java实战之解析xml
在java中解析xml有现成的包提供方法,常用的有四类:Dom,JDom,Sax以及Dom4j。其中前者是java中自带的,后三者需要大家从开源诸如sourceforge这样的网站下载jar包,然后在eclipse中“build path”加载外来的jar文件就行。各自的入门demo可以观看官网文档,听说文档有点晦涩难懂,可以多多google之,园子里有的是资源。接下来主要讲的是如何使用Dom4j解析xml文档。
1、什么是xml
首先从维基百科里盗图一张,解释xml的主要结构——『节点(node):节点名称和节点值。』,『属性(attribute):属性名称和属性值。』。

上图中第一行解释了该xml文件的版本信息,这在写入xml文件的时候需要注明,有时候还需要注明文件的编码方式例如“utf-8”。在每一个xml文件中都有一个根节点,所有节点数据都是包含在根节点中,例如本xml文档中的根节点名称为quiz。quiz根节点下有一个名称为qanda子节点,这样类似的子节点是可重复的,当然在本xml文件中根节点下只有一个直系子节点qanda,qanda节点中有一个名称为seq的属性,其属性值为“1”,在qanda中有两个子节点,第一个子节点为question,该子节点的节点值为Who was the forty-second....一堆文字,符号标签</question>标志着该节点值的结束。以此类推第二个子节点answer的节点值(节点内容)为William....,后面<!--....>里面的内容是注释,类似html文件中的注释信息。
对xml语言有更多兴趣的可去w2school网站文档学习。
2、开始实战
2.1 准备材料
以下是我的xml文档示例,目的是了解xml文档的结构(完整文档见“下载我吧~”):
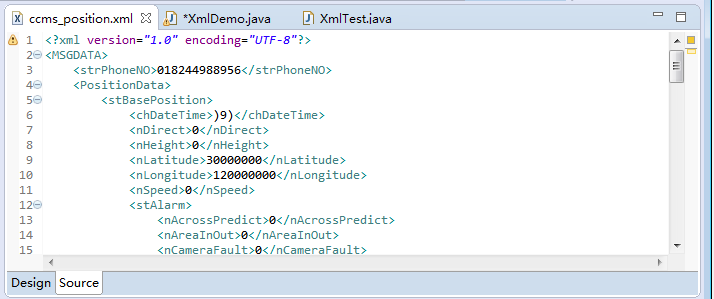
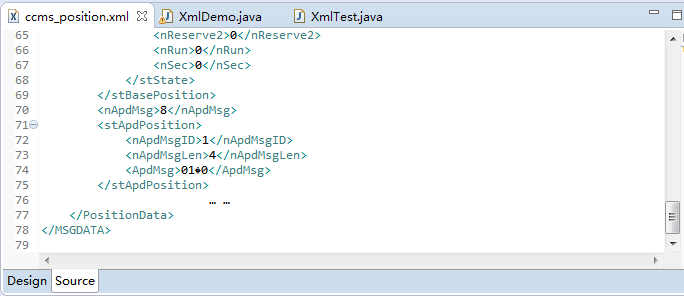
上面的截图中,第一个文件ccms_position.xml文件就是传说中的标记语言,常用语web service中数据的传输,在eclipse中xml文件有两种展示方式(以上展示的是Source源文件模式),它为了让程序员方便的解析和编写xml文件特意设计的Design模式真的很人性化(自行在eclipse中打开xml文件就可以切换Design模式)。
2.2 测试结果分析
上面的XmlDemo和XmlTest分别是demo和测试文件,所有代码如下:
package com.xml; import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
import java.util.Iterator; import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.io.SAXReader; /**
* @author 吴荧
*
* 解析XML文档
*/ public class XmlDemo{ public void parseXml(String inputName, String outputName) { File inputXml = new File(inputName);
SAXReader saxReader = new SAXReader(); try {
//新建输出文件
FileWriter writer = new FileWriter(outputName);
//读取XML文件,获取document对象
Document document = saxReader.read(inputXml);
//获取根节点msgData元素对象
Element msgData = document.getRootElement(); //获取根节点下的子节点strPhoneNO以及该节点名称的内容并写入文件
Element strPhoneNO = msgData.element("strPhoneNO");
String strPhoneNO_text = strPhoneNO.getTextTrim();
writer.write(strPhoneNO_text + ","); //获取根节点下的子节点PositionData
Element PositionData = msgData.element("PositionData");
String PositionData_text = PositionData.getTextTrim();
writer.write(PositionData_text + ","); //在PositionData中迭代第一层子节点
for (Iterator i = PositionData.elementIterator(); i.hasNext();){ Element node1 = (Element) i.next();
//将第一层子节点中的文字写入文本
writer.write(node1.getTextTrim());
if (i.hasNext()){
writer.write(",");
} //第一层子节点中再次遍历第二层子节点
for (Iterator j = node1.elementIterator(); j.hasNext();){ Element node2 = (Element) j.next();
//将第二层子节点中的文字写入文本
writer.write(node2.getTextTrim());
if (j.hasNext()){
writer.write(",");
} //第二层子节点中再次遍历第三层子节点
for (Iterator k = node2.elementIterator(); k.hasNext();){ Element node3 = (Element) k.next();
//将第三层子节点中的文字写入文本
writer.write(node3.getTextTrim());
if (k.hasNext()){
writer.write(",");
}
}
}
} writer.close();
} catch (DocumentException e) {
System.out.println(e.getMessage());
} catch (IOException e) {
e.printStackTrace();
}
}
}
View XmlDemo.java
package com.xml; /*
* 测试代码
*/ public class XmlTest { public static void main(String [] args) {
String inputName = "src/com/xml/ccms_position.xml";
String outputName = "src/com/xml/ccms_out.txt"; XmlDemo demo4 = new XmlDemo();
demo4.parseXml(inputName, outputName);
}
}
View XmlTest.java
上面的代码注释已经是非常详细了,其中的语法主要参考的是这篇博文,但是写入的结果并不如人意,如下图所示:
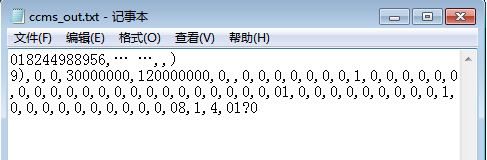
写入文件的目的:希望解析xml文档中的所有数据,并将数据按不同字段用逗号分割符分开存入文本。
目前代码存在的问题:
2.2.1 每遍历一个层结束以后,使用i.hasNext()方法判断是都还有下一个节点的时候被写入一个逗号,但是遇到下一个节点中是子节点而没有节点内容的时候不应该写入数据,否则就会出现第二行输出的两个逗号之间没有数据;
2.2.2 看样本中nSec节点中的内容0与nApdMsg节点中的内容8没有使用逗号分隔符分隔,考虑到也是使用i.hasNext方法的问题,应该考虑该节点的母节点遍历结束以后都要使用逗号分隔。
2.3 调试代码
更改逗号写入条件:当前同一层节点的内容用逗号分隔;当该层循环结束,若下层节点中无文本内容只有子节点的时候不写入逗号,仅当节点有文本内容的时候才将内容写入文本并使用逗号分隔。
在每一层循环中写入以下判断条件再写入:
if (!nodei.getTextTrim().equals("")){
writer.write(nodei.getTextTrim());
if (i.hasNext()){
writer.write(",");
}
}
解决了了2.2.1的问题,但是2.2.2的问题仍然没有解决,只能手动在第一层写入数据之前加入逗号,感觉代码好low啊。
2.4 优化代码
2.4.1 代码中存在大量的重复块,可以将重复块写入方法调用
public Element condition(FileWriter writer, Iterator m) throws IOException {
Element node = (Element) m.next();
//将第一层子节点中的文字写入文本
String text = node.getTextTrim();
if (!text.equals("")){
writer.write(node.getTextTrim());
if (m.hasNext()){
writer.write(",");
}
}
return node;
}
2.5 看看其他的算法
2.5.1 Dom
2.5.2 Sax
2.5.3 JDom
挖个坑,先把jar包的资源扔出来~
java实战之解析xml的更多相关文章
- Java用SAX解析XML
要解析的XML文件:myClass.xml <?xml version="1.0" encoding="utf-8"?> <class> ...
- JAVA使用SAX解析XML文件
在我的另一篇文章(http://www.cnblogs.com/anivia/p/5849712.html)中,通过一个例子介绍了使用DOM来解析XML文件,那么本篇文章通过相同的XML文件介绍如何使 ...
- java使用sax解析xml
目的:解析xml文件,并存入mysql,并且要解析的字段能一一对应.这里解析的是微博的文件,想要利用里面的article和person_id字段. 思路: 为了能得到person_id和article ...
- Java 创建过滤器 解析xml文件
今天写了一个过滤器demo,现在是解析actions.xml文件,得到action中的业务规则:不需要导入任何jar包 ActionFilter过滤器类: package accp.com.xh.ut ...
- 【java】:解析xml
==========================================xml文件<?xml version="1.0" encoding="GB231 ...
- JAVA通过XPath解析XML性能比较(原创)
(转载请标明原文地址) 最近在做一个小项目,使用到XML文件解析技术,通过对该技术的了解和使用,总结了以下内容. 1 XML文件解析的4种方法 通常解析XML文件有四种经典的方法.基本的解析方式有两种 ...
- java使用dom4j解析xml文件
关于xml的知识,及作用什么的就不说了,直接解释如何使用dom4j解析.假如有如下xml: dom4j解析xml其实很简单,只要你有点java基础,知道xml文件.结合下面的xml文件和java代码, ...
- 【收藏用】--切勿转载JAVA 使用Dom4j 解析XML
原帖地址 : http://blog.csdn.NET/yyywyr/article/details/38359049 解析XML的方式有很多,本文介绍使用dom4j解析xml. 1.环境准备 (1) ...
- Java是如何解析xml文件的(DOM)
Java解析xml文件 在Java程序中读取xml文件的过程也称为"解析xml文件": 解析的目的: 获取 节点名和节点值 获取 属性名.属性值. 四中解析方式: DOM SAX ...
随机推荐
- input的file 控件及美化
在一些网站进行上传时,当单击了“浏览”按钮之后会弹出[选择文件]的对话框.想要实现这一功能,用input的file控件来实现就好啦~ <!doctype html> <html la ...
- C# Async Await 注意事项
Avoid Using Async Void --- 避免使用async void async void 只能用于事件处理函数.并且保证永远不在用户代码中调用这些事件处理函数. async void ...
- 用MsmqBinding投送message出现的一个灵异事件 【第二篇】
一直都在用Msmqbinding,也一直忽视了message里面的内容格式是什么样的,这也是微软给我们高层封装带给我们的开发效率,但同时一旦中间出了什么问题, 就不知道从何查起了.有个需求是这样的,服 ...
- mysql 5.5多实例部署【图解】
mysql5.5数据库多实例部署,我们可以分以下几个步骤来完成. 1. mysql多实例的原理 2. mysql多实例的特点 3. mysql多实例应用场景 4. mysql5.5多实例部署方法 一. ...
- mysql datetime查询异常
mysql datetime查询异常 异常:Value '0000-00-00 00:00:00' can not be represented as java.sql.Timestamp (2011 ...
- SQL Server 2008 R2——ROW_NUMBER() 去掉不同行中相同列的重复内容
==================================声明================================== 本文原创,转载在正文中显要的注明作者和出处,并保证文章的完 ...
- tomcat黑/白名单设置
vim $tomcat_home/conf/server.xml(可以单个IP或者多个ip,多个ip用|分隔,支持正则) <Context path=" reloadable=&quo ...
- my_atoi()
void my_atoi(const char* s){ int i=0,res=0; if(*s<='9' && *s>='0'){ //如果输入的一个字符是数字 for ...
- Linux 文件常见类型
- Linux下Redis开机自启(Centos)
废话少说,直接来步骤: 1.设置redis.conf中daemonize为yes,确保守护进程开启. 2.编写开机自启动脚本 vi /etc/init.d/redis 脚本内容如下: # chkcon ...