从零开始:基于CUDA 12.6的YOLOv5模型训练实战(RTX 2050显卡全流程)
基于cuda12.6训练yolov5模型
前面完成了使用CPU调用yolov5s模型进行识别车辆,现在想训练自己的模型进行目标识别,使用CPU效率太低,尝试使用GPU加速的Pytorch,再重新整理了一下完整的流程
注:
- 显卡:RTX 2050
- cuda:NVIDIA CUDA 12.7.33
最后完成了一个识别doro头像的模型:


GitHub开源地址:https://github.com/ChengYull/YOLOv5-CUDA12_6-Training
环境部署
Anaconda环境
Anaconda 是一个用于数据科学和机器学习的开源 Python 发行版本,它简化了包管理和环境管理。可以创建隔离的 Python 环境,避免包冲突。
- 隔离的Python环境非常重要,因为在训练时用到的图片标注工具需要Python3.9版本,而进行训练时用的是Python3.10版本
前往官网下载最新版即可:https://www.anaconda.com/download/
安装完成后使用win+r输入cmd打开命令行,输入conda --version命令
如果成功获取到了版本,说明安装成功
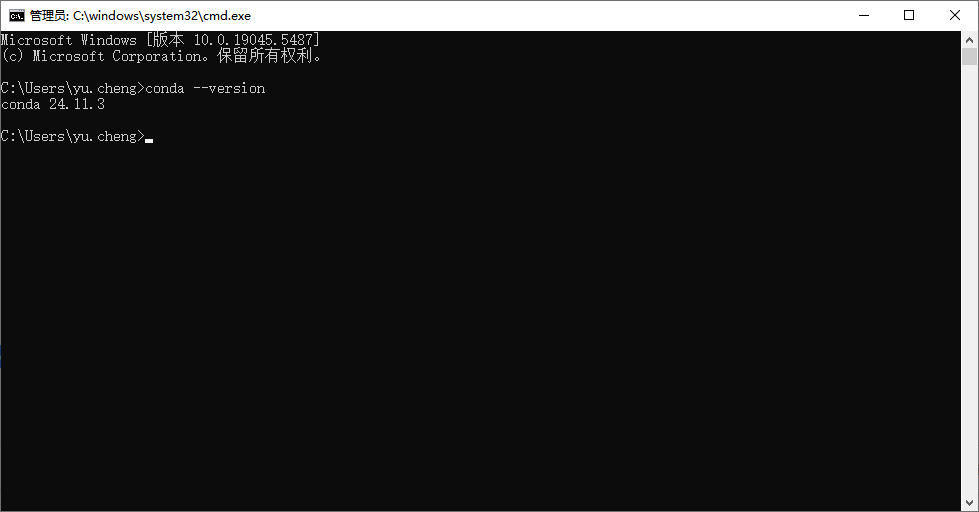
如果提示找不到conda命令,则需要手动配置下环境变量
找到系统变量中的Path,然后下Anaconda安装目录中的condabin目录添加进去
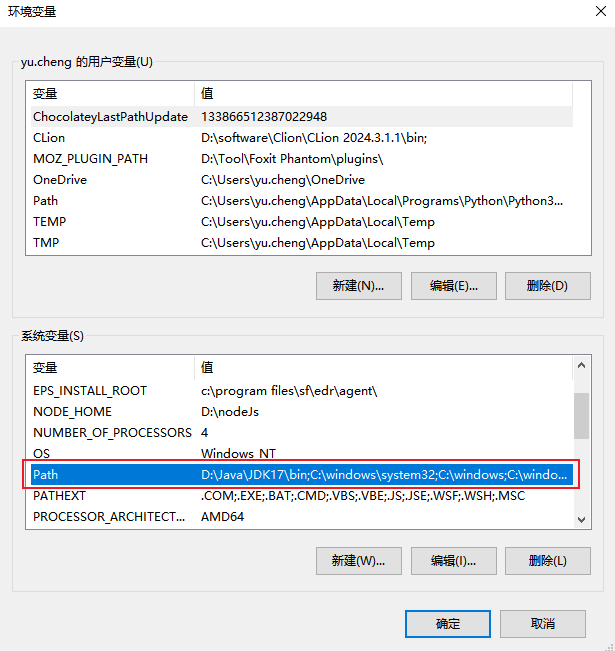
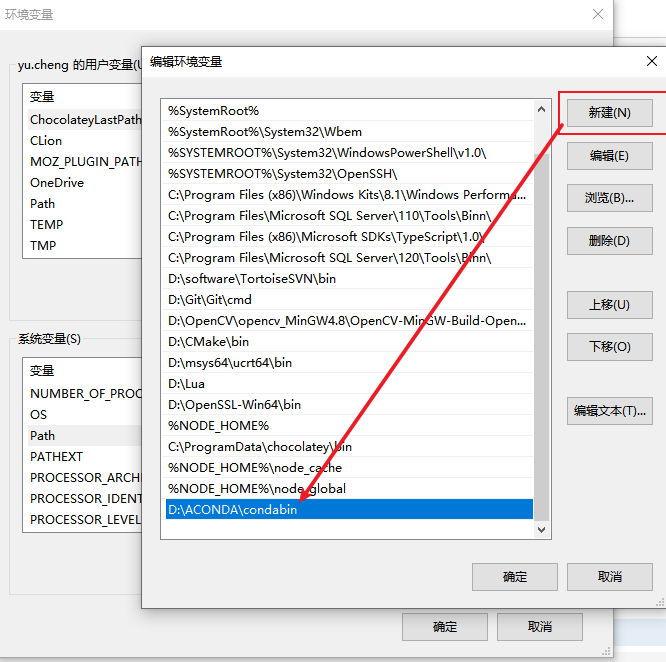
确定关闭环境变量窗口后,新开命令行重新输入conda --version命令 应当是能获取到对应安装的版本
至此Anaconda环境配置完成
- 常用命令
- 创建环境:
conda create -n 环境名 python=版本号 - 激活环境:
conda activate 环境名 - 删除环境:
conda env remove --name 环境名
- 创建环境:
环境配置完成,顺便创建虚拟环境
命令行输入:
conda create -n doro python=3.10
创建环境
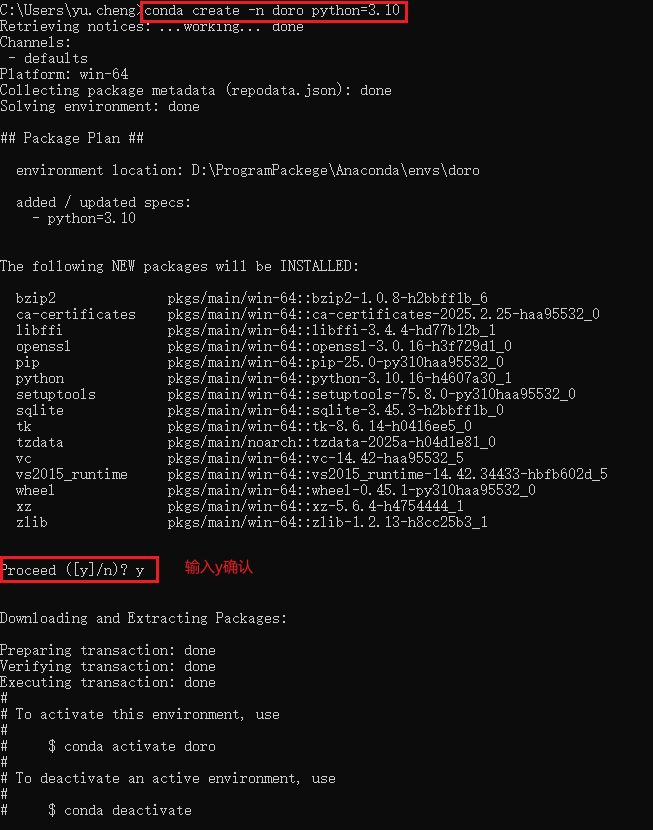
创建完成,在conda根目录的env文件夹下也会生成对应环境名的文件夹
激活环境
conda activate doro
Pytorch环境
这里已经决定使用GPU,需要查看显卡的cuda版本,安装对应支持的cuda版本,再安装对应的Pytorch版本
cuda安装
打开英伟达控制面板,电脑任务栏搜索可以直接搜索NVIDIA Contol Panel打开

找到系统信息
找到cuda版本信息
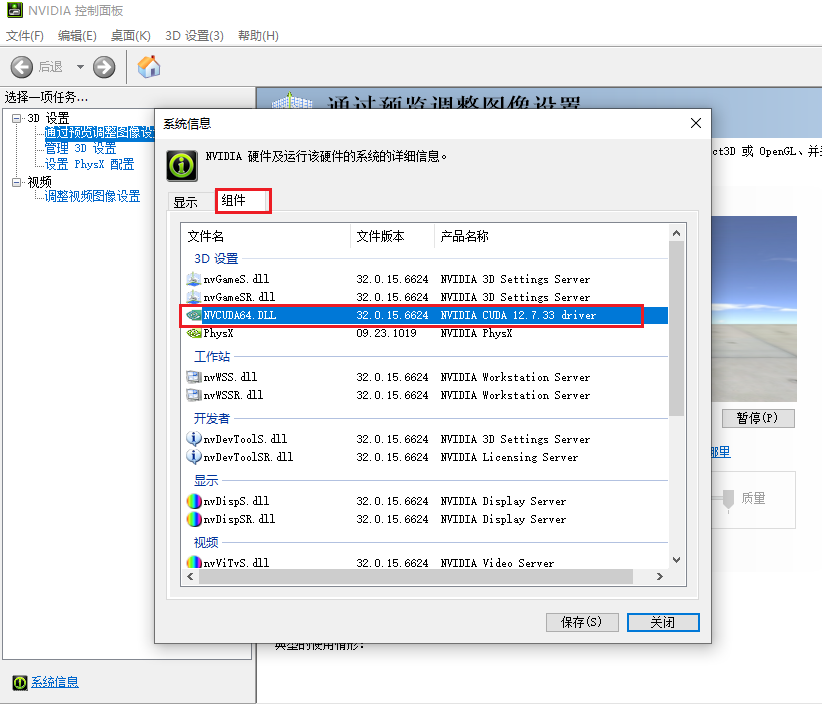
这里我的版本是12.7.33,也就是安装的cuda版本要小于等于12.7.33
打开cuda的下载地址:https://developer.nvidia.com/cuda-toolkit-archive
这里我选择了12.6.0版本
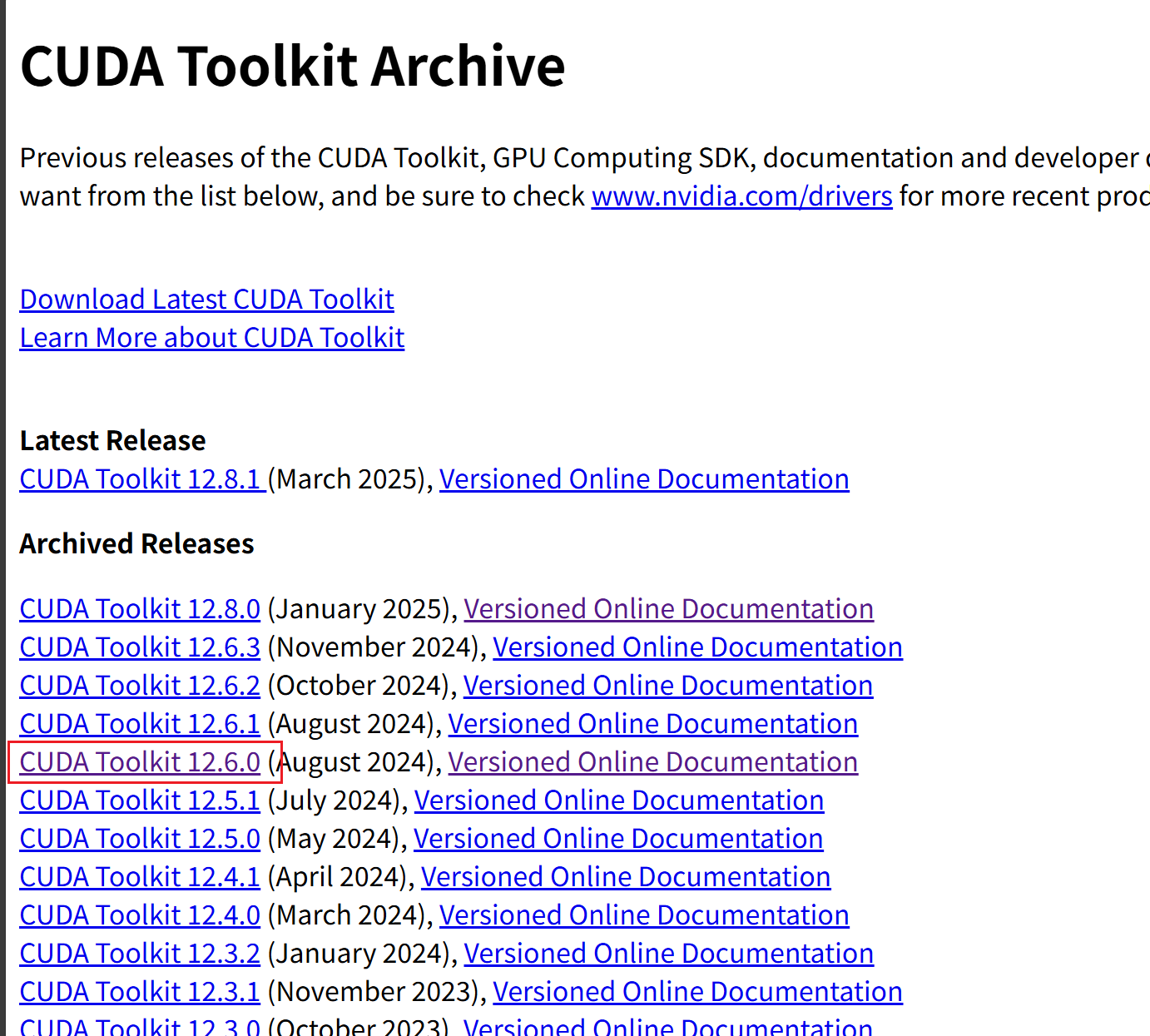
这里选择的网络版下载
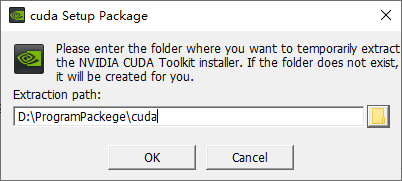
注意可以选择自定义(精简默认安装C盘)
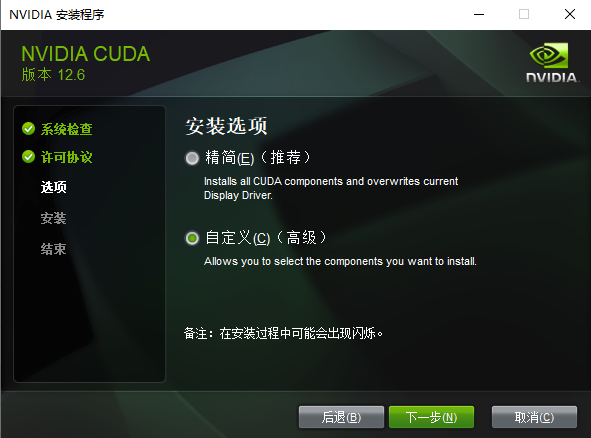
第一次安装尽量全选
等待下载安装
安装完成后,查看环境变量Path,确定安装完成

打开命令行,运行nvcc --version即可查看版本号
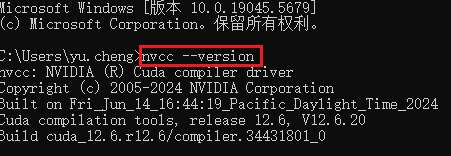
安装成功
cuDNN安装
cuDNN(CUDA Deep Neural Network Library)是 NVIDIA 官方推出的 GPU 加速深度学习库,专为深度神经网络(DNN)计算优化,支持 CNN(卷积神经网络)、RNN(循环神经网络)、Transformer 等模型的训练和推理加速。
cuDNN需要登录英伟达账户才能下载,没有直接注册即可
下载地址:https://developer.nvidia.com/rdp/cudnn-download
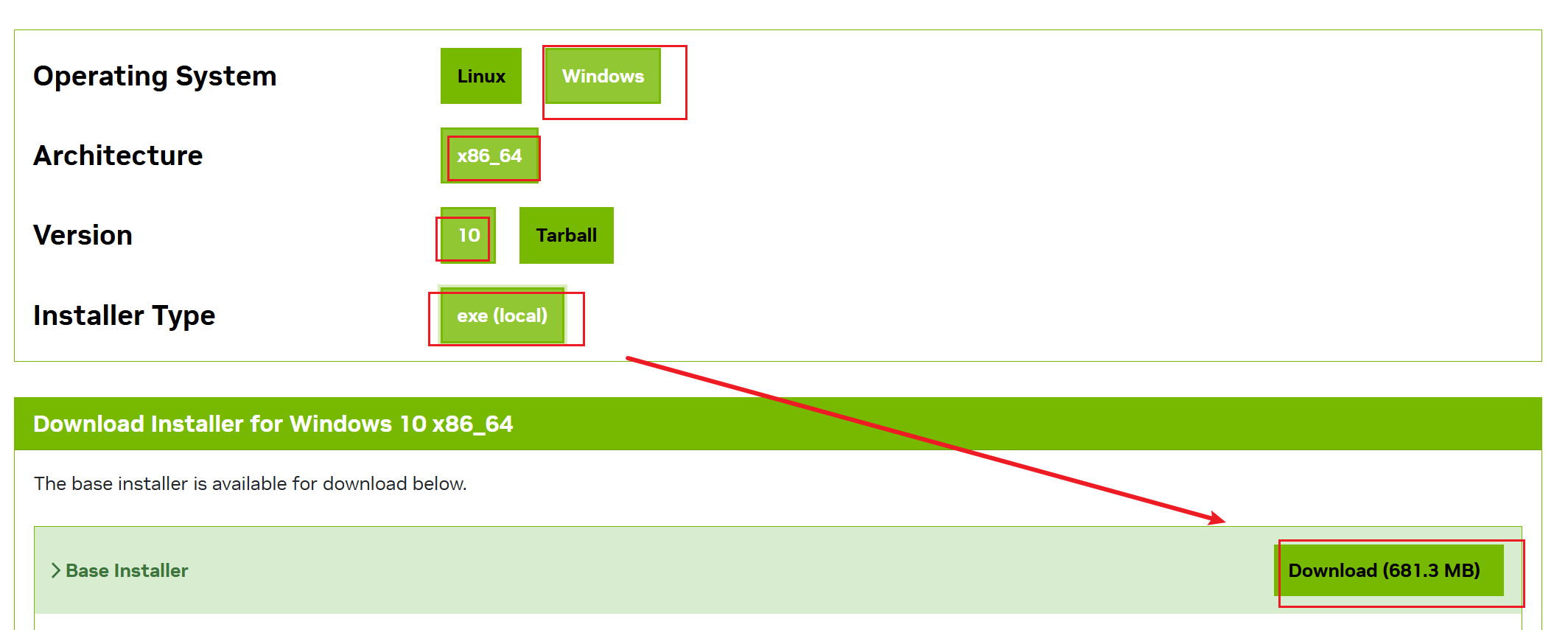
同上选择自定义 全选
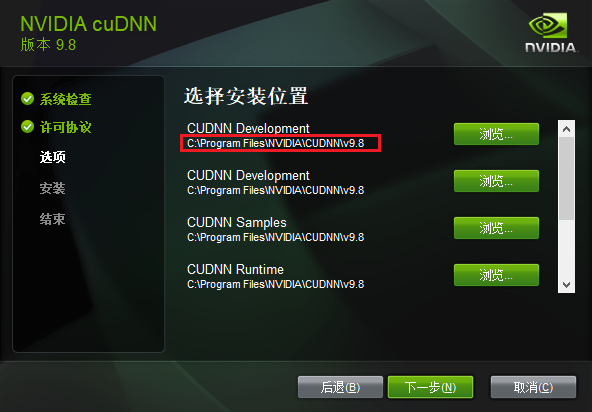
记住安装目录
安装完成后打开对应目录
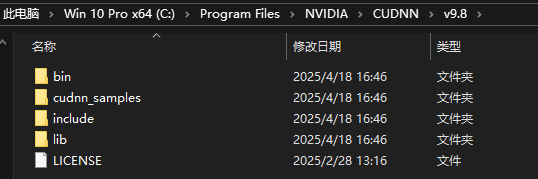
将bin、include、lib文件夹拷贝到cuda的安装目录下
查看环境变量中是否配置了这4项(若没有则补上)
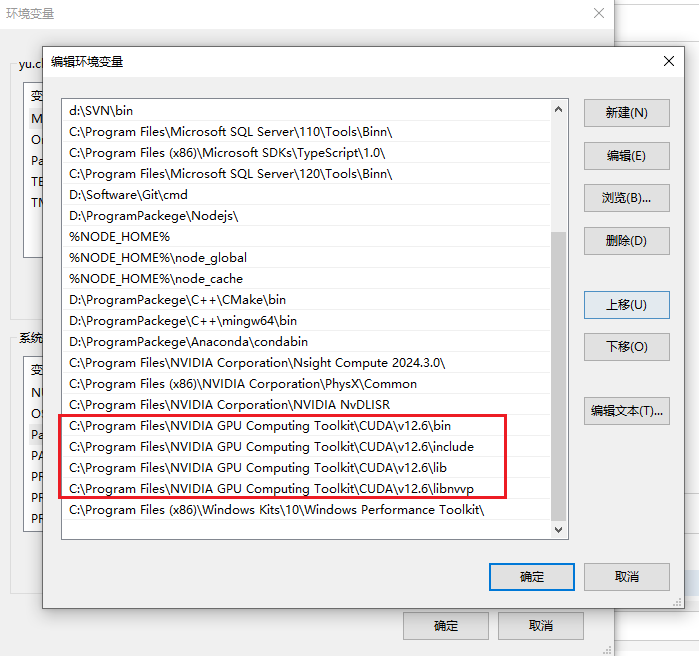
cuDNN安装完成
Pytorch安装
打开Pytorch官网:https://pytorch.org/
往下滑找到下图模块,选择对应的版本(cuda12.6不支持Conda安装 仅能使用pip安装)复制安装命令
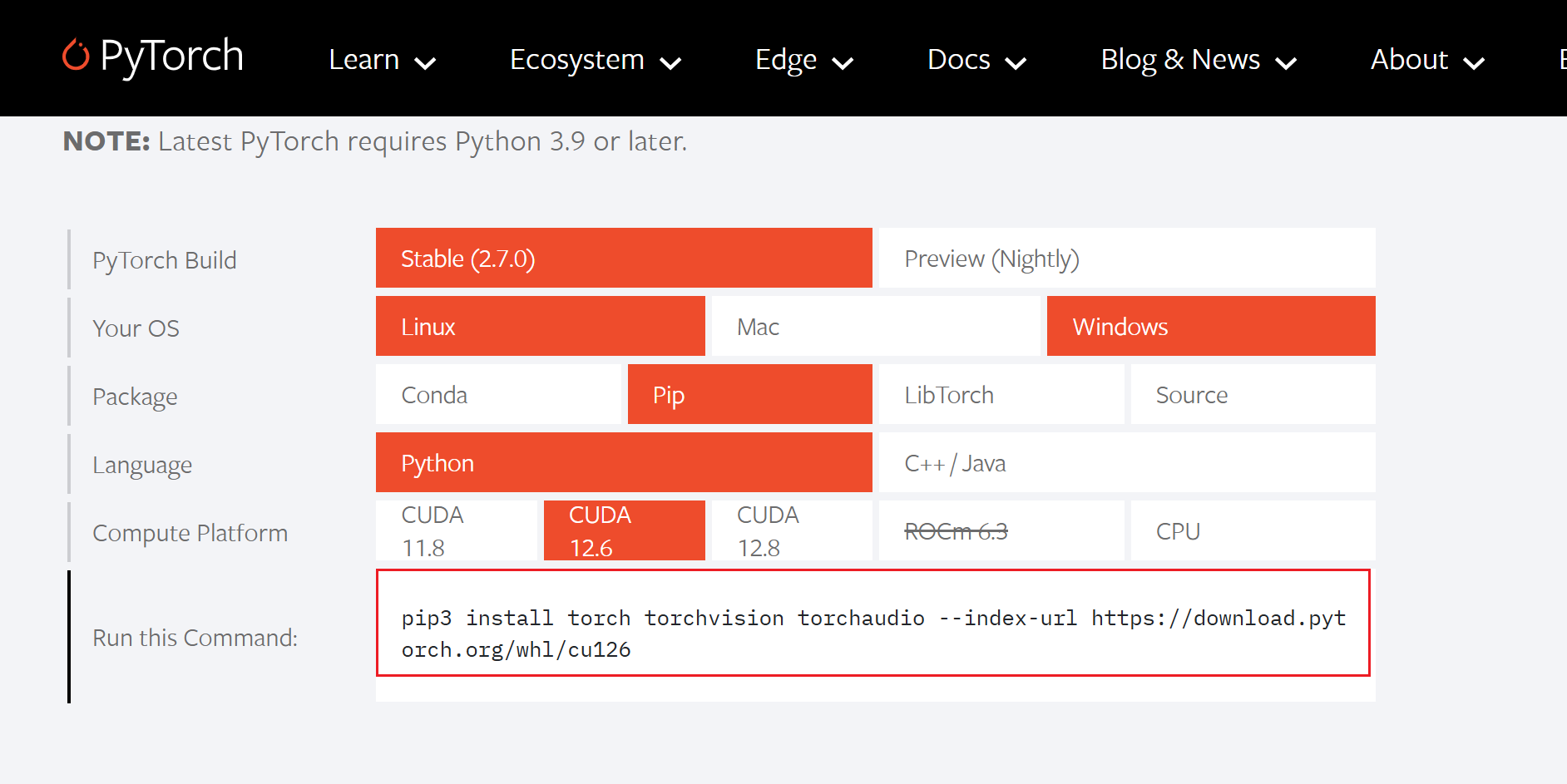
cuda12.6版本的Pytorch,清华镜像源暂时没更新,使用清华镜像会下载cpu版本,所以只能使用源地址下载,大概要下载两个小时
注意要在激活对应的Conda环境下运行命令
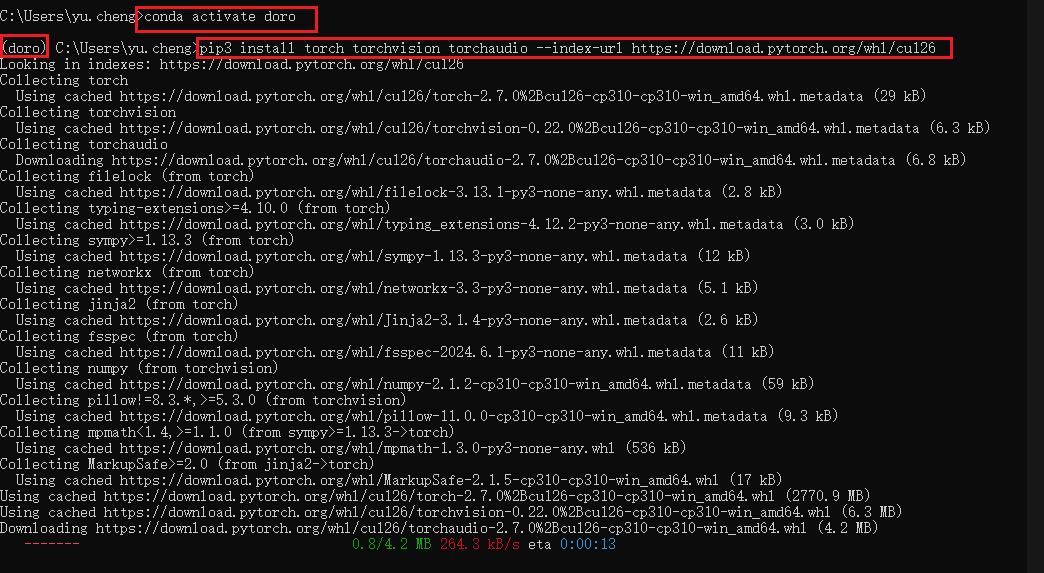
等待下载完成
完成后可以前往Pycharm中验证是否能够调用到GPU
新建项目,选择基础conda(在自定义环境中conda无法选取我们创建的安装Pytorch的虚拟环境)
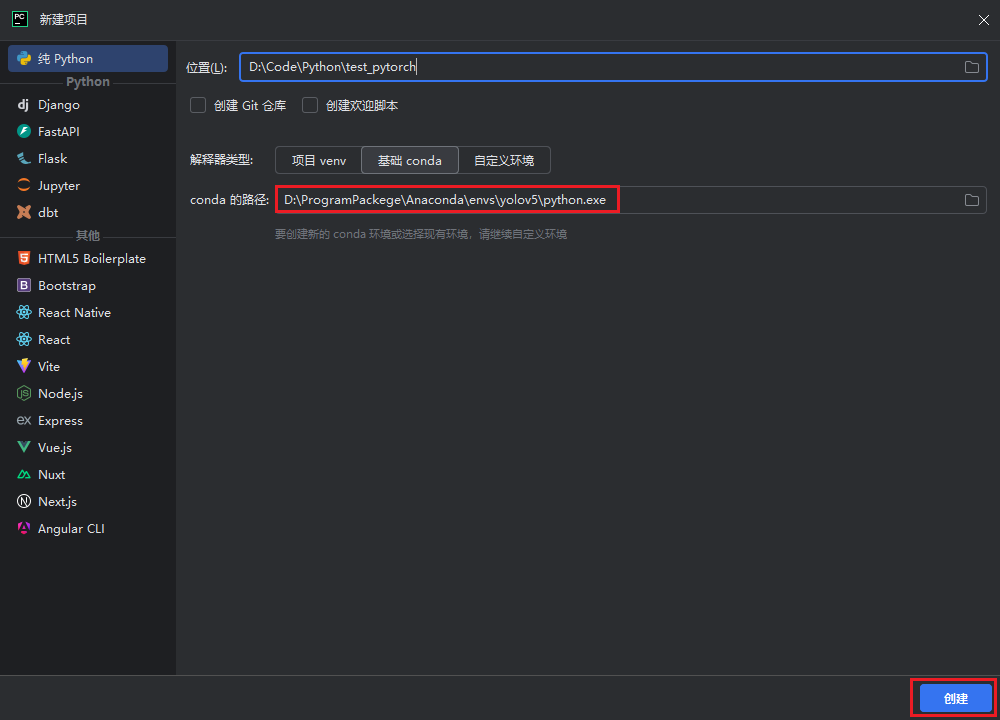
创建后,进入设置-项目-Python解释器,修改环境为安装Pytorch的环境
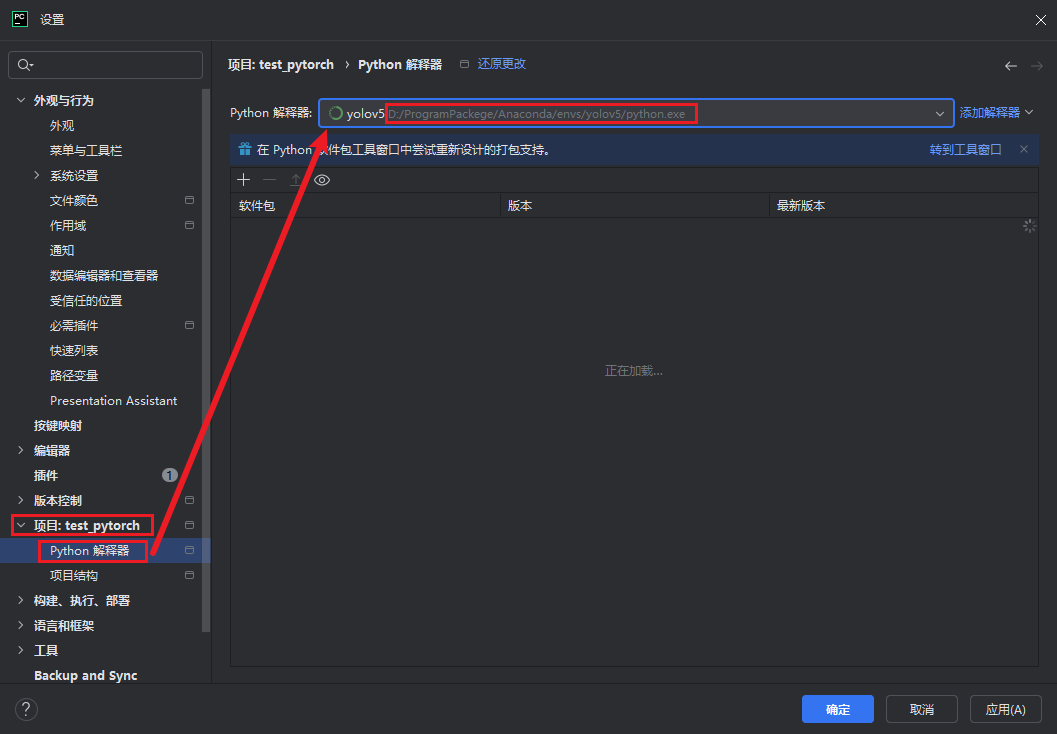
创建程序 验证
代码:
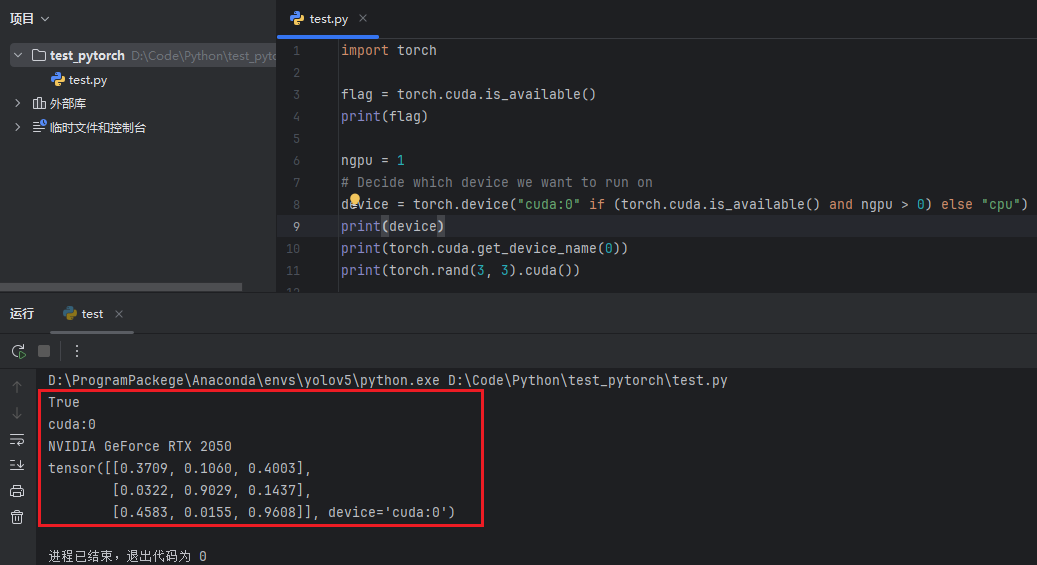
import torch
flag = torch.cuda.is_available()
print(flag)
ngpu = 1
# Decide which device we want to run on
device = torch.device("cuda:0" if (torch.cuda.is_available() and ngpu > 0) else "cpu")
print(device)
print(torch.cuda.get_device_name(0))
print(torch.rand(3, 3).cuda())
成功调用到GPU
至此所有环境配置完成
训练集准备
labelImg图片标注工具安装
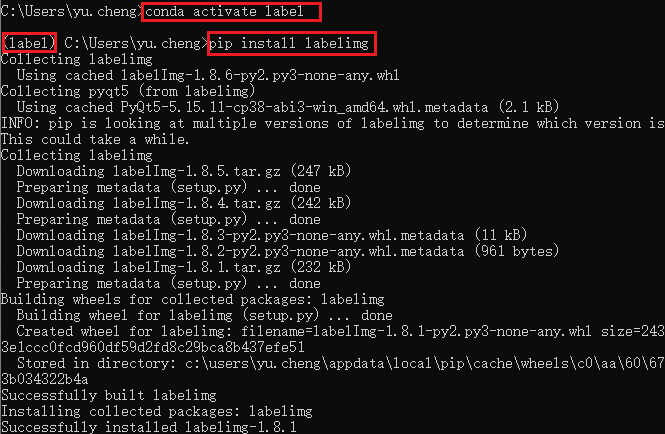
给图片标注构造训练集,用于训练模型,由于在Python3.10环境下,labelImg软件存在闪退问题,这里使用Conda为LabelImg创建一个新的Python3.9环境
conda create -n label python=3.9
注意先激活环境再安装LabelImg
conda activate label
安装LabelImg
conda install pyqt labelimg
找到创建的环境目录,找到Scrip文件夹
打开界面如下
可以参考一下我的设置
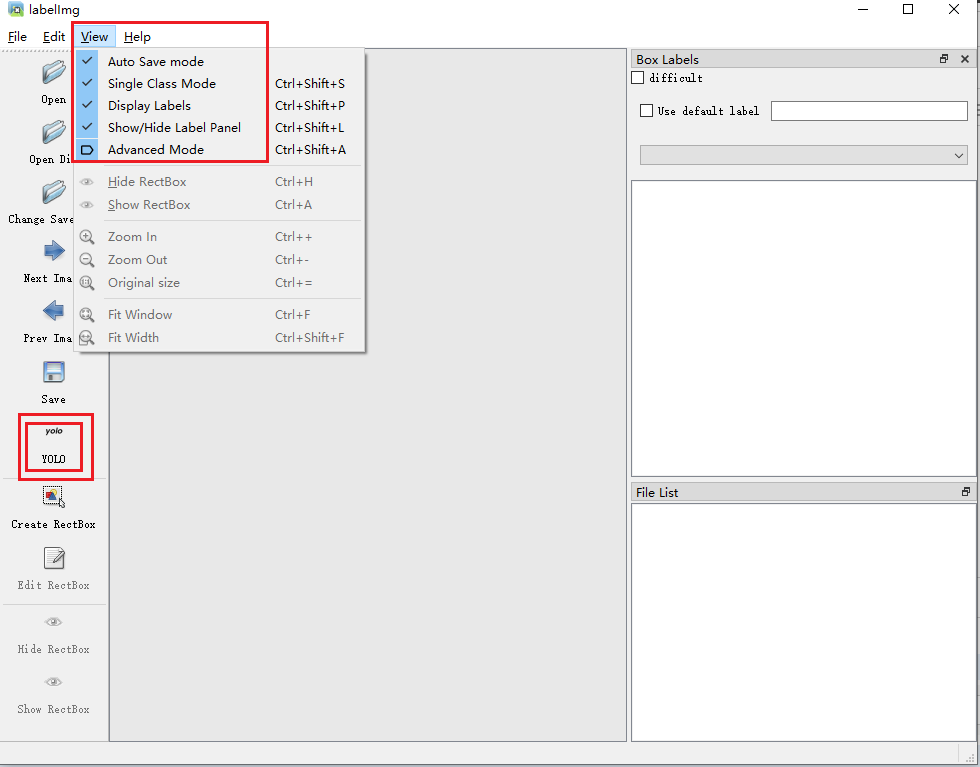
注意:save下方一定要选择yolo模型,否则标注保存的文件是xml文件而非txt文件
标注图片
创建一个单独的文件夹,我这里命名train,再在里面创建两个文件夹(images、labels)以及一个yaml文件(doro.yaml)
yaml文件内容:
# train and val data as 1) directory: path/images/, 2) file: path/images.txt, or 3) list: [path1/images/, path2/images/]
train: ../train/images/
val: ../train/images/
# number of classes
nc: 1
# class names
names: ['doro']
准备好用于训练的图片,我这里是在网上下载的表情包,大概有五十多张,放到刚刚创建的images文件夹中

打开LabelImg,选择打开文件夹
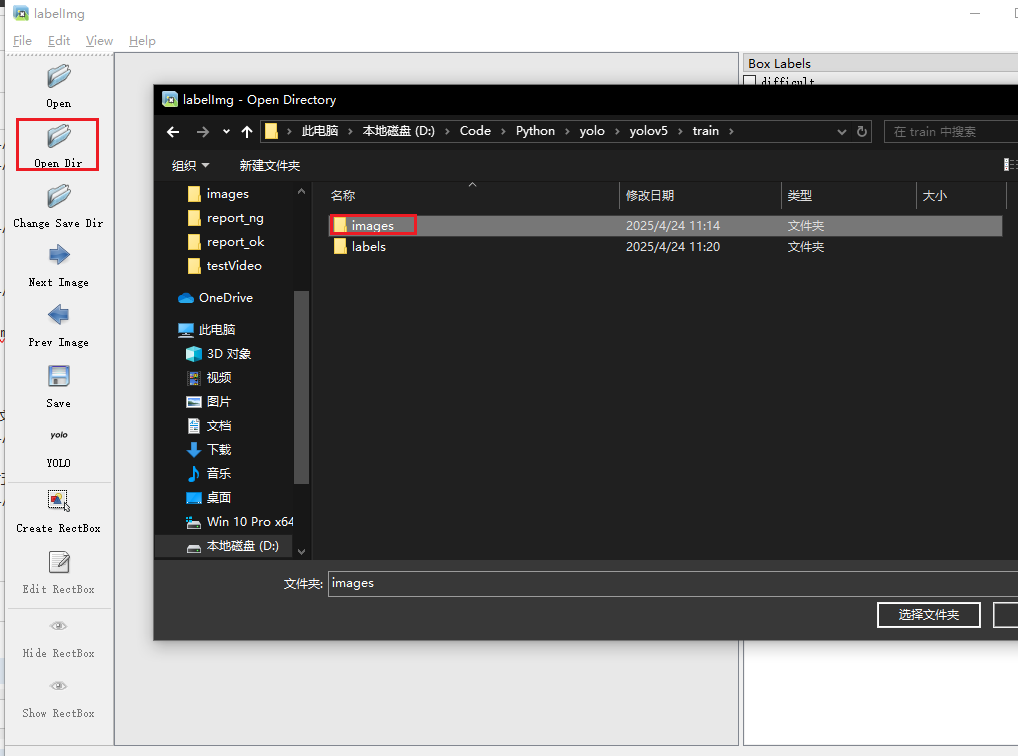
选择保存文件夹位置
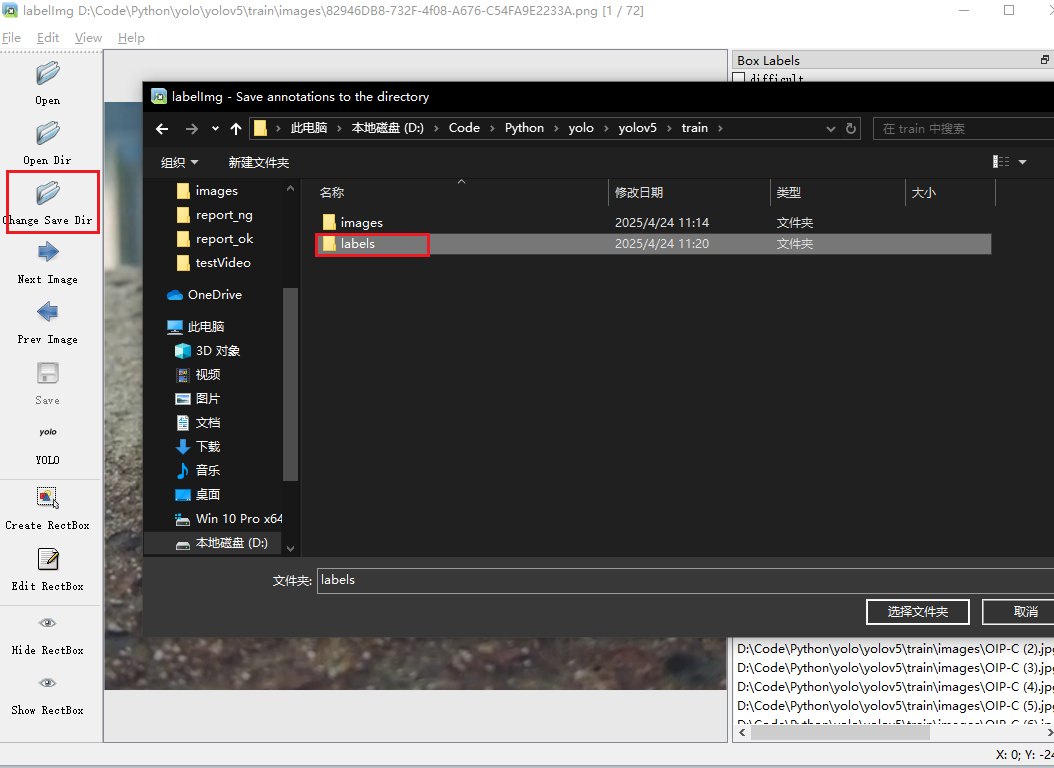
设置一下label名称,就无需手动输入了
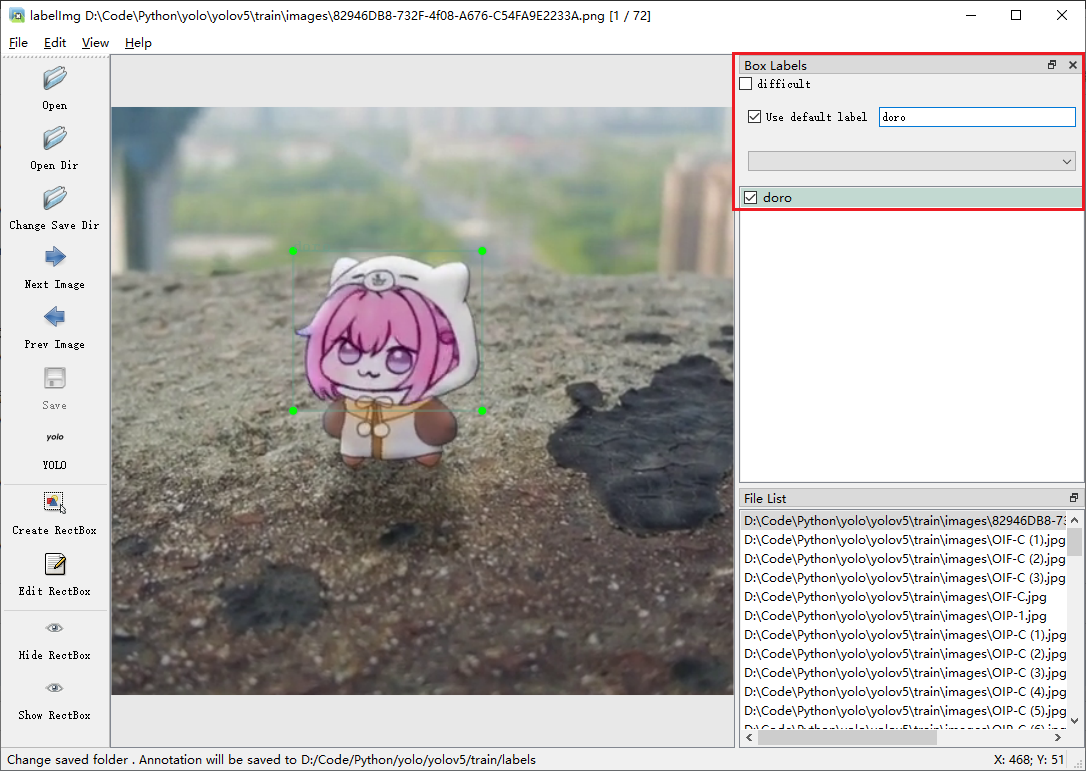
按键w可以快捷创建选框,按键A和D是切换上下张图片
完成后在labels文件夹下就会出现标注的内容
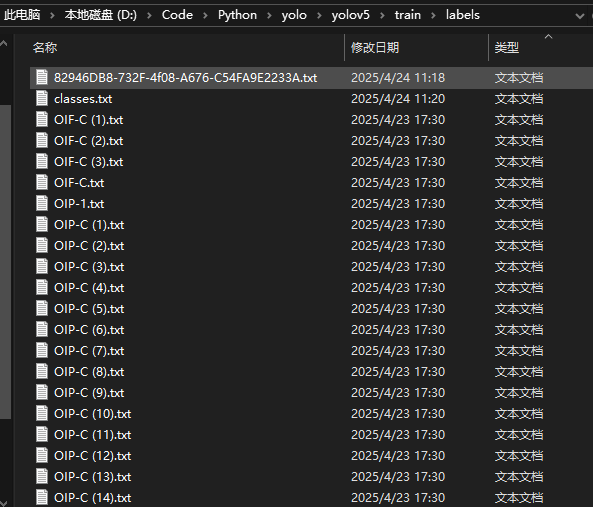
至此训练集准备完成
模型训练
yolov5模型源码部署
Github仓库获取yolov5源码:https://github.com/ultralytics/yolov5
这里我使用的是Pycharm克隆项目
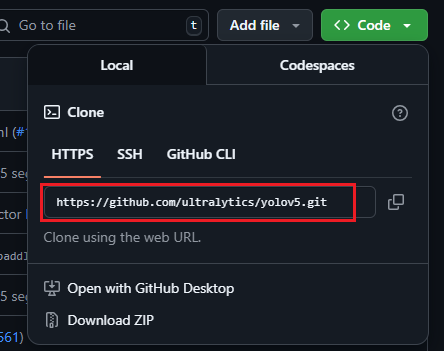
将对应地址填入克隆配置中
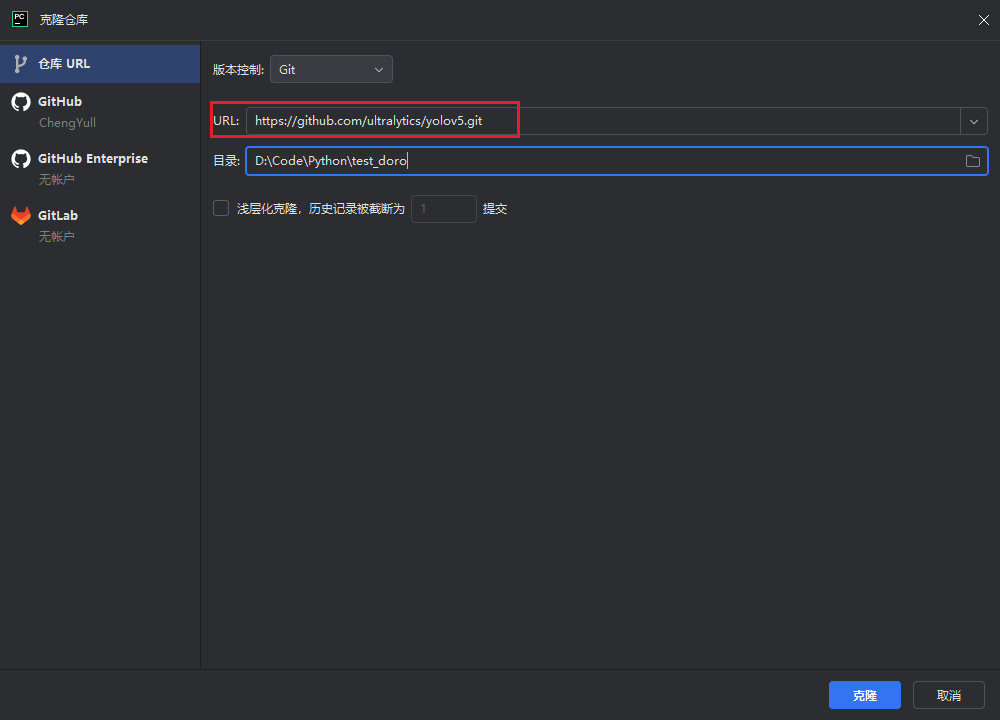
克隆完成如图
同上设置Python解释器
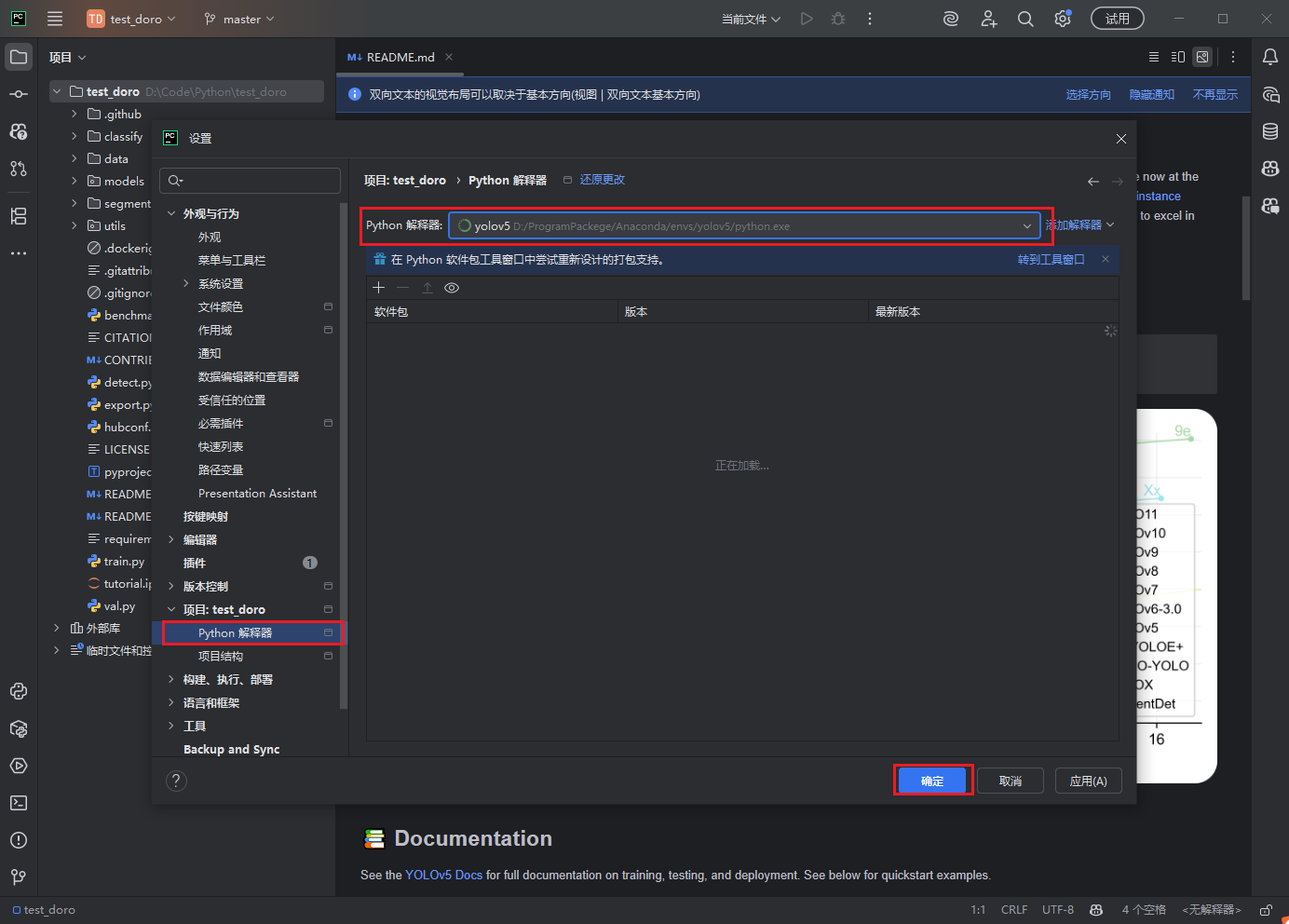
安装依赖
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
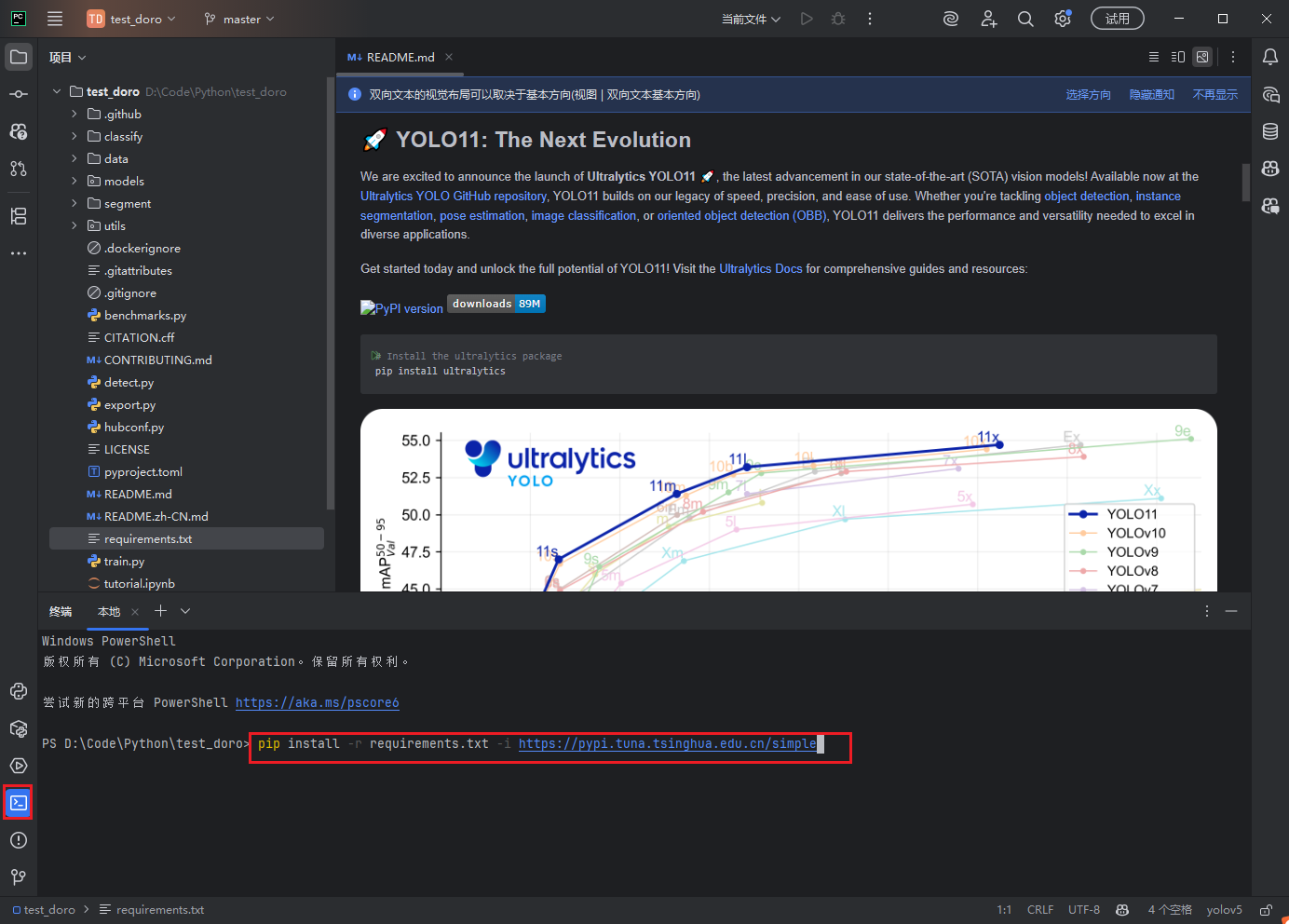
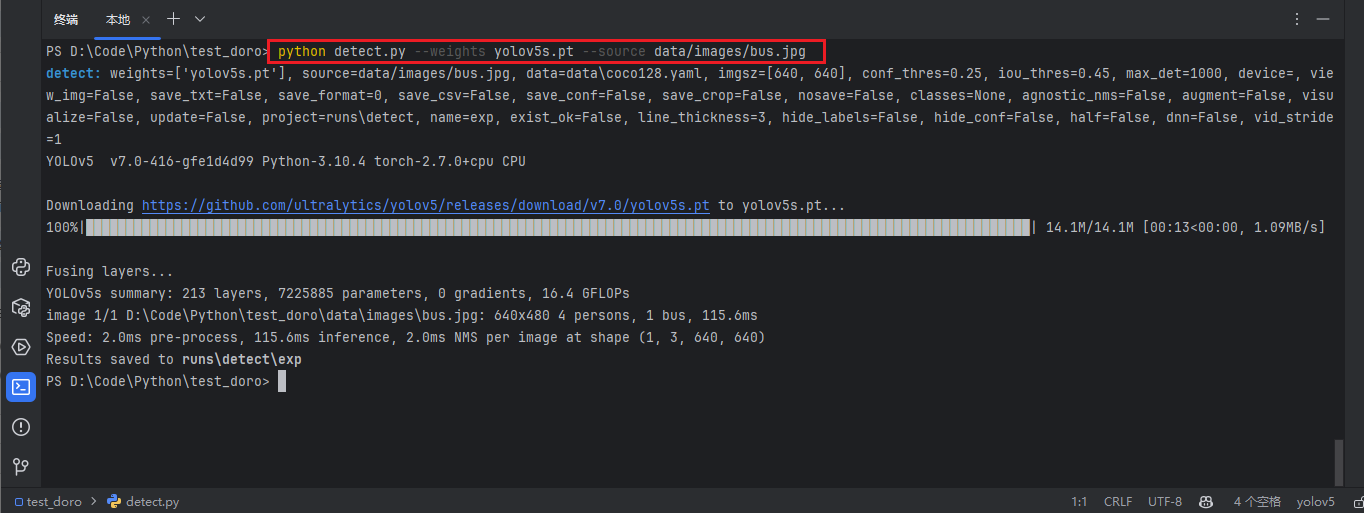
安装完成后测试运行(第一次运行会自动下载yolov5s.pt模型)
python detect.py --weights yolov5s.pt --source data/images/bus.jpg
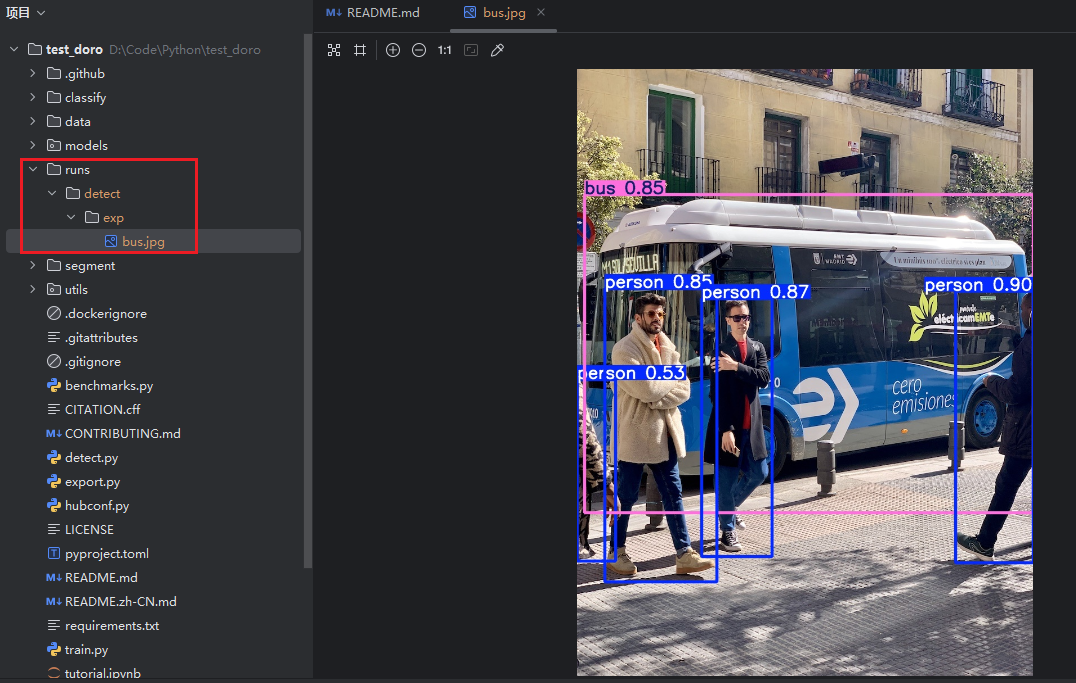
在runs目录如果可以查看到运行结果,说明运行正常
训练
这里为了方便,将之前创建的train文件夹(存放训练集)移动到项目中
在目录中创建src文件夹,用于存放自己的代码
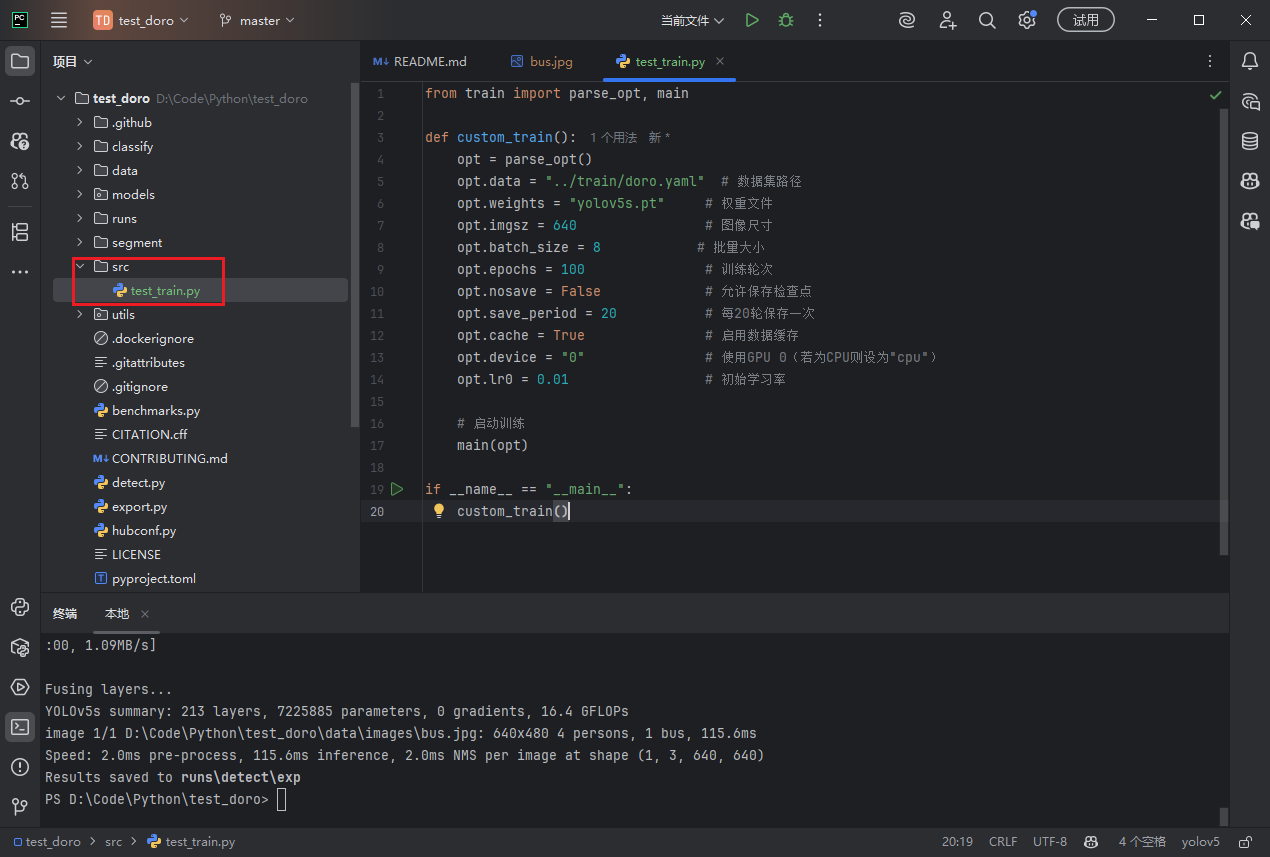
配置训练参数(数据集路径需要改为对应的yaml文件路径)
from train import parse_opt, main
import torch
# 在训练前清理GPU缓存
torch.cuda.empty_cache()
def custom_train():
opt = parse_opt()
opt.data = "../train/doro.yaml" # 数据集路径
opt.weights = "../yolov5s.pt" # 权重文件
opt.imgsz = 640 # 图像尺寸
opt.batch_size = 8 # 批量大小
opt.epochs = 100 # 训练轮次
opt.nosave = False # 允许保存检查点
opt.save_period = 20 # 每20轮保存一次
opt.cache = True # 启用数据缓存
opt.device = "0" # 使用GPU 0(若为CPU则设为"cpu")
opt.lr0 = 0.01 # 初始学习率
# 启动训练
main(opt)
if __name__ == "__main__":
custom_train()
其中图像尺寸imgsz和批量大小batch_size要根据显存配置,如果训练过程中出现torch.OutOfMemoryError: CUDA out of memory,试着将其适当调小

如果多次修改无果,可以试着重启电脑(亲测有效)
训练正式开始,等待100轮的训练
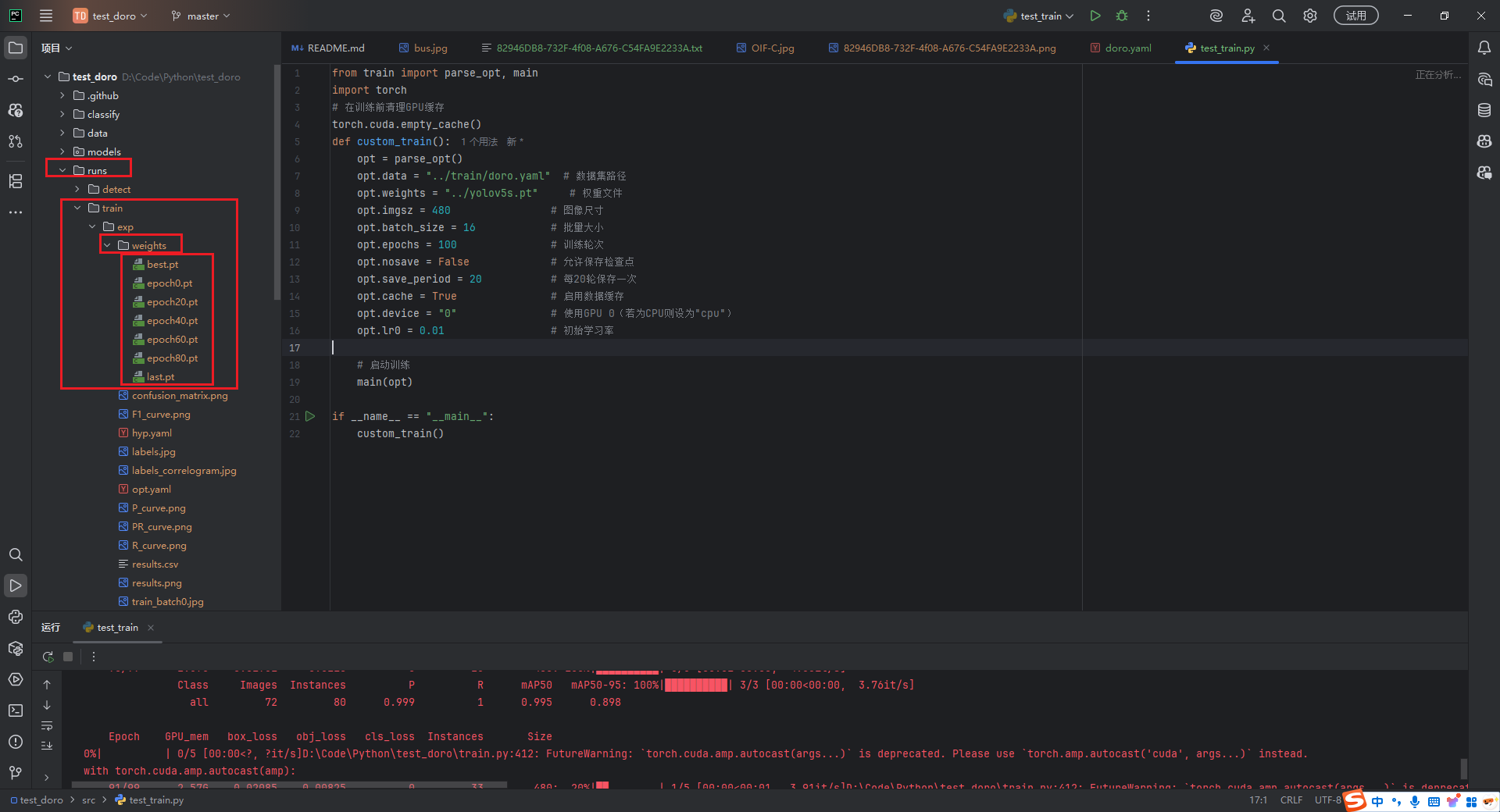
训练完成后,在runs文件夹下可以找到训练好的模型文件(如果不想保存中间生成的模型文件,可以在训练参数将opt.nosave = True改为True,删掉opt.save_period = 20配置)
测试模型
这里使用openCV来读取视频来识别作为测试
import cv2
import torch
# 读取视频
video_path = "../testVideo/doro3.mp4"
cap = cv2.VideoCapture(video_path)
# 加载训练的模型
model = torch.hub.load('../../test_doro', 'custom', path='../runs/train/exp/weights/best.pt', source='local')
# 检查视频是否成功打开
if not cap.isOpened():
print("无法打开视频文件")
exit()
# 播放视频
while True:
ret, frame = cap.read()
if not ret:
break
# 模型推理
results = model(frame)
# 获取预测结果
for pred in results.pred[0]:
x1, y1, x2, y2, conf, cls = pred.tolist()
class_name = model.names[int(cls)]
# 输出结果
print(f"检测到:{class_name}, 置信度:{conf:.2f}")
cv2.rectangle(frame, (int(x1), int(y1)), (int(x2), int(y2)), (0, 255, 0), 2)
cv2.putText(frame, f"{class_name} {conf:.2f}", (int(x1), int(y1) - 10),
cv2.FONT_HERSHEY_SIMPLEX, 0.9, (0, 255, 0), 2)
# 显示当前帧
cv2.imshow("Video", frame)
# 按下 'q' 键退出
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# 释放视频捕获对象和关闭所有窗口
cap.release()
cv2.destroyAllWindows()
这里发现能够成功识别,且效果还行,但是发现控制台有一行警告信息,非常影响观感
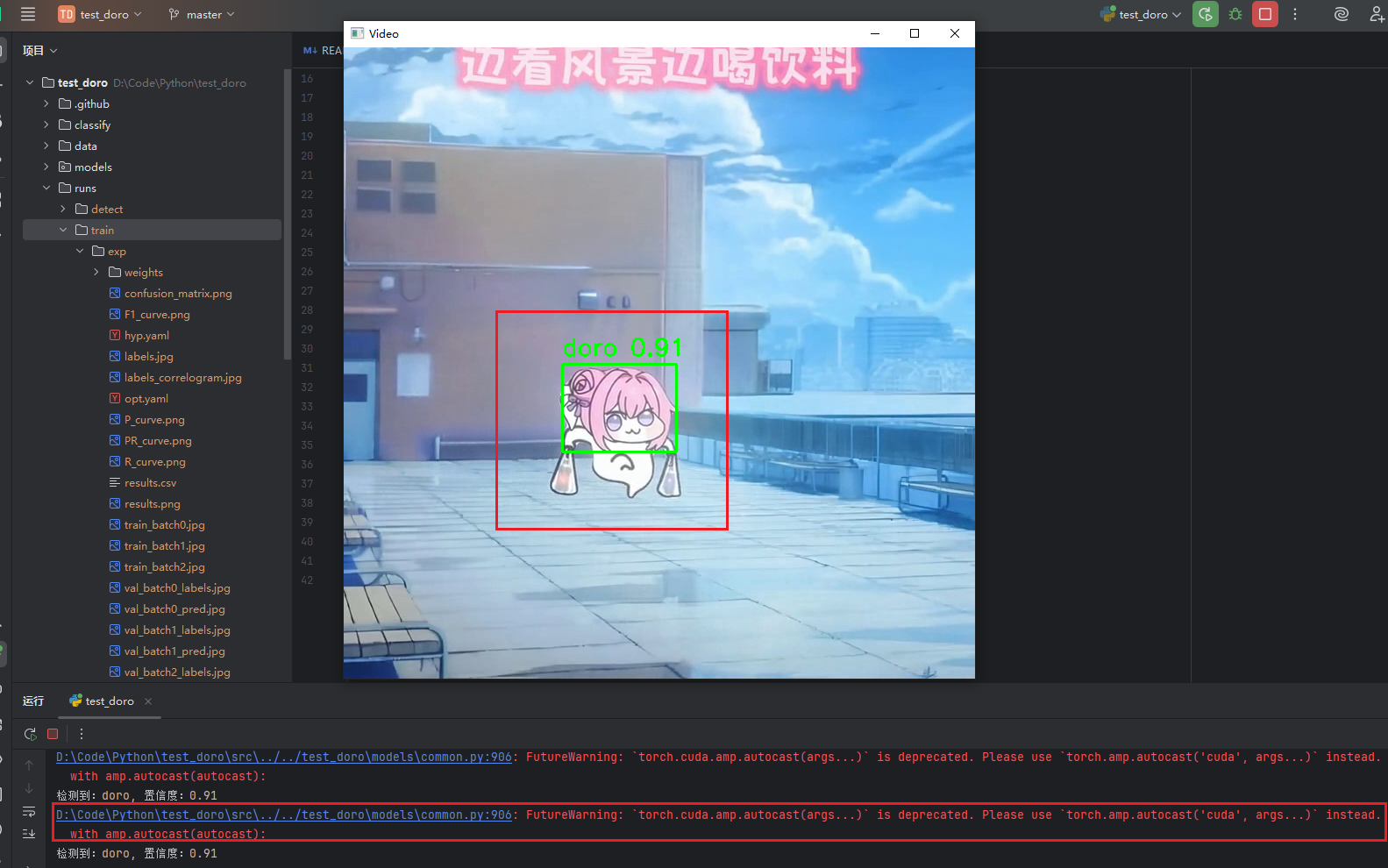
根据提示,找到models目录下的common.py文件,搜索 with amp.autocast(autocast):
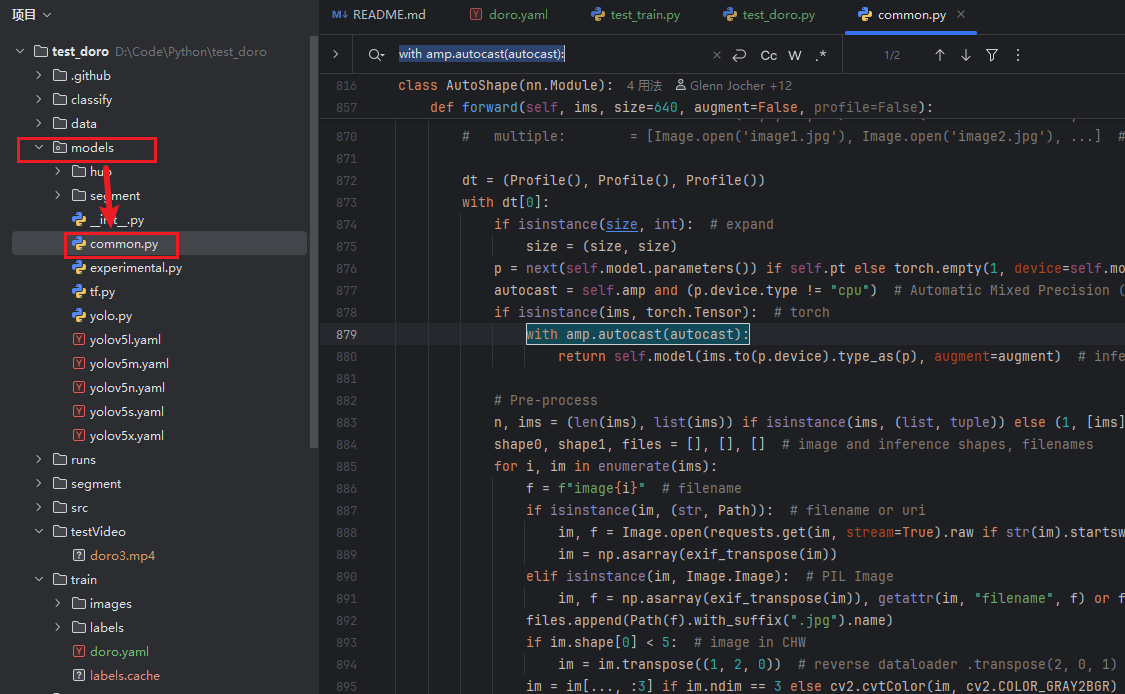
将其替换为:
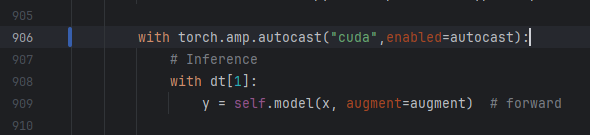
with torch.amp.autocast("cuda",enabled=autocast):
这里有两处:分别在879行和906行

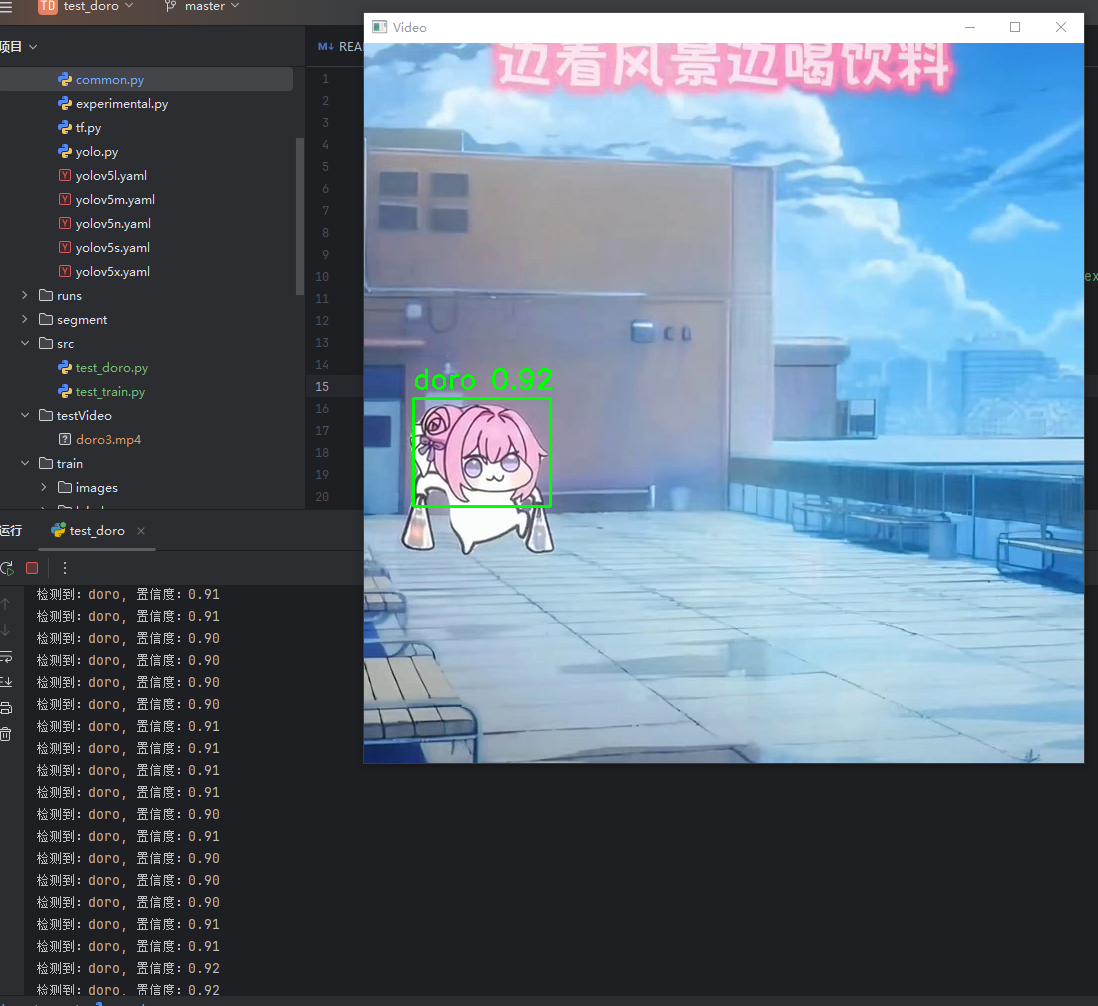
再次运行测试代码,警告消失
从零开始:基于CUDA 12.6的YOLOv5模型训练实战(RTX 2050显卡全流程)的更多相关文章
- MindStudio模型训练场景精度比对全流程和结果分析
摘要:MindStudio是一套基于华为昇腾AI处理器开发的AI全栈开发平台 本文分享自华为云社区<MindStudio模型训练场景精度比对全流程和结果分析>,作者:yd_24730208 ...
- YOLOv5模型训练及检测
一.为什么使用YOLOv5 二.软件工具 2.1 Anaconda https://www.anaconda.com/products/individual 2.2 PyCharm https://w ...
- 基于CUDA的粒子系统的实现
基于CUDA的粒子系统的实现 用途: 这篇文章作为代码实现的先导手册,以全局的方式概览一下粒子系统的实现大纲. 科普: 对粒子进行模拟有两种基本方法: Eulerian(grid-based) met ...
- 基于R语言的时间序列指数模型
时间序列: (或称动态数列)是指将同一统计指标的数值按其发生的时间先后顺序排列而成的数列.时间序列分析的主要目的是根据已有的历史数据对未来进行预测.(百度百科) 主要考虑的因素: 1.长期趋势(Lon ...
- 基于Python的信用评分卡模型分析(一)
信用风险计量体系包括主体评级模型和债项评级两部分.主体评级和债项评级均有一系列评级模型组成,其中主体评级模型可用“四张卡”来表示,分别是A卡.B卡.C卡和F卡:债项评级模型通常按照主体的融资用途,分为 ...
- kaldi基于GMM的单音素模型 训练部分
目录 1. gmm-init-mono 模型初始化 2. compile-train-graghs 训练图初始化 3. align-equal-compiled 特征文件均匀分割 4. gmm-acc ...
- 基于.net的分布式系统限流组件 C# DataGridView绑定List对象时,利用BindingList来实现增删查改 .net中ThreadPool与Task的认识总结 C# 排序技术研究与对比 基于.net的通用内存缓存模型组件 Scala学习笔记:重要语法特性
基于.net的分布式系统限流组件 在互联网应用中,流量洪峰是常有的事情.在应对流量洪峰时,通用的处理模式一般有排队.限流,这样可以非常直接有效的保护系统,防止系统被打爆.另外,通过限流技术手段,可 ...
- PyTorch ImageNet 基于预训练六大常用图片分类模型的实战
微调 Torchvision 模型 在本教程中,我们将深入探讨如何对 torchvision 模型进行微调和特征提取,所有这些模型都已经预先在1000类的Imagenet数据集上训练完成.本教程将深入 ...
- ML.NET 示例:图像分类模型训练-首选API(基于原生TensorFlow迁移学习)
ML.NET 版本 API 类型 状态 应用程序类型 数据类型 场景 机器学习任务 算法 Microsoft.ML 1.5.0 动态API 最新 控制台应用程序和Web应用程序 图片文件 图像分类 基 ...
- 零样本文本分类应用:基于UTC的医疗意图多分类,打通数据标注-模型训练-模型调优-预测部署全流程。
零样本文本分类应用:基于UTC的医疗意图多分类,打通数据标注-模型训练-模型调优-预测部署全流程. 1.通用文本分类技术UTC介绍 本项目提供基于通用文本分类 UTC(Universal Text C ...
随机推荐
- 文本处理命令head tail more less tr cut paste wc
文本处理命令 命令**head tail more less tr cut paste wc** 磁盘分区利用率 df|tr -s ' ' :|cut -d : -f5 df|tr -s ' ' :| ...
- 性能测试-Oceanus 测试FLink mysql到Iceberg性能
一.任务依赖信息 1.mysql测试库信息 地址:127.0.0.1.gomysql_bdg_test 库:bdg_test 表:order_info1 2.iceberg库 hive地址:thrif ...
- mac安装python包
一.常用包安装记录1.分析exl用的pandas pip install xlrd==1.2.0 pip3 install pandas
- mybatis之配置优化
属性优化 properties 外部配置文件[db.properties] driver=com.mysql.jdbc.Driver url=jdbc:mysql://localhost:3306/m ...
- kubsphere应用系列(三)-创建手动流水线
准备工作 1.1 创建凭证 1.2 添加代码仓库 第一步创建流水线 第二步配置流水线 1.1选择CI/CD模板 1.2删除多余阶段 1.3 配置git仓库信息 1.4配置docker仓库信 ...
- AD 测试点覆盖率的统计
在用Altium Designer软件设计PCB时,有时会有统计这个工程的测试点覆盖率需求.在AD 中有2种类型的测试点:Fabrication testppoint(用于PCB的下线电气测试)和As ...
- 【软件开发】Git 概念与常用命令
[软件开发]Git 概念与常用命令 Git 概念 存储方式 Git 是分布式存储,每一个 clone 下来的仓库都可以看成独立的个体,只是 Git 有提供同步功能,因此 Git 支持离线使用,因为本质 ...
- JUC并发—12.ThreadLocal源码分析
大纲 1.ThreadLocal的特点介绍 2.ThreadLocal的使用案例 3.ThreadLocal的内部结构 4.ThreadLocal的核心方法源码 5.ThreadLocalMap的核心 ...
- Typecho实现版权声明的三种方式
在安装完Typecho之后,第一件事应该就是想着如何去折腾了.对于个人博客而言,不希望自己辛辛苦苦写的文章,被别人转载或无脑采集,还不留原地址,所以就需要在文章的末尾地方放上一个版权声明,来提醒下转载 ...
- 有关C++程序设计基础的各种考题解答参考汇总
早先年考研的主考科目正是[算法与数据结构],复习得还算可以.也在当时[百度知道]上回答了许多相关问题,现把他们一起汇总整理一下,供读者参考. [1] 原题目地址:https://zhidao.baid ...