【nodeJS爬虫】前端爬虫系列
写这篇 blog 其实一开始我是拒绝的,因为爬虫爬的就是cnblog博客园。搞不好编辑看到了就把我的账号给封了:)。
能看懂 Javascript 及 JQuery
简单的nodejs基础
http 网络抓包 和 URL 基础
本文较长且图多,但如果能耐下心读完本文,你会发现,简单的一个爬虫实现并不难,并且能从中学到很多东西。
本文中的完整的爬虫代码,在我的github上可以下载。主要的逻辑代码在 server.js 中,建议边对照代码边往下看。
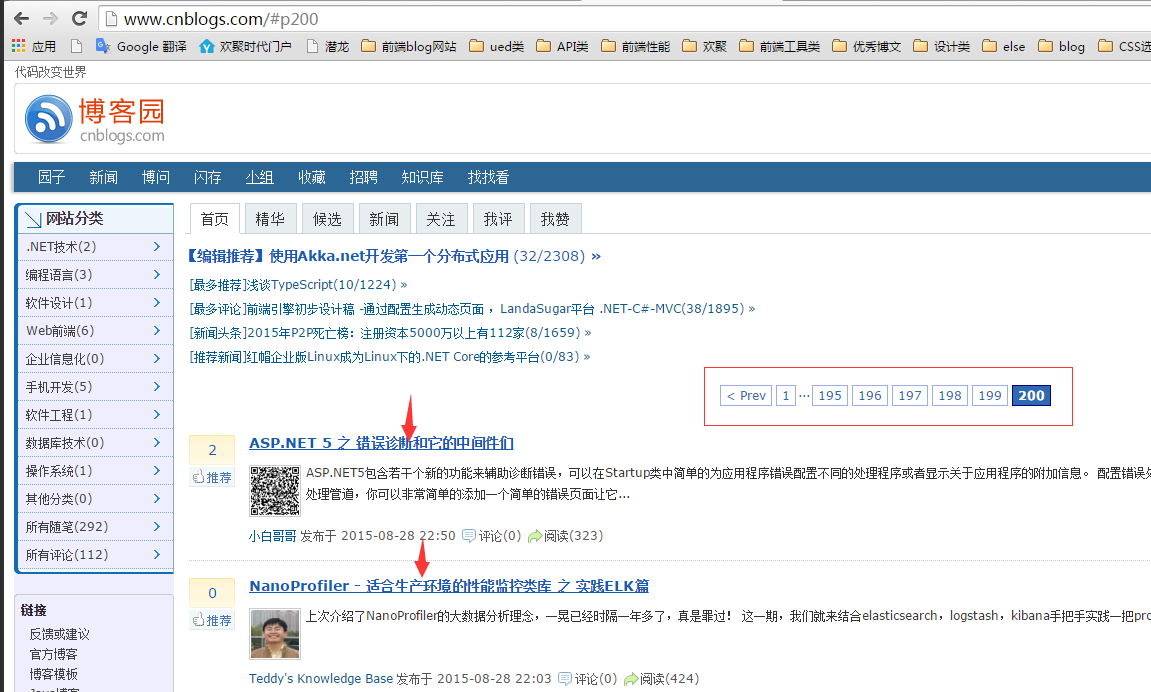
在详细说爬虫前,先来简单看看要达成的最终目标,入口为 http://www.cnblogs.com/ ,博客园文章列表页每页有20篇文章,最多可以翻到200页。我这个爬虫要做的就是异步并发去爬取这4000篇文章的具体内容,拿到一些我们想要的关键数据。
爬虫流程
看到了最终结果,那么我们接下来看看该如何一步一步通过一个简单的 nodejs 爬虫拿到我们想要的数据,首先简单科普一下爬虫的流程,要完成一个爬虫,主要的步骤分为:
抓取
爬虫爬虫,最重要的步骤就是如何把想要的页面抓取回来。并且能兼顾时间效率,能够并发的同时爬取多个页面。
同时,要获取目标内容,需要我们分析页面结构,因为 ajax 的盛行,许多页面内容并非是一个url就能请求的的回来的,通常一个页面的内容是经过多次请求异步生成的。所以这就要求我们能够利用抓包工具分析页面结构。
如果深入做下去,你会发现要面对不同的网页要求,比如有认证的,不同文件格式、编码处理,各种奇怪的url合规化处理、重复抓取问题、cookies 跟随问题、多线程多进程抓取、多节点抓取、抓取调度、资源压缩等一系列问题。
所以第一步就是拉网页回来,慢慢你会发现各种问题待你优化。
存储
当把页面内容抓回来后,一般不会直接分析,而是用一定策略存下来,个人觉得更好的架构应该是把分析和抓取分离,更加松散,每个环节出了问题能够隔离另外一个环节可能出现的问题,好排查也好更新发布。
那么存文件系统、SQL or NOSQL 数据库、内存数据库,如何去存就是这个环节的重点。
分析
对网页进行文本分析,提取链接也好,提取正文也好,总之看你的需求,但是一定要做的就是分析链接了。通常分析与存储会交替进行。可以用你认为最快最优的办法,比如正则表达式。然后将分析后的结果应用与其他环节。
展示
要是你做了一堆事情,一点展示输出都没有,如何展现价值?
所以找到好的展示组件,去show出肌肉也是关键。
如果你为了做个站去写爬虫,抑或你要分析某个东西的数据,都不要忘了这个环节,更好地把结果展示出来给别人感受。
编写爬虫代码
Step.1 页面分析
现在我们一步一步来完成我们的爬虫,目标是爬取博客园第1页至第200页内的4000篇文章,获取其中的作者信息,并保存分析。


共4000篇文章,所以首先我们要获得这个4000篇文章的入口,然后再异步并发的去请求4000篇文章的内容。但是这个4000篇文章的入口 URL 分布在200个页面中。所以我们要做的第一步是 从这个200个页面当中,提取出4000个 URL 。并且是通过异步并发的方式,当收集完4000个 URL 再进行下一步。那么现在我们的目标就很明确了:
Step2.获取4000个文章入口URL

要获取这么多 URL ,首先还是得从分析单页面开始,F12 打开 devtools 。很容易发现文章入口链接保存在 class 为 titlelnk 的 <a> 标签中,所以4000个 URL 就需要我们轮询 200个列表页 ,将每页的20个 链接保存起来。那么该如何异步并发的从200个页面去收集这4000个 URL 呢,继续寻找规律,看看每一页的列表页的 URL 结构:


那么,1~200页的列表页 URL 应该是这个样子的:
|
1
2
3
|
for(var i=1 ; i<= 200 ; i++){ pageUrls.push('http://www.cnblogs.com/#p'+i);} |
有了存放200个文章列表页的 URL ,再要获取4000个文章入口就不难了,下面贴出关键代码,一些最基本的nodejs语法(譬如如何搭建一个http服务器)默认大家都已经会了:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
|
// 一些依赖库var http = require("http"), url = require("url"), superagent = require("superagent"), cheerio = require("cheerio"), async = require("async"), eventproxy = require('eventproxy');var ep = new eventproxy(), urlsArray = [], //存放爬取网址 pageUrls = [], //存放收集文章页面网站 pageNum = 200; //要爬取文章的页数for(var i=1 ; i<= 200 ; i++){ pageUrls.push('http://www.cnblogs.com/#p'+i);}// 主start程序function start(){ function onRequest(req, res){ // 轮询 所有文章列表页 pageUrls.forEach(function(pageUrl){ superagent.get(pageUrl) .end(function(err,pres){ // pres.text 里面存储着请求返回的 html 内容,将它传给 cheerio.load 之后 // 就可以得到一个实现了 jquery 接口的变量,我们习惯性地将它命名为 `$` // 剩下就都是利用$ 使用 jquery 的语法了 var $ = cheerio.load(pres.text); var curPageUrls = $('.titlelnk'); for(var i = 0 ; i < curPageUrls.length ; i++){ var articleUrl = curPageUrls.eq(i).attr('href'); urlsArray.push(articleUrl); // 相当于一个计数器 ep.emit('BlogArticleHtml', articleUrl); } }); }); ep.after('BlogArticleHtml', pageUrls.length*20 ,function(articleUrls){ // 当所有 'BlogArticleHtml' 事件完成后的回调触发下面事件 // ... }); } http.createServer(onRequest).listen(3000);}exports.start= start; |
superagent
superagent(http://visionmedia.github.io/superagent/ ) 是个轻量的的 http 方面的库,是nodejs里一个非常方便的客户端请求代理模块,当我们需要进行 get 、 post 、 head 等网络请求时,尝试下它吧。
cheerio
cheerio(https://github.com/cheeriojs/cheerio ) 大家可以理解成一个 Node.js 版的 jquery,用来从网页中以 css selector 取数据,使用方式跟 jquery 一样一样的。
eventproxy
eventproxy(https://github.com/JacksonTian/eventproxy ) 非常轻量的工具,但是能够带来一种事件式编程的思维变化。
用 js 写过异步的同学应该都知道,如果你要并发异步获取两三个地址的数据,并且要在获取到数据之后,对这些数据一起进行利用的话,常规的写法是自己维护一个计数器。
先定义一个 var count = 0,然后每次抓取成功以后,就 count++。如果你是要抓取三个源的数据,由于你根本不知道这些异步操作到底谁先完成,那么每次当抓取成功的时候,就判断一下count === 3。当值为真时,使用另一个函数继续完成操作。
而 eventproxy 就起到了这个计数器的作用,它来帮你管理到底这些异步操作是否完成,完成之后,它会自动调用你提供的处理函数,并将抓取到的数据当参数传过来。
OK,运行一下上面的函数,假设上面的内容我们保存在 server.js 中,而我们有一个这样的启动页面 index.js,

现在我们在回调里增加几行代码,打印出结果:

打开node命令行,键入指令,在浏览器打开 http://localhost:3000/ ,可以看到:
|
1
|
node index.js |

成功了!我们成功收集到了4000个 URL ,但是我将这个4000个 URL 去重后发现,只有20个 URL 剩下,也就是说我将每个 URL push 进数组了200次,一定是哪里错,看到200这个数字,我立马回头查看 200 个 文章列表页。
我发现,当我用 http://www.cnblogs.com/#p1 ~ 200 访问页面的时候,返回的都是博客园的首页。 而真正的列表页,藏在这个异步请求下面:

看看这个请求的参数:

把请求参数提取出来,我们试一下这个 URL,访问第15页列表页:http://www.cnblogs.com/?CategoryId=808&CategoryType=%22SiteHome%22&ItemListActionName=%22PostList%22&PageIndex=15&ParentCategoryId=0 。

成功了,那么我们稍微修改下上面的代码:
|
1
2
3
4
5
6
7
|
//for(var i=1 ; i<= 200 ; i++){// pageUrls.push('http://www.cnblogs.com/#p'+i);//}//改为for(var i=1 ; i<= 200 ; i++){ pageUrls.push('http://www.cnblogs.com/?CategoryId=808&CategoryType=%22SiteHome%22&ItemListActionName=%22PostList%22&PageIndex='+ i +'&ParentCategoryId=0');} |
再试一次,发现这次成功收集到了4000个没有重复的 URL 。第二步完成!
Step.3 爬取具体页面内容 使用 async 控制异步并发数量
获取到4000个 URL ,并且回调入口也有了,接下来我们只需要在回调函数里继续爬取4000个具体页面,并收集我们想要的信息就好了。其实刚刚我们已经经历了第一轮爬虫爬取,只是有一点做的不好的地方是我们刚刚并没有限制并发的数量,这也是我发现 cnblog 可以改善的一点,不然很容易被单IP的巨量 URL 请求攻击到崩溃。为了做一个好公民,也为了减轻网站的压力(其实为了不被封IP),这4000个URL 我限制了同时并发量最高为5。这里用到了另一个非常强大的库 async ,让我们控制并发量变得十分轻松,简单的介绍如下。
async
async(https://github.com/caolan/async#queueworker-concurrency),async是一个流程控制工具包,提供了直接而强大的异步功能mapLimit(arr, limit, iterator, callback)。
这次我们要介绍的是 async 的 mapLimit(arr, limit, iterator, callback) 接口。另外,还有个常用的控制并发连接数的接口是 queue(worker, concurrency) ,大家可以去看看它的API。
继续我们的爬虫,进到具体的文章页面,发现我们想获取的信息也不在直接请求而来的 html 页面中,而是如下这个 ajax 请求异步生成的,不过庆幸的是我们上一步收集的 URL 包含了这个请求所需要的参数,所以我们仅仅需要多做一层处理,将这个参数从 URL 中取出来再重新拼接成一个ajax URL 请求。
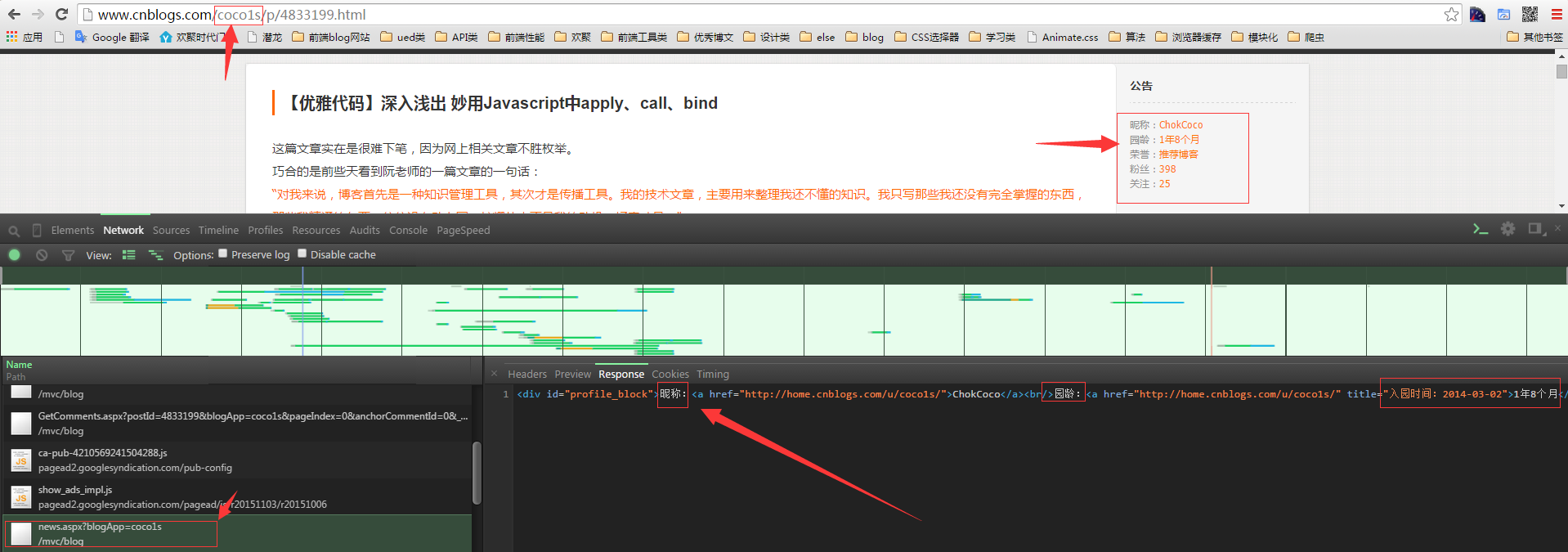
下面,贴出代码,在我们刚刚的回调函数中,继续我们4000个页面的爬取,并且控制并发数为5:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
|
ep.after('BlogArticleHtml',pageUrls.length*20,function(articleUrls){ // 当所有 'BlogArticleHtml' 事件完成后的回调触发下面事件 // 控制并发数 var curCount = 0; var reptileMove = function(url,callback){ //延迟毫秒数 var delay = parseInt((Math.random() * 30000000) % 1000, 10); curCount++; console.log('现在的并发数是', curCount, ',正在抓取的是', url, ',耗时' + delay + '毫秒'); superagent.get(url) .end(function(err,sres){ // sres.text 里面存储着请求返回的 html 内容 var $ = cheerio.load(sres.text); // 收集数据 // 拼接URL var currentBlogApp = url.split('/p/')[0].split('/')[3], appUrl = "http://www.cnblogs.com/mvc/blog/news.aspx?blogApp="+ currentBlogApp; // 具体收集函数 personInfo(appUrl); }); setTimeout(function() { curCount--; callback(null,url +'Call back content'); }, delay); };// 使用async控制异步抓取 // mapLimit(arr, limit, iterator, [callback])// 异步回调async.mapLimit(articleUrls, 5 ,function (url, callback) { reptileMove(url, callback); }, function (err,result) { // 4000 个 URL 访问完成的回调函数 // ... });}); |
根据重新拼接而来的 URL ,再写一个具体的 personInfo(URL) 函数,具体获取我们要的昵称、园龄、粉丝数等信息。
这样,我们把抓取回来的信息以 JSON 串的形式存储在 catchDate 这个数组当中,
node index.js 运行一下程序,将结果打印出来,可以看到中间过程及结果:



至此,第三步就完成了,我们也收集到了4000条我们想要的原始数据。
Step.4 分析 展示
本来想将爬来的数据存入 mongoDB ,但因为这里我只抓取了4000条数据,相对于动不动爬几百万几千万的量级而言不值一提,故就不添加额外的操作 mongoDB 代码,专注于爬虫本身。
收集到数据之后,就想看你想怎么展示了,这里推荐使用 Highcharts 纯JS图表库去展示我们的成果。当然这里我偷懒了没有做,直接用最原始的方法展示结果。
下面是我不同时间段爬取,经过简单处理后的的几张结果图:
(结果图的耗时均在并发量控制为 5 的情况下)



后记
OK,至此,整个爬虫就完成了,其实代码量很少,我觉得写爬虫更多的时间是花在在处理各类问题,分析页面结构。
完整的爬虫代码,在我的github上可以下载。如果仍有疑问,可以把代码 down 到本地,重新从文章开头对照代码再实践一次,相信很多问题会迎刃而解。
因为代码开源,本着负责任的心态,希望大家可以照着代码写写其他网站的爬虫,如果都拿cnblog来爬,服务器可能会承受不住的:)
参考文章:《Node.js 包教不包会》。
原创文章,文笔有限,才疏学浅,文中若有不正之处,万望告知。
【nodeJS爬虫】前端爬虫系列的更多相关文章
- nodejs的简单爬虫
闲聊 好久没写博客了,前几天小颖在朋友的博客里看到了用nodejs的简单爬虫.所以小颖就自己试着做了个爬博客园数据的demo.嘻嘻...... 小颖最近养了条泰日天,自从养了我家 ...
- nodejs 快要变成爬虫界的王者
nodejs 快要变成爬虫界的王者 爬虫这东西是很多数据采集必须要的东西. 但是现在随着网页不断发展,已经出现了出单纯的网页,到 ajax 网页, 再到 spa , 再到 websocket 应用,一 ...
- 一次使用NodeJS实现网页爬虫记
前言 几个月之前,有同事找我要PHP CI框架写的OA系统.他跟我说,他需要学习PHP CI框架,我建议他学习大牛写的国产优秀框架QeePHP. 我上QeePHP官网,发现官方网站打不开了,GOOGL ...
- nodeJS实现简易爬虫
nodeJS实现简易爬虫 需求:使用nodeJS爬取昵图网某个分类下的图片并存入本地 运用nodeJS自带系统模块http.fs 示例代码: var http =require('http'); va ...
- nodejs实现新闻爬虫
作为费德勒的铁杆粉丝,每天早上都会在新浪体育里面的网球频道浏览费德勒新闻.由于只关注费德勒的新闻,所以每次都要在网页中大量的新闻中筛选相关信息,感觉效率好低,所以用node写了一个简单的爬虫程序通过每 ...
- 前端工程化系列[06]-Yeoman脚手架核心机制
在前端工程化系列[05] Yeoman脚手架使用入门这边文章中,对Yeoman的使用做了简单的入门介绍,这篇文章我们将接着探讨Yeoman这个脚手架工具内部的核心机制,主要包括以下内容 ❏ Yeoma ...
- 2019前端面试系列——Vue面试题
Vue 双向绑定原理 mvvm 双向绑定,采用数据劫持结合发布者-订阅者模式的方式,通过 Object.defineProperty()来劫持各个属性的 setter.getter,在数 ...
- PYTHON爬虫实战_垃圾佬闲鱼爬虫转转爬虫数据整合自用二手急速响应捡垃圾平台_3(附源码持续更新)
说明 文章首发于HURUWO的博客小站,本平台做同步备份发布. 如有浏览或访问异常图片加载失败或者相关疑问可前往原博客下评论浏览. 原文链接 PYTHON爬虫实战_垃圾佬闲鱼爬虫转转爬虫数据整合自用二 ...
- Python 爬虫1——爬虫简述
Python除了可以用来开发Python Web之后,其实还可以用来编写一些爬虫小工具,可能还有人不知道什么是爬虫的. 一.爬虫的定义: 爬虫——网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区 ...
- nodejs辅助前台开发系列(1) 搭建简单HTML开发环境
搭建简单的html开发环境一般需要解决两个问题: 文本编辑器 WebServer集成 在文本编辑器选择上,VS Code 无疑是一匹黑马,谁用谁知道.WebServer集成nodejs对前端来说最为友 ...
随机推荐
- FPN 学习笔记
通常,利用网络对物体进行检测时,浅层网络分辨率高,学到的是图片的细节特征,深层网络,分辨率低,学到的更多的是语义特征. 1).通常的CNN使用如下图中显示的网络,使用最后一层特征图进行预测 例如VGG ...
- 关注网页的更新状况,了解最新的handsup 消息.
// 第一部分是网页截图和源码保存 // upon page load. var fs = require("fs"); var resourceWait = 300, maxRe ...
- haproxy配置基于ssl证书的https负载均衡
本实验全部在haproxy1.5.19版本进行测试通过,经过测试1.7.X及haproxy1.3版本以下haproxy配置参数可能不适用,需要注意版本号. 一.业务要求现在根据业务的实际需要,有以下几 ...
- zabbix3.0.4添加对指定进程的监控
zabbix3.0.4添加对进程的监控: 主要思路: 通过 ps -ef|grep sdk-push-1.0.0.jar |grep -v grep|wc -l 这个命令来判断进程sdk-push是否 ...
- 今天刚用asp.net做的导出Eecel
protected void daochu_Click(object sender, EventArgs e) { string hql = "s ...
- 篮球弹起问题(for循环)
- 【mysql】autocommit=0后,commit, rollback无效
之前在[mysql]MySQLdb中的事务处理中用autocommit和commit()以及rollback()实现了事务处理. 但后来,用同样的代码在另一个数据库中运行却失败了.找了一个下午的原因. ...
- Jquery----对文档操作
jquery对css操作: 1.CSS .css() - .css("color") -> 获取color css值 - .css("color", &q ...
- Luogu P4945 【最后的战役】
本来以为做法一样,就是少带个$log$,结果发现看不懂出题人的题解(我好菜啊) 那就自己写一篇吧 比较简单的$DP$思路 状态定义: 前两个转移很好处理,第三个好像就不好办了 不妨暴力定义进状态里 设 ...
- cf 1082abc
还是菜,两题dp一题模拟 /* 反正就两个方向,往左或者往右,如果都不行,那就是-1 */ #include<bits/stdc++.h> using namespace std; int ...