TF-IDF基本原理
1.TF-IDF介绍
TF/IDF(term frequency–inverse document frequency)用以评估字词 对于一个文件集其中一份文件的重要程度。字词的重要性随着它在文件中出 现的次数成正比增加,随着它在语料库中出现的频率下降。注意前后的中心词不一样。
• 词频 (term frequency, TF) 词语在文件中出现的次数,一般进行归一化,防止长文件数字过大。(同一个词语在长文件里可能会比短文件有更高的词频,而不管该词语重要与否。)
• 逆向文件频率 (inverse document frequency, IDF) 是一个词语普遍重要性的度量。总文件数除以包含该词语文件数,再将得到的商取对数。
• 结论:在某特定文件内的高频率词语,但是该词语在整个文件集合中在较少 文件中出现,TF-IDF值较高。
TF-IDF的主要思想:如果某个词或短语在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。TF-IDF实际上是:TF * IDF,TF词频(Term Frequency),IDF逆向文件频率(Inverse Document Frequency)。
IDF的主要思想是:如果包含词条t的文档越少,也就是n越小,IDF越大,则说明词条t具有很好的类别区分能力。如果某一类文档C中包含词条t的文档数为m,而其它类包含t的文档总数为k,显然所有包含t的文档数n=m+k,当m大的时候,n也大,按照IDF公式得到的IDF的值会小,就说明该词条t类别区分能力不强。(另一说:IDF逆向文件频率(Inverse Document Frequency)是指果包含词条的文档越少,IDF越大,则说明词条具有很好的类别区分能力。)但是实际上,如果一个词条在一个类的文档中频繁出现,则说明该词条能够很好代表这个类的文本的特征,这样的词条应该给它们赋予较高的权重,并选来作为该类文本的特征词以区别与其它类文档。这就是IDF的不足之处.
公式:
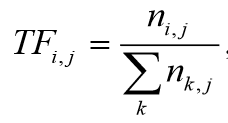
ni,j表示某词在文件出现的次数,分母是文件中字数总和
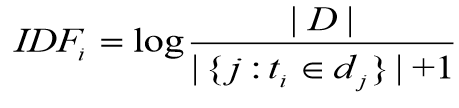
其中| D |表示语料库文件总数,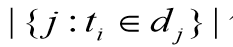 表示包含某词的文件总数。
表示包含某词的文件总数。
最后 TF-IDF=TFij*IDFi
2.TF-IDF文章相似度计算流程:
• A、使用TF-IDF算法,分别找出两篇文章的关键词;
• B、分别取每篇文章TF/IDF值top15(戒者其他值)的词,合并成一个 集合,计算该集合下,每篇文章关键词的相对词频;
• C、分别生成两篇文章的词频向量;
• D、计算两个向量的余弦相似度,值越大就表示越相似。
3.应用举例
• S1:香蕉和苹果都是水果。
• S2:香蕉和苹果都是水果,也是常见的水果。
• 1)分词:S1:香蕉/和/苹果/都/是/水果/。 S2:香蕉/和/苹果/都/是 /水果/,/也/是/常见/的/水果/。
• 2)合并所有的词为集合(无重复词)(香蕉 和 苹果 都 是 常见 的 水果 也)
• 3)计算每个句子词频向量: • v1=[1,1,1,1,1,0,0,1,0],v2=[1,1,1,1,2,1,1,2,1]
• 4)计算余弦相似度
TF-IDF基本原理的更多相关文章
- Elasticsearch由浅入深(十)搜索引擎:相关度评分 TF&IDF算法、doc value正排索引、解密query、fetch phrase原理、Bouncing Results问题、基于scoll技术滚动搜索大量数据
相关度评分 TF&IDF算法 Elasticsearch的相关度评分(relevance score)算法采用的是term frequency/inverse document frequen ...
- TF/IDF(term frequency/inverse document frequency)
TF/IDF(term frequency/inverse document frequency) 的概念被公认为信息检索中最重要的发明. 一. TF/IDF描述单个term与特定document的相 ...
- 基于TF/IDF的聚类算法原理
一.TF/IDF描述单个term与特定document的相关性TF(Term Frequency): 表示一个term与某个document的相关性. 公式为这个term在document中出 ...
- 使用solr的函数查询,并获取tf*idf值
1. 使用函数df(field,keyword) 和idf(field,keyword). http://118.85.207.11:11100/solr/mobile/select?q={!func ...
- TF/IDF计算方法
FROM:http://blog.csdn.net/pennyliang/article/details/1231028 我们已经谈过了如何自动下载网页.如何建立索引.如何衡量网页的质量(Page R ...
- tf–idf算法解释及其python代码实现(下)
tf–idf算法python代码实现 这是我写的一个tf-idf的简单实现的代码,我们知道tfidf=tf*idf,所以可以分别计算tf和idf值在相乘,首先我们创建一个简单的语料库,作为例子,只有四 ...
- tf–idf算法解释及其python代码实现(上)
tf–idf算法解释 tf–idf, 是term frequency–inverse document frequency的缩写,它通常用来衡量一个词对在一个语料库中对它所在的文档有多重要,常用在信息 ...
- 文本分类学习(三) 特征权重(TF/IDF)和特征提取
上一篇中,主要说的就是词袋模型.回顾一下,在进行文本分类之前,我们需要把待分类文本先用词袋模型进行文本表示.首先是将训练集中的所有单词经过去停用词之后组合成一个词袋,或者叫做字典,实际上一个维度很大的 ...
- 信息检索中的TF/IDF概念与算法的解释
https://blog.csdn.net/class_brick/article/details/79135909 概念 TF-IDF(term frequency–inverse document ...
- Elasticsearch学习之相关度评分TF&IDF
relevance score算法,简单来说,就是计算出,一个索引中的文本,与搜索文本,他们之间的关联匹配程度 Elasticsearch使用的是 term frequency/inverse doc ...
随机推荐
- input debounce
项目背景是一个搜索框,不能实时的监听onChange 事件去发送请求,这样会造成服务器的压力 解决思路就是用 setTimeout + clearTimeout 普通js代码如下: / 下面是普通的j ...
- ORM模板层
1.模板语言之变量 def index(request): name='lqz' age=18 ll=['name','age'] dic={'name':name,'age':age} class ...
- 【LeetCode每天一题】Reverse Integer(反转数字)
Given a 32-bit signed integer, reverse digits of an integer. Example 1: ...
- HttpwebRequest - 带ViewState的网页POST请求
这是我今天下午碰到的案例,一个退订页面的post请求,请求头信息都很明确,but看看下面这个请求体,除了最后一个key是我的页面控件名称,其他的几个ViewState相关都是what呢?(ViewSt ...
- https://sweetalert2.github.io/
https://sweetalert2.github.io/
- 配置完centos 6以后,大概需要安装的软件(主要是yum)
根据实践,把我的经验说一下,以后我自己也可以按照这个快速安装软件. 1. 配置源.百度网盘的tools/download/linux已经放了几个挺重要的 东西了. yum -y install epe ...
- 第二章:Opencv核心類Mat
Opecv就是做計算機視覺,就是讲图片转换成计算机所能识别的数据 Mat类中由大量的内联函数,主要就是用于提高速度. 一般类型都用rgb,存的时候用CV_8UC3.create函数一般会把原来的空间释 ...
- java 基础功能
1.str.length();// 获取整个字符串的长度 public class Test { public static void main(String[] args) { String s = ...
- linux的swap相关
linux的系统采用的内存方案一般都是 物理内存+swap.物理内存供日常使用,swap用来救急. 但在实际使用的过程中,发现有时候物理内存还没被完全占用的情况下,已经开始使用swap了.而这时候,由 ...
- 在caffe中执行脚本文件时 报错:-bash: ./train.sh: Permission denied
报错原因:没有权限 解决方法:chmod 777 train.sh获得权限