【读书笔记】Data_Mining_with_R---Chapter_2_Predicting Algae Blooms
本书概要
《Data Mining with R》这本书通过实例,并结合R讲解数据挖掘技术。本书的核心理念就是“Learning it by doing”。本书分5章,第一章介绍R和MySql的基本知识,后面4章分别结合4个案例进行讲解。最精刚刚看完第二章,觉得还是学习了一些新的东西,在这里记录一下,作为备忘。
本章背景
藻类的过渡繁殖会破坏河流生态。希望找到一种办法对河流内的藻类生长情况进行预测。在生物化学领域,很容易测量河流中的化学物质,但是生物测量的成本很高,比如观察每立方米藻类数量,需要受过训练的人员测定,而且效率低。所以,希望找到一种方法通过河流中的化学元素预测藻类含量。同时还可以更好的了解哪些化学元素主要影响藻类的生长。
数据描述
数据可以从本书的R包(DMwR)中下载,该包可以通过下面的R命令直接安装:
> install.packages(“DMwR”)
加载库和本案例的数据可以用下面的代码
> library(“DMwR”)
> data(algae)
数据格式如下,主要有3个名词变量,描述观测季节,河流大小和河流速度;8个数值变量,分别记录8中不同化学物质的含量;需要预测7种藻类的含量。实验数据有200条记录,其中有些记录的部分数据有缺失。加载完数据后,可以用如下命令查看数据,
> head(algae)
虽然有7个变量需要预测,其实可以理解为对一个变量进行回归预测,然后复用到其他6个变量中,只是每个变量的模型可能不同。
数据可视化
验证正太分布
看看mxPH的值,有点类似正太分布,
plot(algae$mxPH,prob=T)
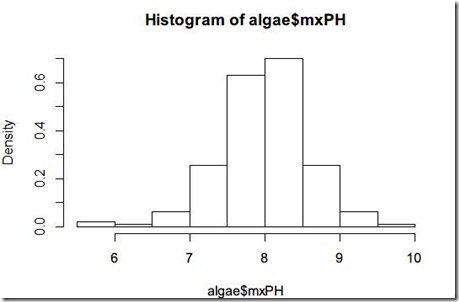
prob=T参数用于将纵坐标转成比例,那么就可以在这个图上直接绘制正态分布的概率函数了。
lines(density(algae$mxPH, na.rm=T))
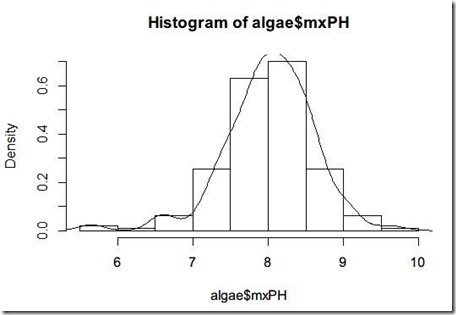
看起来的确符合正太分布,但是这样还是不太有把握,好在可以使用car包中的qq-plot[1][2]图来观察符合的情况。
library(car)
qq.plot(algae$mxPH, main = ‘Normal QQ plot of maximum PH’)
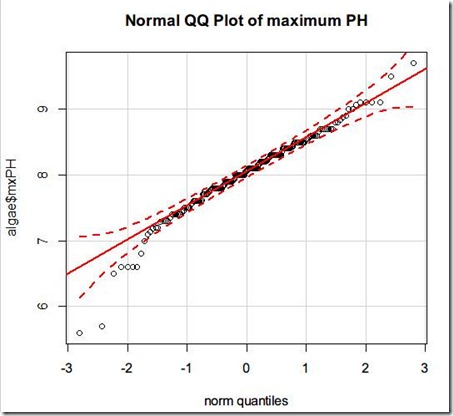
如果mxPH符合正太分布,那么数据点应该落在实现上,虚线是95%的置信区间,也就是落在虚线内的点有95%可能属于正太分布。那么,从上述图中可以看出,除了较低的数据不在虚线范围内,大多数数据落在95%的置信区间的范围内,所以可以认为符合正太分布(用上述方法观察其他变量,可以发现基本上都不符合正太分布)。
分类绘图
使用lattce库(一个R的可视化包),可以将不同数据按照指定类型分类,然后绘制图形,如下所示,可以根据season变量,绘制不同的mxPH的直方图,
> algae$season <- factor(algae$season,levels = c('spring','summer','autumn','winter'))
> histogram(~mxPH | season, data = algae)
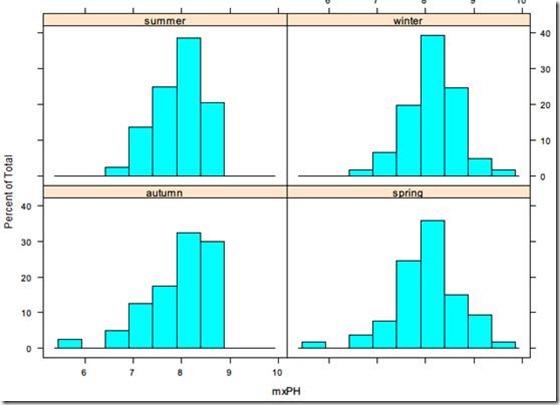
lattce还可以绘制交叉属性图,
> histogram(~mxPH|season*size,algae)
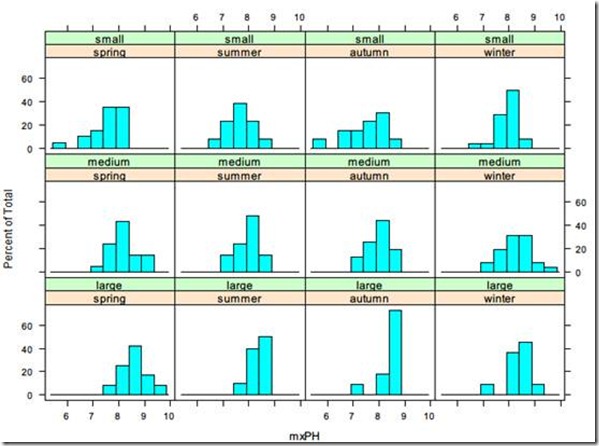
多为度散点图可以通过下面的命令
> stripplot(size ~ mxPH | speed, data = algae, jitter = T,pch = 19)
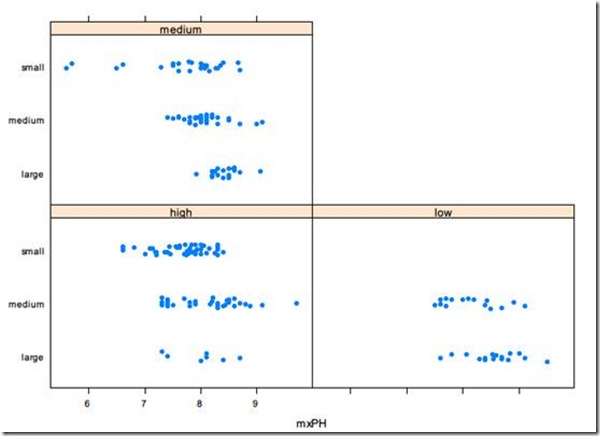
jitter参数用于添加轻微的颤抖,避免数据重合。
NA数据处理
原始数据不可避免的会有NA(Not Avaliable)数据,处理NA数据有一下几个基本原则:
1. 去掉带有NA数据的记录
2. 通过变量(列)之间的关系,计算NA数据
3. 通过记录(行)之间的关系,计算NA数据,如KNN
4. 使用可以处理NA数据的模型(有些模型可以容忍NA,有些不能)
统计方法填充NA
符合正太分布的数据如(mxPH),可以使用平均值来填补NA数据,因为这些数据都均匀的分布在平均值左右。但是如何是倾斜太大(如OP4)或是有异类值(非常大的值),采用中位数更好,因为此时平均值已经不能很好的描述总体了。
变量关联填充NA
如果变量之间存在一定的关联,那么可以通过此联系计算出NA值。R中提供了一个很方便的函数cor查看所有变量之间的相关系数[3],如下:
> symnum(cor(algae[,4:18],use = “complete.obs”))
生成如下数据
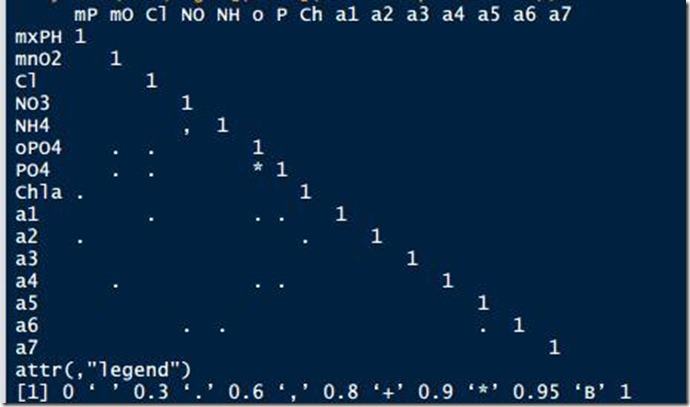
可以看到,“*”表示两个变量的相关度达到0.9(相关度处于-1到1之间,绝对值越大,越相关),use = “complete.obs”类似na.rm = T。从领域专家那里,也可以得知oPO4和PO4的含量是相关的。接下来就可以使用线性回归[4]计算缺失值。
相似性填充NA
如果变量之间没有显著的相似性,那么上述方法没有多大作用。这时可以使用记录之间的相似性填充NA,一般使用KNN[5](K Nearest Neighbor)。R中的impitation和impute两个包具有类似函数,DMwR包中也提供类似函数knnImputation。
多元线性回归
线性回归模型无法接受NA数据,所以需要先用前面将的方法填充NA。线性模型可以使用lm函数获得,这里略去。接下来讨论一下如何评估模型的好坏。
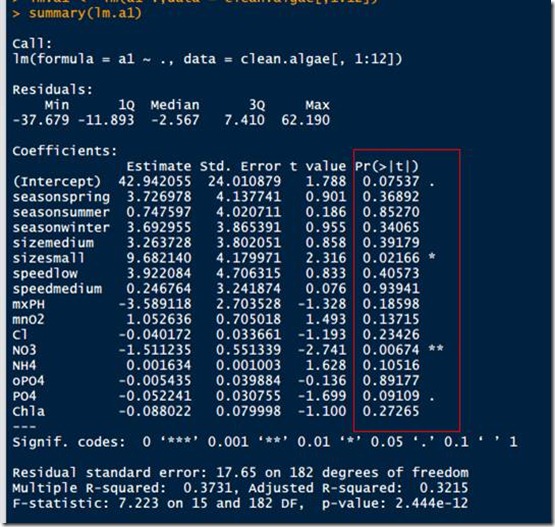
一般会看每个计算出来的系数的假设检验结果。lm计算出的结果会对每个参数计算假设检验,原始假设:H0: β=0。检测结果是Pr(>|t|)这一类对应的值(采用t分布测试,变量是系数与标准差的比例)。一般来讲,0.1以下拒绝原始假设,接受系数不为0。
方差分析可以用来判断变量的重要性,可以通过一步一步的去掉不重要的变量来逐步找到最有效的模型,
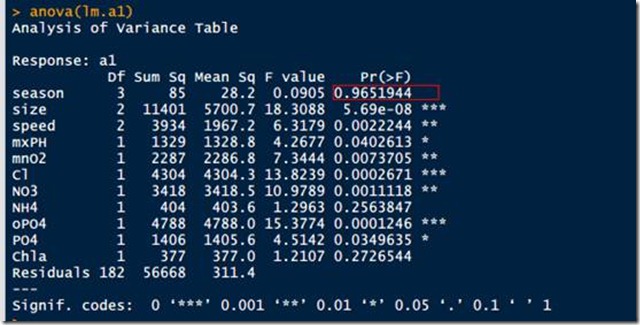
上面的方差分析可以看出season的作用最弱,所以可以去掉,采用下面的命令
> lm2.a1 <- update(lm.a1, .~.-season)
> lm2.a1
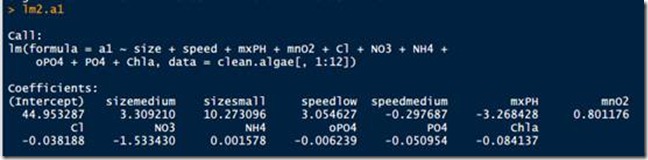
已经没有season变量了。这样,一步一步的裁剪掉不重要的变量,得到最后的线性模型。但是,R也提供一个便捷的方法,一次性完成上面的操作,如下:
> final.lm <- step(lm.a1)
线性模型有个最直观的判别方法就是R-Squared参数(介于0到1之间),有点类是变量的相关性,但考虑的所有变量。一般来讲,如果这个值小于0.5,说明线性模型不适合这个问题。
rpart决策树
决策树计算回归时,纯度是用deviance(节点内每个记录值与均值的差的平方和)描述。这个值越小,说明越纯。
控制树的创建结束有三个参数
1. cp,当前节点deviance与两个子节点deviance之和的差的比例,如果分裂前后deviance之差越大,那么说明切分的越好
2. minsplit,分裂后节点的小于此阀值后就不再分裂
3. maxdepth,书的最大深度
rpart包提供printcp,用于辅助评估最佳的切分cp,可以看看输出结果:
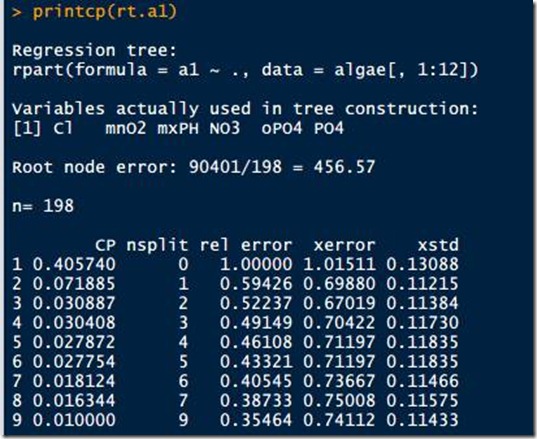
rpart函数在构建树时尝试用不同的cp值构建的不同大小的数(nsplit),并用K Folder交叉检验评估了不同树的相对错误率(xerror)和方差(xstd)。可以直接通过最小xerror来选择最优树,这里选择3号。也可以使用X-SE的方法,这里定X=1,也就是1-SE(1个标准差)。那么3号树的1-SE = 0.67019+0.11215 = 0.784037,选择xerror比这个值小且具有最少分割点的树,也就是2号树(nsplit = 1),作为最终的树,最后,用下面的命令给树截肢:
> rt2.a1 <- prunt(rt.a1, cp = 0.072)
得到的树如下:
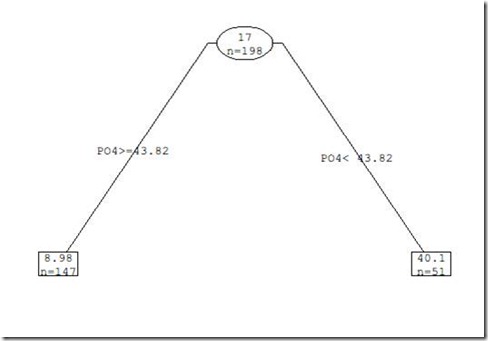
进一步阅读:
1. Beriman et al. 1984 决策树鼻祖,主要使用统计方法,此书目前还没有找到资料。
2. C4.5 by Quinlan (1993),主要从机器学习领域描述分类决策树,C5.0已经运用于商业领域,CSDN上可以下载到。
3. 作者的博士论文 “Torgo 1999a”,google这个关键字可以找到在线资料
模型评估和选取
回归树评估可以使用下面几个指标
MAE mean absolute error,预测值与真实值差的绝对值的均值
NMAE normalized mean absoulate error, 计算方法:MAE /平均值与真实值差的绝对值的均值
MSE mean squared error,预测值与真实值差的平方的均值。
NMSE normalized mean squared error,计算方法:MSE / 平均值与真实值差的平方的均值
(上面的值越小越好,大于等于1说明预测的结果还不如直接用均值预测!)
本节中的k-fold框架以后可以直接拿来复用,很方便。可以使用不同参数和模型的组合,并且为每个组合进行n次k-fold交叉测试(n和k都可以设置)。作者还实现了一个配套的plot函数,可以用箱盒图直观的查看不同组合的评估结果。
参考
[1] QQ-plot Wiki: http://en.wikipedia.org/wiki/Q%E2%80%93Q_plot
[2] QQ-plot百度百科:http://baike.baidu.com/view/8040278.htm
[3] Wiki: 相关系数http://zh.wikipedia.org/wiki/%E7%9B%B8%E5%85%B3
[4] Wiki:线性回归 http://en.wikipedia.org/wiki/Linear_regression
[5] 互动百科KNN http://www.baike.com/wiki/KNN
【读书笔记】Data_Mining_with_R---Chapter_2_Predicting Algae Blooms的更多相关文章
- 读书笔记汇总 - SQL必知必会(第4版)
本系列记录并分享学习SQL的过程,主要内容为SQL的基础概念及练习过程. 书目信息 中文名:<SQL必知必会(第4版)> 英文名:<Sams Teach Yourself SQL i ...
- 读书笔记--SQL必知必会18--视图
读书笔记--SQL必知必会18--视图 18.1 视图 视图是虚拟的表,只包含使用时动态检索数据的查询. 也就是说作为视图,它不包含任何列和数据,包含的是一个查询. 18.1.1 为什么使用视图 重用 ...
- 《C#本质论》读书笔记(18)多线程处理
.NET Framework 4.0 看(本质论第3版) .NET Framework 4.5 看(本质论第4版) .NET 4.0为多线程引入了两组新API:TPL(Task Parallel Li ...
- C#温故知新:《C#图解教程》读书笔记系列
一.此书到底何方神圣? 本书是广受赞誉C#图解教程的最新版本.作者在本书中创造了一种全新的可视化叙述方式,以图文并茂的形式.朴实简洁的文字,并辅之以大量表格和代码示例,全面.直观地阐述了C#语言的各种 ...
- C#刨根究底:《你必须知道的.NET》读书笔记系列
一.此书到底何方神圣? <你必须知道的.NET>来自于微软MVP—王涛(网名:AnyTao,博客园大牛之一,其博客地址为:http://anytao.cnblogs.com/)的最新技术心 ...
- Web高级征程:《大型网站技术架构》读书笔记系列
一.此书到底何方神圣? <大型网站技术架构:核心原理与案例分析>通过梳理大型网站技术发展历程,剖析大型网站技术架构模式,深入讲述大型互联网架构设计的核心原理,并通过一组典型网站技术架构设计 ...
- LOMA280保险原理读书笔记
LOMA是国际金融保险管理学院(Life Office Management Association)的英文简称.国际金融保险管理学院是一个保险和金融服务机构的国际组织,它的创建目的是为了促进信息交流 ...
- 《3D Math Primer for Graphics and Game Development》读书笔记2
<3D Math Primer for Graphics and Game Development>读书笔记2 上一篇得到了"矩阵等价于变换后的基向量"这一结论. 本篇 ...
- 《3D Math Primer for Graphics and Game Development》读书笔记1
<3D Math Primer for Graphics and Game Development>读书笔记1 本文是<3D Math Primer for Graphics and ...
随机推荐
- Evolution ZOJ2853
矩阵太大导致爆栈 解决方法:矩阵不要开在main函数里面 全部在外面处理 main函数只能处理简单的赋值和加减 损失的要自减!! 最后为 sum+=t[i]*ans.m[i][n-1]; 得 ...
- 6-17 看图写树 uva10562
非常好的dfs题 有很多细节 关于‘ ’ ‘0’ ’\n‘ 的处理 他们都属于isspace函数 其中 while(buf[x+2][i]=='-'&&buf[x+3][i] ...
- pyrhon SQLite数据库
pyrhon SQLite数据库 目录 介绍 导入模块 创建数据库/打开数据库 创建表 在表中插入行 查询/修改 删除表中的行 删除表 介绍 Python SQLITE数据库是一款非常小巧的嵌入式开源 ...
- ASP.NET Core 文件系统
ASP.NET Core 文件系统 静态文件 目录浏览 默认页面 MIME类型配置 实战文件服务器 紧接上一讲 中间件 之后,今天来我们来讲一下关于 ASP.NET Core 中静态文件服务. 什 ...
- Alpha冲刺随笔—:第一天
课程名称:软件工程1916|W(福州大学) 作业要求:项目Alpha冲刺(十天冲刺) 团队名称:葫芦娃队 作业目标:在十天冲刺里对每天的任务进行总结. 随笔汇总:https://www.cnblogs ...
- BZOJ.2756.[SCOI2012]奇怪的游戏(二分 黑白染色 最大流ISAP)
题目链接 \(Description\) \(Solution\) 这种题当然要黑白染色.. 两种颜色的格子数可能相同,也可能差1.记\(n1/n2\)为黑/白格子数,\(s1/s2\)为黑/白格子权 ...
- 潭州课堂25班:Ph201805201 并发(进程与线程池) 第十四课 (课堂笔记)
循环执行一个线程 # -*- coding: utf-8 -*- # 斌彬电脑 # @Time : 2018/7/20 0020 5:35 import threading import queue ...
- node+express上传图片
注意: 别用multer 上传文件了,太坑了,普通文本获取不到,折腾了半天没有解决,最后采用 multiparty 解决了: <!DOCTYPE html><html> < ...
- 使用C3P0报错:java.lang.NoClassDefFoundError: com/mchange/v2/ser/Indirector
错误提示: java.lang.NoClassDefFoundError: com/mchange/v2/ser/Indirector at JDBC.ConnectionPool.testC3P0( ...
- 启明星系统安装教程(如何在windows2012里配置IIS)
(1)安装IIS 因为在windows2012里,安装数据库,IIS部分组件都需要.NET3.5,而默认windows2012安装时,并不会把此组件复制到电脑里 导致,后期要安装.NET3.5还需要安 ...