传统Item-Based协同过滤推荐算法改进
前言
今天要读的论文为一篇于2009年10月15日发表在《计算机研究与发展》的一篇会议论文,论文针对只根据相似性无法找到准确可靠的最近邻这个问题,提出了结合项目近部等级与相似性求取最近邻的新方法;此外针对系统中新加入的项目,因为其上评分信息的匾乏,求得的最近邻往往是不准确的,为此,提出了聚合最近邻和”集体评分”两种改进方法。
摘要
传统Item-Based协同过滤算法根据项目之间的相似性来选取最近邻居。然而,现存的几种相似性度量方法都存在相应的弊端,因此只根据相似性无法找到准确可靠的最近邻。根据对两项目共同评分的用户个数,建立项目近邻等级,提出了结合项目近部等级与相似性求取最近邻的新方法。另外,对于系统中新加入的项目,因为其上评分信息的匾乏,求得的最近邻往往是不准确的。为此,提出了聚合最近邻和”集体评分”两种改进方法。在MovieLens数据集上的实验结果表明,将上述改进应用于传统Item-Based协同过滤推荐算法,推荐质量有明显提升。
传统的item-based协同过滤推荐算法
推荐系统中,数据的核心是一个用户一项目评分矩阵A(m,n),它包含m个用户的集合U={u1, u2, ..., um},和n个项目的集合I={i1, i2, ..., in},元素Rui表示用户u对项目i的评分,若用户u未对项目i评分,则Rui=0.
项目的相似度度量方法
首先我们定义:
- 对于任意的i∈I,定义项目一评分矩阵A(m,n)中对应于i的列为项目i的评分向量,记为Ui。
- 对于任意的u∈U,定义项目一评分矩阵A(m,n)中对应于u的 行为用户u 的评分向量,记为Iu。
余弦相似度
标准的余弦相似度:

修正的余弦相似度
不同用户存在不同评分尺度的偏见,下面将采取减去对应项目上所有用户的平均评分的方法,来刻画用户对某一项目的评分与“公众意见”的偏差。

相关相似性
根据pearson提出的相关系数来度量项目之间的相似性,定义对项目i和j都有评分的用户集合为Uij。
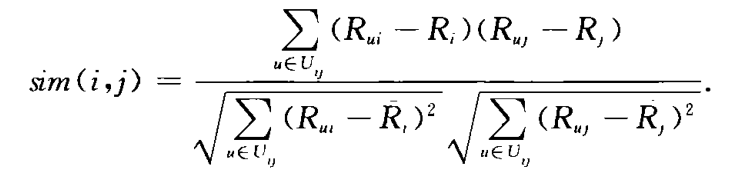
选择合适的相似性度量方法,求出项目集I中任意两项目之间的相似性,存入项目相似性矩阵Sim中,显然,Sim是对称矩阵。
最近邻的选取
中心最近邻
中心最近邻,是当前最常用也是最成功的最近邻选取方法。对于任意的i∈I,根据相似性矩阵Sim中其他项目与i的相似性,按从大到小顺序排列,将相应的项目编号存入最近邻矩阵TkNN的相应行中,构成项目i的最近邻集合;即第一最近邻与i的相似性最高,第二最近邻次之,依此类推。
聚合最近邻
聚合最近邻,对于某些新加人的项目,其评分向量与其他项目的评分向量的交集很小,不利于准确地计算相似性。比如说,已知当前项目i的第一最近邻为j,项目k和i被1个用户共同评分,项目t和i没有被共同评过分。这样,在i的最近邻列表中,k排在t前。但此时,若t是j的第一最近邻,那么t
也很有可能是i的最近邻。聚合最近邻的思想就是基于上述考虑。
算法改进
求取最近邻过程的改进—结合使用项目相似性与项目近邻等级
求取最近邻是整个协同过滤算法最关键的一步。最近邻越准确,其推荐结果就越可靠。因为最近邻根据项目相似性矩阵Sim来选取。
产生推荐过程的改进—集体评分
对于新加入的项目,集体评分是一个解决难以找到新加入项目最近邻的好方法。
结尾
好了,今天的论文就先读到这儿了,明天再见喽。
传统Item-Based协同过滤推荐算法改进的更多相关文章
- SimRank协同过滤推荐算法
在协同过滤推荐算法总结中,我们讲到了用图模型做协同过滤的方法,包括SimRank系列算法和马尔科夫链系列算法.现在我们就对SimRank算法在推荐系统的应用做一个总结. 1. SimRank推荐算法的 ...
- SparkMLlib—协同过滤推荐算法,电影推荐系统,物品喜好推荐
SparkMLlib-协同过滤推荐算法,电影推荐系统,物品喜好推荐 一.协同过滤 1.1 显示vs隐式反馈 1.2 实例介绍 1.2.1 数据说明 评分数据说明(ratings.data) 用户信息( ...
- 基于物品的协同过滤推荐算法——读“Item-Based Collaborative Filtering Recommendation Algorithms” .
ligh@local-host$ ssh-copy-id -i ~/.ssh/id_rsa.pub root@192.168.0.3 基于物品的协同过滤推荐算法--读"Item-Based ...
- 基于MapReduce的(用户、物品、内容)的协同过滤推荐算法
1.基于用户的协同过滤推荐算法 利用相似度矩阵*评分矩阵得到推荐列表 已经推荐过的置零 2.基于物品的协同过滤推荐算法 3.基于内容的推荐 算法思想:给用户推荐和他们之前喜欢的物品在内容上相似的物品 ...
- Spark ML协同过滤推荐算法
一.简介 协同过滤算法[Collaborative Filtering Recommendation]算法是最经典.最常用的推荐算法.该算法通过分析用户兴趣,在用户群中找到指定用户的相似用户,综合这些 ...
- 基于局部敏感哈希的协同过滤推荐算法之E^2LSH
需要代码联系作者,不做义务咨询. 一.算法实现 基于p-stable分布,并以‘哈希技术分类’中的分层法为使用方法,就产生了E2LSH算法. E2LSH中的哈希函数定义如下: 其中,v为d维原始数据, ...
- 推荐系统| ② 离线推荐&基于隐语义模型的协同过滤推荐
一.离线推荐服务 离线推荐服务是综合用户所有的历史数据,利用设定的离线统计算法和离线推荐算法周期性的进行结果统计与保存,计算的结果在一定时间周期内是固定不变的,变更的频率取决于算法调度的频率. 离线推 ...
- Mahout之(二)协同过滤推荐
协同过滤 —— Collaborative Filtering 协同过滤简单来说就是根据目标用户的行为特征,为他发现一个兴趣相投.拥有共同经验的群体,然后根据群体的喜好来为目标用户过滤可能感兴趣的内容 ...
- 协同过滤CF算法之入门
数据规整 首先将评分数据从 ratings.dat 中读出到一个 DataFrame 里: >>> import pandas as pd In [2]: import pandas ...
- Spark2.0 协同过滤推荐
ALS矩阵分解 http://blog.csdn.net/oucpowerman/article/details/49847979 http://www.open-open.com/lib/view/ ...
随机推荐
- 2024年1月Java项目开发指南18:自定义异常输出
一般情况下,报错信息一大堆,值得注意的只有三个地方: 哪个文件发生了错误 哪一行发生了错误 错误原因是什么 只要知道这三个东西就能快速的定位到错误发生的位置并且根据提示解决. 如果你也喜欢我的这种异常 ...
- Nginx+ModSecurity(WAF) 加强 Web 应用程序安全性
Nginx 和 ModSecurity 加强 Web 应用程序的安全性 在当今互联网时代,Web 应用程序的安全性变得尤为重要.为了保护应用程序和用户的数据免受恶意攻击和漏洞利用,使用合适的工具和技术 ...
- Mac系统Obsidian和Typora更换霞鹜文楷字体
在github上发现了一款非常好看的字体LXGW WenKai / 霞鹜文楷,这里记录下Mac电脑如何安装这个字体,以及我用到的笔记软件更换字体的过程. Mac安装字体 # 增加代理,不加代理下载速度 ...
- 【OpenCV】features2d_converters.cpp:2:10: fatal error: common.h: 没有那个文件或目录
Linux环境下使用opencv的dnn模块调用yolov4遇到的坑(纯CPU)一.问题描述Ubuntu安装opencv4.4,第一次编译完成安装成功,发现编译时少加了几个选项,于是重新编译,结果报如 ...
- [转]vue调试工具vue-devtools安装及使用(亲测有效,望采纳)
vue调试工具vue-devtools安装及使用(亲测有效,望采纳) 本文主要介绍 vue的调试工具 vue-devtools 的安装和使用 工欲善其事, 必先利其器, 快快一起来用vue-devto ...
- 如何使用vs将现有的项目或者文件夹(尤其是多层目录的)添加到项目中
在Visual Studio中将现有的项目或者文件夹(尤其是多层目录的)添加到项目解决方案中,步骤如下: 1.将现有项目或文件夹拷贝到指定目录下: 2.解决方案右上有个显示所有文件的按钮,如下图所示: ...
- 在Eclipse配置并编译worldwind java2.1.0源码,选中Src目录下gov.nasa.worldwindx.examples包下ApplicationTemplate.java类文件run时提示“javax.xml.parsers.DocumentBuilderFactory.setFeature(Ljava/lang/String;Z)V”异常的解决办法
问题现象: 在Eclipse配置并编译worldwind java2.1.0源码,选中Src目录下gov.nasa.worldwindx.examples包下ApplicationTemplate.j ...
- IM通讯协议专题学习(八):金蝶随手记团队的Protobuf应用实践(原理篇)
本文由金蝶随手记技术团队丁同舟分享. 1.引言 跟移动端IM中追求数据传输效率.网络流量消耗等需求一样,随手记客户端与服务端交互的过程中,对部分数据的传输大小和效率也有较高的要求,普通的数据格式如 J ...
- kubernetes系列(二) - kubectl的入门操作
目录 1. 安装 / 卸载 1 .1 前提条件 1.2 安装方式 1.3 卸载 2. 通过 minikube 学习 k8s 实操基础 2.1 创建集群 2.2 部署应用 2.3 探索当前应用[故障排除 ...
- TNN-linux编译测试记录
Github: https://github.com/Tencent/TNN docs: https://github.com/Tencent/TNN/blob/master/doc/cn/user/ ...