02_zookeeper集群安装
zookeeper集群安装
(1) 下载zookeeper安装包,并上传到要组成zookeeper集群的多个机器上
我放置的目录:/usr/local/src/zookeeper-3.4.5.tar.gz, 使用3个节点构成zookeeper集群
(2) 将各个节点上的压缩包进行解压, 得到zookeeper目录
# tar –xzvf zookeeper-3.4..tart.gz
(3) 修改zookeeper目录的owener为当前用户及群组
# chown –R root:root zookeeper-3.4.
(4) 选任意一台机器,进入zookeeper配置目录,将zoo_sample.cfg复制并重命名为zoo.cfg
# cd /usr/local/src/zookeeper-3.4./conf
# cp zoo_sample.cfg zoo.cfg
(5) 修改zoo.cfg配置文件
# vim zoo.cfg
修改dataDir路径,同时增加3行集群节点描述,每行对应1个即将作为zookeeper集群节点的机器
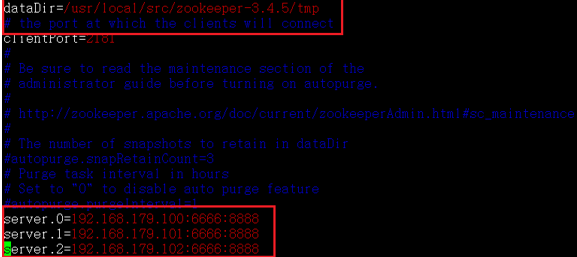
配置文件中的相关参数说明:
tickTime: 毫秒单位,zookeeper时间单位,也是zkserver-client间发送心跳的间隔时间
initLimit: zk集群中follower角色的机器和leader角色的机器,初始连接时能够容忍的最大 无心跳时间(多少个tick)
syncLimit: zk集群中follower角色的机器和leader角色的机器,同步阶段能够容忍的最大无 心跳时间(多少个tick)
dataDir: zk保存数据的本地目录
clientPort: zk公布给外接的,用于client端连接zk集群的端口号(TCP长连接)
server.0=ip:通信端口:选举端口
0,1,2 是zk服务器的内部编号
通信端口,zk集群中的follower和leader间的通信端口
选举端口,zk集群中进行选举时使用的通信端口
(6) 在各个主机上都创建zookeeper的数据目录
# mkdir /usr/local/src/zookeeper-3.4./tmp
(7) 将zoo.cfg文件分发到各个机器
# scp –rp zoo.cfg root@slave1:/usr/local/src/zookeeper-3.4./conf
# scp –rp zoo.cfg root@slave2:/usr/local/src/zookeeper-3.4./conf
(8) 所有节点都进入到conf中设置的zk的数据目录,并创建新myid文件
节点1
# cd /usr/local/src/zookeeper-3.4./tmp
# touch myid
# vim myid
写入0
节点2
# cd /usr/local/src/zookeeper-3.4./tmp
# touch myid
# vim myid
写入1
节点3
# cd /usr/local/src/zookeeper-3.4./tmp
# touch myid
# vim myid
写入2
0,1,2和zoo.cfg中的server.0, server.1, server.2保持一致
(9) 在所有节点上都启动bin目录下的zkServer.sh
# cd /usr/local/src/zookeeper-3.4./bin
# ./zkServer.sh start
所有节点的终端上都出现如下提示,则表示zk启动成功

(10) 查看各个节点的zk状态
# cd /usr/local/src/zookeeper-3.4./bin
# ./zkServer.sh status
节点1

节点2

节点3:

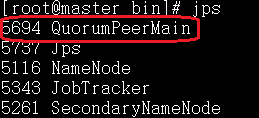
(11) 查看各个节点上的zookeeper进程
Zookeeper以java进程的方式运行,通过JPS可以确定正常运行,安装结束
02_zookeeper集群安装的更多相关文章
- 【Oracle 集群】Oracle 11G RAC教程之集群安装(七)
Oracle 11G RAC集群安装(七) 概述:写下本文档的初衷和动力,来源于上篇的<oracle基本操作手册>.oracle基本操作手册是作者研一假期对oracle基础知识学习的汇总. ...
- kafka集群安装部署
kafka集群安装 使用的版本 系统:centos6.5 centos6.7 jdk:1.7.0_79 zookeeper:3.4.9 kafka:2.10-0.10.1.0 一.环境准备[只列,不具 ...
- CentOS下Hadoop-2.2.0集群安装配置
对于一个刚开始学习Spark的人来说,当然首先需要把环境搭建好,再跑几个例子,目前比较流行的部署是Spark On Yarn,作为新手,我觉得有必要走一遍Hadoop的集群安装配置,而不仅仅停留在本地 ...
- Hadoop多节点集群安装配置
目录: 1.集群部署介绍 1.1 Hadoop简介 1.2 环境说明 1.3 环境配置 1.4 所需软件 2.SSH无密码验证配置 2.1 SSH基本原理和用法 2.2 配置Master无密码登录所有 ...
- codis集群安装
在网上找了很多codis的集群安装方法,看起来都是大同小异,本人结合了大多种方法完成了一套自己使用的codis的集群安装,可以供大家学习使用,如果有什么问题或者不懂的地方欢迎指正 1.集群规划: 三台 ...
- [bigdata] spark集群安装及测试
在spark安装之前,应该已经安装了hadoop原生版或者cdh,因为spark基本要基于hdfs来进行计算. 1. 下载 spark: http://mirrors.cnnic.cn/apache ...
- (原) 1.2 Zookeeper伪集群安装
本文为原创文章,转载请注明出处,谢谢 Zookeeper伪集群安装 zookeeper单机安装配置可以查看 1.1 zookeeper单机安装 1.复制三份zookeeper,分别为zookeeper ...
- 一步步教你Hadoop多节点集群安装配置
1.集群部署介绍 1.1 Hadoop简介 Hadoop是Apache软件基金会旗下的一个开源分布式计算平台.以Hadoop分布式文件系统HDFS(Hadoop Distributed Filesys ...
- kafka 集群安装与安装测试
一.集群安装 1. Kafka下载:wget https://archive.apache.org/dist/kafka/0.8.1/kafka_2.9.2-0.8.1.tgz 解压 tar zxvf ...
随机推荐
- Google发布机器学习术语表 (包括简体中文)
Google 工程教育团队已经发布了多语种的 Google 机器学习术语表,该术语表中列出了一般的机器学习术语和 TensorFlow 专用术语的定义.语言版本包括西班牙语,法语,韩语和简体中文. 查 ...
- 搭建wordpress
https://www.themepark.com.cn/xcjxgwordpressdzdyglyd.html
- shell awk实战
一.文本处理 1.按行提取关键字频次(如取第5列) awk 'BEGIN{FS="|"} {a[$5]+=1;} END {for(i in a) print i ":& ...
- 系列:每日一linux命令(转)
原文:http://www.cnblogs.com/peida/archive/2012/12/05/2803591.html 一. 文件目录操作命令: 1.每天一个linux命令(1):ls命令 2 ...
- (0.2.3)Mysql安装——二进制安装
Linux平台下二进制方式安装卸载mysql 本章节:二进制安装mysql 目录: 1.基于Linux平台的Mysql项目场景介绍 2.mysql数据库运行环境准备-最优配置 3.如何下载mysql数 ...
- 怎么解决tomcat占用8080端口问题图文教程
怎么解决tomcat占用8080端口问题 相信很多朋友都遇到过这样的问题吧,tomcat死机了,重启eclipse之后,发现 Several ports (8080, 8009) required ...
- Spring框架第一篇之Spring的第一个程序
一.下载Spring的jar包 通过http://repo.spring.io/release/org/springframework/spring/地址下载最新的Spring的zip包,当然,如果你 ...
- append和extend区别
append append方法用于在列表末尾添加新的对象 它是把添加的对象当成一个整体追加到末尾 a=[1,23,436] b=[] b.append(a) print(b)""& ...
- 腾讯 微信春招nlp实习生一面二面(猝)
一面: 1.算法题: 1 28数组中出现次数超过一半的数字 2 手写快排:八大排序算法总结(2) 2.项目介绍: 大多都是项目中涉及到的技术. TFIDF 的原理 word2vec的原理 3.算法原理 ...
- python的socket网络编程(二)
(注:本文部分内容摘自互联网,由于作者水平有限,不足之处,还望留言指正.) 国庆八天假,已过去3天了,加上明天又是中秋,还是决定在今晚把之前想写的东西写完.国庆节在宁波老家,吃好喝好睡好,就是没有好好 ...