embedding与word2vec
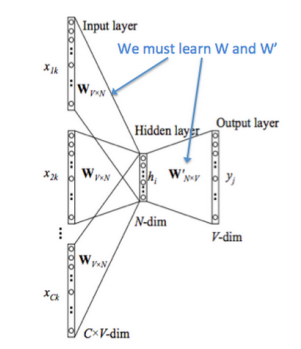
embedding与word2vec的更多相关文章
- Embedding和Word2Vec实战
在之前的文章中谈到了文本向量化的一些基本原理和概念,本文将介绍Word2Vec的代码实现 https://www.cnblogs.com/dogecheng/p/11470196.html#Word2 ...
- Word Embedding与Word2Vec
http://blog.csdn.net/baimafujinji/article/details/77836142 一.数学上的“嵌入”(Embedding) Embed这个词,英文的释义为, fi ...
- 无所不能的Embedding 1 - Word2vec模型详解&代码实现
word2vec是google 2013年提出的,从大规模语料中训练词向量的模型,在许多场景中都有应用,信息提取相似度计算等等.也是从word2vec开始,embedding在各个领域的应用开始流行, ...
- word2vec和word embedding有什么区别?
word2vec和word embedding有什么区别? 我知道这两个都能将词向量化,但有什么区别?这两个术语的中文是什么? from: https://www.zhihu.com/question ...
- 学习笔记CB011:lucene搜索引擎库、IKAnalyzer中文切词工具、检索服务、查询索引、导流、word2vec
影视剧字幕聊天语料库特点,把影视剧说话内容一句一句以回车换行罗列三千多万条中国话,相邻第二句很可能是第一句最好回答.一个问句有很多种回答,可以根据相关程度以及历史聊天记录所有回答排序,找到最优,是一个 ...
- Word Embedding理解
一直以来感觉好多地方都吧Word Embedding和word2vec混起来一起说,所以导致对这俩的区别不是很清楚. 其实简单说来就是word embedding包含了word2vec,word2ve ...
- tensorflow加载embedding模型进行可视化
1.功能 采用python的gensim模块训练的word2vec模型,然后采用tensorflow读取模型可视化embedding向量 ps:采用C++版本训练的w2v模型,python的gensi ...
- PaperWeekly 第五期------从Word2Vec到FastText
PaperWeekly 第五期------从Word2Vec到FastText 张俊 10 个月前 引 Word2Vec从提出至今,已经成为了深度学习在自然语言处理中的基础部件,大大小小.形形色色的D ...
- 无所不能的embedding 3. word2vec->Doc2vec[PV-DM/PV-DBOW]
这一节我们来聊聊不定长的文本向量,这里我们暂不考虑有监督模型,也就是任务相关的句子表征,只看通用文本向量,根据文本长短有叫sentence2vec, paragraph2vec也有叫doc2vec的. ...
随机推荐
- PTA L2-001 紧急救援
题目链接:https://pintia.cn/problem-sets/994805046380707840/problems/994805073643683840 输入: 输入第一行给出4个正整数N ...
- 有一个问题关于stl函数中的算法问题
是不是stl中的算法函数中参数只要是和函数相关的就是函数对象和谓词?
- H5 DeviceMotionEvent 事件制作“摇一摇效果”
摇一摇”的效果制作主要依赖于H5的deviceMotionEvent事件 先讲怎么使用,具体的原理在后边补充 第一步:捕捉重力加速度 var acceleration = eventData.acce ...
- IDEA上传一个项目到github
IDEA上传一个项目到github 只要3步 1. 2. 3. 4. 5.查看页面 上传成功... 详情: https://blog.csdn.net/qq_27093465/article/d ...
- SSL证书读取
证书内容: MIIDhDCCAmygAwIBAgIFAV0Imw0wDQYJKoZIhvcNAQELBQAwXDEnMCUGA1UEAwweczUwLTYyLTEzNS0xNS5zZWN1cmVzZX ...
- AIX 5335端口IBM WebSphere应用服务器关闭连接信息泄露漏洞的修复
今天按要求协助进行漏洞修复,有个“IBM WebSphere应用服务器关闭连接信息泄露漏洞”,一直没太搞清是不是没打补丁引起的问题. 感觉同样的安装有的报这漏洞有的不报,而报的有的是应用端口,有时是控 ...
- css 让div 的高度和屏幕的高度一样
<html><head><title>无标题文档</title><style type="text/css">html, ...
- mysql迁移到ubuntu遇到到问题
1.表名大小写敏感,linux下到mysql: 数据库名与表名是严格区分大小写的: 表的别名是严格区分大小写的: 列名与列的别名在所有的情况下均是忽略大小写的: 变量名也是严格区分大小写的. 修改方法 ...
- react router @4 和 vue路由 详解(一)vue路由基础和使用
完整版:https://www.cnblogs.com/yangyangxxb/p/10066650.html 1.vue路由基础和使用 a.大概目录 我这里建了一个router文件夹,文件夹下有in ...
- js 日期格式化函数(可自定义)
js 日期格式化函数 DateFormat var DateFormat = function (datetime, formatStr) { var dat = datetime; var str ...