ETL工具--Sqoop
1. 概述
- Sqoop是apache旗下的一款 ”Hadoop和关系数据库之间传输数据”的工具
导入数据:将MySQL,Oracle导入数据到Hadoop的HDFS、HIVE、HBASE等数据存储系统
导出数据:从Hadoop的文件系统中导出数据到关系数据库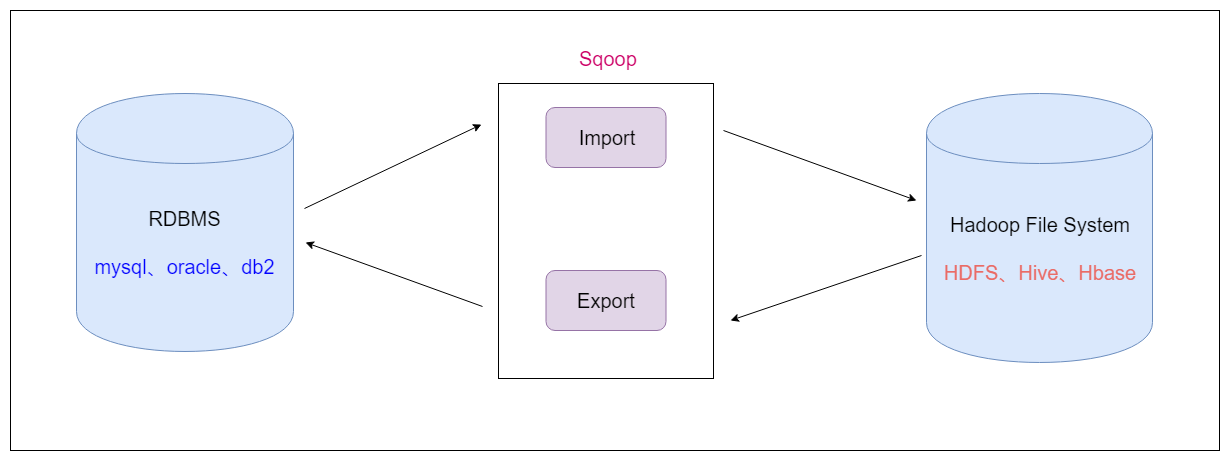
2. Sqoop的工作机制
- 将导入和导出的命令翻译成mapreduce程序实现
- 在翻译出的mapreduce中主要是对inputformat和outputformat进行定制
3. Sqoop1与Sqoop2架构对比
- sqoop在发展中的过程中演进出来了两种不同的架构.架构演变史
- Sqoop1架构
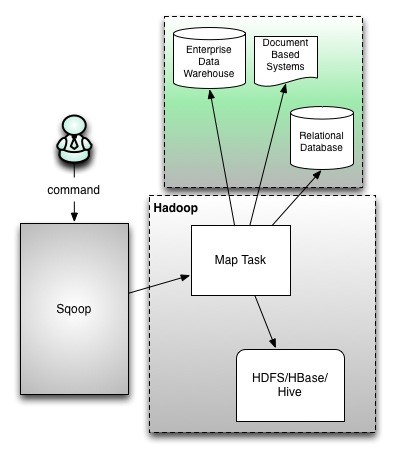
版本号为1.4.x为sqoop1
在架构上:sqoop1使用sqoop客户端直接提交的方式
访问方式:CLI控制台方式进行访问
安全性:命令或脚本中指定用户数据库名及密码
- Sqoop2架构
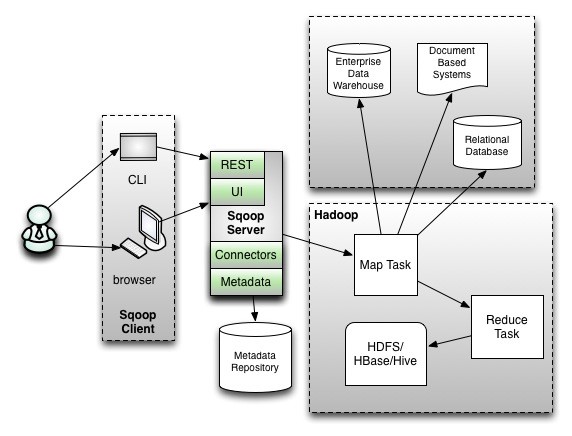
版本号为1.99x为sqoop2
在架构上:sqoop2引入了sqoop server,对connector实现了集中的管理
访问方式:REST API、 JAVA API、 WEB UI以及CLI控制台方式进行访问
- sqoop1与sqoop2比较

Sqoop安装部署
第一步:下载安装包
https://mirrors.bfsu.edu.cn/apache/sqoop/1.4.7
第二步:上传并解压
- 将我们下载好的安装包上传到hadoop03服务器的/bigdata/soft路径下,然后进行解压
cd /bigdata/soft/
tar -xzvf sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz -C /bigdata/install
第三步:修改配置文件
- 更改sqoop的配置文件
cd /bigdata/install/sqoop-1.4.7.bin__hadoop-2.6.0/conf/
mv sqoop-env-template.sh sqoop-env.sh
vim sqoop-env.sh
#Set path to where bin/hadoop is available
export HADOOP_COMMON_HOME=/bigdata/install/hadoop-3.1.4
#Set path to where hadoop-*-core.jar is available
export HADOOP_MAPRED_HOME=/bigdata/install/hadoop-3.1.4
#set the path to where bin/hbase is available
export HBASE_HOME=/bigdata/install/hbase-2.2.6
#Set the path to where bin/hive is available
export HIVE_HOME=/bigdata/install/hive-3.1.2
#Set the path for where zookeper config dir is
export ZOOCFGDIR=/bigdata/install/zookeeper-3.6.2
第四步:添加两个必要的jar包
- sqoop需要两个额外依赖的jar包,将课件资料当中两个jar包添加到sqoop的lib目录下
cd /bigdata/soft
cp java-json.jar mysql-connector-java-5.1.38.jar /bigdata/install/sqoop-1.4.7/lib/

第五步:配置sqoop的环境变量
sudo vim /etc/profile
# 添加如下内容
export SQOOP_HOME=/bigdata/install/sqoop-1.4.7
export PATH=:$SQOOP_HOME/bin:$PATH
- 让环境变量生效
source /etc/profile
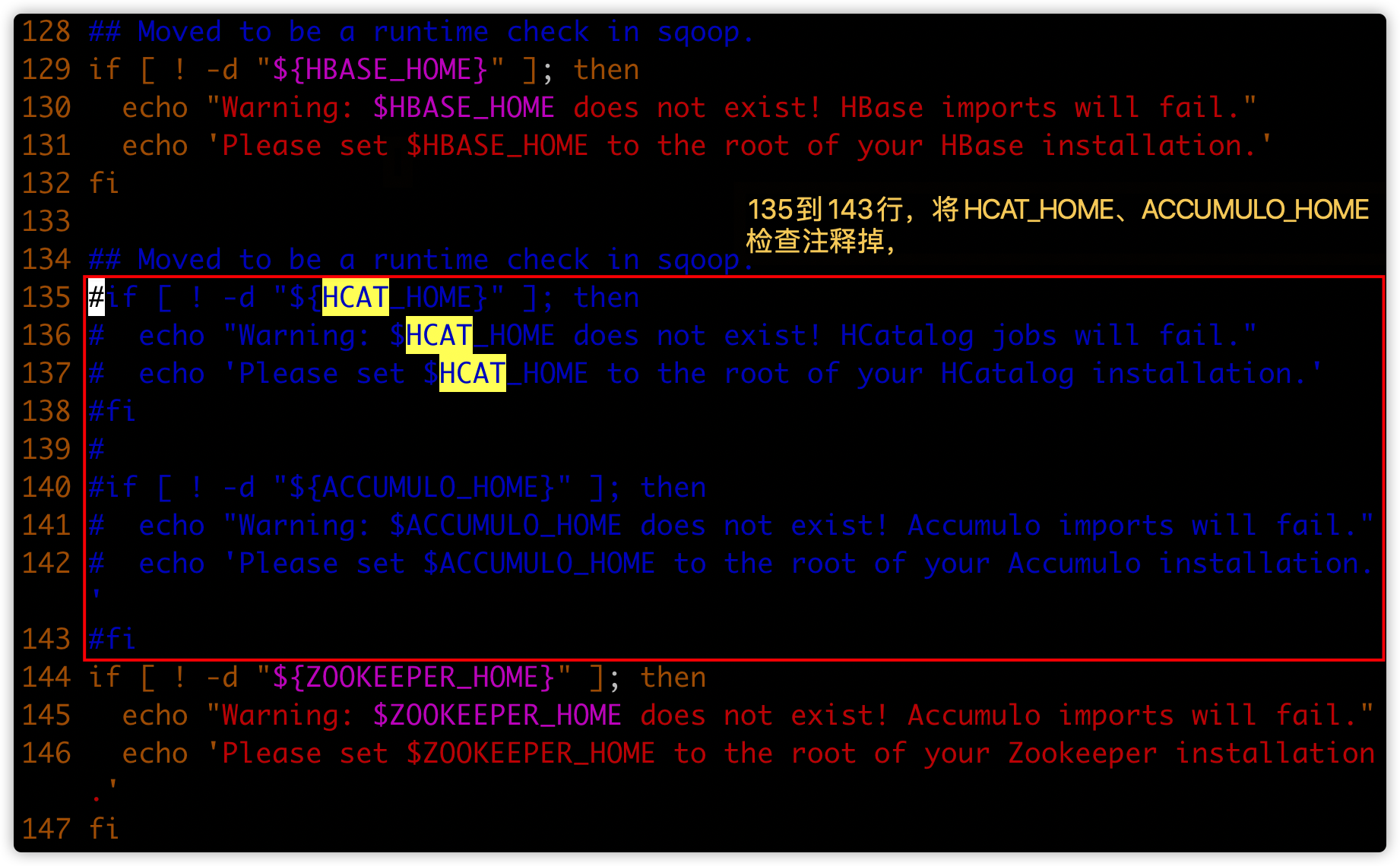
1. sqoop help有warning日志
执行命令
sqoop help,有warning日志
解决方案
[hadoop@hadoop03 bin]$ pwd
/bigdata/install/sqoop-1.4.7/bin
# 搜索HCAT_HOME,将下图红框内容注释掉
[hadoop@hadoop03 bin]$ vim configure-sqoop
2. sqoop help有错误
- 运行sqoop help有错误:
错误: 找不到或无法加载主类 org.apache.hadoop.hbase.util.GetJavaProperty
- 此错误,不影响sqoop的;可以忽略不管
- 如果有洁癖,可以看如下方式解决
1. 解决方案一:
- 简单的做法,直接用修改过的hbase文件,替换集群3个节点目录
/bigdata/install/hbase-2.2.6/bin中的hbase文件 - 重启hbase集群即可
2. 解决方案二
- hadoop01修改hbase命令文件
[hadoop@hadoop01 bin]$ cd /bigdata/install/hbase-2.2.6/bin/
[hadoop@hadoop01 bin]$ vim hbase
如下图显示,找到指定的位置(根据行号或关键字内容进行定位)
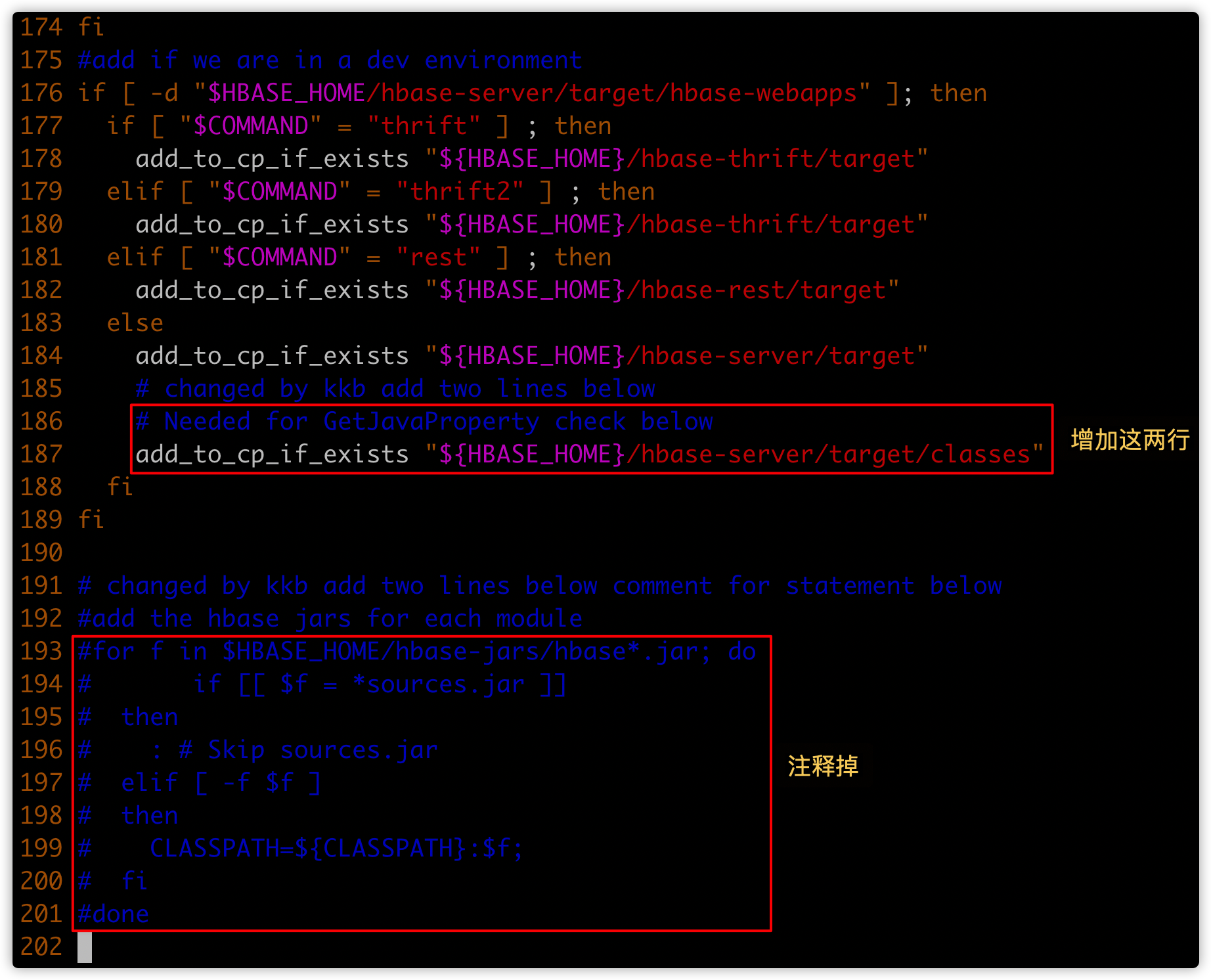
- 新增第一个红框的内容;注意缩进
# Needed for GetJavaProperty check below
add_to_cp_if_exists "${HBASE_HOME}/hbase-server/target/classes"
- 将第二个红框的内容注释掉
继续查找hbase文件,定位到如下黄框内容
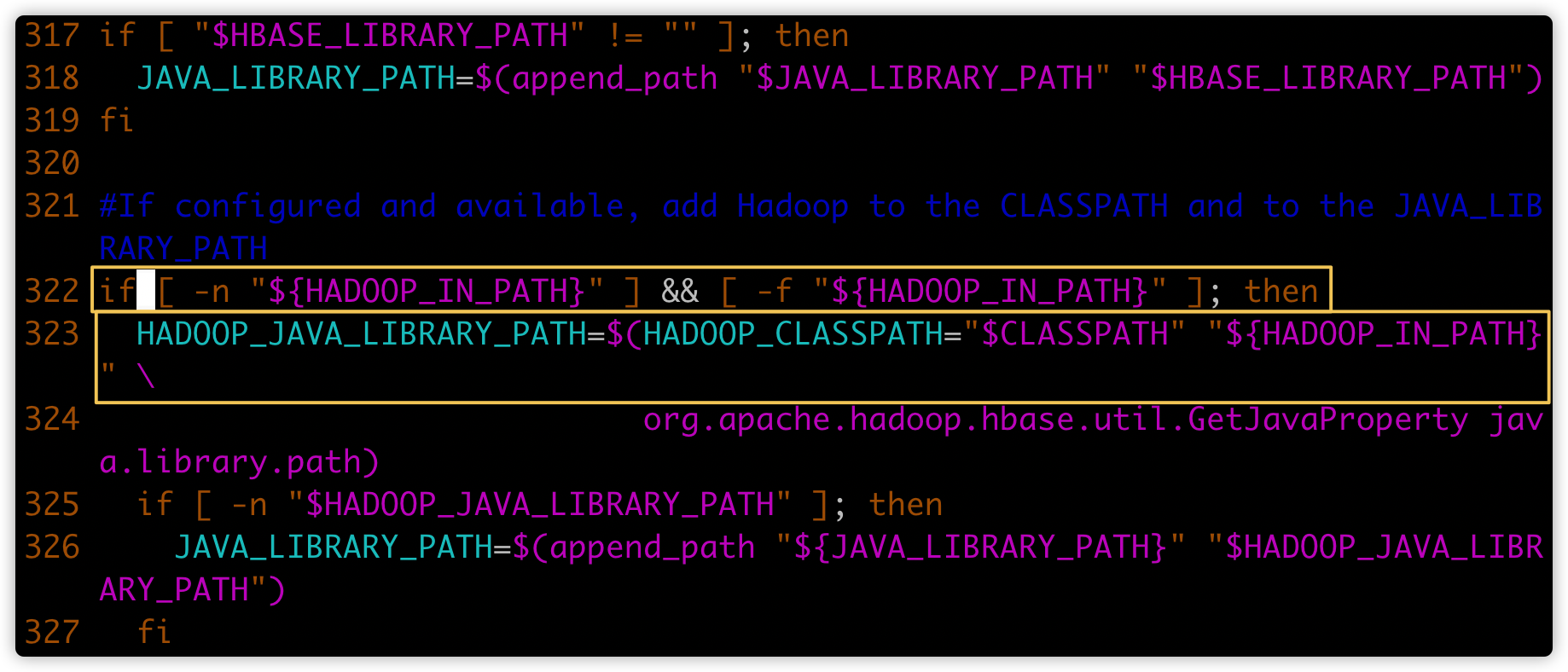
在上图322行(第一个黄色框)增加下图①的代码;注意缩进
temporary_cp=
for f in "${HBASE_HOME}"/lib/hbase-server*.jar; do
if [[ ! "${f}" =~ ^.*\-tests\.jar$ ]]; then
temporary_cp=":$f"
fi
done
- 将上图的第二个黄色框的内容修改成下图②的代码;注意缩进
HADOOP_JAVA_LIBRARY_PATH=$(HADOOP_CLASSPATH="$CLASSPATH${temporary_cp}" "${ HADOOP_IN_PATH}" \
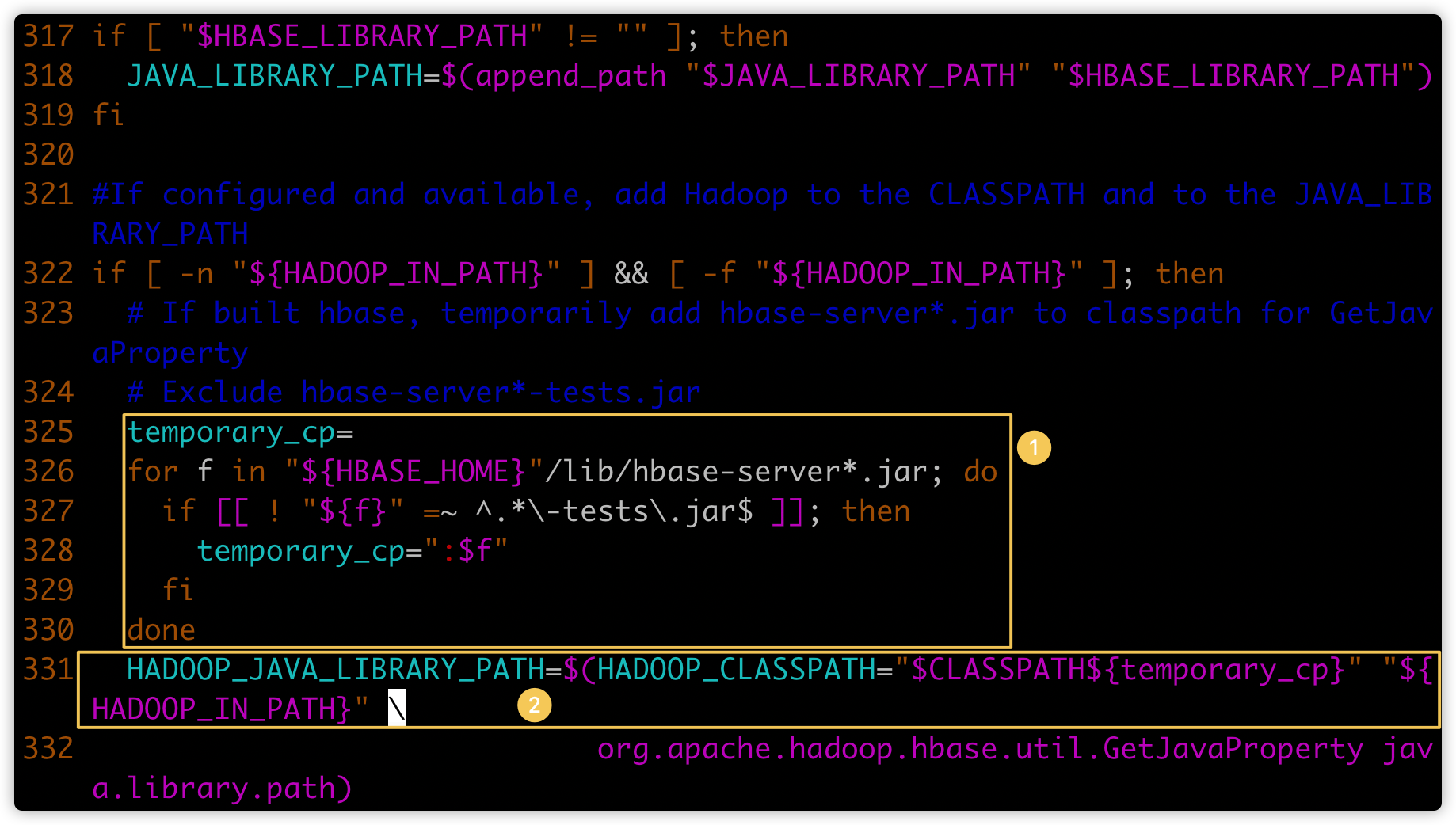
- 保存退出
- 将hbase分发到另外两个节点
[hadoop@hadoop01 bin]$ pwd
/bigdata/install/hbase-2.2.6/bin
[hadoop@hadoop01 bin]$ scp hbase hadoop02:$PWD
[hadoop@hadoop01 bin]$ scp hbase hadoop03:$PWD
- 重启hbase
Sqoop的数据导入
1. 列举出所有的数据库
- 命令行查看帮助
sqoop help
- 列出hadoop02主机所有的数据库
sqoop list-databases --connect jdbc:mysql://hadoop02:3306/ --username root --password 123456
- 查看某一个数据库下面的所有数据表(将数据库名称hive替换成自己的某个数据库名)
sqoop list-tables --connect jdbc:mysql://hadoop02:3306/mysql --username root --password 123456
2. 准备表数据
在mysql中有一个库userdb中三个表:emp, emp_add和emp_conn
表emp:
id name deg salary dept 1201 gopal manager 50,000 TP 1202 manisha Proof reader 50,000 TP 1203 khalil php dev 30,000 AC 1204 prasanth php dev 30,000 AC 1205 kranthi admin 20,000 TP 表emp_add:
id hno street city 1201 288A vgiri jublee 1202 108I aoc sec-bad 1203 144Z pgutta hyd 1204 78B old city sec-bad 1205 720X hitec sec-bad 表emp_conn:
id phno email 1201 2356742 gopal@tp.com 1202 1661663 manisha@tp.com 1203 8887776 khalil@ac.com 1204 9988774 prasanth@ac.com 1205 1231231 kranthi@tp.com 建表语句如下:
CREATE DATABASE /*!32312 IF NOT EXISTS*/`userdb` /*!40100 DEFAULT CHARACTER SET utf8 */;
USE `userdb`;
DROP TABLE IF EXISTS `emp`;
CREATE TABLE `emp` (
`id` INT(11) DEFAULT NULL,
`name` VARCHAR(100) DEFAULT NULL,
`deg` VARCHAR(100) DEFAULT NULL,
`salary` INT(11) DEFAULT NULL,
`dept` VARCHAR(10) DEFAULT NULL,
`create_time` TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP,
`update_time` TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
`is_delete` BIGINT(20) DEFAULT '1'
) ENGINE=INNODB DEFAULT CHARSET=latin1;
INSERT INTO `emp`(`id`,`name`,`deg`,`salary`,`dept`) VALUES (1201,'gopal','manager',50000,'TP'),(1202,'manisha','Proof reader',50000,'TP'),(1203,'khalil','php dev',30000,'AC'),(1204,'prasanth','php dev',30000,'AC'),(1205,'kranthi','admin',20000,'TP');
DROP TABLE IF EXISTS `emp_add`;
CREATE TABLE `emp_add` (
`id` INT(11) DEFAULT NULL,
`hno` VARCHAR(100) DEFAULT NULL,
`street` VARCHAR(100) DEFAULT NULL,
`city` VARCHAR(100) DEFAULT NULL,
`create_time` TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP,
`update_time` TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
`is_delete` BIGINT(20) DEFAULT '1'
) ENGINE=INNODB DEFAULT CHARSET=latin1;
INSERT INTO `emp_add`(`id`,`hno`,`street`,`city`) VALUES (1201,'288A','vgiri','jublee'),(1202,'108I','aoc','sec-bad'),(1203,'144Z','pgutta','hyd'),(1204,'78B','old city','sec-bad'),(1205,'720X','hitec','sec-bad');
DROP TABLE IF EXISTS `emp_conn`;
CREATE TABLE `emp_conn` (
`id` INT(100) DEFAULT NULL,
`phno` VARCHAR(100) DEFAULT NULL,
`email` VARCHAR(100) DEFAULT NULL,
`create_time` TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP,
`update_time` TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
`is_delete` BIGINT(20) DEFAULT '1'
) ENGINE=INNODB DEFAULT CHARSET=latin1;
INSERT INTO `emp_conn`(`id`,`phno`,`email`) VALUES (1201,'2356742','gopal@tp.com'),(1202,'1661663','manisha@tp.com'),(1203,'8887776','khalil@ac.com'),(1204,'9988774','prasanth@ac.com'),(1205,'1231231','kranthi@tp.com');
3. 导入数据库表数据到HDFS
- 使用sqoop命令导入、导出数据前,要先启动hadoop集群
- 下面的命令用于从MySQL数据库服务器中的emp表导入HDFS。
sqoop import --connect jdbc:mysql://hadoop02:3306/userdb --password 123456 --username root --table emp -m 1
如果成功执行,那么会得到下面的输出。
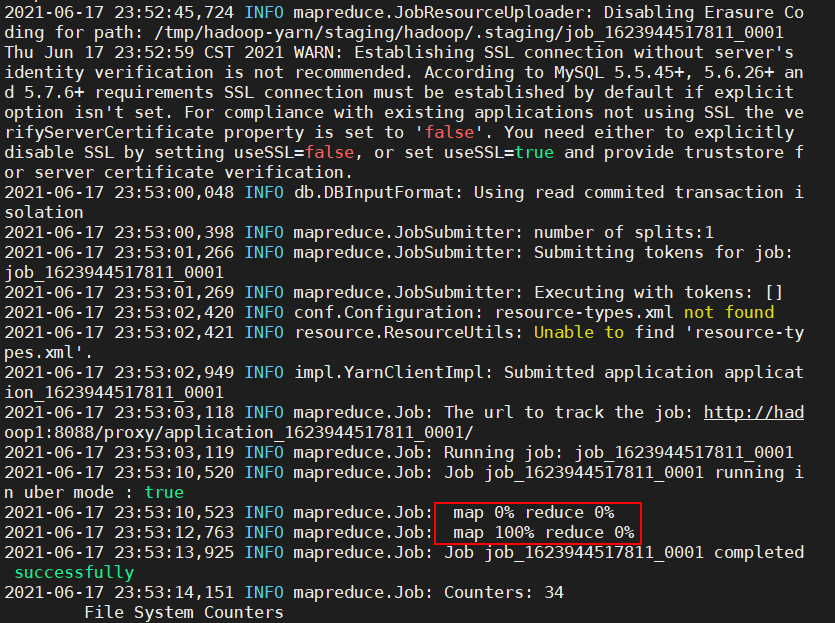
为了验证在HDFS导入的数据,请使用以下命令查看导入的数据
hdfs dfs -ls /user/hadoop/emp

- 以上有参数
--m 1,表示只启动一个map task进行数据的导入 - 如果要开启多个map task的话,需要在命令中添加
--split-by column-name,如下,其中map个数为4
sqoop import --connect jdbc:mysql://hadoop02:3306/userdb --password 123456 --username root --table emp -m 4 --split-by id
4. 导入到HDFS指定目录
- 在导入表数据到HDFS使用Sqoop导入工具,我们可以指定目标目录。
- 使用参数 --target-dir来指定导出目的地,
- 使用参数--delete-target-dir来判断导出目录是否存在,如果存在就删掉
sqoop import --connect jdbc:mysql://hadoop02:3306/userdb --username root --password 123456 --delete-target-dir --table emp --target-dir /sqoop/emp -m 1
- 查看导出的数据
hdfs dfs -text /sqoop/emp/part-m-00000

- 它会用逗号(,)分隔emp_add表的数据和字段。
1201,gopal,manager,50000,TP
1202,manisha,Proof reader,50000,TP
1203,khalil,php dev,30000,AC
1204,prasanth,php dev,30000,AC
1205,kranthi,admin,20000,TP
5. 导入到hdfs指定目录并指定字段之间的分隔符
sqoop import --connect jdbc:mysql://hadoop02:3306/userdb --username root --password 123456 --delete-target-dir --table emp --target-dir /sqoop/emp2 -m 1 --fields-terminated-by '\t'
- 查看文件内容
hdfs dfs -text /sqoop/emp2/part-m-00000

Sqoop的数据导出
将数据从HDFS把文件导出到RDBMS数据库
- 导出前,目标表必须存在于目标数据库中。
- 默认操作是从将文件中的数据使用INSERT语句插入到表中
- 更新模式下,是生成UPDATE语句更新表数据
- 数据是在HDFS当中的如下目录/sqoop/emp,数据内容如下
1201,gopal,manager,50000,TP,2018-06-17 18:54:32.0,2018-06-17 18:54:32.0,1
1202,manisha,Proof reader,50000,TP,2018-06-15 18:54:32.0,2018-06-17 20:26:08.0,1
1203,khalil,php dev,30000,AC,2018-06-17 18:54:32.0,2018-06-17 18:54:32.0,1
1204,prasanth,php dev,30000,AC,2018-06-17 18:54:32.0,2018-06-17 21:05:52.0,0
1205,kranthi,admin,20000,TP,2018-06-17 18:54:32.0,2018-06-17 18:54:32.0,1
第一步:创建mysql表
use userdb;
CREATE TABLE `emp_out` (
`id` INT(11) DEFAULT NULL,
`name` VARCHAR(100) DEFAULT NULL,
`deg` VARCHAR(100) DEFAULT NULL,
`salary` INT(11) DEFAULT NULL,
`dept` VARCHAR(10) DEFAULT NULL,
`create_time` TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP,
`update_time` TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
`is_delete` BIGINT(20) DEFAULT '1'
) ENGINE=INNODB DEFAULT CHARSET=utf8;
第二步:执行导出命令
通过kkb来实现数据的导出,将hdfs的数据导出到mysql当中去
sqoop export \
--connect jdbc:mysql://hadoop02:3306/userdb \
--username root --password 123456 \
--table emp_out \
--export-dir /sqoop/emp \
--input-fields-terminated-by ","
第三步:验证mysql表数据
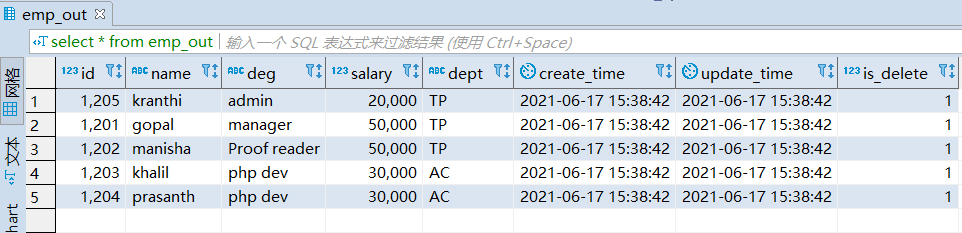
ETL工具--Sqoop的更多相关文章
- 开源作业调度工具实现开源的Datax、Sqoop、Kettle等ETL工具的作业批量自动化调度
1.阿里开源软件:DataX DataX 是一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL.Oracle等).HDFS.Hive.ODPS.HBase.FTP等各种异构数据源之间稳 ...
- ETL工具Datax、sqoop、kettle 的区别
一.Sqoop主要特点: 1.可以将关系型数据库中的数据导入到hdfs,hive,hbase等hadoop组件中,也可以将hadoop组件中的数据导入到关系型数据库中: 2.sqoop在导入导出数据时 ...
- etl工具,kettle实现了周期
Kettle这是国外的来源ETL工具,纯java写.能Window.Linux.Unix在执行.绿色无需安装,稳定高效的数据提取. 业务模型: 在关系型数据库中有张非常大的数据存储表,被设计成奇偶库存 ...
- ETL工具--kettle篇(17.10.09更新)
ETL是EXTRACT(抽取).TRANSFORM(转换).LOAD(加载)的简称,实现数据从多个异构数据源加载到数据库或其他目标地址,是数据仓库建设和维护中的重要一环也是工作量较大的一块.当前知道的 ...
- 【转】阿里出品的ETL工具dataX初体验
原文链接:https://www.imooc.com/article/15640 来源:慕课网 我的毕设选择了大数据方向的题目.大数据的第一步就是要拿到足够的数据源.现实情况中我们需要的数据源分布在不 ...
- etl工具,kettle实现循环
Kettle是一款国外开源的ETL工具,纯Java编写,可以在Window.Linux.Unix上运行,绿色无需安装,数据抽取高效稳定. 业务模型: 在关系型数据库中有张很大的数据存储表,被设计成奇偶 ...
- ETL工具-Kattle:初识kattle
ETL是EXTRACT(抽取).TRANSFORM(转换).LOAD(加载)的简称,实现数据从多个异构数据源加载到数据库或其他目标地址,是数据仓库建设和维护中的重要一环也是工作量较大的一块.当前知道的 ...
- etl工具
ETL 工具下载全集 包括 Informatica Datastage Cognos( 持续更新) Datastage 8.0 BT种子下载:http://files.cnblogs.com/ta ...
- etl学习系列1——etl工具安装
ETL(Extract-Transform-Load的缩写,即数据抽取.转换.装载的过程),对于企业或行业应用来说,我们经常会遇到各种数据的处理,转换,迁移,所以了解并掌握一种etl工具的使用,必不可 ...
- sql server 内置ETL工具学习(一) BCP篇
sql server 内置ETL工具学习 常用的导入方式:bcp, BULK INSERT,OPENROWSET和 SSIS. BCP BCP全称BULK COPY PROGRAM 有以下特点: 命令 ...
随机推荐
- hbase的管理相关看法
运维任务 regionserver添加/删除节点 master备份 1 添加新节点 复制hbase目录并进行配置文件修改(regionserver增加新节点)并保持配置文件在全集群一致,在新节点上启动 ...
- 3.12 Linux创建文件及修改文件时间戳(touch命令)
既然知道了如何在 Linux 系统中创建目录,接下来你可能会想在这些目录中创建一些文件,可以使用 touch 命令. 需要注意的是,touch 命令不光可以用来创建文件(当指定操作文件不存在时,该命令 ...
- 离线快速LCA(最近公共祖先) Tarjan算法
离线快速LCA(最近公共祖先) Tarjan算法 前言 对于 OIer 来说,LCA 一直是处理树上问题的好帮手,无论是倍增还是树剖都有着优秀的 \(\log n\) 的复杂度.不过由于我们(数据规模 ...
- 一个关于CountDownLatch的并发需求
需求 A,B,C可并发运行,全部成功才算成功,一个失败全员回滚. 思考 使用CountDownLatch,可以保证三个线程结束后,才进行提交成功状态.但是怎么才能判断某个任务失败了呢? 捕获子线程异常 ...
- vue开发一个简单的组件
首先在项目中新建一个js文件 在文件内创建一个对象,对象内创建install方法,将对象用export default暴漏出去 export default{ install(){ console.l ...
- Mysql之innodb引擎
优势总结 只有数据库引擎为innodb且事务的隔离级别repeatable--read (可重复读)的时候 才会使用mvcc来实现多版本控制 事务中的可重复读可以有效的避免幻读问题 innodb从硬盘 ...
- 鸿蒙UI开发快速入门 —— part05:组件的样式复用
1. 为什么要样式复用? 如果每个组件的样式都需要单独设置,在开发过程中会出现大量代码在进行重复样式设置,虽然可以复制粘贴,但为了代码简洁性和后续方便维护,样式的复用就很有必要了. 为此,鸿蒙推出了可 ...
- 入门 .NET Aspire: 使用 .NET 简化云原生应用开发
入门 .NET Aspire: 使用 .NET 简化云原生应用开发 https://devblogs.microsoft.com/dotnet/introducing-dotnet-aspire-si ...
- 一文学会powshell使用及功能
声明! 原文来自微信公众号泷羽Sec-track 认识powsehll PowerShell(通常称作PowerShell或Windows PowerShell)是由微软开发的一种任务自动化和配置管理 ...
- 2024年1月Java项目开发指南6:接口测试
我们使用API Fox这款工具对接口进行测试. (你要是会其他的例如postman进行测试也行) https://apifox.com/ 新建一个项目,新增一个接口 因为这个接口没有参数,所以无需填写 ...