Selenium运用-漫画批量下载
今天我们要爬去的网站是http://comic.sfacg.com/。漫画网站一般都是通过JavaScript和AJAX来动态加载漫画的,这也就意味着想通过原来爬取静态网站的方式去下载漫画是不可能的,这次我们就来用Selenium&PhantomJS来下载漫画。
分析:我们通过Selenium模拟打开漫画网站,找到每一章每一页漫画图片地址,按章节目录分类,下载图片。
下面我们随便打开一个漫画如下
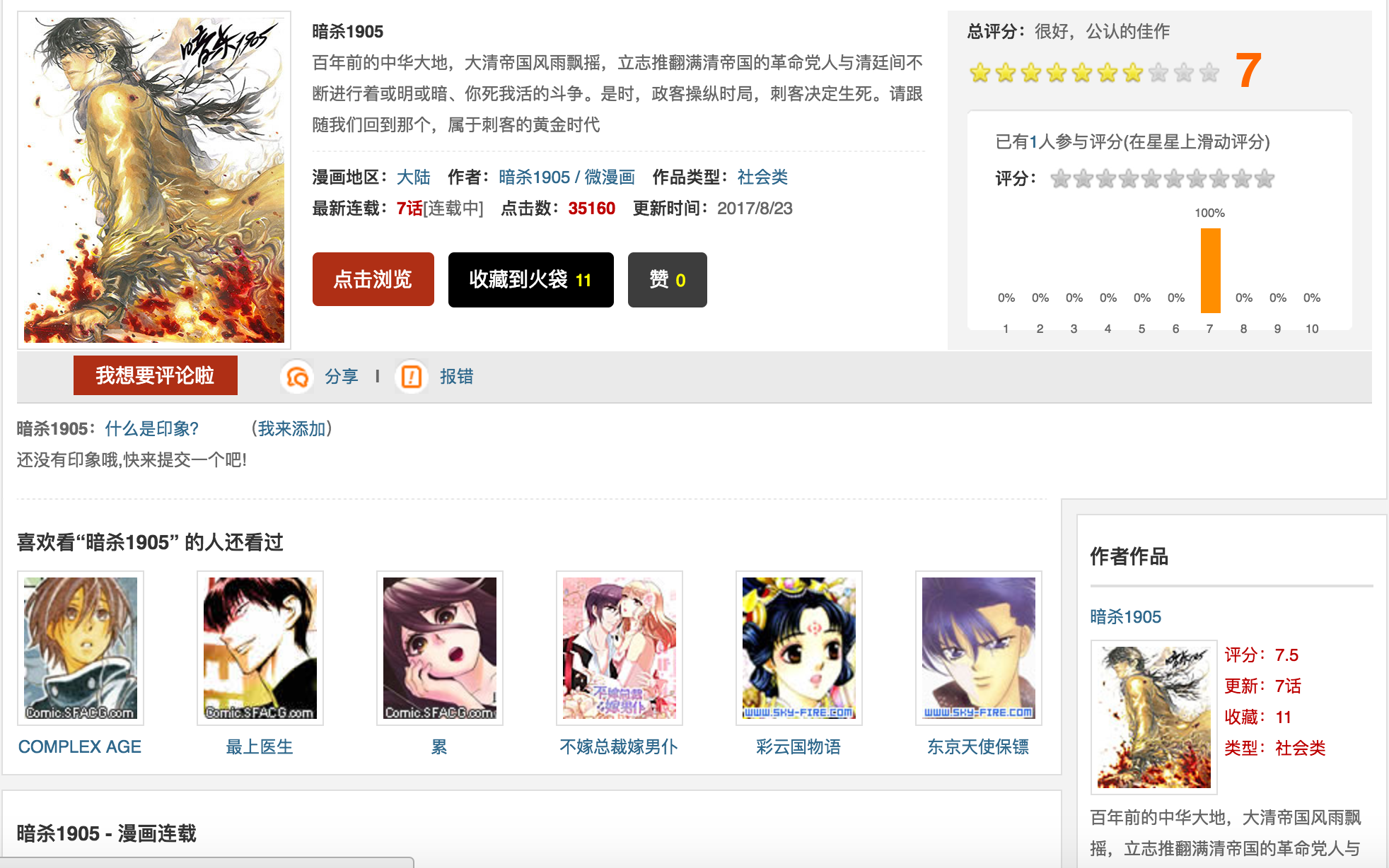
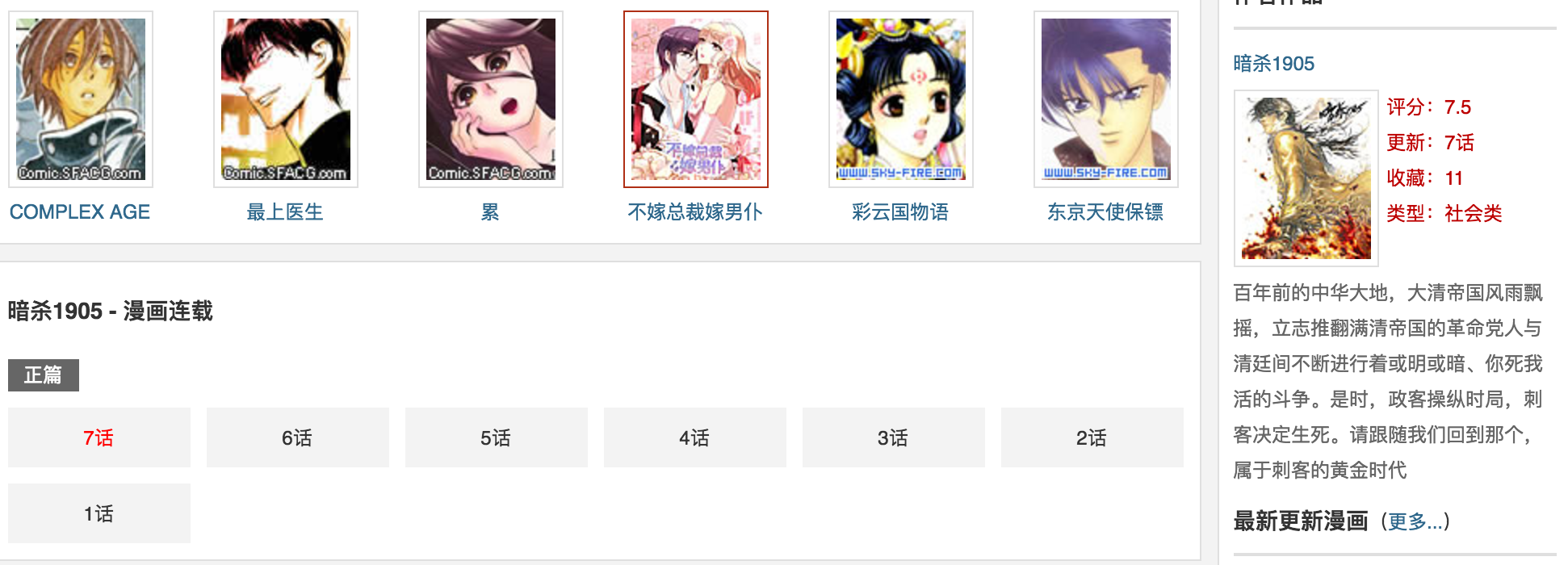
使用谷歌浏览器检查一下发现每一个章节都在下面标签里,这样我们很容易获取到每一章节地址了。
<div class="serialise_list Blue_link2">
下面进入代码编写过程:
首先创建目录和图片保存
def mkdir(path):
'''
防止目录存在
:param path:
:return:
'''
if not os.path.exists(path):
os.mkdir(path) def SavePic(filename,url):
'''
图片的保存
:param filename:
:param url:
:return:
'''
content = requests.get(url).content
with open(filename,'wb') as f:
f.write(content)
获取每一章节的链接保存到字典里
def get_TOF(index_url):
url_list = []
browser = webdriver.PhantomJS()
browser.get(index_url)
browser.implicitly_wait(3) title = browser.title.split(',')[0]#获取漫画标题
mkdir(title)#创建目录 comics_lists = browser.find_elements_by_class_name('comic_Serial_list')#找到漫画章节
for part in comics_lists:#找到每一章节所在的标签信息
links = part.find_elements_by_tag_name('a')
for link in links:
url_list.append(link.get_attribute('href'))#获取每个单独章节链接
browser.quit()
Comics = {'name':title,'urls':url_list}
return Comics
下面是代码的核心部分,通过selenium打开漫画找到漫画的地址,下载漫画图片,找到漫画中下一页按钮,点击并获取下一页图片,循环这个过程。当循环到最后一页到时候,仍然有下一页到按钮,因此需要计算一下漫画有多少页。
def get_pic(Comics):
comic_list = Comics['urls']
basedir = Comics['name'] browser = webdriver.PhantomJS()
for url in comic_list:
browser.get(url)
browser.implicitly_wait(3)
dirname = basedir+'/'+browser.title.split('-')[1]
mkdir(dirname)
#找到漫画一共有多少页
pageNum = len(browser.find_elements_by_tag_name('option'))
#找到下一页按钮
nextpage = browser.find_element_by_xpath('//*[@id="AD_j1"]/div/a[4]')
for i in range(pageNum):
pic_url = browser.find_element_by_id('curPic').get_attribute('src')
filename = dirname+'/'+str(i)+'.png'
SavePic(filename,pic_url)
nextpage.click()
print('当前章节\t{} 下载完毕'.format(browser.title))
browser.quit()
print('所有章节下载完毕!')
下面是主函数到编写
if __name__ == '__main__':
url = str(input('请输入漫画首页地址:\n'))
Comics = get_TOF(url)
#print(Comics)
get_pic(Comics)
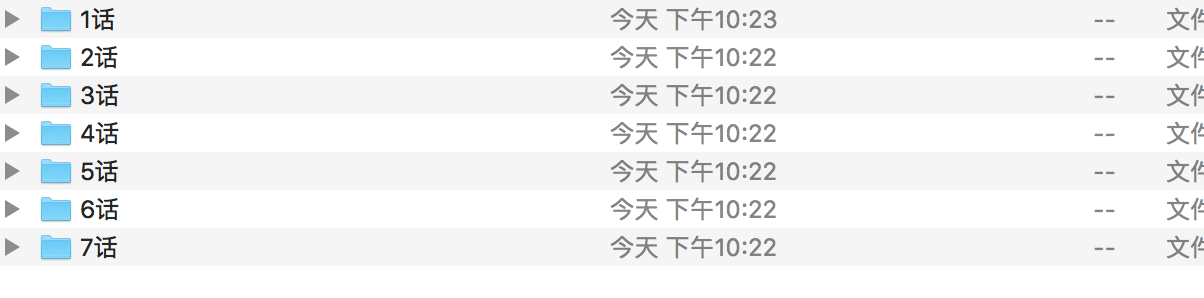
结果展示:
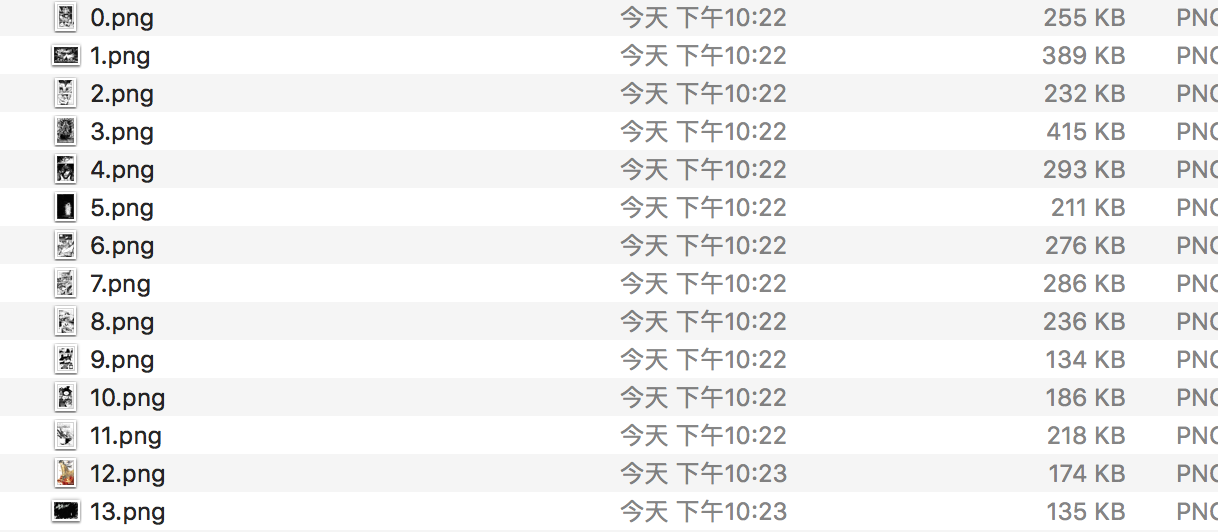
下面是1话里面到图片
 Selenium爬虫虽然能模拟浏览器加载JS动态页面,但是其速度就十分堪忧了和Scrapy库、requests更完全不能比了。
Selenium爬虫虽然能模拟浏览器加载JS动态页面,但是其速度就十分堪忧了和Scrapy库、requests更完全不能比了。
Selenium运用-漫画批量下载的更多相关文章
- 【pyhon】怨灵侍全本漫画批量下载爬虫1.00
代码: # 怨灵侍全本漫画批量下载爬虫1.00 # 拜CARTOON.fydupiwu.com整理有序所赐,寻找图片只要观察出规律即可,不用费劲下一页的找了 import time import ur ...
- Java实现批量下载《神秘的程序员》漫画
上周看了西乔的博客“西乔的九卦”.<神秘的程序员们>系列漫画感觉很喜欢,很搞笑.这些漫画经常出现在CSDN“程序员”杂志末页的,以前也看过一些. 后来就想下载下来,但是一张一张的点击右键“ ...
- Python + Selenium +Chrome 批量下载网页代码修改【新手必学】
Python + Selenium +Chrome 批量下载网页代码修改主要修改以下代码可以调用 本地的 user-agent.txt 和 cookie.txt来达到在登陆状态下 批量打开并下载网页, ...
- python图片爬虫 - 批量下载unsplash图片
前言 unslpash绝对是找图的绝佳场所, 但是进网站等待图片加载真的令人捉急, 仿佛是一场拼RP的战争 然后就开始思考用爬虫帮我批量下载, 等下载完再挑选, 操作了一下不算很麻烦, 顺便也给大家提 ...
- 用python批量下载图片
一 写爬虫注意事项 网络上有不少有用的资源, 如果需要合理的用爬虫去爬取资源是合法的,但是注意不要越界,前一阶段有个公司因为一个程序员写了个爬虫,导致公司200多个人被抓,所以先进入正题之前了解下什么 ...
- KRPano资源分析工具使用说明(KRPano XML/JS解密 切片图批量下载 球面图还原 加密混淆JS还原美化)
软件交流群:571171251(软件免费版本在群内提供) krpano技术交流群:551278936(软件免费版本在群内提供) 最新博客地址:blog.turenlong.com 限时下载地址:htt ...
- 批量下载小说网站上的小说(python爬虫)
随便说点什么 因为在学python,所有自然而然的就掉进了爬虫这个坑里,好吧,主要是因为我觉得爬虫比较酷,才入坑的. 想想看,你可以批量自动的采集互联网上海量的资料数据,是多么令人激动啊! 所以我就被 ...
- 利用SkyDrive Pro 迅速批量下载SharePoint Server 上已上传的文件
在上一篇<SharePoint Server 2013 让上传文件更精彩>,我们一起了解了如何快速的方便的上传批量文件到SharePoint Server 2013 ,而在这一篇日志中您将 ...
- 批量下载网站图片的Python实用小工具
定位 本文适合于熟悉Python编程且对互联网高清图片饶有兴趣的筒鞋.读完本文后,将学会如何使用Python库批量并发地抓取网页和下载图片资源.只要懂得如何安装Python库以及运行Python程序, ...
随机推荐
- windows python文件拷贝到linux上执行问题-换行符问题/r/n
之前在Windows下写好了一个Python脚本,运行没问题,今天在Linux下,脚本开头的注释行已经指明了解释器的路径,也用chmod给了执行权限,但就是不能直接运行脚本. 1 问题1: 报错:: ...
- 【BZOJ】3524 [POI2014] Couriers(主席树)
题目 传送门:QWQ 传送到洛谷QWQ 分析 把求区间第k大的改一改就ok了. 代码 #include <bits/stdc++.h> using namespace std; ; ], ...
- CC1,IceBreak,Hello world ,hello toastmaster
this is my first speech:icebreak in toastmaster,it is precious memory for me,this is first time that ...
- python学习笔记(十一):网络编程
一.python操作网络,也就是打开一个网站,或者请求一个http接口,使用urllib模块. urllib模块是一个标准模块,直接import urllib即可,在python3里面只有urllib ...
- OD 实验(十六) - 从对话框入手对程序的逆向
对话框: 对话框从类型上分为两类:modal 对话框和 modeless 对话框,就是模态对话框和非模态对话框,也有叫成模式和非模式 模态对话框不允许用户在不同窗口间进行切换,非模态对话框允许用户在不 ...
- HTTP与TCP/IP的区别
TPC/IP协议是传输层协议,主要解决数据如何在网络中传输,而HTTP是应用层协议,主要解决如何包装数据.关于TCP/IP和HTTP协议的关系,网络有一段比较容易理解的介绍:“我们在传输数据时,可以只 ...
- Error: listen EACCES 0.0.0.0:8080 错误解决记录
live-server -- 热加载利器 实现本地服务器,可及时刷新. 1.通过npm install -g live-server进行安装 2.npm init 初始化项目3.在所需要的文件夹内运行 ...
- 【Oracle】Oracle数据库DATABASE LINK 的命名
当前数据库的GLOBAL_NAMES参数设置为 TRUE,使用DATABASE LINK 时,DATABASE LINK的名称必须与被连接库的 GLOBAL_NAME一致. 而要建多个 DBLINK到 ...
- ffmpeg源码分析四:transcode_step函数 (转4)
原帖地址:http://blog.csdn.net/austinblog/article/details/25099979 该函数的主要功能是一步完整的转换工作,下面看看源代码: static int ...
- UNITY 带spriterender的对象导出为prefab时主贴图丢失的BUG
从场景导出带有sprite的对象为prefab时贴图丢失的BUG.解决方案:对场景中每个sprite重新赋一下贴图,然后导出就好了,原因不明. 补充:这个有时候是因为贴图类型不是 2D AND UI ...