scrapy框架post请求发送,五大核心组件,日志等级,请求传参
一、post请求发送
- 问题:爬虫文件的代码中,我们从来没有手动的对start_urls列表中存储的起始url进行过请求的发送,但是起始url的确是进行了请求的发送,那这是如何实现的呢?
- 解答:其实是因为爬虫文件中的爬虫类继承到了Spider父类中的start_requests(self)这个方法,该方法就可以对start_urls列表中的url发起请求:
def start_requests(self):
for u in self.start_urls:
yield scrapy.Request(url=u,callback=self.parse)
【注意】该方法默认的实现,是对起始的url发起get请求,如果想发起post请求,则需要子类重写该方法。
-方法: 重写start_requests方法,让其发起post请求:
def start_requests(self):
#请求的url
post_url = 'http://fanyi.baidu.com/sug'
# post请求参数
formdata = {
'kw': 'wolf',
}
# 发送post请求
yield scrapy.FormRequest(url=post_url, formdata=formdata, callback=self.parse)
在scrapy框架中默认情况下cookie会被自动处理,无需手动!
二.五大核心组件工作流程
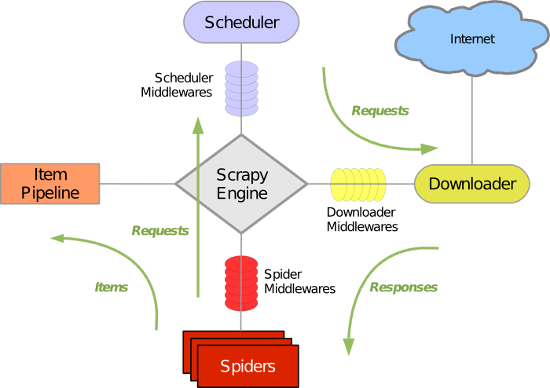
- 引擎(Scrapy)
用来处理整个系统的数据流处理, 触发事务(框架核心) - 调度器(Scheduler)
用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址 - 下载器(Downloader)
用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的) - 爬虫(Spiders)
爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面 - 项目管道(Pipeline)
负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。
三、scrapy日志等级
在使用scrapy crawl spiderFileName运行程序时,在终端里打印输出的就是scrapy的日志信息。
- 日志信息的种类:
ERROR : 一般错误
WARNING : 警告
INFO : 一般的信息
DEBUG : 调试信息
- 设置日志信息指定输出:
在settings.py配置文件中,加入
LOG_LEVEL = ‘指定日志信息种类’ 即可。
LOG_LEVEL = 'ERROR' 只打印错误日志。
LOG_FILE = 'log.txt' 则表示将日志信息写入到指定文件中进行存储。
四、请求传参
在某些情况下,我们爬取的数据不在同一个页面中,例如,我们爬取一个电影网站,电影的名称,评分在一级页面,而要爬取的其他电影详情在其二级子页面中。这时我们就需要用到请求传参。
- 案例:爬取boos直聘上的招聘信息,将一级页面中的工作名称,薪资,公司, 二级页面中的工作详情进行爬取。
爬虫文件:
import scrapy
from ..items import BoosproItem # 当我们请求的数据不在同一页面中,那么必须使用请求传参
class BoosSpider(scrapy.Spider):
name = 'boos'
# allowed_domains = ['www.xxx.com']
start_urls = ['https://www.zhipin.com/c101010100/?query=python%E7%88%AC%E8%99%AB&page=1'] # 通用的url模板
url = 'https://www.zhipin.com/c101010100/?query=python%E7%88%AC%E8%99%AB&page={}'
pageNum = 1 def parse(self, response):
li_list = response.xpath('//div[@class="job-list"]/ul/li')
for li in li_list:
item = BoosproItem() job_name = li.xpath('.//div[@class="job-title"]/text()').extract_first()
salary = li.xpath('.//div[@class="info-primary"]/h3/a/span/text()').extract_first()
company = li.xpath('.//div[@class="company-text"]/h3/a/text()').extract_first()
# url拼接
detail_url = 'https://www.zhipin.com' + li.xpath('.//div[@class="info-primary"]/h3/a/@href').extract_first() # 将解析到的数据存储到item类型的对象中
item['job_name'] = job_name
item['salary'] = salary
item['company'] = company # 对详情页的url进行手动请求的发送 , callback请求成功后的回调函数,
# 请求传参,将meta所对应的值传递给回调函数
yield scrapy.Request(url=detail_url, callback=self.parsrDetail, meta={'item': item}) # 对其他的页码进行手动请求
if self.pageNum <= 3:
self.pageNum += 1
newUrl = self.url.format(self.pageNum)
yield scrapy.Request(url=newUrl, callback=self.parse) # 用来解析详情页的相关的数据
def parsrDetail(self,response):
# 接收meta
item = response.meta['item']
job_desc = response.xpath('//*[@id="main"]/div[3]/div/div[2]/div[2]/div[1]/div//text()').extract()
job_desc = ''.join(job_desc)
# 将job_desc封装到item中
item['job_desc'] = job_desc # 提交item 到管道
yield item
items文件:
import scrapy class BoosproItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
job_name = scrapy.Field()
salary = scrapy.Field()
company = scrapy.Field()
job_desc = scrapy.Field()
管道文件:
class BoosproPipeline(object):
# 该方法只会被执行一次,
def open_spider(self, spider):
self.fp = open('./boos.txt', 'w', encoding='utf-8')
# 用于处理item的方法,爬虫文件每次提交一次item方法就会被调用一次
def process_item(self, item, spider):
# 取出item中的值
job_name = item["job_name"].strip()
salary = item["salary"].strip()
company = item["company"].strip()
job_desc = item["job_desc"].strip()
self.fp.write(job_name + ":" + salary + "\n" + company + "\n" + job_desc + '\n\n')
return item # 返回给了下一个即将被执行的管道类
# 关闭文件夹
def close_spider(self, spider):
self.fp.close()
注意settings中的配置:
开启管道,
robotstxt改为False,
UA伪装,
日志指定输出, LOG_LEVEL = 'ERROR'
scrapy框架post请求发送,五大核心组件,日志等级,请求传参的更多相关文章
- EasyUI queryParams属性 在请求远程数据同时给action方法传参
http://www.cnblogs.com/iack/p/3530500.html?utm_source=tuicool EasyUI queryParams属性 在请求远程数据同时给action方 ...
- 11-scrapy(递归解析,post请求,日志等级,请求传参)
一.递归解析: 需求:将投诉_阳光热线问政平台中的投诉标题和状态网友以及时间爬取下来永久储存在数据库中 url:http://wz.sun0769.com/index.php/question/que ...
- Vue框架(四)——路由跳转、路由传参、cookies、axios、跨域问题、element-ui模块
路由跳转 三种方式: $router.push / $router.go / router-link to this.$router.push('/course'); this.$router.pus ...
- 8.MVC框架开发(URL路由配置和URL路由传参空值处理)
1.ASP.NET和MVC的路由请求处理 1)ASP.NET的处理 请求---------响应请求(HttpModule)--------处理请求(HttpHandler)--------把请求的资源 ...
- Scrapy框架的使用 -- 自动跳转链接并请求
# -*- coding: utf-8 -*- import scrapy from movie.items import MovieItem class MoviespiderSpider(scra ...
- Vue 踩坑日志 - 有关路由传参的坑
1.有关路由传参 vue中当通过params传过去的参数刷新页面以后会消失,所以可以用query传参.但此时又会出现另一个坑,刷新后数据仍在.但这是针对单个的某个变量的. 如果传入一个对象的话,刷新页 ...
- scrapy框架的日志等级和请求传参, 优化效率
目录 scrapy框架的日志等级和请求传参, 优化效率 Scrapy的日志等级 请求传参 如何提高scripy的爬取效率 scrapy框架的日志等级和请求传参, 优化效率 Scrapy的日志等级 在使 ...
- 13.scrapy框架的日志等级和请求传参
今日概要 日志等级 请求传参 如何提高scrapy的爬取效率 今日详情 一.Scrapy的日志等级 - 在使用scrapy crawl spiderFileName运行程序时,在终端里打印输出的就是s ...
- scrapy框架的日志等级和请求传参
日志等级 请求传参 如何提高scrapy的爬取效率 一.Scrapy的日志等级 - 在使用scrapy crawl spiderFileName运行程序时,在终端里打印输出的就是scrapy的日志信息 ...
- 爬虫开发10.scrapy框架之日志等级和请求传参
今日概要 日志等级 请求传参 今日详情 一.Scrapy的日志等级 - 在使用scrapy crawl spiderFileName运行程序时,在终端里打印输出的就是scrapy的日志信息. - 日志 ...
随机推荐
- DBArtist之Oracle入门第1步: 如何安装Oracle 11g
操作系统: Windows 7 数据库 : Oracle 11gR2 第一步: 下载Oracle安装包 Oracle官网: https://www.oracle.com/index.html ...
- swift新建类和子类方法的重写与重载
1.首先什么是重写与重载? 一.重写(override) override是重写(覆盖)了一个方法,以实现不同的功能.一般是用于子类在继承父类时,重写(重新实现)父类中的方法. 重写(覆盖)的规则: ...
- 572. Subtree of Another Tree 大树里包括小树
[抄题]: Given two non-empty binary trees s and t, check whether tree t has exactly the same structure ...
- 637. Average of Levels in Binary Tree 二叉树的层次遍历再求均值
[抄题]: Given a non-empty binary tree, return the average value of the nodes on each level in the form ...
- .NET 使用HttpWebRequest 伪造Request.UrlReferrer
在网上找了许久关于伪造UrlReferrer地址资料,也许是搜索的关键词不对吧,还是内容涉及到了什么敏感的东西,愣是没找到,换成自定义UrlReferrer也找不到.经过仔细研究,原来在.NET中要自 ...
- 3d点云与cad模型
https://stackoverflow.com/questions/19000096/match-3d-point-cloud-to-cad-model
- JS和DOM的关系
DOM对象 DOM实际上是以面向对象方式描述的文档模型.DOM定义了表示和修改文档所需的对象.这些对象的行为和属性以及这些对象之间的关系. 根据W3C DOM规范,DOM是HTML与XML的应用编程接 ...
- Django学习笔记:为Model添加Action
|- Django版本:1.8 |- Python版本:3.4 models.py 1 class Story(models.Model): #编辑Story状态 STATUS_CHOICES = ( ...
- Hadoop中的控制脚本
1.提出问题 在上篇博文中,提到了为什么要配置ssh免密码登录,说是Hadoop控制脚本依赖SSH来执行针对整个集群的操作,那么Hadoop中控制脚本都是什么东西呢?具体是如何通过SSH来针对整个集群 ...
- [Selenium With C#基础教程] Lesson-05 文本框
作者:Surpassme 来源:http://www.jianshu.com/p/7dca7d0d1ea3 声明:本文为原创文章,如需转载请在文章页面明显位置给出原文链接,谢谢. 文本框在Web页面中 ...