_.split(" "))
val wordCounts = words.groupBy("value").count()
先把DataFrame转成单列的DataSet,然后通过空格切分每一行,再根据value做groupby,并统计个数。
val query = wordCounts.writeStream
.outputMode("complete")
.format("console")
.start()
调用DataFrame的writeStream方法,转换成输出流,设置模式为"complete",指定输出对象为控制台"console",然后调用start()方法启动计算。并返回queryStreaming,进行控制。
这里的outputmode和format都会后续详细介绍。
query.awaitTermination()
通过QueryStreaming的对象,调用awaitTermination阻塞主线程。程序就可以不断循环调用了。
观察一下Spark UI,可以发现程序稳定的在运行~

总结
这就是一个最基本的wordcount的例子,想象一下,如果没有Structured Streaming,想要统计全局的wordcount,还是很费劲的(即便使用streaming的state,其实也不是那么好用的)。
Structured Streaming教程(1) —— 基本概念与使用的更多相关文章
- Structured Streaming教程(2) —— 常用输入与输出
上篇了解了一些基本的Structured Streaming的概念,知道了Structured Streaming其实是一个无下界的无限递增的DataFrame.基于这个DataFrame,我们可以做 ...
- Structured Streaming教程(3) —— 与Kafka的集成
Structured Streaming最主要的生产环境应用场景就是配合kafka做实时处理,不过在Strucured Streaming中kafka的版本要求相对搞一些,只支持0.10及以上的版本. ...
- Spark Streaming揭秘 Day29 深入理解Spark2.x中的Structured Streaming
Spark Streaming揭秘 Day29 深入理解Spark2.x中的Structured Streaming 在Spark2.x中,Spark Streaming获得了比较全面的升级,称为St ...
- Structured Streaming Programming Guide结构化流编程指南
目录 Overview Quick Example Programming Model Basic Concepts Handling Event-time and Late Data Fault T ...
- DataFlow编程模型与Spark Structured streaming
流式(streaming)和批量( batch):流式数据,实际上更准确的说法应该是unbounded data(processing),也就是无边界的连续的数据的处理:对应的批量计算,更准确的说法是 ...
- Structured Streaming编程向导
简介 Structured Streaming is a scalable and fault-tolerant stream processing engine built on the Spark ...
- 浅谈Spark2.x中的Structured Streaming
在Spark2.x中,Spark Streaming获得了比较全面的升级,称为Structured Streaming,和之前的很不同,功能更强大,效率更高,跟其他的组件整合性也更好. 连续应用程序c ...
- Apache Spark 2.2.0 中文文档 - Structured Streaming 编程指南 | ApacheCN
Structured Streaming 编程指南 概述 快速示例 Programming Model (编程模型) 基本概念 处理 Event-time 和延迟数据 容错语义 API 使用 Data ...
- Spark之Structured Streaming
目录 Part V. Streaming Stream Processing Fundamentals Structured Streaming Basics Event-Time and State ...
随机推荐
- nginx访问报错403 is forbidden
由于开发需要,在本地环境中配置了nginx环境,使用的是Centos 6.5 的yum安装,安装一切正常,于是把网站文件用mv命令移动到了新的目录,并相应修改了配置文件,并重启Nginx. 重启就报个 ...
- Day5-----------------vi编辑器
1.操作模式 1).命令行模式 2).编辑模式 3).扩展模式 2.命令行模式 1).删除与复制 dd 删除光标所在行 ndd 删除光标向下n行 yy 复制光标所在行 nyy 复制光标乡下n行 2). ...
- fatal error: google/protobuf/arena.h:没有那个文件或目录
安装caffe时make all会出现这个错误,按照https://github.com/BVLC/caffe/issues/4988说法,可能时libprotobuf-dev过时了,需要从源码重新变 ...
- CPU密集型 VS IO密集型
CPU密集型 CPU密集型也叫计算密集型,指的是系统的硬盘.内存性能相对CPU要好很多,此时,系统运作大部分的状况是CPU Loading 100%,CPU要读/写I/O(硬盘/内存),I/O在很短的 ...
- vue-cli之webpack的proxyTable无效的解决方案
最近遇到这个需要单页访问跨域后台的问题 可以按照如下设置: proxyTable: { '/list': { target: 'http://api.xxxxxxxx.com', pathRewrit ...
- Windows Mac地址伪装步骤
本文介绍Windows上Mac地址修改方法,适用于网络环境绑定了Mac地址需要修改上网的情况. 工具/原料 PC电脑一台 Windows系统 方法/步骤 点击右下角图标. 点击打开网络和共享中心. 点 ...
- VIM 报错
syntax error: unexpected end of file if 没配对 在最后加 fi 试试 环境变量用不了 export PATH=/usr/bin:/usr/sbin:/bin:/ ...
- Spring 核心API
BeanFactory: 这是一个工厂,用于生产任意Bean,采用延迟加载,第一次getBean时才会加载 ApplicationContext: 是BeanFactory的一个子接口,功能更强大(国 ...
- ubuntu 12.04 安装 openssh-server 失败,请问怎么该弄?
$ sudo apt-get install openssh-server Reading package lists... Done Building dependency tree Reading ...
- 【C++ Primer 第11章】2. 关联容器操作
练习答案 一.访问元素 关联容器额外类型别名 key_type 此容器类型的关键字类型 mapped_type 每个关键字关联的类型,只 适用于map mapped_type 对于set,与key_ ...