python爬虫之反爬虫(随机user-agent,获取代理ip,检测代理ip可用性)
python爬虫之反爬虫(随机user-agent,获取代理ip,检测代理ip可用性)
目录
随机User-Agent 获取代理ip 检测代理ip可用性
随机User-Agent
fake_useragent库,伪装请求头
from fake_useragent import UserAgent ua = UserAgent()
# ie浏览器的user agent
print(ua.ie) # opera浏览器
print(ua.opera) # chrome浏览器
print(ua.chrome) # firefox浏览器
print(ua.firefox) # safri浏览器
print(ua.safari) # 最常用的方式
# 写爬虫最实用的是可以随意变换headers,一定要有随机性。支持随机生成请求头
print(ua.random)
print(ua.random)
print(ua.random)
获取代理ip
在免费的代理网站爬取代理ip,免费代理的采集也很简单,无非就是:访问页面页面 —> 正则/xpath提取 —> 保存
代理ip网站
有代理:https://www.youdaili.net/Daili/guonei/
66代理:http://www.66ip.cn/6.html
西刺代理:https://www.xicidaili.com/
快代理:https://www.kuaidaili.com/free/
#根据网页结果,适用正则表达式匹配
#这种方法适合翻页的网页
import re
import requests
import time def get_ip():
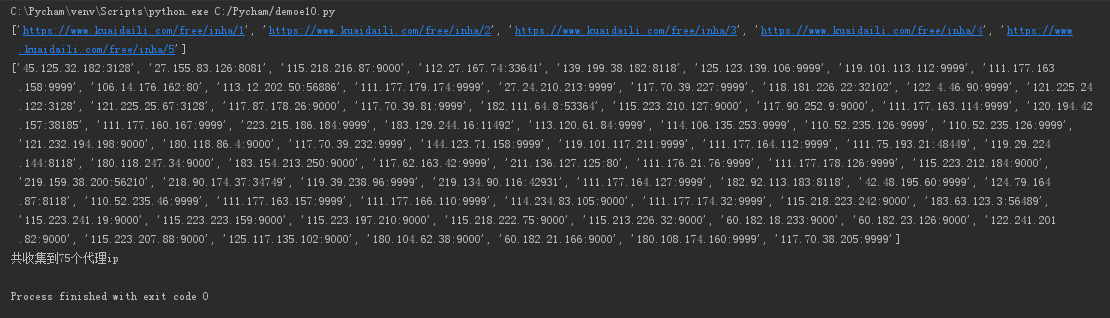
url='https://www.kuaidaili.com/free/inha/'
url_list=[url+str(i+1) for i in range(5)] #生成url列表,5代表只爬取5页
print(url_list)
ip_list = []
for i in range(len(url_list)):
url =url_list[i]
html = requests.get(url=url,).text
regip = '<td.*?>(\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3})</td>.*?<td.*?>(\d{1,5})</td>'
matcher = re.compile(regip,re.S)
ipstr = re.findall(matcher, html)
time.sleep(1) for j in ipstr:
ip_list.append(j[0]+':'+j[1]) #ip+port
print(ip_list)
print('共收集到%d个代理ip' % len(ip_list))
return ip_list
if __name__=='__main__':
get_ip()
#先获取特定标签
#解析
import requests
from bs4 import BeautifulSoup
def get_ip_list(obj):
ip_text = obj.findAll('tr', {'class': 'odd'}) # 获取带有IP地址的表格的所有行
ip_list = []
for i in range(len(ip_text)):
ip_tag = ip_text[i].findAll('td')
ip_port = ip_tag[1].get_text() + ':' + ip_tag[2].get_text() # 提取出IP地址和端口号
ip_list.append(ip_port)
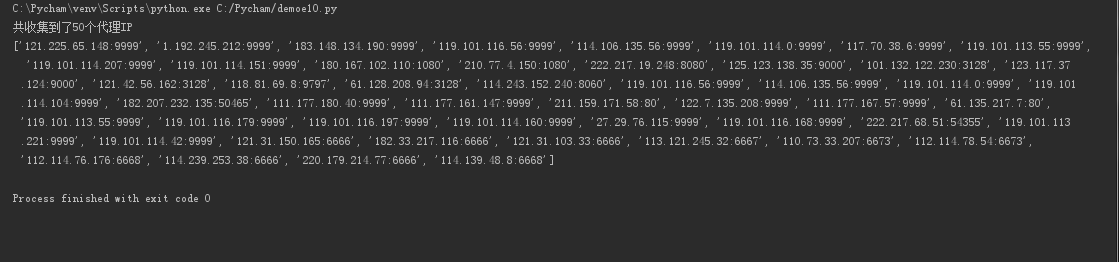
print("共收集到了{}个代理IP".format(len(ip_list)))
print(ip_list)
return ip_list
url = 'http://www.xicidaili.com/'
headers = {
'User-Agent': 'User-Agent:Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.62 Safari/537.36'}
request = requests.get(url, headers=headers)
response =request.text
bsObj = BeautifulSoup(response, 'lxml') # 解析获取到的html
lists=get_ip_list(bsObj)
检测代理ip可用性
第一种方法:通过返回的状态码判断
import requests
import random
import re
import time def get_ip():
url='https://www.kuaidaili.com/free/inha/'
url_list=[url+str(i+1) for i in range(1)]
print(url_list)
ip_list = []
for i in range(len(url_list)):
url =url_list[i]
html = requests.get(url=url,).text
regip = '<td.*?>(\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3})</td>.*?<td.*?>(\d{1,5})</td>'
matcher = re.compile(regip,re.S)
ipstr = re.findall(matcher, html)
time.sleep(1) for j in ipstr:
ip_list.append(j[0]+':'+j[1])
print('共收集到%d个代理ip' % len(ip_list))
print(ip_list)
return ip_list
def valVer(proxys):
badNum = 0
goodNum = 0
good=[]
for proxy in proxys:
try:
proxy_host = proxy
protocol = 'https' if 'https' in proxy_host else 'http'
proxies = {protocol: proxy_host}
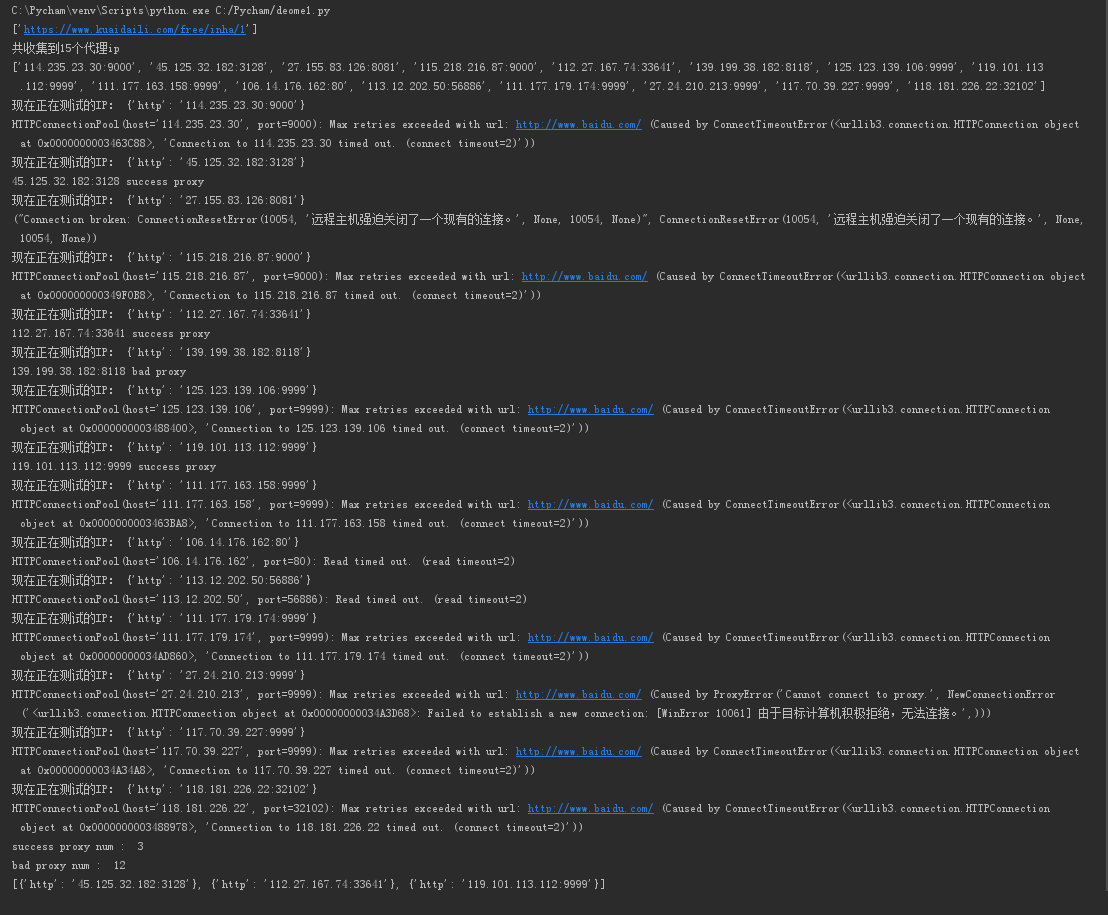
print('现在正在测试的IP:',proxies)
response = requests.get('http://www.baidu.com', proxies=proxies, timeout=2)
if response.status_code != 200:
badNum += 1
print (proxy_host, 'bad proxy')
else:
goodNum += 1
good.append(proxies)
print (proxy_host, 'success proxy')
except Exception as e:
print( e)
# print proxy_host, 'bad proxy'
badNum += 1
continue
print ('success proxy num : ', goodNum)
print( 'bad proxy num : ', badNum)
print(good) if __name__ == '__main__':
ip_list=get_ip()
valVer(ip_list)
第二种方法:使用requests包来进行验证
import requests
import random
import re
import time def get_ip():
url='https://www.kuaidaili.com/free/inha/'
url_list=[url+str(i+1) for i in range(1)]
print(url_list)
ip_list = []
for i in range(len(url_list)):
url =url_list[i]
html = requests.get(url=url,).text
regip = '<td.*?>(\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3})</td>.*?<td.*?>(\d{1,5})</td>'
matcher = re.compile(regip,re.S)
ipstr = re.findall(matcher, html)
time.sleep(1) for j in ipstr:
ip_list.append(j[0]+':'+j[1])
print(ip_list)
print('共收集到%d个代理ip' % len(ip_list))
return ip_list
def valVer(proxys):
badNum = 0
goodNum = 0
good=[]
for proxy in proxys:
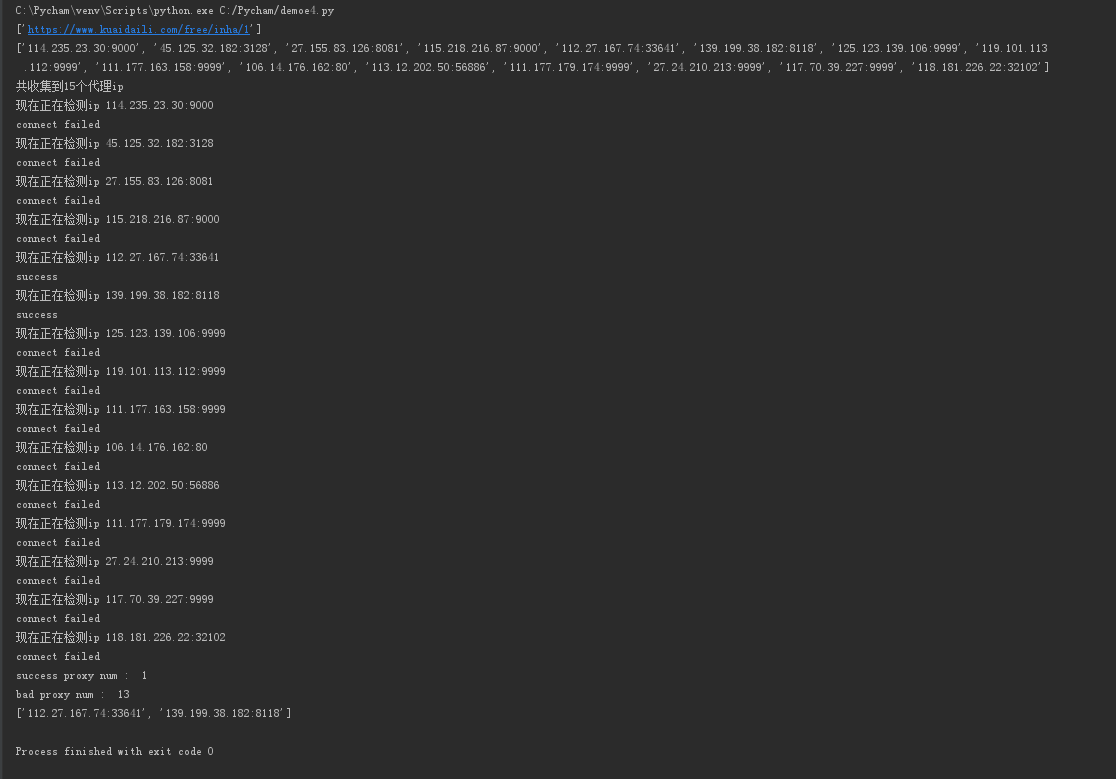
print("现在正在检测ip",proxy)
try:
requests.get('http://wenshu.court.gov.cn/', proxies={"http":"http://"+str(proxy)}, timeout=2)
except:
badNum+=1
print('connect failed')
else:
goodNum=1
good.append(proxy)
print('success') print ('success proxy num : ', goodNum)
print( 'bad proxy num : ', badNum)
print(good) if __name__ == '__main__':
ip_list=get_ip()
valVer(ip_list)
第三种方法:使用telnet
import telnetlib
try:
telnetlib.Telnet('127.0.0.1', port='80', timeout=20)
except:
print 'connect failed'
else:
print 'success'
python爬虫之反爬虫(随机user-agent,获取代理ip,检测代理ip可用性)的更多相关文章
- Python爬虫与反爬虫(7)
[Python基础知识]Python爬虫与反爬虫(7) 很久没有补爬虫了,相信在白蚁二周年庆的活动大厅比赛中遇到了关于反爬虫的问题吧 这节我会做个基本分享. 从功能上来讲,爬虫一般分为数据采集,处理, ...
- Python爬虫从入门到放弃(二十二)之 爬虫与反爬虫大战
爬虫与发爬虫的厮杀,一方为了拿到数据,一方为了防止爬虫拿到数据,谁是最后的赢家? 重新理解爬虫中的一些概念 爬虫:自动获取网站数据的程序反爬虫:使用技术手段防止爬虫程序爬取数据误伤:反爬虫技术将普通用 ...
- Python爬虫入门教程 65-100 爬虫与反爬虫的修罗场,点评网站,字体反爬之三
爬虫与反爬虫的修罗场 哪种平台最吸引爬虫爱好者,当然是社区类的,那里容易产生原生态,高质量的数据啊, 你看微博,知乎,豆瓣爬的不亦乐乎. 评论也是产生内容的好地方 生活类点评网站 旅游类点评网站 音乐 ...
- 【Python】爬虫与反爬虫大战
爬虫与发爬虫的厮杀,一方为了拿到数据,一方为了防止爬虫拿到数据,谁是最后的赢家? 重新理解爬虫中的一些概念 爬虫:自动获取网站数据的程序反爬虫:使用技术手段防止爬虫程序爬取数据误伤:反爬虫技术将普通用 ...
- Python之爬虫(二十四) 爬虫与反爬虫大战
爬虫与发爬虫的厮杀,一方为了拿到数据,一方为了防止爬虫拿到数据,谁是最后的赢家? 重新理解爬虫中的一些概念 爬虫:自动获取网站数据的程序反爬虫:使用技术手段防止爬虫程序爬取数据误伤:反爬虫技术将普通用 ...
- C#爬虫与反爬虫--字体加密篇
爬虫和反爬虫是一条很长的路,遇到过js加密,flash加密.重点信息生成图片.css图片定位.请求头.....等手段:今天我们来聊一聊字体: 那是一个偶然我遇到了这个网站,把价格信息全加密了:浏览器展 ...
- 深入细枝末节,Python的字体反爬虫到底怎么一回事
内容选自 即将出版 的<Python3 反爬虫原理与绕过实战>,本次公开书稿范围为第 6 章——文本混淆反爬虫.本篇为第 6 章中的第 4 小节,其余小节将 逐步放送 . 字体反爬虫开篇概 ...
- Python Scrapy突破反爬虫机制(项目实践)
对于 BOSS 直聘这种网站,当程序请求网页后,服务器响应内容包含了整个页面的 HTML 源代码,这样就可以使用爬虫来爬取数据.但有些网站做了一些“反爬虫”处理,其网页内容不是静态的,而是使用 Jav ...
- crawler_爬虫_反爬虫策略
关于反爬虫和恶意攻击的一些策略和思路 有时网站经常受到恶意spider攻击,疯狂抓取网站内容,对网站性能有较大影响. 下面我说说一些反恶意spider和spam的策略和思路. 1. 通过日志分析来 ...
随机推荐
- HDU 2191 - 单调队列优化多重背包
题目: 传送门呀传送门~ Problem Description 急!灾区的食物依然短缺! 为了挽救灾区同胞的生命,心系灾区同胞的你准备自己采购一些粮食支援灾区,现在假设你一共有资金n元,而市场有m种 ...
- SpringBoot在IDEA中实现热部署
gradle构建形式 添加依赖 compile("org.springframework.boot:spring-boot-devtools") 其他设置 步骤1 步骤2 按下 C ...
- tidb 架构~tidb 理论学习(1)
一 简介:介绍新型NEW SQL数据库tidb 二 目的: tidb出现的目的,就是代替mysql+中间件,实现横向水平扩展 三 核心理论观点 1 MySQL 是单机数据库,只能通过 XA 来满足跨数 ...
- 以前的 Delphi版本
Delphi 1 Delphi 2 Delphi 3 Delphi 4 Delphi 5 Delphi 6 Delphi 7 Delphi 8 Delphi 2005
- CSS :invalid 选择器
如果 input 元素中的值是非法的,实时提醒 <!DOCTYPE html> <html> <head> <meta charset="utf-8 ...
- escape、encodeURI和encodeURIComponent的区别
1.简单解释 简单来说,escape是对字符串(string)进行编码(而另外两种是对URL),作用是让它们在所有电脑上可读. 编码之后的效果是%XX或者%uXXXX这种形式. 其中 ASCII字母. ...
- KERMIT,XMODEM,YMODEM,ZMODEM传输协议小结
转:http://blog.163.com/czblaze_3333/blog/static/208996228201272295236713/ Kermit协议 报文格式: 1. MAR ...
- Linux中THIS_MODULE宏定义详解
一直都在耿耿于怀,这个THIS_MODULE到底是个什么玩意,linux内核中无处不在的东西.今天上网搜了一下,算是基本明白了.网上牛人写的已经比较详细,另外目前暂时没有时间往更深层次分析,所以直接贴 ...
- 解决LoggerFactory is not a Logback LoggerContext but Logback is on the classpath
因为引用了log4j2同时还引用了logback
- JAVA中各种日期表示字母
字母 日期或时间元素 表示 示例 G Era 标志符 Text AD y 年 Year 1996; 96 M 年中的月份 Month July; Jul; 07 w 年中的周数 Number 27 W ...