MapReduce(四)
MapReduce(四)
1.shuffle过程
2.map中setup,map,cleanup的作用。
一.shuffle过程
https://blog.csdn.net/techchan/article/details/53405519
来张图吧
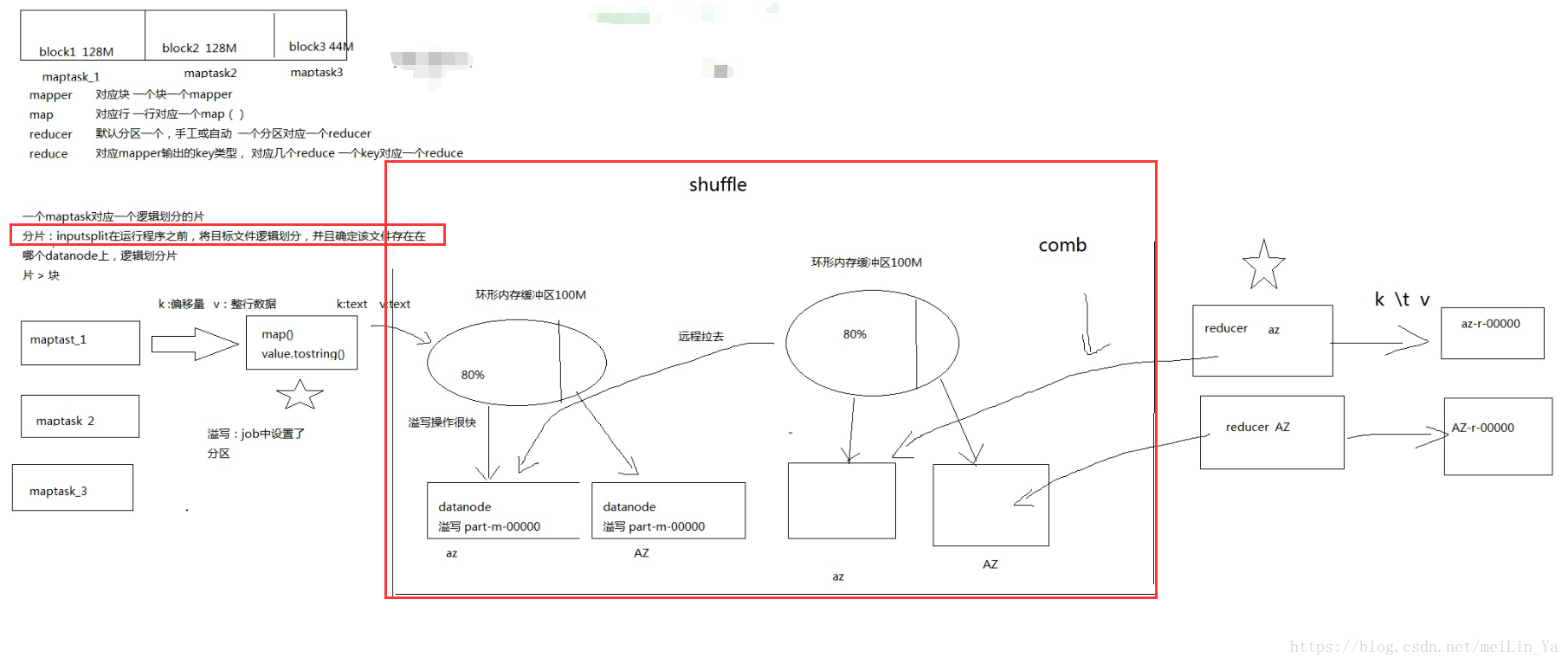
二.map中setup,map,cleanup的作用。
- setup(),此方法被MapReduce框架仅且执行一次,在执行Map任务前,进行相关变量或者资源的集中初始化工作。若是将资源初始化工作放在方法map()中,导致Mapper任务在解析每一行输入时都会进行资源初始化工作,导致重复,程序运行效率不高!
- run()映射k,v 数据
- cleanup(),此方法被MapReduce框架仅且执行一次,在执行完毕Map任务后,进行相关变量或资源的释放工作。若是将释放资源工作放入方法map()中,也会导致Mapper任务在解析、处理每一行文本后释放资源,而且在下一行文本解析前还要重复初始化,导致反复重复,程序运行效率不高!
代码测试 Cleanup的作用
package com.huhu.day04;
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.IOException;
import java.net.URI;
import java.util.HashSet;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.filecache.DistributedCache;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.partition.HashPartitioner;
import org.apache.hadoop.util.GenericOptionsParser;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
/**
* 在这里进行wordCount统计 在一遍英语单词中 不统计 i have 这两个单词
*
* @author huhu_k
*
*/
public class TestCleanUpEffect extends ToolRunner implements Tool {
private Configuration conf;
public static class MyMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
private Path[] localCacheFiles;
// 不通过MapReduce过滤计算的word
private HashSet<String> keyWord;
@Override
protected void setup(Context context) throws IOException, InterruptedException {
Configuration conf = context.getConfiguration();
localCacheFiles = DistributedCache.getLocalCacheFiles(conf);
keyWord = new HashSet<>();
for (Path p : localCacheFiles) {
BufferedReader br = new BufferedReader(new FileReader(p.toString()));
String word = "";
while ((word = br.readLine()) != null) {
String[] str = word.split(" ");
for (String s : str) {
keyWord.add(s);
}
}
br.close();
}
}
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] line = value.toString().split(" ");
for (String str : line) {
for (String k : keyWord) {
if (!str.contains(k)) {
context.write(new Text(str), new IntWritable(1));
}
}
}
}
@Override
protected void cleanup(Mapper<LongWritable, Text, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
}
}
public static class MyReduce extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
int sum = 0;
for (IntWritable v : values) {
sum += v.get();
}
context.write(key, new IntWritable(sum));
}
}
public static void main(String[] args) throws Exception {
TestCleanUpEffect t = new TestCleanUpEffect();
Configuration conf = t.getConf();
String[] other = new GenericOptionsParser(conf, args).getRemainingArgs();
if (other.length != 2) {
System.err.println("number is fail");
}
int run = ToolRunner.run(conf, t, args);
System.exit(run);
}
@Override
public Configuration getConf() {
if (conf != null) {
return conf;
}
return new Configuration();
}
@Override
public void setConf(Configuration arg0) {
}
@Override
public int run(String[] other) throws Exception {
Configuration con = getConf();
DistributedCache.addCacheFile(new URI("hdfs://ry-hadoop1:8020/in/advice.txt"), con);
Job job = Job.getInstance(con);
job.setJarByClass(TestCleanUpEffect.class);
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setReducerClass(MyReduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(other[0]));
FileOutputFormat.setOutputPath(job, new Path(other[1]));
return job.waitForCompletion(true) ? 0 : 1;
}
}我是使用在setup中过滤另一个文件:advice 然后通过运行,wordCount时,adivce中有的word则过滤不计算。我的数据分别是:

运行结果:
测试mapper中cleanup的作用
package com.huhu.day04;
import java.io.IOException;
import java.util.HashMap;
import java.util.Map;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.partition.HashPartitioner;
import org.apache.hadoop.util.GenericOptionsParser;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class TestCleanUpEffect extends ToolRunner implements Tool {
private Configuration conf;
public static class MyMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
private Map<String, Integer> map = new HashMap<String, Integer>();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] line = value.toString().split(" ");
for (String s : line) {
if (map.containsKey(s)) {
map.put(s, map.get(s) + 1);
} else {
map.put(s, 1);
}
}
}
@Override
protected void cleanup(Context context) throws IOException, InterruptedException {
for (Map.Entry<String, Integer> m : map.entrySet()) {
context.write(new Text(m.getKey()), new IntWritable(m.getValue()));
}
}
}
public static class MyReduce extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
protected void setup(Context context) throws IOException, InterruptedException {
}
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
for (IntWritable v : values) {
context.write(key, new IntWritable(v.get()));
}
}
@Override
protected void cleanup(Context context) throws IOException, InterruptedException {
}
}
public static void main(String[] args) throws Exception {
TestCleanUpEffect t = new TestCleanUpEffect();
Configuration conf = t.getConf();
String[] other = new GenericOptionsParser(conf, args).getRemainingArgs();
if (other.length != 2) {
System.err.println("number is fail");
}
int run = ToolRunner.run(conf, t, args);
System.exit(run);
}
@Override
public Configuration getConf() {
if (conf != null) {
return conf;
}
return new Configuration();
}
@Override
public void setConf(Configuration arg0) {
}
@Override
public int run(String[] other) throws Exception {
Configuration con = getConf();
Job job = Job.getInstance(con);
job.setJarByClass(TestCleanUpEffect.class);
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
// 默认分区
job.setPartitionerClass(HashPartitioner.class);
job.setReducerClass(MyReduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileInputFormat.addInputPath(job, new Path(other[0]));
FileOutputFormat.setOutputPath(job, new Path(other[1]));
return job.waitForCompletion(true) ? 0 : 1;
}
}使用map来处理数据,减小reducer的压力,并使用mapper中的cleanup方法
运行结果
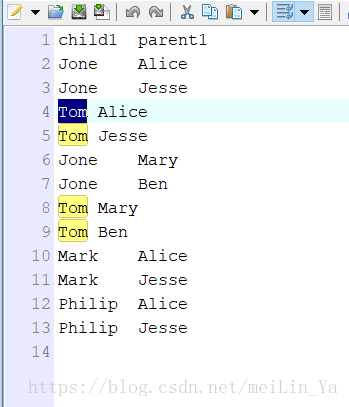
打印孩子的所有父母(爷爷,姥爷,奶奶,姥姥),看下数据

package com.huhu.day04;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
/**
* 分代计算 将 孩子 父母 奶奶 姥姥 分为一代
*
* @author huhu_k
*
*/
public class ProgenyCount extends ToolRunner implements Tool {
public static class MyMapper extends Mapper<LongWritable, Text, Text, Text> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] line = value.toString().split(" ");
String childname = line[0];
String parentname = line[1];
if (line.length == 2 && !value.toString().contains("child")) {
context.write(new Text(childname), new Text("t1:" + childname + ":" + parentname));
context.write(new Text(parentname), new Text("t2:" + childname + ":" + parentname));
}
}
}
public static class MyReduce extends Reducer<Text, Text, Text, Text> {
boolean flag = true;
@Override
protected void setup(Context context) throws IOException, InterruptedException {
}
@Override
protected void reduce(Text key, Iterable<Text> values, Context context)
throws IOException, InterruptedException {
if (flag) {
context.write(new Text("child1"), new Text("parent1"));
flag = false;
}
List<String> child = new ArrayList<>();
List<String> parent = new ArrayList<>();
for (Text v : values) {
String line = v.toString();
System.out.println(line+"**");
if (line.contains("t1")) {
parent.add(line.split(":")[2]);
System.err.println(line.split(":")[2]);
} else if (line.contains("t2")) {
System.out.println(line.split(":")[1]);
child.add(line.split(":")[1]);
}
}
for (String c : child) {
for (String p : parent) {
context.write(new Text(c), new Text(p));
}
}
}
}
public static void main(String[] args) throws Exception {
ProgenyCount t = new ProgenyCount();
Configuration conf = t.getConf();
String[] other = new GenericOptionsParser(conf, args).getRemainingArgs();
if (other.length != 2) {
System.err.println("number is fail");
}
int run = ToolRunner.run(conf, t, args);
System.exit(run);
}
@Override
public Configuration getConf() {
return new Configuration();
}
@Override
public void setConf(Configuration arg0) {
}
@Override
public int run(String[] other) throws Exception {
Configuration con = getConf();
Job job = Job.getInstance(con);
job.setJarByClass(ProgenyCount.class);
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
// 默认分区
// job.setPartitionerClass(HashPartitioner.class);
job.setReducerClass(MyReduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileInputFormat.addInputPath(job, new Path("hdfs://ry-hadoop1:8020/in/child.txt"));
Path path = new Path("hdfs://ry-hadoop1:8020/out/mr");
FileSystem fs = FileSystem.get(getConf());
if (fs.exists(path)) {
fs.delete(path, true);
}
FileOutputFormat.setOutputPath(job, path);
return job.waitForCompletion(true) ? 0 : 1;
}
}
MapReduce(四)的更多相关文章
- mapreduce (四) MapReduce实现Grep+sort
1.txt dong xi cheng xi dong cheng wo ai beijing tian an men qiche dong dong dong 2.txt dong xi cheng ...
- MapReduce(四) 典型编程场景(二)
一.MapJoin-DistributedCache 应用 1.mapreduce join 介绍 在各种实际业务场景中,按照某个关键字对两份数据进行连接是非常常见的.如果两份数据 都比较小,那么可以 ...
- Hadoop版本变迁
内容来自<Hadoop技术内幕:深入解析YARN架构设计与实现原理>第2章:http://book.51cto.com/art/201312/422022.htm Hadoop版本变迁 当 ...
- Hadoop 概述
Hadoop 是 Apache 基金会下的一个开源分布式计算平台,以 HDFS 分布式文件系统 和 MapReduce 分布式计算框架为核心,为用户提供底层细节透明的分布式基础设施.目前,Hadoop ...
- hadoop基础教程免费分享
提起Hadoop相信大家还是很陌生的,但大数据呢?大数据可是红遍每一个角落,大数据的到来为我们社会带来三方面变革:思维变革.商业变革.管理变革,各行业将大数据纳入企业日常配置已成必然之势.阿里巴巴创办 ...
- Hadoop的版本演变
Hadoop版本演变 Apache Hadoop的四大分支构成了三个系列的Hadoop版本: 0.20.X系列 主要有两个特征:Append与Security 0.21.0/0.22.X系列 整个Ha ...
- PowerJob 的故事开始:“玩够了,才有精力写开源啊!”
本文适合有 Java 基础知识的人群 作者:HelloGitHub-Salieri HelloGitHub 推出的<讲解开源项目>系列.经过几番的努力和沟通,终于邀请到分布式任务调度与计算 ...
- ApacheCN 大数据译文集(二) 20211206 更新
Hadoop3 大数据分析 零.前言 一.Hadoop 简介 二.大数据分析概述 三.MapReduce 大数据处理 四.基于 Python 和 Hadoop 的科学计算和大数据分析 五.基于 R 和 ...
- Hadoop阅读笔记(四)——一幅图看透MapReduce机制
时至今日,已然看到第十章,似乎越是焦躁什么时候能翻完这本圣经的时候也让自己变得更加浮躁,想想后面还有一半的行程没走,我觉得这样“有口无心”的学习方式是不奏效的,或者是收效甚微的.如果有幸能有大牛路过, ...
随机推荐
- 3、Python函数详解(0601)
回顾: re search,findall,finditer.sub,subn function () 调用函数 def func_name(arg1,....) 生成函数对象 func_s ...
- CSS sprites
CSS Sprites在国内很多人叫css精灵,是一种网页图片应用处理方式. 优点: 它允许你将一个页面涉及到的所有零星图片都包含到一张大图中去,这样一来,当访问该页面时,载入的图片就不会像以前那样一 ...
- [从零开始搭网站三]CentOS配置JDK
点击下面连接查看从零开始搭网站全系列 从零开始搭网站 上一章我介绍了,如何不用每次都输密码连接服务器.那么这一章终于要开始服务器的开发环境配置了. 1:先输入以下代码来检验有没有已经安装的CDK: r ...
- CentOS6.5下搭建SVN服务器
1.检查是否已安装 rpm -qa | grep subversion 如果要卸载旧版本: yum remove subversion 2.安装 yum install subversion PS:y ...
- Django2.2安装
Django2.2安装 https://media.djangoproject.com/releases/2.2/Django-2.2.tar.gz 解压 tar -zvxf Django-2.2.t ...
- x1c 2018 静音调教
折腾快1周,在去intel官网手动下载最新显卡驱动,手动卸载老驱动,断网,重启,手动安装之后(还要再禁用点和散热相关的设备).终于不卡了.开始工作,但又遇到一个问题:太TM吵了! 经过调教,基本保障看 ...
- pointer-events
在做移动端的页面时,经常会遇到点击(touch)一个弹出的层,在上面触发点击(touch)事件,当弹出层关闭之后点击(touch)事件会穿透到下面的层,这时候如果下一层的某个元素也绑定了点击(touc ...
- Learning by doing——百日“扇贝打卡” 历程&展望
Java结课了.如果说这学期学习这门课后最明显的成果,那就是写了那么多的博客吧.而如果说本学期最有里程碑的事,那就是背了100多天单词,其中还获得了徽章! 这次想说说从中学以来一直喜欢的一门课--英语 ...
- 使用validateXxx()方法进行输入校验 --Struts2框架
1.本例是在使用validate()方法进行输入校验 --Struts2框架的基础上接着做的,上一篇使用validate()方法进行输入校验时会对当前Action中的所有方法有效,由于Struts2框 ...
- LeetCode--012--整数转罗马数字(java)
罗马数字包含以下七种字符: I, V, X, L,C,D 和 M. 字符 数值 I 1 V 5 X 10 L 50 C 100 D 500 M 1000 例如, 罗马数字 2 写做 II ,即为两个并 ...