理解Rust引用及其生命周期标识(下)
在上一篇文章中,我们围绕 “引用必然存在来源” 这一基本概念,介绍了Rust中引用之间的关系,以及生命周期标记的实际意义。我们首先从最简单的单参数方法入手,通过示例说明了返回引用与输入引用参数之间的逻辑关系;通过多引用参数的复杂场景,阐释了生命周期标注(本人给其命名为 “引用关系标记”)的必要性及其编译器检查机制。在上一篇文章的最后,我们还提到了关于包含引用的结构体,只不过由于篇幅原因以及文章结构原因,我们没有细讲。因此,在本文中,我们将继续通过实际示例出发,探讨包含引用的结构体的生命周期相关内容。
包含引用的结构体的本质
单从数据结构的角度来看,结构体本质上是具有类型安全的复合数据体,即结构体是一个可以包含多个数据字段的逻辑单元:
struct MyData {
pub num: i32,
pub is_ok: bool,
}
引用的本质也是一份包含了被引用者内存地址信息(以及其他上下文)的数据,因此,我们当然可以让结构体包含引用字段:
struct MyData<'a> {
pub num_ref: &'a i32,
pub is_ok: bool,
}
在这里我们先暂且不考虑具体的语法(添加生命周期参数标记),而是思考一下一个包含引用的结构体相比于没有包含任何引用的结构体究竟有什么特殊之处。首先,一个结构体一旦被创建出来,就意味着它内部的数据字段此时都是合法的数据,并且,结构体中的字段数据一定不可能晚于这个结构体创建时刻。
struct Data {
pub num: i32
}
// main
let num_val = 123;
let data = Data { num: num_val } // <- Data实例化时,里面的字段的数据肯定早于实例化当前Data
有的读者可能会给出这样的反例:
struct Data {
pub num: Option<i32>
}
// main
let mut data = Data { num: None };
let num_val = Some(123);
data.num = num_val;
请注意,这里结构体中的num字段类型是Option<i32>,而不是i32,因此,我们需要在创建Data结构体实例数据的时候,把Option<i32>类型数据准备好,这里我们用的是None。这里并没有违背我们上面说的“结构体中的字段数据一定不可能晚于这个结构体创建时刻”。
在笔者看来,一个包含了引用的结构体有如下两个信息点:
- 本身可以作为一种引用类型来看。
- 可以将其创建的实例等价为一个引用。
我们先看第1点。我们知道,i32是一种类型,&i32也是一种类型。同样的,像上述的MyData这个结构体同样是一种类型。同时,因为该结构体包含了引用,所以我们可以将其等价理解为某种引用类型:
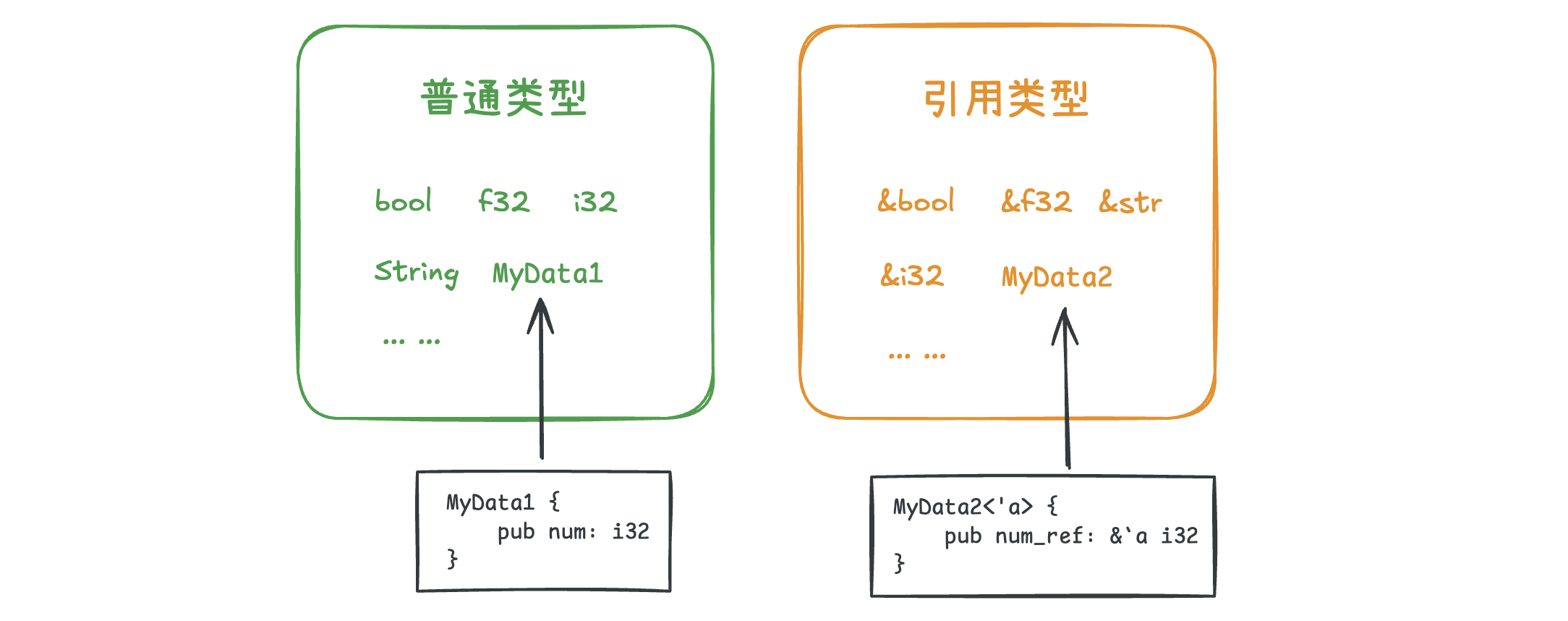
上图中,笔者将MyData1归为了普通类型,而将MyData2归为了引用类型。它俩区别在于,MyData1不包含任何的引用字段,而MyData2包含引用字段。
对于第2点,当我们创建一个包含引用的结构体的实例以后,这个实例本身也可以理解为一个引用:
let num = 123;
// ┍ data这个变量本质上一个引用
let data: MyData2 = { num_ref: &num }
这里的data变量,可以等价为一个引用,它类似于这样的代码:
let num = 123;
let other = #
只不过在结构体形式下,我们把这个所谓的&num赋值给了结构体内部某个字段而已。
单个引用的结构体
在大体上能够理解包含引用的结构体的本质以后,我们就可以按照之前的思路,来理解这种含引用的结构体实例变量的其生命周期相关内容了。
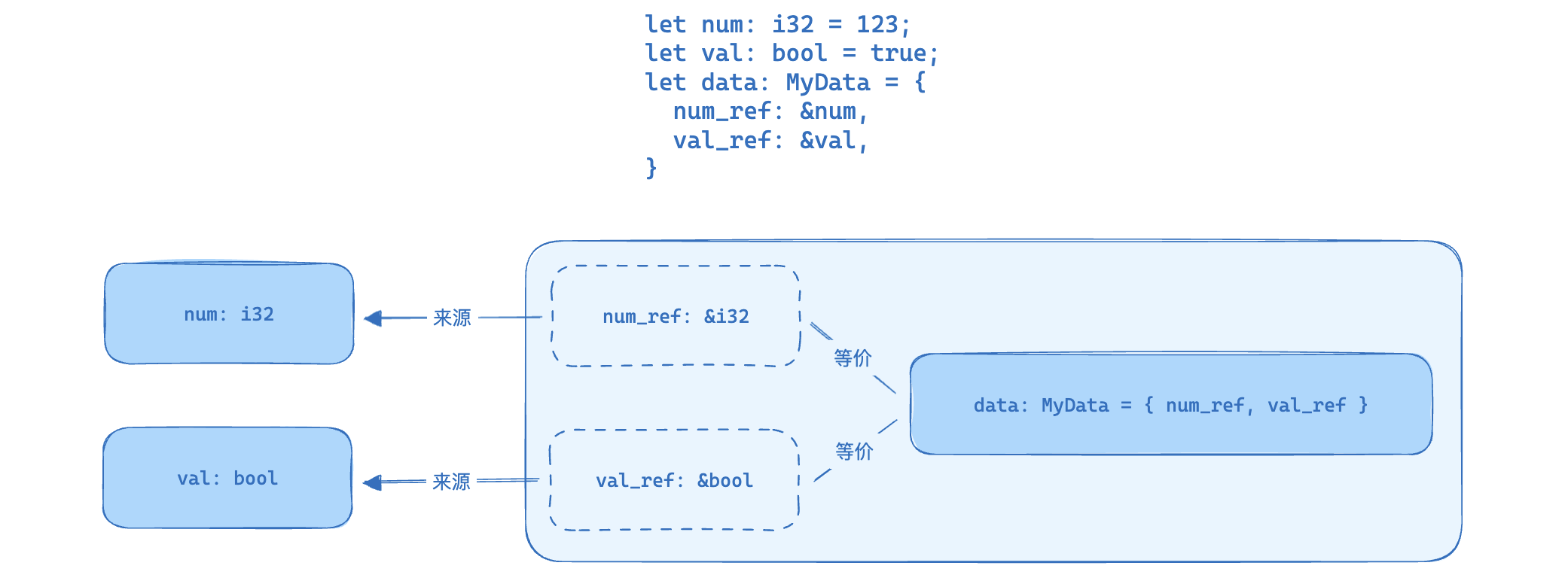
首先,一个创建出来的含引用的结构体的实例本身就成为了一个引用数据,而不是普通数据了,那这个引用必然有其来源,而这个引用的来源自然是先前另一个变量借用而来的引用:

注意看上图,我将num_ref和data圈在了一起,并用“等价”相连接,是因为num_ref一旦设置到了MyData结构体的字段中,就意味着num_ref这个引用被转移到了MyData内部,成为了其一部分,此时data: MyData尽管看起来就是一个普通的数据,但此时它就是一个引用数据。
从上面的关系图我们很容易知道,如果要满足正确的生命周期,很显然,data(num_ref的 “代名词”)不能存活的比其来源num久。
始终牢记:”引用必然有其来源,且不能活的比其来源更久“
多个引用的结构体
事实上,包含多个引用的结构体本质上和包含单个引用的结构体的理解思路一致的,即结构体中多个引用字段都有其来源,唯一需要注意的为了保证包含多引用的结构体实例在运行时合法,很显然这个结构体实例的存活时间不能超过结构体所包含的多个引用字段的各自存活时间。还是用来源关系图来表达如下的代码:
let num: i32 = 123;
let val: bool = true;
let data: MyData = {
num_ref: &num,
val_ref: &val,
}
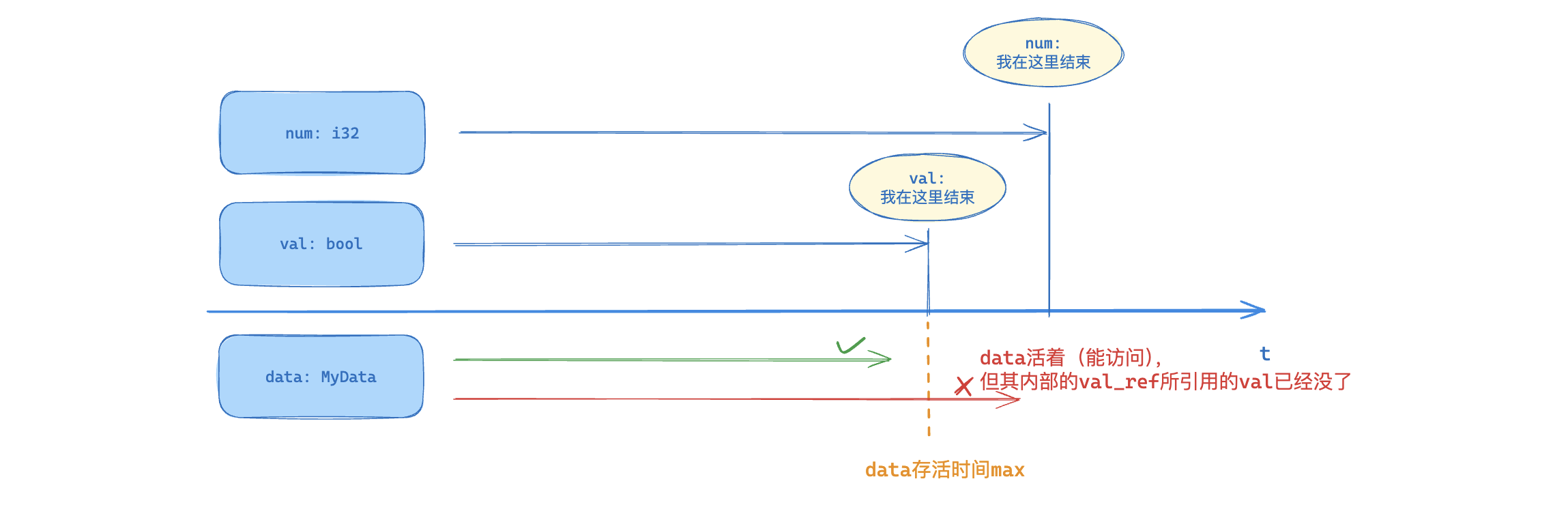
data来包含了num_ref和val_ref,也就是说,data此时应该视为num_ref和val_ref这两个引用的“结合体”。而num_ref和val_ref又各自来源于num和val,那么为了满足内存安全的要求,我们只有让data的存活时间同时不能超过num_ref和val_ref各自所引用的源头数据num和val的存活时间。如果随时都要同时满足,就只有让data的存活时间不能超过num和val其中距离销毁时刻最近的那一个:
结构体的生命周期参数标识
目前为止,我们基本理解了包含引用的结构体究竟是一个什么“东西”以及它的存活要求,但Rust中让很多新手难以理解的,其实是结构体中的生命周期参数标识,比如:
struct MyData<'a> {
pub num_ref: &'a i32
}
甚至有一些“丧心病狂”的代码:
struct MyData<'a> {
pub num_ref: &'a i32
}
struct MyDataWrapper<'a, 'b> {
pub my_data: &'a MyData<'b>, // wtf!
pub len: &'b i32,
}
但请不要担心,在阅读了本文以后,我相信你能够很轻松的理解上面这些代码的意义。在继续之前,让我们回顾一下在《理解Rust引用及其生命周期标识(上)》一个例子:
fn func<'a>(num_ref: &'a i32) -> &'a i32 {
num_ref
}
fn main() {
let num = 123;
let num_ref = #
let res = func(num_ref);
}
在这个例子中,生命周期参数标识的核心作用,是把func方法的输入引用参数num_ref和输出引用&i32建立依赖关联(它们都使用了相同的生命周期参数'a)。而正是由于该关联关系,我们可以分析出上述的res(返回的引用)本质上依赖num变量。因此,为了内存安全性,我们很显然不能让res这一引用的存活时间超过它的来源num。所以,一旦编译器发现num和res的生命周期不正确时,会予以编译错误。
添加参数标识的必要性
那为什么包含引用的结构体需要为其添加生命周期参数呢?在笔者看来,核心作用是为了让开发者通过引用关系标记来更加明确的指定相关的引用依赖关系。让我们用一个例子来更好的解释。
首先,让我们还是定义一个包含引用的结构体:
struct MyData { // 先假设此时没有生命周期参数
num_ref: &i32
}
然后,我们定义如下签名的方法,该方法能够返回一个包含引用的结构体实例:
fn func(num_ref1: &i32, num_ref2: &i32) -> MyData;
基于这个方法签名,无论其内部的代码怎样编写,我们都可以将其简化为如下的流程:
fn func(num_ref1: &i32, num_ref2: &i32) -> MyData {
let num_ref: &i32 = ???;
let data = MyData { num_ref: num_ref };
data
}
MyData中的num_ref字段是一个引用,基于 “引用不可能凭空产生” ,一定要有一个来源,这里只能是num_ref1或者num_ref2。然而,究竟是num_ref1还是num_ref2呢?很显然我们(以及Rust编译器)是无法通过静态的代码就能分析出,毕竟这是一个运行时才能知道的结果,例如下面的伪代码就没法静态确定:
fn func(num_ref1: &i32, num_ref2: &i32) -> MyData {
let current_sec = ... // 当前运行时的秒数
let num_ref: &i32;
if current_sec % 2 == 1 // 秒数为奇数
num_ref = num_ref1;
else
num_ref = num_ref2;
let data = MyData { num_ref: num_ref };
data
}
既然无法确定返回结构体中的引用字段究竟与哪个入参存在依赖关系,编译器可以做到的一种检查方式就是确保返回的MyData的实例的存活时间不能超过入参num_ref1和num_ref2这两个引用的来源变量存活时间最短的那一个,因为MyData持有的num_ref引用不管依赖哪一个,但只要其存活时间不超过num_ref1和num_ref2所对应的来源变量最先销毁的那个,MyData持有的num_ref就一定是合法的。
尽管这样的处理限制理论上来讲是“最保险最安全”的,但在某些场景下又过于严格了,比如如下的代码从内存安全的角度来看,也是合理的:
fn func(num_ref1: &i32, num_ref2: &i32) -> MyData {
println!('{}', num_ref2) // <- num_ref2只用做其它用途,不会与最终返回的MyData产生关系
// 返回的MyData只依赖num_ref1,即只依赖num_ref1的来源
let data = MyData { num_ref: num_ref1 };
data
}
上述func返回的MyData实例所包含的引用只会来自于num_ref1,永远不会来自num_ref2,也就是说,返回的MyData只需要保证其存活时间不超过num_ref1的来源变量的存活时间即可。但如果按照上述“最安全最保险”的方式进行生命周期检查,Rust编译器是不会给我们通过的。为了即可以保证内存安全,又不过于严格限制引用关系(例如此时这种情况),Rust做法是要求开发者通过显式的生命周期参数标识来告诉告知编译器:返回的MyData中的num_ref字段只会和入参num_ref1产生关系。
对于func的入参,只需要给num_ref1和num_ref2分别给予不同的生命周期参数来区分它们:

但是对于MyData来说,我们应该如何的将入参num_ref1的生命周期参数'a与MyData中的num_ref这个引用字段进行关联呢?Rust语言规范给出的答案就是对于包含引用的结构体在定义时必须要增加生命周期“形式”参数。比如MyData我们可以这样定义:
struct MyData<'hello> {
num_ref: &'hello i32,
}
面对上述定义的结构体,我们可以按照这样的理解思路来看:
MyData放置参数列表的尖括号<xxx>中的第一个位置是一个引用生命周期参数标识,这里写作'hello;MyData中的num_ref这个引用类型的字段的生命周期参数标识使用了参数列表中第一个位置上的的'hello,因此,在将来我们使用MyData的时候,填入的实际周期参数就对应了num_ref字段。
紧接着,我们不气上面的方法签名。此时,我们只需要在返回的MyData把实际的生命周期参数标识'a填入到尖括号中即可:

而此时的'a这个生命周期参数标识叫做“实际参数 ”,它放在了参数列表的第一位,指代了MyData在定义时的参数'hello:

至此,我们就完成了整个依赖的链路的确定。相信读者在阅读了上述的内容以后,能够理解对于包含引用的结构体添加需要添加生命周期参数标识的必要性了吧。记住,对于结构体上定义时的生命周期参数标识,是一种标记,它在参数列表(就是结构体名称后面的尖括号列表<xxx, xxx>)中的位置用于在将来实际使用时传入到对应的位置来表达实际的意义。
注意结构体与结构体引用
关于包含结构体引用的实例还有一个需要读者注意点就是仔细区分结构体实例与其借用而来的引用。例如下面的代码:
struct MyData<'a> {
num_ref: &'a i32
}
fn func<'a, 'b>(data_ref: &'a MyData<'b>);
上述的方法有两个生命周期参数标识'a和'b,其中'a用于标记&MyData这个结构体实例的引用;而'b则用于标记MyData实例中的字段num_ref这个引用。注意它俩有着不同的概念,用依赖图可能更加直接:

data_ref依赖data,而data包含num_ref,即依赖于num,因此data_ref的生命周期存活时间,不能超过num的存活时间。
生命周期参数标记不改变客观存在的生命周期
很多Rust新手可能会有这样的误区,认为当修改了或者设置了方法的生命周期参数标记的时候,就会改变实际传入的变量的生命周期,这是很多新手无法掌握生命周期参数标记的典型问题。但实际上,生命周期参数标记的核心作用是通过语法约束向编译器提供引用关系的逻辑描述,而不会改变引用本身客观存在的生命周期范围。通常,我们需要从“客观生命周期事实”和“主观引用关系逻辑描述”两个方面来看待包含生命周期参数标记的代码。例如,如下的代码:
fn func<'a>(num_ref: &'a i32) -> &'a i32 {
// ... ...
}
fn main() {
let result: &i32;
{
let num: i32 = 123;
let num_ref: &i32 = #
result = func(num_ref);
}
println!("{}", result);
}
从“客观生命周期事实”的角度来看,result这个&i32引用的生命周期是最长的,比起num_ref以及num都长;而“主观引用关系逻辑描述”来看,这个result是由func输出而来,而观察该方法的签名,我们知道通过'a引用生命周期参数标记,返回的引用生命周期依赖于入参,而入参是num_ref,来源于num,因此它不能超过num的生命周期。因此,我们(Rust编译器)能够根据其中的矛盾点而识别到错误。
写在最后
本文在编写过程中也是断断续续,修修改改了有小半个月才完成,虽然文章已经编写了完成了,但是笔者还有很多内容想说,就放在后续的文章讲吧。
理解Rust引用及其生命周期标识(下)的更多相关文章
- 【译】深入理解Rust中的生命周期
原文标题:Understanding Rust Lifetimes 原文链接:https://medium.com/nearprotocol/understanding-rust-lifetimes- ...
- 我所理解的 Laravel 请求 生命周期
转载自:https://laravel-china.org/topics/3343/my-understanding-of-the-laravel-request-life-cycle 当你使用一个工 ...
- MVVM的理解和Vue的生命周期
一.对于MVVM的理解? MVVM 是 Model-View-ViewModel 的缩写.Model代表数据模型,也可以在Model中定义数据修改和操作的业务逻辑.View 代表UI 组件,它负责将数 ...
- Spring官网阅读(十)Spring中Bean的生命周期(下)
文章目录 生命周期概念补充 实例化 createBean流程分析 doCreateBean流程分析 第一步:factoryBeanInstanceCache什么时候不为空? 第二步:创建对象(crea ...
- 理解React组件的生命周期
本文作者写作的时间较早,所以里面会出现很多的旧版ES5的时代的方法.不过,虽然如此并不影响读者理解组件的生命周期.反而是作者分为几种不同的触发机制来解释生命周期的各个方法,让读者更加容易理解涉及到的概 ...
- JVM详解之:汇编角度理解本地变量的生命周期
目录 简介 本地变量的生命周期 举例说明 优化的原因 总结 简介 java方法中定义的变量,它的生命周期是什么样的呢?是不是一定要等到方法结束,这个创建的对象才会被回收呢? 带着这个问题我们来看一下今 ...
- asp.net MVC 应用程序的生命周期(下)
看看上面的UrlRoutingModule源码里面是怎么实现Init方法的,Init()方法里面我标注红色的地方: application.PostResolveRequestCache += new ...
- Rust 闭包与生命周期
- Rust生命周期bound用于泛型的引用
在实际编程中,可能会出现泛型引用这种情况,我们会编写如下的代码: struct Inner<'a, T> { data: &'a T, } 会产生编译错误: error[E0309 ...
- 对Rust所有权、借用及生命周期的理解
Rust的内存管理中涉及所有权.借用与生命周期这三个概念,下面是个人的一点粗浅理解. 一.从内存安全的角度理解Rust中的所有权.借用.生命周期 要理解这三个概念,你首要想的是这么做的出发点是什么-- ...
随机推荐
- Mac上安装mongoDB详细教程
Mac OSX 平台安装 MongoDB MongoDB 提供了 OSX 平台上 64 位的安装包,你可以在官网下载安装包. 下载地址:https://www.mongodb.com/download ...
- w3cschool-Spring Security
https://www.w3cschool.cn/springsecurity/na1k1ihx.html Spring Security,这是一种基于 Spring AOP 和 Servlet 过滤 ...
- Golang-反射10
http://c.biancheng.net/golang/reflect/ Go语言反射(reflection)简述 反射(reflection)是在 Java 出现后迅速流行起来的一种概念,通过反 ...
- w3cschool-R语言 教程
https://www.w3cschool.cn/r/ R语言教程 R语言是用于统计分析,图形表示和报告的编程语言和软件环境. R语言由Ross Ihaka和Robert Gentleman在新西兰奥 ...
- DICOM-SCP,可以直接使用的SCP(.net framework 4.6.1以上)控制台接收端
此程序只能运行在.net framework 4.6.1版本上的环境,如果要运行在低版本环境,请看上一篇文档 using System; using System.IO; using System.T ...
- Superset 筛选器理解
免于被筛选器筛选,dashboard中,编辑,高级,"__time_range": {"scope": ["ROOT_ID"], " ...
- AI编程:cursor使用教程
这是小卷对AI编程工具学习的第1篇文章,今天以cursor为例,通过给提示词,让不懂编程的小白也能自己用代码实现需求 1.什么是AI编程工具? 可以分为两类: 狭义的AI编程工具 面向程序员的,主要用 ...
- manim边学边做--通用变换
在 Manim 动画制作中,Transform.TransformFromCopy.ReplacementTransform和Restore是四个通用的对象变换动画类. 这几个类能够实现从一个对象到另 ...
- Luogu P2292 HNOI2004 L 语言 题解 [ 紫 ] [ AC 自动机 ] [ 状压 dp ]
L 语言:很好的一道状压 dp 题. 思路 看到这题,首先可以想到一个很暴力的 dp,设 \(dp_i\) 表示考虑到第 \(i\) 位能否被理解,暴力匹配字符串转移即可. 第一个优化也很显然,暴力匹 ...
- 『玩转Streamlit』--会话状态管理
在Web应用开发中,会话管理是一个至关重要的概念,它能够帮助开发者追踪用户在应用中的行为和状态,从而为用户提供更加个性化.连贯且高效的交互体验. Streamlit作为一个简单而强大的用于快速构建和部 ...