聊聊kafka结构
因为kafka用到的地方比较多,日志收集、数据同步等,所以咱们来聊聊kafka。
首先先看看kafaka的结构,producer将消息放到一个Topic然后push到broker,然后cosumer从broker中拉取对应Topic的消息。
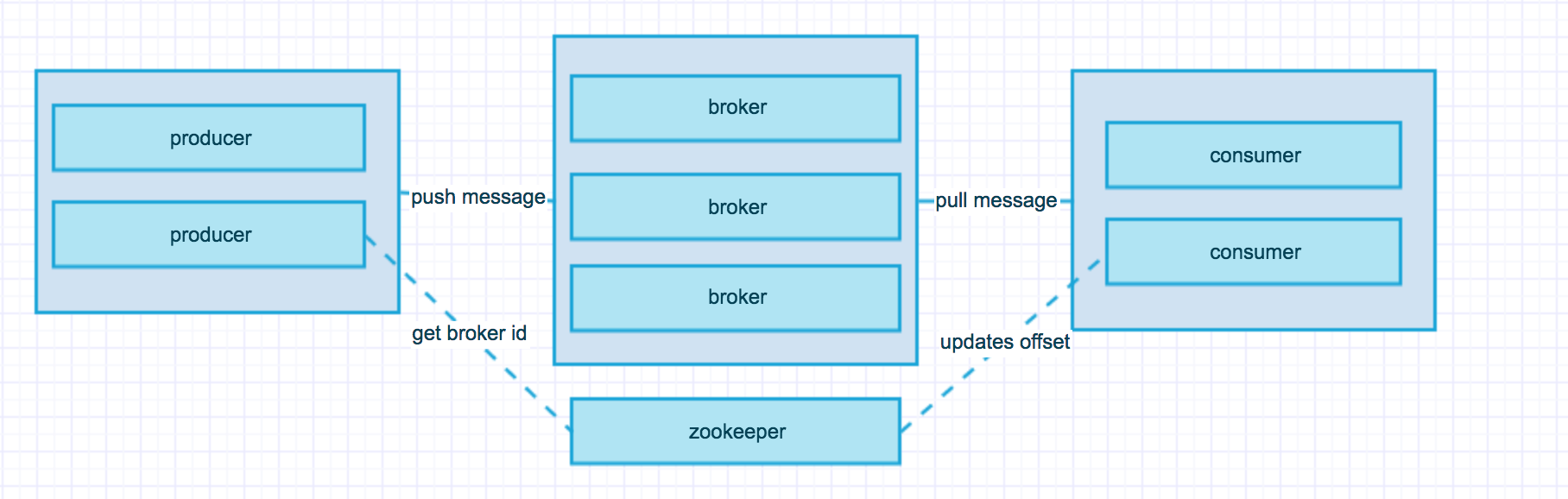
broker可能大家不太熟悉,这个broker就是构成kafka集群的机器,用于实现将数据持久化并且其他数据从leader broker中进行备份,一旦其中一台 broker出现问题之后将由其他broker直接升级为leader,然后代替原来的broker。
zookeeper的作用是记录当前leader broker的id,并将其发送给producer,并且记录每个consumer的进行的offset。offset就是消息存在的位置,这块与其他消息组件不同的是其他的消息组件消费完了直接就没有了,但是kafka会将消息持久化一段时间,这个时间可以是几天时间,用于消息重新再读取。
接下来咱们再继续看看broker的内部实现:
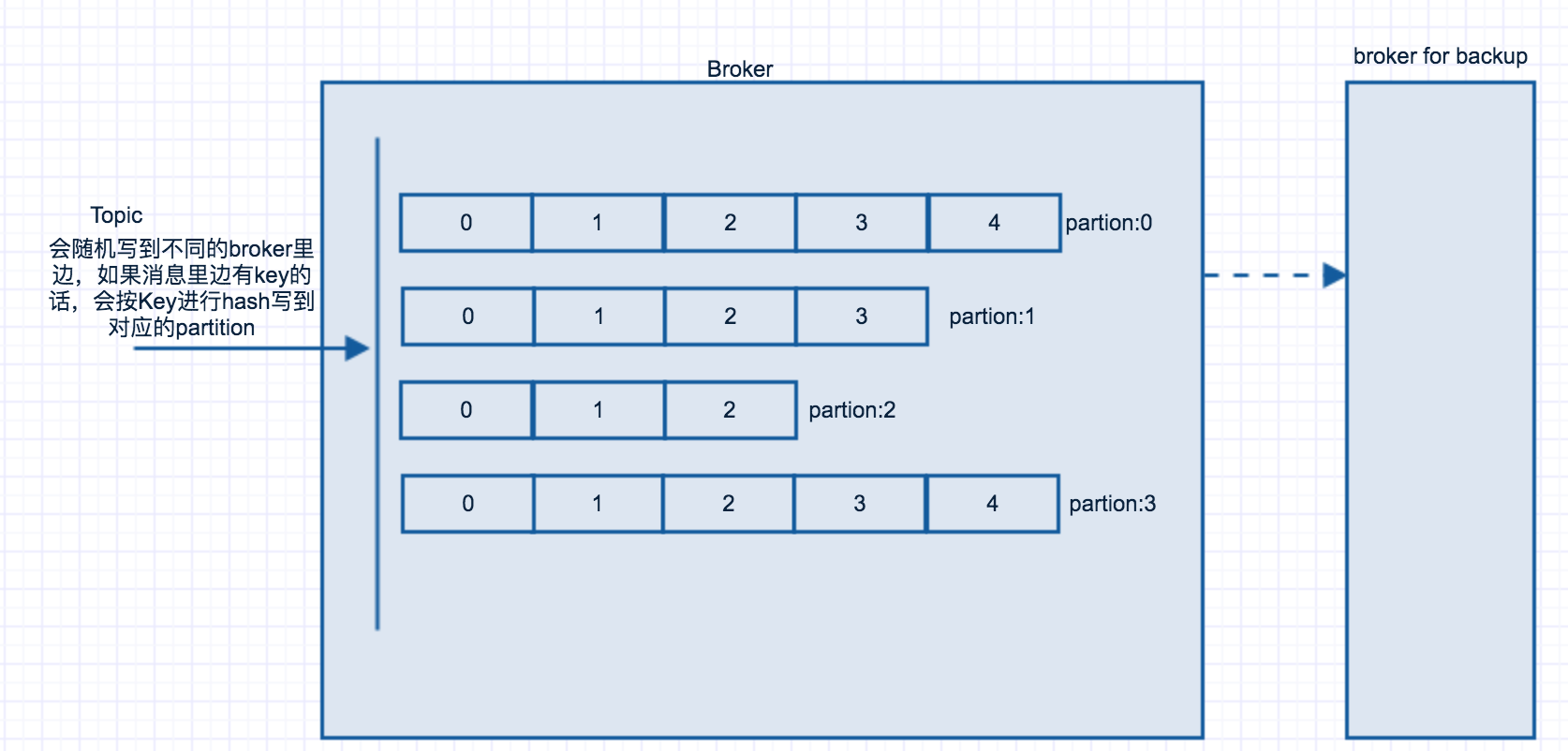
在每一个broker里边有相应的partition,这个partition就是按照Topic将消息分发到不同的partition, 然后consumer再到相应的partition获取对应的消息。如果producer发送消息到某个指定的key上,那么kafka会将这个key进行hash到指定的partition上。在kafka里边可以指定factor,这个factor的作用是备份,对partition的备份。如果指定factor=2,那么一个partion会有2个备份。如下图所示:
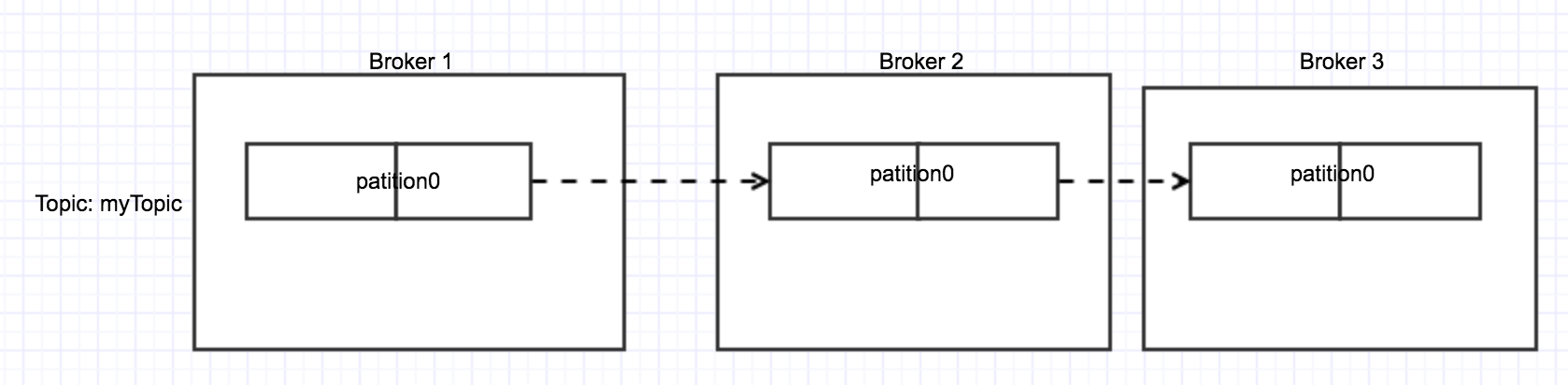
下面说一下consumer group, 因为partion设置的数量固定,所以在consumer group中的数量一定是小于等于partition的数量,因为最多每个consumer消息一个,consumer多了就消费不过来了。
consumer group 是拥有相同group id的机器,这些机器是单独的机器,每个机器都可以指定topic、partition进行消费。如下图所示:

这些就是基本的kafka结构了,当然里边还有很多非常详细的内容,这里就不单独说了。kafka的功能非常强大,分布式,可动态扩展,消息复制,高可用低延迟等特点,这就是为什么很多人喜欢使用kafka。kafka单台机器生产消费机器的话,每秒处理70-80万左右的消息。当然消息备份采用异步处理,如果消息采用同步处理的话,一秒可以处理的数据每秒也有30-40万左右。
kafka支持消息持久化,这个持久化的时间可以进行配置,也就是消息可以被consumer多次消费。这个是其他消息队列所没有的。
kafka支持consumer进行assign(分配)topic,也就是单独消费某一个消息,在consumer group里边只有一台机器消费此topic。也支持Pub-Sub模式,所有订阅指定Topic的consumer会收到消息。同时支持取消订阅功能。
kafka还支持connector(连接器),可以进行数据库连接,连上数据库后可以将数据库的记录读取到,按照自增列id或者timestamp(时间戳)进行读取,然后将消息写入到需要的地方,比如写到数据分析的地方。
kafka支持stream(流),可以将消息写入到stream,并将消息以流的形式从一个topic写入到另一个topic中,这个功能其他队列也没有。
kafka一般用于消息队列,日志收集,网站行为记录等,当然它也有区别,比如不能topic不能使用通配符,connector的支持的语言不是特别多。
好了,关于kafka咱们先聊到这里,还有很多地方没有说到,有觉得那些写的不好的地方还望同学不吝赐教。
聊聊kafka结构的更多相关文章
- 大数据之kafka-05.讲聊聊Kafka的版本号
今天聊聊kafka版本号的问题,这个问题实在是太重要了,我觉得甚至是日后能否用好kafka的关键.上一节我们介绍了kafka的几种发行版,其实不论是哪种kafka,本质上都内嵌了最核心的Apache ...
- 聊聊kafka
两个月因为忙于工作毫无输出了,最近想给团队小伙伴分享下kafka的相关知识,于是就想着利用博客来做个提前的准备工作了:接下来会对kafka做一个简单的介绍,包括利用akf原则来解析单机下kafk的各个 ...
- 【原创】美团二面:聊聊你对 Kafka Consumer 的架构设计
在上一篇中我们详细聊了关于 Kafka Producer 内部的底层原理设计思想和细节, 本篇我们主要来聊聊 Kafka Consumer 即消费者的内部底层原理设计思想. 1.Consumer之总体 ...
- 涨姿势了解一下Kafka消费位移可好?
摘要:Kafka中的位移是个极其重要的概念,因为数据一致性.准确性是一个很重要的语义,我们都不希望消息重复消费或者丢失.而位移就是控制消费进度的大佬.本文就详细聊聊kafka消费位移的那些事,包括: ...
- Kafka入门(2):消费与位移
摘要 在这篇文章中,我将从消息在Kafka中的物理存储方式讲起,介绍分区-日志段-日志的各个层次. 然后我将接着上一篇文章的内容,把消费者的内容展开讲一讲,区分消费者与消费者组,以及这么设计有什么用. ...
- 【原创】阿里三面:搞透Kafka的存储架构,看这篇就够了
阅读本文大约需要30分钟.这篇文章干货很多,希望你可以耐心读完. 你好, 我是华仔,在这个 1024 程序员特殊的节日里,又和大家见面了. 从这篇文章开始,我将对 Kafka 专项知识进行深度剖析, ...
- Go语言结构
目录 结构体定义 创建结构体实例 普通方式创建结构体实例 new()创建结构体实例 结构体实例初始化 结构体类型实例和指向它的指针内存布局 结构体的方法 面向对象 组合(继承) 结构体使用注意事项 G ...
- Kafka架构
一.Kafka介绍 Kafka是Linkin在2010年开源的分布式发布订阅消息系统,Kafka是高吞吐量的消息订阅系统. 二.Kafka结构 Kafka由三部分构成,producer.broker. ...
- Kafka系列1:Kafka概况
Kafka系列1:Kafka概况 Kafka是当前分布式系统中最流行的消息中间件之一,凭借着其高吞吐量的设计,在日志收集系统和消息系统的应用场景中深得开发者喜爱.本篇就聊聊Kafka相关的一些知识点. ...
随机推荐
- adb不识别设备(手机)的若干情形及解决方法
1.执行adb root 提示adb: unable to connect for root: no devices/emulators found:执行adb devices ,List下无设备 ...
- android aysncTask面试解析
- fastdfs+nginx集群高可用搭建的一些坑!!记录一下
首先我这里是三台节点,都搭tracker和storage,然后使用nginx做负载,只建一个group1,三个tracker! 搭建步骤比较麻烦,里面有很多坑需要注意,步骤就不啰嗦了,这里主要记录几个 ...
- 关注网页的更新状况,了解最新的handsup 消息.
// 第一部分是网页截图和源码保存 // upon page load. var fs = require("fs"); var resourceWait = 300, maxRe ...
- 如何设置使eclipse修改代码不重启tomcat
tomcat配置 1.server.xml reloadable="true"<Context docBase="ins" path="/ins ...
- 反向代理负载均衡之APACHE
反向代理负载均衡之APACHE 一.反向代理1.1 介绍反响代理 反向代理(Reverse Proxy)方式是指以代理服务器来接受internet上的连接请求,然后将请求转发给内部网络上的服务器,并将 ...
- mysql 常用,使用经验
mysql default boolean字段 `enable` char(1) NOT NULL DEFAULT '1' COMMENT '启(禁)用',结果: this.enable ? &qu ...
- 恋爱Linux(Fedora20)2——安装Java运行环境(JDK)
因为Fedora20自带OpenJDK,所以我们先删除掉自带的: 1)查看当前的jdk情况 # rpm -qa|grep jdk 2)卸载openjdk # yum -y remove java ja ...
- OCM_第十五天课程:Section6 —》数据库性能调优 _SQL 访问建议 /SQL 性能分析器/配置基线模板/SQL 执行计划管理/实例限制
注:本文为原著(其内容来自 腾科教育培训课堂).阅读本文注意事项如下: 1:所有文章的转载请标注本文出处. 2:本文非本人不得用于商业用途.违者将承当相应法律责任. 3:该系列文章目录列表: 一:&l ...
- 洛谷 P4427 求和
传送门啦 思路: 开始不肿么容易想到用倍增,但是想到需要求 $ Lca $ ,倍增这种常数小而且快的方法就很方便了.求 $ Lca $ 就是一个最普通的板子.那现在考虑怎么求题目中的结果. 树上差分可 ...