opencv3.1线性可分svm例子及函数分析
https://www.cnblogs.com/qinguoyi/p/7272218.html
//摘自:http://docs.opencv.org/2.4/doc/tutorials/ml/introduction_to_svm/introduction_to_svm.html
#include <opencv2/core/core.hpp>
#include <opencv2/highgui/highgui.hpp>
#include <opencv2/ml/ml.hpp>
#include <iostream> using namespace cv;
using namespace cv::ml; int main()
{
// Data for visual representation
int width = 512, height = 512;
Mat image = Mat::zeros(height, width, CV_8UC3); // Set up training data
int labels[4] = { 1, -1, -1, -1};
Mat labelsMat(4, 1, CV_32SC1, labels); //将labels转换成4行1列的32位单通道字符型阵列 float trainingData[4][2] = { { 501, 10 }, { 255, 10 }, { 501, 255 }, { 10, 501 } };
Mat trainingDataMat(4, 2, CV_32FC1, trainingData);//将训练数据转换成4行2列的32位单通道浮点型阵列 // Set up SVM's parameters
Ptr<SVM> svm = SVM::create();//建立一个空的svm文件
svm->setType(SVM::Types::C_SVC);
svm->setKernel(SVM::KernelTypes::LINEAR);
svm->setTermCriteria (cvTermCriteria(CV_TERMCRIT_ITER, 100, 1e-6));//SVM的迭代训练过程的中止条件 // Train the SVM
svm->StatModel::train(trainingDataMat, SampleTypes::ROW_SAMPLE, labelsMat); Vec3b green(0, 255, 0), blue(255, 0, 0);
// Show the decision regions given by the SVM
for (int i = 0; i < image.rows; ++i)
{
for (int j = 0; j < image.cols; ++j)
{
Mat sampleMat = (Mat_<float>(1, 2) << j,i);//将每个i, j按照顺序输入进Mat
float response = svm->predict(sampleMat);
//std::cout << sampleMat << std::endl;
//std::cout << response << std::endl;
if (response == 1)
image.at<Vec3b>(i,j) = green;
else if (response == -1)
image.at<Vec3b>(i,j) = blue;
//std::cout << image.at<Vec3b>(i, j) << std::endl;
}
}
imshow("SVM Simple Example", image); // show it to the user
waitKey(0);
std::cout << "done" << std::endl;
}

opencv3.1属于阉割版的opencv,很多以前的函数被改版,甚至删除掉,比如circle函数。
Mat初始化
Mat sampleMat = (Mat_<float>(1, 2) << j,i);是Mat的一种初始化方式,将每次循环的i,j输入进Mat,然后初始化。
.at<Vec3b>(i,j)
image.at<Vec3b>(i,j),.at(int y, int x)表示用来存取图像中对应坐标为(x, y)的元素坐标,<type>为类型。Vec3b表示三通道的赋值类型。
Vec3b green(0, 255, 0),也可以 Vec3b green;green[0]=0;green[1]=255;green[2]=0。
- SVM::C_SVC : C类支持向量分类机。 n类分组 (n≥2),允许用异常值惩罚因子C进行不完全分类。
- SVM::NU_SVC :
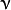 类支持向量分类机。n类似然不完全分类的分类器。参数为取代C(其值在区间【0,1】中,nu越大,决策边界越平滑)。
类支持向量分类机。n类似然不完全分类的分类器。参数为取代C(其值在区间【0,1】中,nu越大,决策边界越平滑)。 - SVM::ONE_CLASS : 单分类器,所有的训练数据提取自同一个类里,然后SVM建立了一个分界线以分割该类在特征空间中所占区域和其它类在特征空间中所占区域。
- SVM::EPS_SVR :
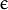 类支持向量回归机。训练集中的特征向量和拟合出来的超平面的距离需要小于p。异常值惩罚因子C被采用。
类支持向量回归机。训练集中的特征向量和拟合出来的超平面的距离需要小于p。异常值惩罚因子C被采用。 - SVM::NU_SVR : 类支持向量回归机。 代替了 p。
<2>kernel_type:SVM的内核类型(4种):
- SVM::LINEAR : 线性内核,没有任何向映射至高维空间,线性区分(或回归)在原始特征空间中被完成,这是最快的选择。
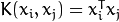 .
.- SVM::POLY : 多项式内核:
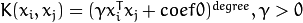 .
.- SVM::RBF : 基于径向的函数,对于大多数情况都是一个较好的选择:
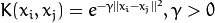 .
.- SVM::SIGMOID : Sigmoid函数内核:
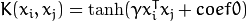 .
.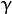 。。
。。 。
。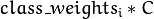 。所以这些权重影响不同类别的错误分类惩罚项。权重越大,某一类别的误分类数据的惩罚项就越大。
。所以这些权重影响不同类别的错误分类惩罚项。权重越大,某一类别的误分类数据的惩罚项就越大。CvTermCriteria
迭代算法的终止准则
#define CV_TERMCRIT_ITER 1
#define CV_TERMCRIT_NUMBER CV_TERMCRIT_ITER
#define CV_TERMCRIT_EPS 2
typedef struct CvTermCriteria {
int type; /* CV_TERMCRIT_ITER 和CV_TERMCRIT_EPS二值之一,或者二者的组合 */
int max_iter; /* 最大迭代次数 */
double epsilon; /* 结果的精确性 */
}
CvTermCriteria;
/* 构造函数 */
inline CvTermCriteria cvTermCriteria( int type, int max_iter, double epsilon );
svm->setType(SVM::Types::C_SVC);
svm->setKernel(SVM::KernelTypes::LINEAR);
svm->setTermCriteria (cvTermCriteria(CV_TERMCRIT_ITER, 100, 1e-6));//100是迭代次数,1e-6是精确度。
上面的3-9都是有使用条件的,比如LINEAR为内核的时候,3-9都是不需要的,设置完如上代码后可以直接训练,也可以调用自动训练函数,那样的话其实意义不大:
svm->StatModel::train(trainingDataMat, SampleTypes::ROW_SAMPLE, labelsMat);
svm_ = cv::ml::SVM::create();
svm_->setType(cv::ml::SVM::C_SVC);
svm_->setKernel(cv::ml::SVM::RBF);
svm_->setDegree(0.1);
// 1.4 bug fix: old 1.4 ver gamma is 1 //1.4版本bug修复
svm_->setGamma(1);
svm_->setCoef0(0.1);
svm_->setC(1);
svm_->setNu(0.1);
svm_->setP(0.1);
svm_->setTermCriteria(cvTermCriteria(CV_TERMCRIT_ITER, 20000, 0.0001));
svm_->train(train_data);
Ptr<cv::ml::TrainData>tdata; //将训练数据和标签整合成tdata
tdata = TrainData::create(trainingDataMat, cv::ml::SampleTypes::ROW_SAMPLE, labelsMat);
svm->trainAuto(tdata, 10,
SVM::getDefaultGrid(SVM::C),
SVM::getDefaultGrid(SVM::GAMMA),
SVM::getDefaultGrid(SVM::P),
SVM::getDefaultGrid(SVM::NU),
SVM::getDefaultGrid(SVM::COEF),
SVM::getDefaultGrid(SVM::DEGREE),
true);
- k_fold: 交叉验证参数。训练集被分成k_fold的自子集。其中一个子集是用来测试模型,其他子集则成为训练集。所以,SVM算法复杂度是执行k_fold的次数。
- *Grid: (6个)对应的SVM迭代网格参数。
- balanced: 如果是true则这是一个2类分类问题。这将会创建更多的平衡交叉验证子集。
训练完成后保存txt或者xml文件:
svm->save("svm_image.xml");
OpenCV3.1中载入模型的语句:
//Ptr<SVM> svmp = SVM::create();
//svmp = SVM::load<SVM>("svm_image.xml");
Ptr<SVM> svmp = SVM::load<SVM>("svm_image.xml");
载入之后就可以进行预测了:
//返回的是预测数据距离决策面(超平面)的几何距离
float response = svmp->predict(sampleMat, noArray(), StatModel::Flags::RAW_OUTPUT); //返回的是标签分类
float response = svmp->predict(sampleMat, noArray(), 0);
float response = svmp->predict(sampleMat);
opencv3.1线性可分svm例子及函数分析的更多相关文章
- 线性可分SVM中线性规划问题的化简
在网上找了许多关于线性可分SVM化简的过程,但似乎都不是很详细,所以凭借自己的理解去详解了一下. 线性可分SVM的目标是求得一个超平面(其实就是求w和b),在其在对目标样本的划分正确的基础上,使得到该 ...
- Support Vector Machine(2):Lagrange Duality求解线性可分SVM的最佳边界
在上篇文章<Support Vector Machine(1):线性可分集的决策边界>中,我们最后得到,求SVM最佳Margin的问题,转化为了如下形式: 到这一步后,我个人又花了很长的时 ...
- 线性可分SVM完全推导过程
- SVM清晰讲解——线性可分问题
转载作者:liangdas 引言: 1995年Cortes和Vapnik于首先提出了支持向量机(Support Vector Machine),由于其能够适应小样本的分类,分类速度快等特点,性能不差于 ...
- 线性可分支持向量机与软间隔最大化--SVM(2)
线性可分支持向量机与软间隔最大化--SVM 给定线性可分的数据集 假设输入空间(特征向量)为,输出空间为. 输入 表示实例的特征向量,对应于输入空间的点: 输出 表示示例的类别. 我们说可以通过间隔最 ...
- 线性可分支持向量机--SVM(1)
线性可分支持向量机--SVM (1) 给定线性可分的数据集 假设输入空间(特征向量)为,输出空间为. 输入 表示实例的特征向量,对应于输入空间的点: 输出 表示示例的类别. 线性可分支持向量机的定义: ...
- SVM明确的解释1__
线性可分问题
笔者:liangdas 出处:简单点儿,通俗点儿,机器学习 http://blog.csdn.net/liangdas/article/details/44251469 引言: 1995年Cor ...
- svm 之 线性可分支持向量机
定义:给定线性可分训练数据集,通过间隔最大化或等价的求解凸二次规划问题学习获得分离超平面和分类决策函数,称为线性可分支持向量机. 目录: • 函数间隔 • 几何间隔 • 间隔最大化 • 对偶算法 1. ...
- 统计学习:线性可分支持向量机(SVM)
模型 超平面 我们称下面形式的集合为超平面 \[\begin{aligned} \{ \bm{x} | \bm{a}^{T} \bm{x} - b = 0 \} \end{aligned} \tag{ ...
随机推荐
- vux 是基于 WeUI 和Vue(2.x)开发的移动端UI组件库,主要服务于微信页面。
https://doc.vux.li/zh-CN/ https://vux.li/
- vue接口地址配一个全局的
main.js加 if (process.env.NODE_ENV !== 'development') { Vue.prototype.URL_PREFIX = 'http://139.196.7. ...
- jenkins 常用插件和配置项介绍和使用
jenkins 上搜索不到的插件可以在如下地址下载: http://updates.jenkins-ci.org/download/plugins/ 1.Notification Plugin 介绍: ...
- GCC 用户态&内核态 Makefile
转了一圈,今天再次回到C 网上一篇博文,个人感觉良心作品,故而拿来重新实现一遍,原作者原文有问题,我这里把他打通了 一.GCC Makefile //hello.c #include <stdi ...
- smali加入日志
const-string v0, "aaatag"const-string v1, "msg"invoke-static {v0,v1}, Landroid/u ...
- Selenium基础知识(二)鼠标操作
一.鼠标操作 这个需要使用webdriver下的ActionChains类,这个类是操作鼠标操作的: from selenium.webdriver import ActionChains 鼠标操作可 ...
- AutoMapper.Mapper.CreateMap报“System.NullReferenceException: 未将对象引用设置到对象的实例。”异常复现
>>Agenda: >>Ⅰ.国庆假期问题出现 >>Ⅱ.双休日异常再次出现 >>Ⅲ.排障 >>Ⅳ.异常复盘 >>Ⅴ.修复后监测 & ...
- 独立出properties的mybatis连接池
jdbc.driver=com.mysql.jdbc.Driver jdbc.url=jdbc:mysql://localhost:3306/java505?useSSL=true&chara ...
- python时间和日期
一.time 和 calendar 模块可以用于格式化日期和时间 import time; # 引入time模块 ticks = time.time() print "当前时间戳为:&quo ...
- 恢复Windows10应用商店
用管理员权限运行powershell,输入 Get-AppxPackage -AllUsers| Foreach {Add-AppxPackage -DisableDevelopmentMode -R ...