搞人工智能开源大语言模型GPT2、Llama的正确姿势

(如果想及时收到人工智能相关的知识更新,请点击关注!!)
序言:目前我们每一小节的内容都讲解得非常慢,因为这是人工智能研发中的最基础知识。如果我们不能扎实掌握这些知识,将很难理解后续更复杂且实用的概念。因此,我们甚至采用一个概念一节的方式来编排内容,区分得清清楚楚、明明白白,以便大家能够非常明确地了解各知识点之间的关联关系和界限。本节将讲述一种在人工智能领域中被视为“泰斗绝学”的方法,帮助我们高效地完成模型训练——这项绝学就是“迁移学习”。
迁移学习
正如我们在本章中已经看到的那样,使用卷积操作来提取特征是识别图像内容的一个强大工具。生成的特征图可以输入到神经网络的密集层中,与标签匹配,从而更准确地确定图像的内容。通过这种方法,结合一个简单、易于训练的神经网络和一些图像增强技术,我们构建了一个模型,在非常小的数据集上训练时,能够以80-90%的准确率区分马和人。
但是我们可以通过一种叫做迁移学习的方法进一步改进我们的模型。迁移学习的理念很简单:与其从零开始为我们的数据集学习一组滤波器,为什么不使用一个在更大数据集上学习到的滤波器集合呢?该数据集包含了比我们自己“从零开始构建”所能负担得起的更多特征。我们可以将这些滤波器放入我们的网络中,然后使用这些预学习的滤波器训练一个适合我们数据的模型。例如,我们的马或人数据集只有两个类别,而我们可以使用一个已经为一千个类别预训练过的现有模型,但到某个阶段我们不得不舍弃部分已有的网络结构,添加适合两分类的层来构建分类器。
图 3-14 展示了类似于我们这种分类任务的卷积神经网络架构。我们有一系列的卷积层,连接到一个密集层,进而连接到输出层。

图 3-14. 卷积神经网络架构
我们已经看到,使用这种架构,我们能够构建一个相当不错的分类器。但是,通过迁移学习,如果我们可以从另一个模型中提取预学习的层,冻结或锁定它们以使其不可训练,然后将它们置于我们的模型之上,就像图 3-15 所示,这会怎么样呢?
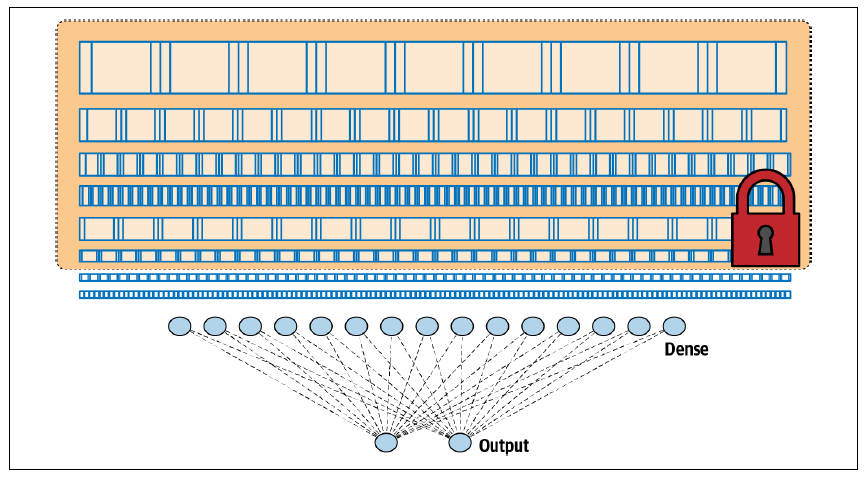
图 3-15. 通过迁移学习从另一个架构中获取层
当我们考虑到,一旦这些层被训练好,它们实际上只是一些数字,表示滤波器的值、权重和偏置,配合一个已知的架构(每层滤波器的数量、滤波器的大小等),那么重用它们的想法就非常直接了当了。
让我们看看代码中的实现。这方面有很多预训练的模型可以使用。我们将使用来自谷歌的流行模型Inception的第3版,它在一个名为ImageNet的数据库中用超过一百万张图片进行了训练。该模型有几十层,可以将图像分类为一千个类别。一个包含预训练权重的已保存模型也已经可以使用。要使用它,我们只需下载这些权重,创建一个Inception V3架构的实例,然后将这些权重加载到这个架构中,代码如下:
from tensorflow.keras.applications.inception_v3 import InceptionV3
weights_url = "https://storage.googleapis.com/mledudatasets/inception_v3_weights_tf_dim_ordering_tf_kernels_notop.h5"
weights_file = "inception_v3.h5"
urllib.request.urlretrieve(weights_url, weights_file)
pre_trained_model = InceptionV3(input_shape=(150, 150, 3),
include_top=False,
weights=None)
pre_trained_model.load_weights(weights_file)
现在我们有一个完整的预训练Inception模型。如果你想查看它的架构,可以用以下代码:
pre_trained_model.summary()
不过要小心,它很庞大!可以浏览一下,看看层和它们的名称。我喜欢用一个叫做mixed7的层,因为它的输出很小——7 × 7的图像——不过你可以随意尝试其他层。
接下来,我们将冻结整个网络,使其不再重新训练,然后设置一个变量指向mixed7的输出,作为我们要裁剪网络的位置。代码如下:
for layer in pre_trained_model.layers:
layer.trainable = False
last_layer = pre_trained_model.get_layer('mixed7')
print('last layer output shape: ', last_layer.output_shape)
last_output = last_layer.output
注意,我们打印了最后一层的输出形状,你会看到我们在这时得到了7 × 7的图像。这表示当图像被传递到mixed7时,滤波器输出的图像大小为7 × 7,所以很容易管理。同样,你不必选择这个特定层,可以尝试其他层。
现在让我们看看如何在这个输出下添加我们的密集层:
/将输出层展开为1维/
x = layers.Flatten()(last_output)
/添加一个带有1,024个隐藏单元和ReLU激活的全连接层/
x = layers.Dense(1024, activation='relu')(x)
/添加一个用于分类的最终sigmoid层/
x = layers.Dense(1, activation='sigmoid')(x)
就这么简单,我们将最后的输出展平,因为我们将把结果传递到密集层中。然后,我们添加一个包含1,024个神经元的密集层,和一个带有1个神经元的输出层。
现在我们可以简单地将模型定义为预训练模型的输入,接着是刚刚定义的x,然后以通常的方式编译它:
model = Model(pre_trained_model.input, x)
model.compile(optimizer=RMSprop(lr=0.0001),
loss='binary_crossentropy',
metrics=['acc'])
在这个架构上训练模型40个周期后,准确率达到99%+,验证准确率则达到96%+(见图3-16)。

图 3-16. 使用迁移学习训练马或人分类器
这里的结果比我们之前的模型要好得多,但你可以继续进行微调和改进。你还可以试试这个模型在更大数据集上的表现,比如Kaggle上著名的猫狗大战(Dogs vs. Cats)。这是一个非常多样化的数据集,包含了25,000张猫和狗的图片,很多图片中的主体都有一定遮挡——比如被人抱着的情况下。
使用之前的同样算法和模型设计,你可以在Colab上训练一个猫狗分类器,利用GPU每个周期大约3分钟。训练20个周期,大约需要1小时。
在测试一些非常复杂的图片时(如图3-17所示),这个分类器全都判断正确。我特意选择了一张长着像猫耳朵的狗的图片,还有一张背对着的狗的图片。另外两张猫的图片也都是非典型的。

图 3-17. 成功分类的非典型猫狗图片
右下角的那只猫,闭着眼睛、耳朵下垂、伸着舌头舔爪子,把它加载到模型中时,得到了图3-18中的结果。你可以看到,它给出了一个非常低的值(4.98 × 10⁻²⁴),这表明网络几乎可以确定它是一只猫!
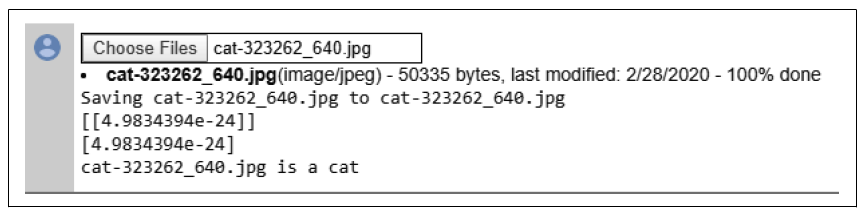
图 3-18. 分类舔爪子的猫
你可以在作者的一个GitHub仓库中找到马或人分类器以及猫狗分类器的完整代码。
本节我们介绍了使用“迁移学习”的方法来完成模型训练,省去了繁琐的前期训练过程,通过迁移已有知识并结合少量数据进行微调即可实现模型的适应性。这种方法是通用的,适用于小型神经网络,同样也适用于如2024年Facebook的开源大型语言模型Llama等知名大模型。在这些预训练模型的基础上,迁移学习可以有效节省大量GPU资源的预训练成本。下一节我们要讲解的也是人工智能模型训练中的很重要的技能“随机失活”法。
搞人工智能开源大语言模型GPT2、Llama的正确姿势的更多相关文章
- 本地推理,单机运行,MacM1芯片系统基于大语言模型C++版本LLaMA部署“本地版”的ChatGPT
OpenAI公司基于GPT模型的ChatGPT风光无两,眼看它起朱楼,眼看它宴宾客,FaceBook终于坐不住了,发布了同样基于LLM的人工智能大语言模型LLaMA,号称包含70亿.130亿.330亿 ...
- 保姆级教程:用GPU云主机搭建AI大语言模型并用Flask封装成API,实现用户与模型对话
导读 在当今的人工智能时代,大型AI模型已成为获得人工智能应用程序的关键.但是,这些巨大的模型需要庞大的计算资源和存储空间,因此搭建这些模型并对它们进行交互需要强大的计算能力,这通常需要使用云计算服务 ...
- 《开源大数据分析引擎Impala实战》目录
当当网图书信息: http://product.dangdang.com/23648533.html <开源大数据分析引擎Impala实战>目录 第1章 Impala概述.安装与配置.. ...
- 开源大数据技术专场(上午):Spark、HBase、JStorm应用与实践
16日上午9点,2016云栖大会“开源大数据技术专场” (全天)在阿里云技术专家封神的主持下开启.通过封神了解到,在上午的专场中,阿里云高级技术专家无谓.阿里云技术专家封神.阿里巴巴中间件技术部高级技 ...
- Hugging News #0324: 🤖️ 黑客松结果揭晓、一键部署谷歌最新大语言模型、Gradio 新版发布,更新超多!
每一周,我们的同事都会向社区的成员们发布一些关于 Hugging Face 相关的更新,包括我们的产品和平台更新.社区活动.学习资源和内容更新.开源库和模型更新等,我们将其称之为「Hugging Ne ...
- 使用 LoRA 和 Hugging Face 高效训练大语言模型
在本文中,我们将展示如何使用 大语言模型低秩适配 (Low-Rank Adaptation of Large Language Models,LoRA) 技术在单 GPU 上微调 110 亿参数的 F ...
- 【转】使用Apache Kylin搭建企业级开源大数据分析平台
http://www.thebigdata.cn/JieJueFangAn/30143.html 本篇文章整理自史少锋4月23日在『1024大数据技术峰会』上的分享实录:使用Apache Kylin搭 ...
- [转载] 一共81个,开源大数据处理工具汇总(下),包括日志收集系统/集群管理/RPC等
原文: http://www.36dsj.com/archives/25042 接上一部分:一共81个,开源大数据处理工具汇总(上),第二部分主要收集整理的内容主要有日志收集系统.消息系统.分布式服务 ...
- Impala:新一代开源大数据分析引擎
Impala架构分析 Impala是Cloudera公司主导开发的新型查询系统,它提供SQL语义,能查询存储在Hadoop的HDFS和HBase中的PB级大数据.已有的Hive系统虽然也提供了SQL语 ...
- 【转】福利大放送--不止是Android,Github超高影响力开源大放送,学习开发必备教科书
[福利大放送]不止是Android,Github超高影响力开源大放送,学习开发必备教科书 目录 一.写在前面 1.free-programming-books 2.oh-my-zsh 3.awes ...
随机推荐
- js map方法处理返回数据,获取指定数据简写方法
map方法处理返回数据,获取指定数据简写方法 前言 后端返回数据为数组列表时,通常比较全面,包含了很多不需要的数据,可以通过 map 方法处理返回数据,筛选出想要的数据 例如 // 返回数据 res ...
- 记一次 .NET某智慧出行系统 CPU爆高分析
一:背景 1. 讲故事 前些天有位朋友找到我,说他们的系统出现了CPU 100%的情况,让你帮忙看一下怎么回事?dump也拿到了,本想着这种情况让他多抓几个,既然有了就拿现有的分析吧. 二:WinDb ...
- 附038.Kubernetes_v1.30.3高可用部署架构二
部署组件 该 Kubernetes 部署过程中,对于部署环节,涉及多个组件,主要有 kubeadm .kubelet .kubectl. kubeadm介绍 Kubeadm 为构建 Kubernete ...
- Maven经验分享(五)Maven拷贝资源
上一章介绍使用ant拷贝资源,这里介绍maven拷贝资源,使用maven-resources-plugin插件. <plugin> <groupId>org.apache.ma ...
- mmdetection使用未定义backbone训练
首先找到你需要用到的 backbone,一般有名的backbone 都会在github有相应的代码开源和预训练权重提供 本文以mobilenetv3 + fastercnn 作为举例,在mmdetec ...
- Odoo13开发环境搭建
准备:windows10 64位系统.Python3.6.8.Pycharm2019.2.Postgresql-12.0-1.Odoo13 其它:nodejs.rtlcss.wkhtmltopdf 安 ...
- java_可变参数&增强for循环
代码比较无厘头,记录看懂的意思 在可变参数的构造方法中,需要使用增强for循环遍历 public class name { String sex; public static void main(St ...
- Gluon 编译 JavaFx -> android apk
Gluon 编译 JavaFx -> android apk 本文的内容属 在linux服务器上 搭建 Gluon 编译 android-apk 环境 这一篇文章直接跟着官网操作一次性成功 虚拟 ...
- Maven 项目 有Dependencies, 使用时无法引用,爆红
1. 找到本地的该依赖的文件夹,将里面的.lastUpdated文件删除 2. IDEA清缓存重启
- 在 Web 中判断页面是不是刷新
在 Web 开发中,我们经常需要区分用户是否通过刷新操作重新加载了页面.这一操作可能是由用户手动刷新(如按下 F5 键或点击浏览器刷新按钮)或通过浏览器自动重新加载.判断页面是否刷新有助于开发者优化用 ...