Tensorflow实现手写体分类(含dropout)
一、手写体分类
1. 数据集
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
import os os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
config = tf.ConfigProto(allow_soft_placement = True)
gpu_options = tf.GPUOptions(per_process_gpu_memory_fraction = 0.33)
config.gpu_options.allow_growth = True max_steps = 20 # 最大迭代次数
learning_rate = 0.001 # 学习率
dropout = 0.9 # dropout时随机保留神经元的比例
data_dir = '.\MNIST_DATA' # 样本数据存储的路径
log_dir = 'E:\MNIST_LOG' # 输出日志保存的路径 # 获取数据集,并采用采用one_hot热编码
mnist = input_data.read_data_sets(data_dir,one_hot = True)
# mnist=input_data.read_data_sets('MNIST_data',one_hot=True) '''下载数据是直接调用了tensorflow提供的函数read_data_sets,输入两个参数,
第一个是下载到数据存储的路径,第二个one_hot表示是否要将类别标签进行独热编码。
它首先回去找制定目录下有没有这个数据文件,没有的话才去下载,有的话就直接读取。
所以第一次执行这个命令,速度会比较慢。''' # sess = tf.InteractiveSession(config = config)
下面的图是通过调用 tf.summary.image('input', image_shaped_input, 10)得到的,具体见2.初始化参数

2. 初始化参数
with tf.name_scope('input'):
x = tf.placeholder(tf.float32, [None, 784], name='x-input')
y_ = tf.placeholder(tf.float32, [None, 10], name='y-input')
# 保存图像信息
with tf.name_scope('input_reshape'):
image_shaped_input = tf.reshape(x, [-1, 28, 28, 1])
tf.summary.image('input', image_shaped_input, 10)
# 初始化权重参数
def weight_variable(shape):
initial = tf.truncated_normal(shape, stddev = 0.1)
return tf.Variable(initial)
# 初始化偏执参数
def bias_variable(shape):
initial = tf.constant(0.1, shape = shape)
return tf.Variable(initial)
# 绘制参数变化
def variable_summaries(var):
with tf.name_scope('summaries'):
# 计算参数的均值,并使用tf.summary.scaler记录
mean = tf.reduce_mean(var)
tf.summary.scalar('mean', mean)
# 计算参数的标准差
with tf.name_scope('stddev'):
stddev = tf.sqrt(tf.reduce_mean(tf.square(var - mean)))
# 使用tf.summary.scaler记录下标准差,最大值,最小值
tf.summary.scalar('stddev', stddev)
tf.summary.scalar('max', tf.reduce_max(var))
tf.summary.scalar('min', tf.reduce_min(var))
# 用直方图记录参数的分布
tf.summary.histogram('histogram', var)
第一层的weight和biases的变化情况
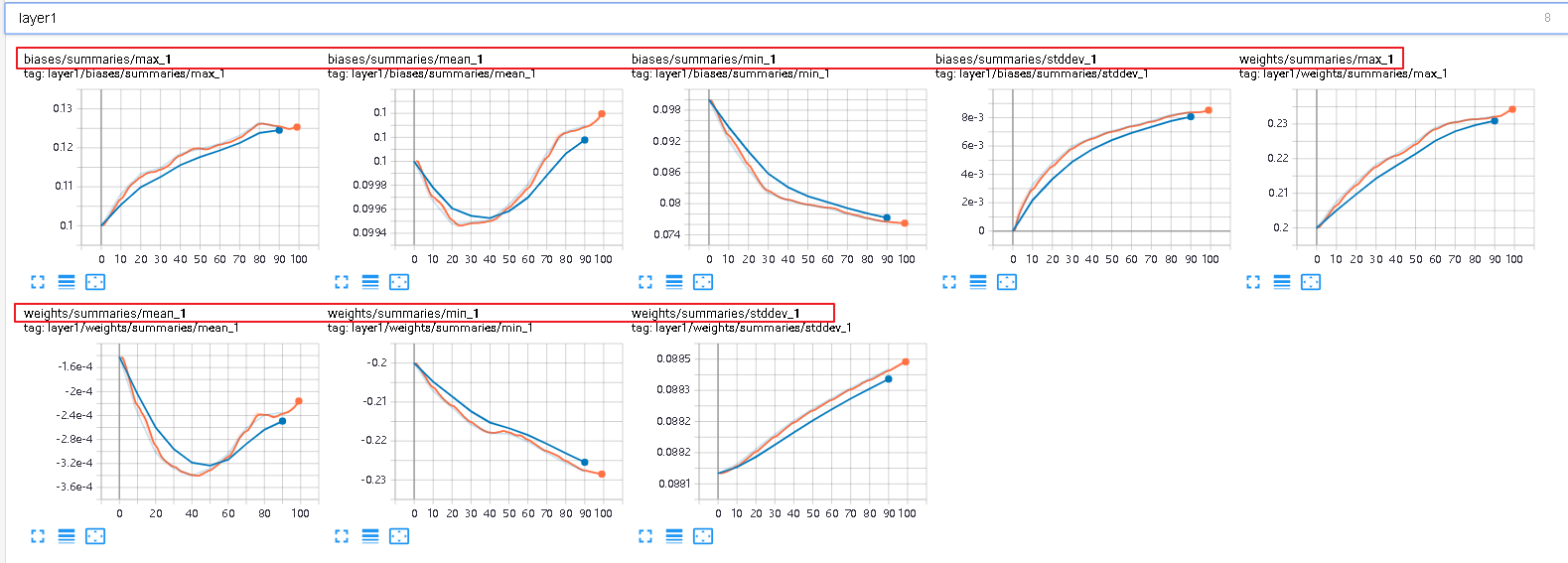
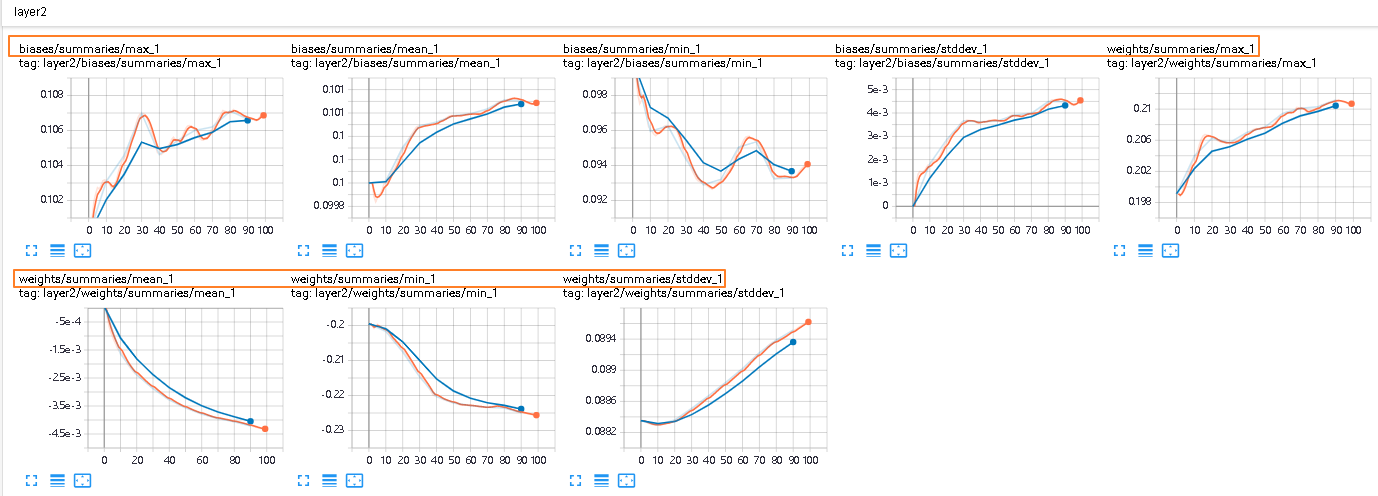
第二层的weight和biases的变化情况
3. 构建神经网络
下面是单层神经网络模型
# 构建神经网络
def nn_layer(input_tensor, input_dim, output_dim, layer_name, act=tf.nn.relu):
# 设置命名空间
with tf.name_scope(layer_name):
# 调用之前的方法初始化权重w,并且调用参数信息的记录方法,记录w的信息
with tf.name_scope('weights'):
weights = weight_variable([input_dim, output_dim])
variable_summaries(weights)
# 调用之前的方法初始化权重b,并且调用参数信息的记录方法,记录b的信息
with tf.name_scope('biases'):
biases = bias_variable([output_dim])
variable_summaries(biases)
# 执行wx+b的线性计算,并且用直方图记录下来
with tf.name_scope('linear_compute'):
preactivate = tf.matmul(input_tensor, weights) + biases
tf.summary.histogram('linear', preactivate)
# 将线性输出经过激励函数,并将输出也用直方图记录下来
activations = act(preactivate, name='activation')
tf.summary.histogram('activations', activations)
# 返回激励层的最终输出
return activations
下面要建双层神经网络,第一层加dropout
hidden1 = nn_layer(x, 784, 500, 'layer1') # 创建dropout层
with tf.name_scope('dropout'):
keep_prob = tf.placeholder(tf.float32)
tf.summary.scalar('dropout_keep_probability', keep_prob)
dropped = tf.nn.dropout(hidden1, keep_prob) y = nn_layer(dropped, 500, 10, 'layer2', act=tf.identity)
模型图如下:
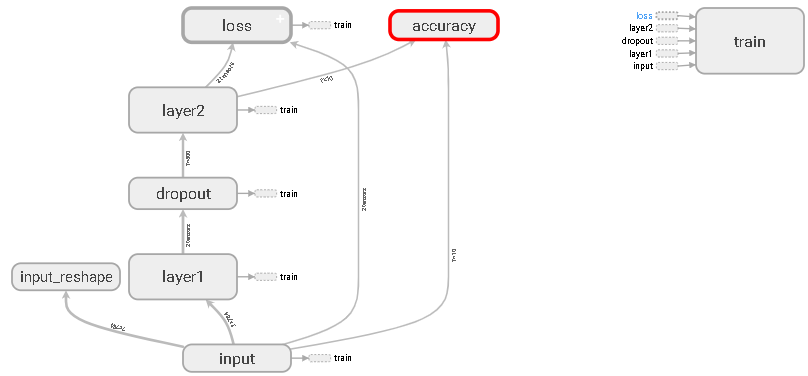
dropout变化如下:

第一层和第二层的weights、bias、未激活前,激活后的值分布如下:

tf.summary.histogram接受任意大小和形状的张量,并将该张量压缩成一个由许多分箱组成的直方图数据结构,这些分箱有各种宽度和计数。例如,假设我们要将数字 [0.5, 1.1, 1.3, 2.2, 2.9, 2.99] 整理到不同的分箱中,我们可以创建三个分箱: * 一个分箱包含 0 到 1 之间的所有数字(会包含一个元素:0.5), * 一个分箱包含 1 到 2 之间的所有数字(会包含两个元素:1.1 和 1.3), * 一个分箱包含 2 到 3 之间的所有数字(会包含三个元素:2.2、2.9 和 2.99)。TensorFlow 使用类似的方法创建分箱,但与我们的示例不同,它不创建整数分箱。对于大型稀疏数据集,可能会导致数千个分箱。相反,这些分箱呈指数分布,许多分箱接近 0,有较少的分箱的数值较大。 然而,将指数分布的分箱可视化是非常艰难的。如果将高度用于为计数编码,那么即使元素数量相同,较宽的分箱所占的空间也越大。反过来推理,如果用面积为计数编码,则使高度无法比较。因此,直方图会将数据重新采样并分配到统一的分箱。很不幸,在某些情况下,这可能会造成假象。
直方图可视化工具中的每个切片显示单个直方图。切片是按步骤整理的;较早的切片(如,步骤 0)位于较“靠后”的位置,颜色也较深,而较晚的切片则靠近前景,颜色也较浅。右侧的 y 轴显示步骤编号。
举例:下图表示时间步骤76,对应的直方图的分箱位于0.0695附近,分箱中有712个元素

切换historm到覆盖模式
信息中心左侧有一个控件,可以将直方图模式从“偏移”切换到“覆盖”:在“偏移”模式下,可视化旋转 45 度,以便各个直方图切片不再按时间展开,而是全部绘制在相同的 y 轴上。
现在,每个切片都是图表上的一条单独线条,y 轴显示的是每个分箱内的项目数。颜色较深的线条表示较早的步,而颜色较浅的线条表示较晚的步。同样,可以将鼠标悬停在图表上以查看其他一些信息。

4. 损失函数+优化器
# 创建损失函数
with tf.name_scope('loss'):
# 计算交叉熵损失(每个样本都会有一个损失)
diff = tf.nn.softmax_cross_entropy_with_logits_v2(labels=y_, logits=y)
with tf.name_scope('total'):
# 计算所有样本交叉熵损失的均值
cross_entropy = tf.reduce_mean(diff)
tf.summary.scalar('loss', cross_entropy) # 使用AdamOptimizer优化器训练模型,最小化交叉熵损失
with tf.name_scope('train'):
train_step = tf.train.AdamOptimizer(learning_rate).minimize(cross_entropy) # 计算准确率
with tf.name_scope('accuracy'):
with tf.name_scope('correct_prediction'):
# 分别将预测和真实的标签中取出最大值的索引,弱相同则返回1(true),不同则返回0(false)
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1))
with tf.name_scope('accuracy'):
# 求均值即为准确率
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32)) tf.summary.scalar('accuracy', accuracy)
5. 训练
sess = tf.Session()
#summaries合并
merged = tf.summary.merge_all()
# 写到指定的磁盘路径中
train_writer = tf.summary.FileWriter(log_dir + '/train', sess.graph)
test_writer = tf.summary.FileWriter(log_dir + '/test',sess.graph) #运行初始化所有变量
# global_variables_initializer().run()
sess.run(tf.global_variables_initializer()) def feed_dict(train):
"""Make a TensorFlow feed_dict: maps data onto Tensor placeholders."""
if train:
xs, ys = mnist.train.next_batch(10)
k = dropout
else:
xs, ys = mnist.test.images[:100], mnist.test.labels[:100]
k = 1.0
return {x: xs, y_: ys, keep_prob: k} for i in range(100):
if i % 10 == 0: #记录测试集的summary与accuracy
summary, acc = sess.run([merged, accuracy], feed_dict=feed_dict(False))
test_writer.add_summary(summary, i)
print('Accuracy at step %s: %s' % (i, acc))
else: # 记录训练集的summary
summary, _ = sess.run([merged, train_step], feed_dict=feed_dict(True))
train_writer.add_summary(summary, i) train_writer.close()
test_writer.close()
准确率:

损失函数:
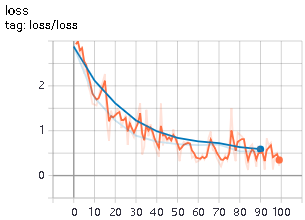
参考文献:
【1】莫烦Python
Tensorflow实现手写体分类(含dropout)的更多相关文章
- 芝麻HTTP:TensorFlow LSTM MNIST分类
本节来介绍一下使用 RNN 的 LSTM 来做 MNIST 分类的方法,RNN 相比 CNN 来说,速度可能会慢,但可以节省更多的内存空间. 初始化 首先我们可以先初始化一些变量,如学习率.节点单元数 ...
- SVM原理以及Tensorflow 实现SVM分类(附代码)
1.1. SVM介绍 1.2. 工作原理 1.2.1. 几何间隔和函数间隔 1.2.2. 最大化间隔 - 1.2.2.0.0.1. \(L( {x}^*)\)对$ {x}^*$求导为0 - 1.2.2 ...
- tensorflow实现二分类
读万卷书,不如行万里路.之前看了不少机器学习方面的书籍,但是实战很少.这次因为项目接触到tensorflow,用一个最简单的深层神经网络实现分类和回归任务. 首先说分类任务,分类任务的两个思路: 如果 ...
- tensorflow学习笔记————分类MNIST数据集
在使用tensorflow分类MNIST数据集中,最容易遇到的问题是下载MNIST样本的问题. 一般是通过使用tensorflow内置的函数进行下载和加载, from tensorflow.examp ...
- 使用TensorFlow给花朵🌺分类
第一步:准备好需要的库 tensorflow-gpu 1.8.0 opencv-python 3.3.1 numpy skimage os pillow 第二步:准备数据集: 链接:http ...
- 用 TensorFlow 实现 SVM 分类问题
这篇文章解释了底部链接的代码. 问题描述  如上图所示,有一些点位于单位正方形内,并做好了标记.要求找到一条线,作为分类的标准.这些点的数据在 inearly_separable_data.csv ...
- TF Boys (TensorFlow Boys ) 养成记(四):TensorFlow 简易 CIFAR10 分类网络
前面基本上把 TensorFlow 的在图像处理上的基础知识介绍完了,下面我们就用 TensorFlow 来搭建一个分类 cifar10 的神经网络. 首先准备数据: cifar10 的数据集共有 6 ...
- tensorflow 教程 文本分类 IMDB电影评论
昨天配置了tensorflow的gpu版本,今天开始简单的使用一下 主要是看了一下tensorflow的tutorial 里面的 IMDB 电影评论二分类这个教程 教程里面主要包括了一下几个内容:下载 ...
- 基于tensorflow的文本分类总结(数据集是复旦中文语料)
代码已上传到github:https://github.com/taishan1994/tensorflow-text-classification 往期精彩: 利用TfidfVectorizer进行 ...
随机推荐
- Maven Web项目部署到Tomcat下问题
但是也遇到了很多问题,下面记录一下Web项目部署到Tomcat下的问题 1.普通的WEB项目,就是虽然是用maven搭建的,但是没有使用profiles.xml文件来配置参数.这样的项目可以通过以下的 ...
- 实际体验 .NET Standard 2.0 的魅力
在我们的 .net core 大迁移工程中,有些项目完成了迁移,有些还未迁移,这就带来了一个烦恼——我们自己开发的公用类库如何在 .net core 与 .net framework 项目中共享?如果 ...
- python中的日志,logger用法
python中自带logger模块,实现方法有两种,一般使用第二种,更灵活 方法一: import logging # 通过logging.basicConfig完成 logging.basicCon ...
- 运行gedit报No protocol specified
No protocol specifiedxhost: unable to open display ":0" 这是因为在Xserver默认情况下,不允许Linux非当前登录用户( ...
- sql join 语句的小总结
CREATE TABLE Persons ( id INT PRIMARY KEY, LastName CHAR() NOT NULL, FirstName VARCHAR (), address V ...
- NLP去特殊字符
在自然语言处理中,我们有时对文本进行处理,需要去除一些特殊符号,保留中文,这是在预处理过程中常用到的.分享给你,希望对你有帮助! import re def delete_sysbol(line): ...
- 一道hive SQL面试题
一.hive中实现方法 基表: 组表: gt gid gname 1001 g1 1002 g2 1003 g3 create table g( gid int, gname string )ro ...
- 一些shell默认的变量
测试脚本如下,我这里主要想测试$0,$1,$2,$n,$@,$*默认都代表了什么? #!/bin/sh echo '$1='$1 echo '$2='$2 echo '$@='$@ echo '$*= ...
- Exception 06 : org.hibernate.NonUniqueObjectException: A different object with the same identifier value was already associated with the session :
异常名称: org.hibernate.NonUniqueObjectException: A different object with the same identifier value was ...
- [daily] 使用左右对比查看diff 格式的文件
如题: Given your references to Vim in the question, I'm not sure if this is the answer you want :) but ...