hadoop 3.1.1 安装
以下是本次搭建说使用的服务器
| IP | 节点名称 | 说明 |
| 192.168.172.130 | master | 主服务器 |
| 192.168.172.131 | slave1 | 从服务器1 |
| 192.168.172.132 | slave2 | 从服务器2 |
1、分别 在三台服务器上新增用户、组
groupadd hadoop
useradd -d /home/hadoop -g hadoop -s /bin/bash -m hadoop
visudo
#在文中root行下添加hadoop行
root ALL=(ALL:ALL) ALL
hadoop ALL=(ALL) ALL
2、分别 在三台服务器上执行如下操作
vi /etc/hosts
#追加如下内容
192.168.172.130 master
192.168.172.131 slave1
192.168.172.132 slave2
3、分别 在三台服务器上执行如下操作
vi /etc/hostname
#master服务器将内容修改为如下内容
hadoop_master.localdomain #slave1服务器将内容修改为如下内容
hadoop_slave1.localdomain #slave2服务器将内容修改为如下内容
hadoop_slave2.localdomain
4、分别 在三台服务器上执行如下操作
#重启服务器
reboot
5、设置SSH免密码远程登录,环境设置:修改sshd的配置文件
vim /etc/ssh/sshd_config
#找到以下内容,并去掉注释符“#” RSAAuthentication yes
PubkeyAuthentication yes
AuthorizedKeysFile .ssh/authorized_keys
重启sshd服务
/sbin/service sshd restart
本机生成公钥和私钥
本机切换成需要免密码登陆的账户,然后运行以下命令:
ssh-keygen -t rsa
运行后默认会在该账号的home目录下生成~/.ssh/id_rsa: 私钥和~/.ssh/id_rsa.pub:公钥两个文件。
将公钥导入本机认证文件
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
将公钥导入到目标(将远程登录到的服务器)服务器的特定账号(将以该账号登录远程服务器)的认证文件
scp ~/.ssh/id_rsa.pub xxx@目标主机ip或主机名:/home/xxx/id_rsa.pub
然后以相应账号登录到远程服务器,再运行以下命令导入公钥到认证文件
cat ~/id_rsa.pub >> ~/.ssh/authorized_keys //将所有服务器的id_rsa.pub相互导入服务器
修改远程服务器相应账号下的.ssh文件夹和authorized_keys文件的权限
chmod 700 ~/.ssh
chmod 710 ~/.ssh/authorized_keys
测试是否配置成功
在 master 服务器使用如下命令,第一次会提示输入一次公钥密码,以后再次登录不再提示则表示成功
ssh slave1
ssh slave2
在 slave1 服务器使用如下命令,第一次会提示输入一次公钥密码,以后再次登录不再提示则表示成功
ssh master
ssh slave2
在 slave2 服务器使用如下命令,第一次会提示输入一次公钥密码,以后再次登录不再提示则表示成功
ssh master
ssh slave1
若上面操作始终提示需要输入密码,尝试修改hadoop用户组再重复上面操作
usermod -G root hadoop
6、配置java环境(以下操作都在master上操作)
mkdir -p /usr/local/java
下载jdk1.8版本,并将其解压到/usr/local/java目录下
tar -zxf jdk-8u65-linux-x64.tar.gz -C /usr/local/java/
配置环境变量
vi /etc/profile #在配置文件的最后添加如下配置 #JAVA
JAVA_HOME=/usr/local/java/jdk1.8.0_65 #自己解压后的jdk目录名称
JRE_JOME=/usr/local/java/jdk1.8.0_65/jre
CLASS_PATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib
PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
export JAVA_HOME JRE_JOME CLASS_PATH PATH
保存退出后,执行以下命令刷新环境变量
source /etc/profile
进行测试是否成功
java -version
7、安装hadoop3.1.1(以下操作都在master上操作)
cd /usr/local/
sudo wget https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/core/hadoop-3.1.1/hadoop-3.1.1.tar.gz
#解压配置环境变量
tar -zxf hadoop-3.1.1.tar.gz -C /usr/local/hadoop/
配置hadoop环境变量
vi /etc/profile
#在配置文件最后一行添加如下配置 #HADOOP
export HADOOP_HOME=/usr/local/hadoop/hadoop-3.1.1
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
运行如下命令刷新环境变量
source /etc/profile
进行测试是否成功
hadoop version
配置Hadoop3.1.1
#在/usr/local/hadoop目录下创建目录
cd /usr/local/hadoop/
mkdir tmp
mkdir var
mkdir dfs
mkdir dfs/name
mkdir dfs/data
进入hadoop的配置文件目录下,修改配置文件
cd /usr/local/hadoop/hadoop-3.1.1/etc/hadoop
vi workers
#删除localhost,添加从节点主机名,例如我这里是:
slave1
slave2
a、修改 hadoop-env.sh 文件
vi hadoop-env.sh
在# JAVA_HOME=/usr/java/testing hdfs dfs -ls一行下面添加如下代码
export JAVA_HOME=/usr/local/java/jdk1.8.0_65
export HADOOP_HOME=/usr/local/hadoop/hadoop-3.1.1
export HDFS_NAMENODE_USER=hadoop
export HDFS_DATANODE_USER=hadoop
export HDFS_SECONDARYNAMENODE_USER=hadoop
export YARN_RESOURCEMANAGER_USER=hadoop
export YARN_NODEMANAGER_USER=hadoop
b、修改 core-site.xml 文件
vim /usr/local/hadoop/hadoop-3.1.1/etc/hadoop/core-site.xml
内容如下:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.172.130:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
</property>
</configuration>
c、修改 hdfs-site.xml 文件
vim /usr/local/hadoop/hadoop-3.1.1/etc/hadoop/hdfs-site.xml
内容如下:
<configuration>
<property>
<name>dfs.name.dir</name>
<value>/usr/local/hadoop/dfs/name</value>
<description>
Path on the local filesystem where theNameNode stores the namespace and transactions logs persistently.
</description>
</property>
<property>
<name>dfs.data.dir</name>
<value>/usr/local/hadoop/dfs/data</value>
<description>
Comma separated list of paths on the localfilesystem of a DataNode where it should store itsblocks.
</description>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>192.168.172.130:50070</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>192.168.172.130:50090</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
<description>need not permissions</description>
</property>
</configuration>
d、修改 yarn-site.xml 文件
在命令行下输入如下命令,并将返回的地址复制,在配置下面的yarn-site.xml时会用到。
hadoop classpath
将上面命令获取的到结果复制一下,下面会用到
vim /usr/local/hadoop/hadoop-3.1.1/etc/hadoop/yarn-site.xml
内容如下:
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.application.classpath</name>
<value>输入刚才返回的Hadoop classpath路径</value>
</property>
</configuration>
8、同步(以下操作都在master上操作)
以下命令一条一条执行
scp -r /usr/local/java slave1:/usr/local/java
scp -r /usr/local/hadoop slave1:/usr/local/hadoop
scp -r /etc/profile slave1:/etc/ scp -r /usr/local/java slave2:/usr/local/java
scp -r /usr/local/hadoop slave2:/usr/local/hadoop
scp -r /etc/profile slave2:/etc/
上面的所有命令都执行完之后,分别在slave1、slave2刷新环境变量
source /etc/profile
9、格式化节点(以下操作都在master上操作)
hdfs namenode -format
10、启动hadoop集群的服务 (以下操作都在master上操作)
start-all.sh
启动完之后在master、slave1、slave2上执行如下命令,查看启动情况
jps
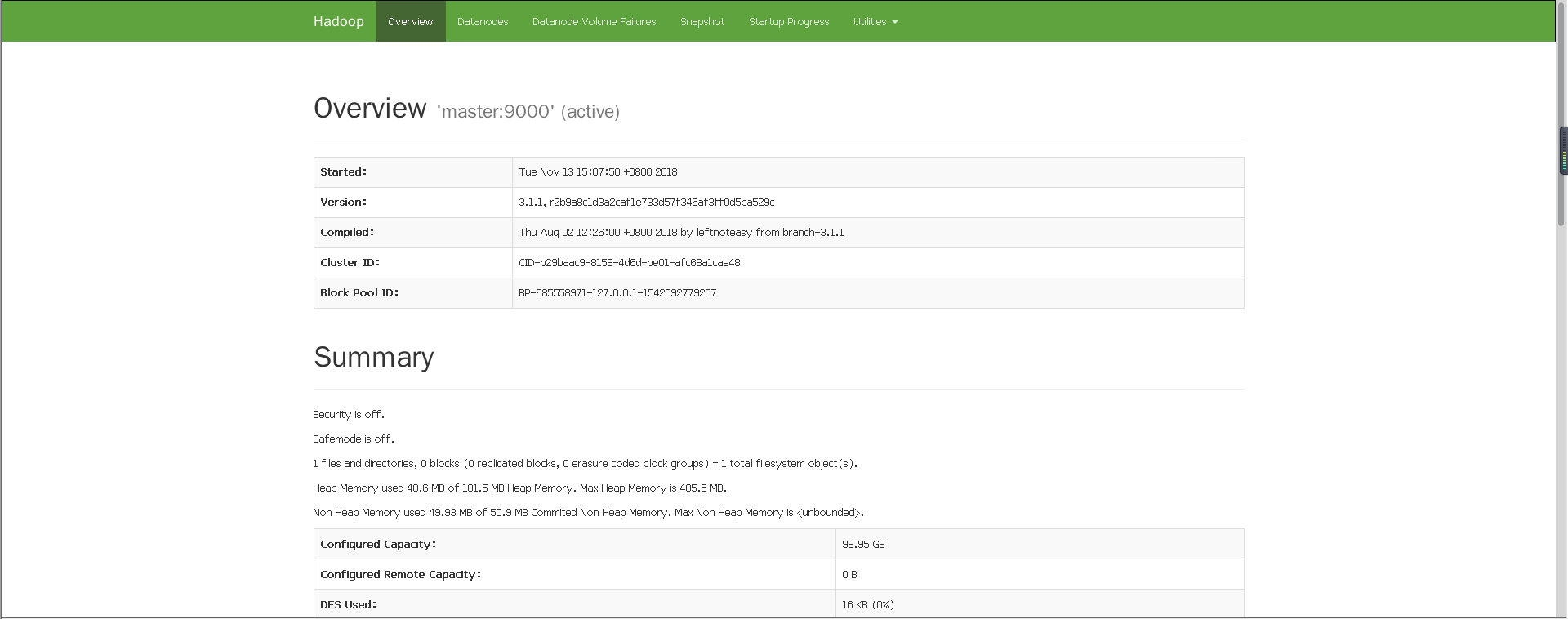
在浏览器查看启动情况:http://192.168.172.130:8088/cluster
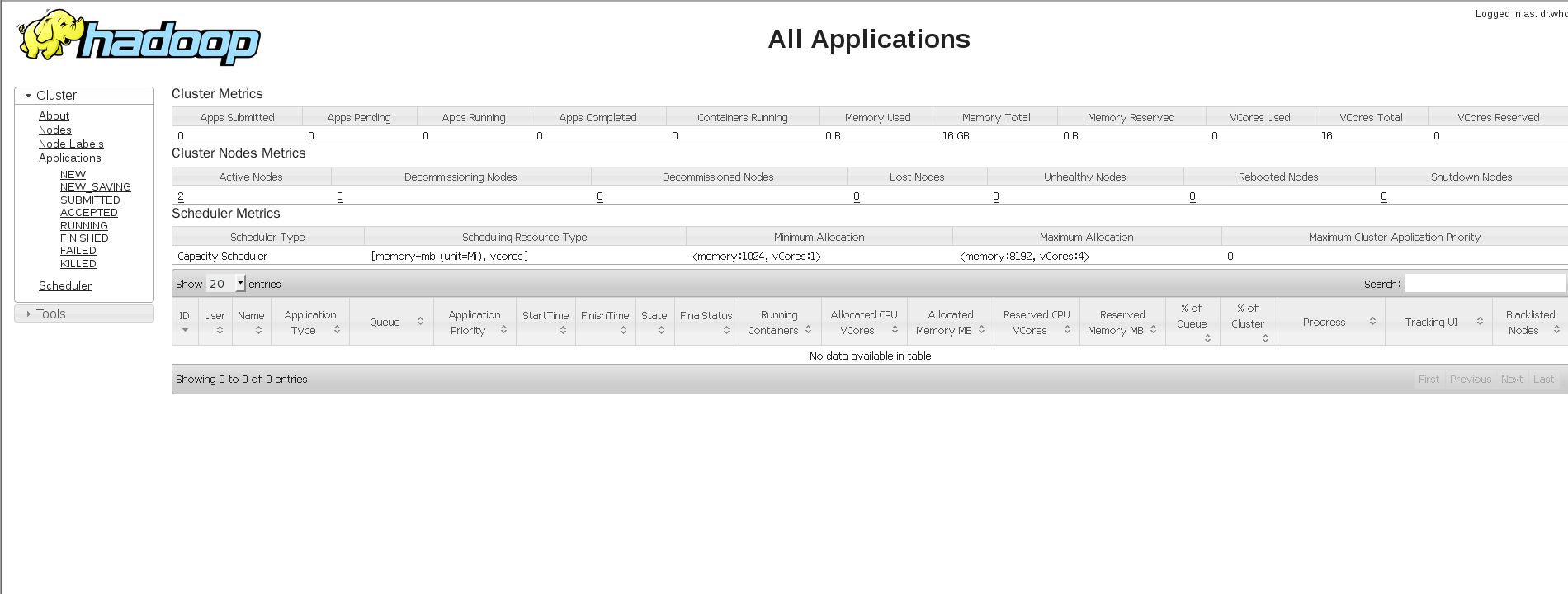
或者 http://192.168.172.130:50070/dfshealth.html#tab-overview
hadoop 3.1.1 安装的更多相关文章
- Hadoop集群搭建安装过程(三)(图文详解---尽情点击!!!)
Hadoop集群搭建安装过程(三)(图文详解---尽情点击!!!) 一.JDK的安装 安装位置都在同一位置(/usr/tools/jdk1.8.0_73) jdk的安装在克隆三台机器的时候可以提前安装 ...
- Hadoop集群搭建安装过程(二)(图文详解---尽情点击!!!)
Hadoop集群搭建安装过程(二)(配置SSH免密登录)(图文详解---尽情点击!!!) 一.配置ssh无密码访问 ®生成公钥密钥对 1.在每个节点上分别执行: ssh-keygen -t rsa(一 ...
- Ganglia监控Hadoop集群的安装部署[转]
Ganglia监控Hadoop集群的安装部署 一. 安装环境 Ubuntu server 12.04 安装gmetad的机器:192.168.52.105 安装gmond的机 器:192.168.52 ...
- 【原】Hadoop伪分布模式的安装
Hadoop伪分布模式的安装 [环境参数] (1)Host OS:Win7 64bit (2)IDE:Eclipse Version: Luna Service Release 2 (4.4.2) ( ...
- hadoop的集群安装
hadoop的集群安装 1.安装JDK,解压jar,配置环境变量 1.1.解压jar tar -zxvf jdk-7u79-linux-x64.tar.gz -C /opt/install //将jd ...
- Hadoop 发行版本 Hortonworks 安装详解(一) 准备工作
一.前言 目前Hadoop发行版非常多,所有这些发行版均是基于Apache Hadoop衍生出来的,之所以有这么多的版本,完全是由Apache Hadoop的开源协议决定的:任何人可以对其进行修改,并 ...
- Hadoop 发行版本 Hortonworks 安装详解(二) 安装Ambari
一.通过yum安装ambari-server 由于上一步我们搭建了本地源,实际上yum是通过本地源安装的ambari-server,虽然也可以直接通过官方源在线安装,不过体积巨大比较费时. 这里我选择 ...
- Hadoop生态圈-使用FreeIPA安装Kerberos和LDAP
Hadoop生态圈-使用FreeIPA安装Kerberos和LDAP 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 有些大数据平台只是简单地通过防火墙来解决他们的网络安全问题.十分 ...
- 基于zookeeper的高可用Hadoop HA集群安装
(1)hadoop2.7.1源码编译 http://aperise.iteye.com/blog/2246856 (2)hadoop2.7.1安装准备 http://aperise.iteye.com ...
- Hadoop分布式HA的安装部署
Hadoop分布式HA的安装部署 前言 单机版的Hadoop环境只有一个namenode,一般namenode出现问题,整个系统也就无法使用,所以高可用主要指的是namenode的高可用,即存在两个n ...
随机推荐
- 基于ZooKeeper的服务注册中心
本文介绍基于ZooKeeper的Dubbo服务注册中心的原理. 1.ZooKeeper中的节点 ZooKeeper是一个树形结构的目录服务,支持变更推送,因此非常适合作为Dubbo服务的注册中心. 注 ...
- 【转】Keepalived无法绑定VIP故障排查经历
一 故障描述 我在台湾合作方给定的两台虚拟机上部署HAProxy+Keepalived负载均衡高可用方案.在配置完Keepalived后,重新启动Keepalived,Keepalived没有绑定VI ...
- Windows 下配置 php_imagick 扩展
1.首先按装 imageimagick 可以去 http://imagemagick.org/script/binary-releases.php#windows 这里下载,看好自己的系统环境和选择好 ...
- 【opencv】cv::Mat转std::vector<cv::Point2d> (注意两容器中数据类型的一致性)
获取cv::Mat大小: mymat.size() 获取cv::Mat指定位置的值:需指定数据类型,且注意数据类型应与存入时的数据类型一致,否则会导致不抛出异常的数据错误 mymat.at<,i ...
- Linux下桥接模式详解一
注册博客园已经好长时间,一直以来也没有在上面写过文章,都是随意的记录在了未知笔记上,今天开始本着分享和学习的精神想把之前总结的笔记逐步分享到博客园,和大家一起学习,一起进步吧! 2016-09-20 ...
- BroadcastReceiver 翻译
1. 动态注册与退出 If registering a receiver in your Activity.onResume() implementation, you should unregist ...
- 前端 javascript 数据类型 数字
1.数字(Number) JavaScript中不区分整数值和浮点数值,JavaScript中所有数字均用浮点数值表示. 转换: parseInt(..) 将某值转换成数字,不成功则NaN pa ...
- CheckStyle——检查编码格式等是否符合规范
CheckStyle 一.checkstyle简介 checkstyle是idea中的一个插件,可以很方便的帮我们检查java代码中的格式错误,它能够自动化代码规范检查过程,从而使得开发人员从这项重要 ...
- Jmeter(四)测试webservice脚本
1.有些非标准的wsdl文件导入到loadrunner时候会报错,这时候我们就能利用jmeter进行性能测试2.在soapui中新建已经soap项目,File---->new soapUI Pr ...
- Shiro起步
1.测试环境 IntelliJ Idea 2.pom配置 <?xml version="1.0" encoding="UTF-8"?> <p ...