生鲜超市源码+springboot3+vue3+JDK17(带用户协同过滤个性化推荐算法)
今天教大家如何设计一个 生鲜超市源码 , 基于目前最新的技术:前端vue3,后端springboot3。
学习完这个项目,你将来找工作开发实际项目都会又很大帮助。我们出去找工作时,也可以用这个作为实际项目案例。文章最后部分还带来的项目的部署教程。
系统含有现代化商城的设计思想,有着在线客服聊天系统, 基于用户的协同过滤推荐算法,保证库存不超卖的机制,还有运费管理, 订单管理,购物车等子模块系统的设计,基本上符合将来工作上的实际项目。
视频演示
https://githubs.xyz/show/6ccb20eb-620d-46a3-ad0b-359275212407.mp4
图片演示
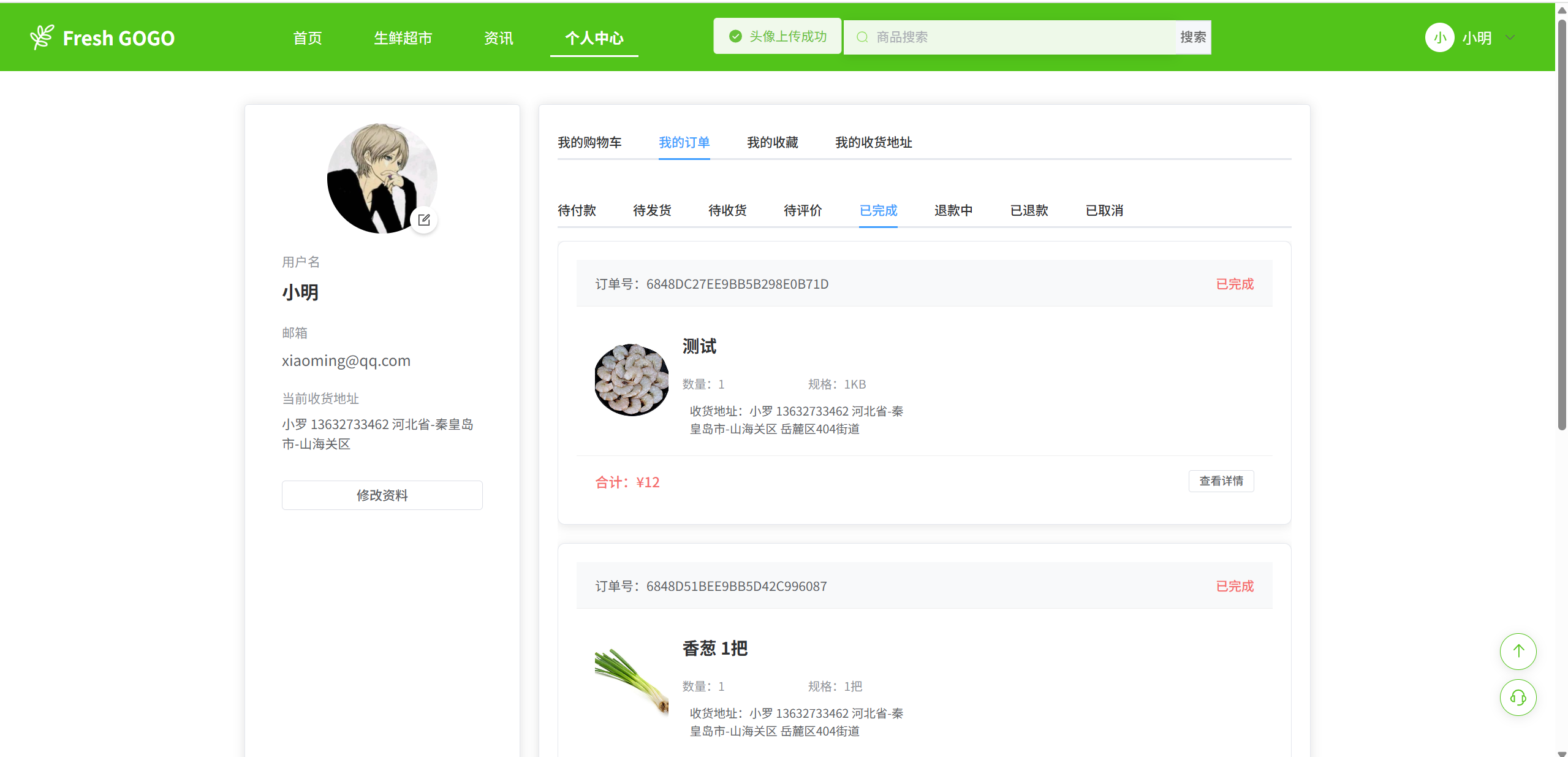
系统功能概述
SQL文件与全部源码我已整理清楚,移步获取:
gitcode( 巅 ) C 〇 M/hadluo2/shop.git
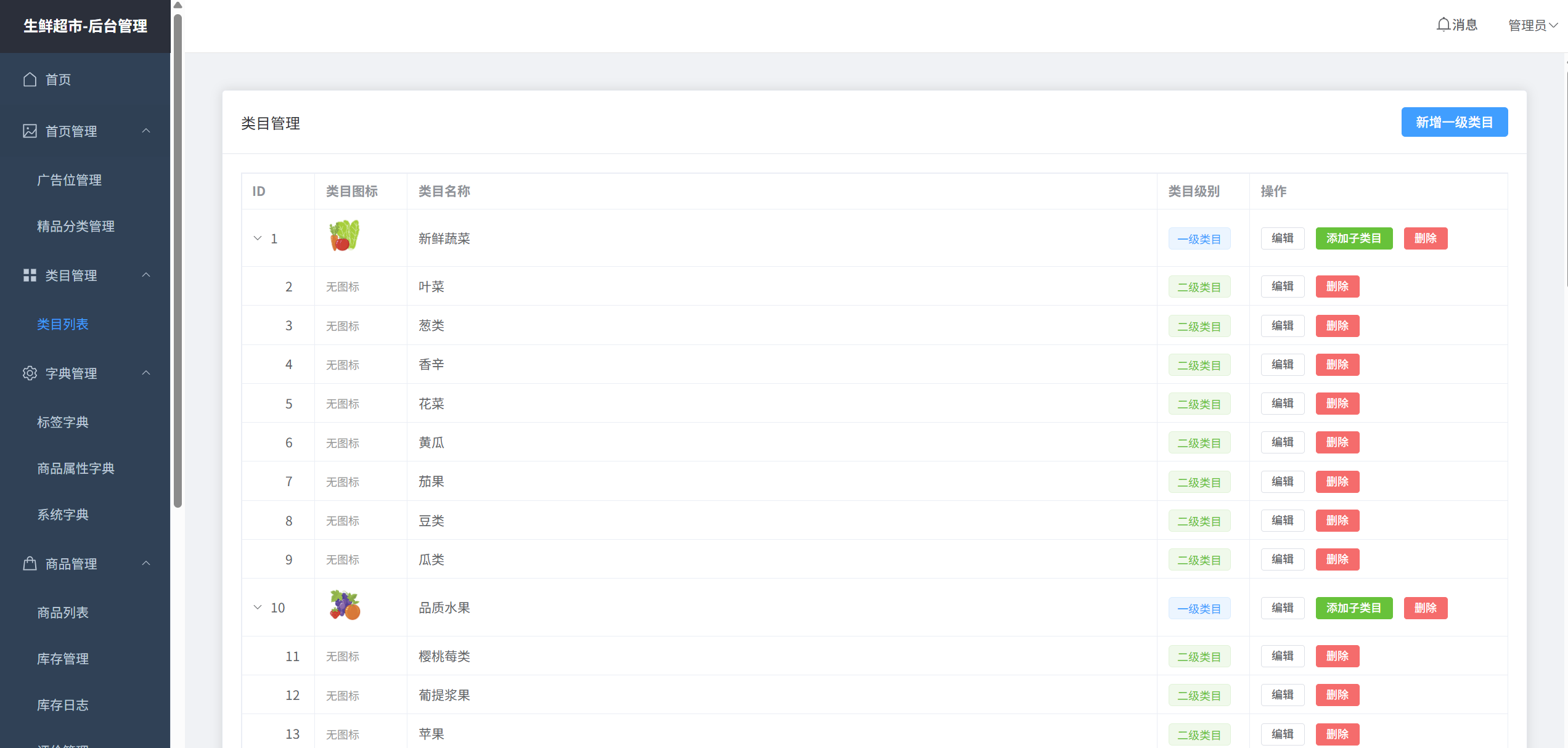
分类管理
系统的分类支持一级类目,二级类目。目前的类目结果如下图:
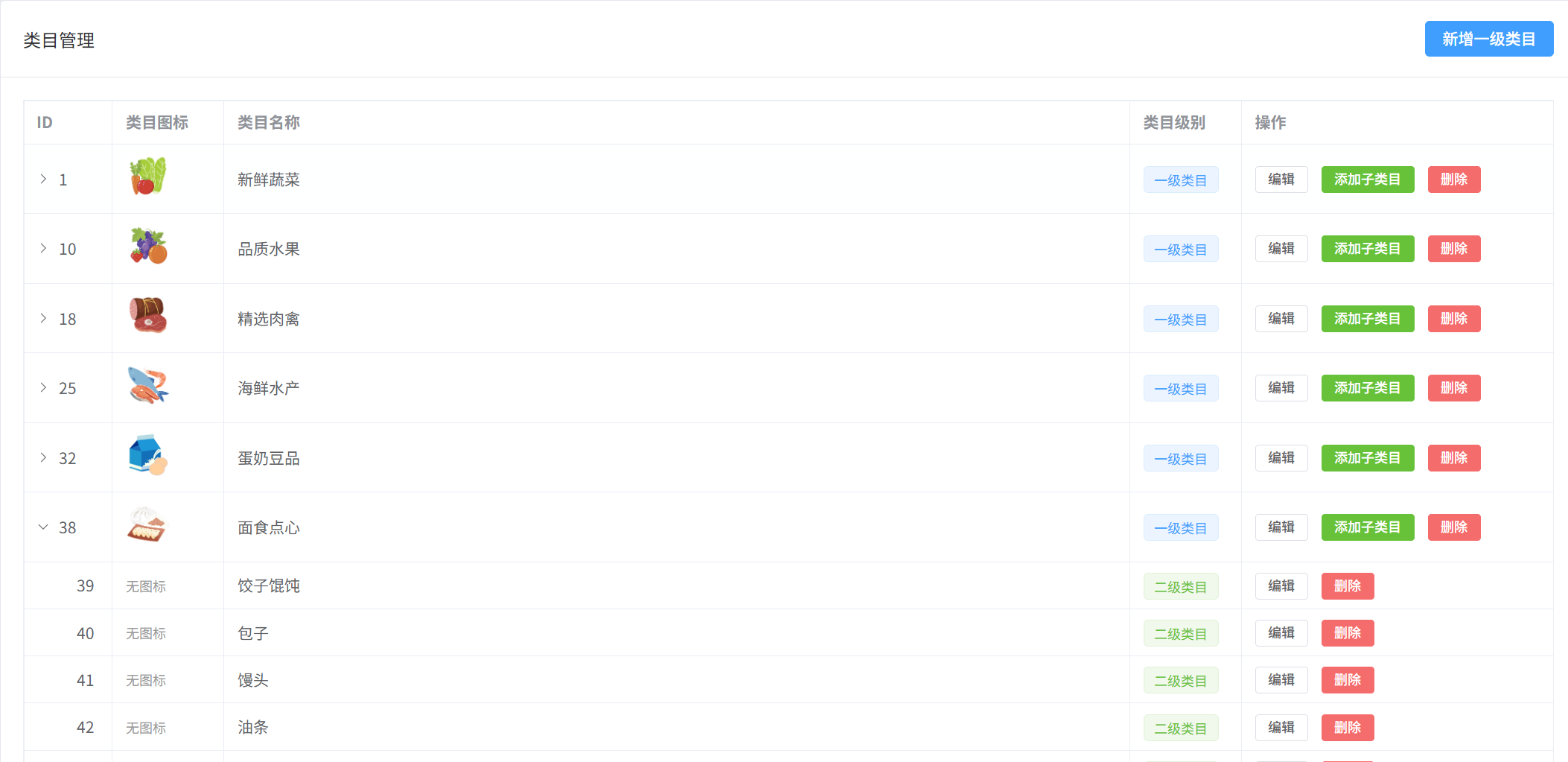
在后端管理你可以随意的对类目进行编辑删除,一级类目需要一个小图标, 二级类目是不用的。
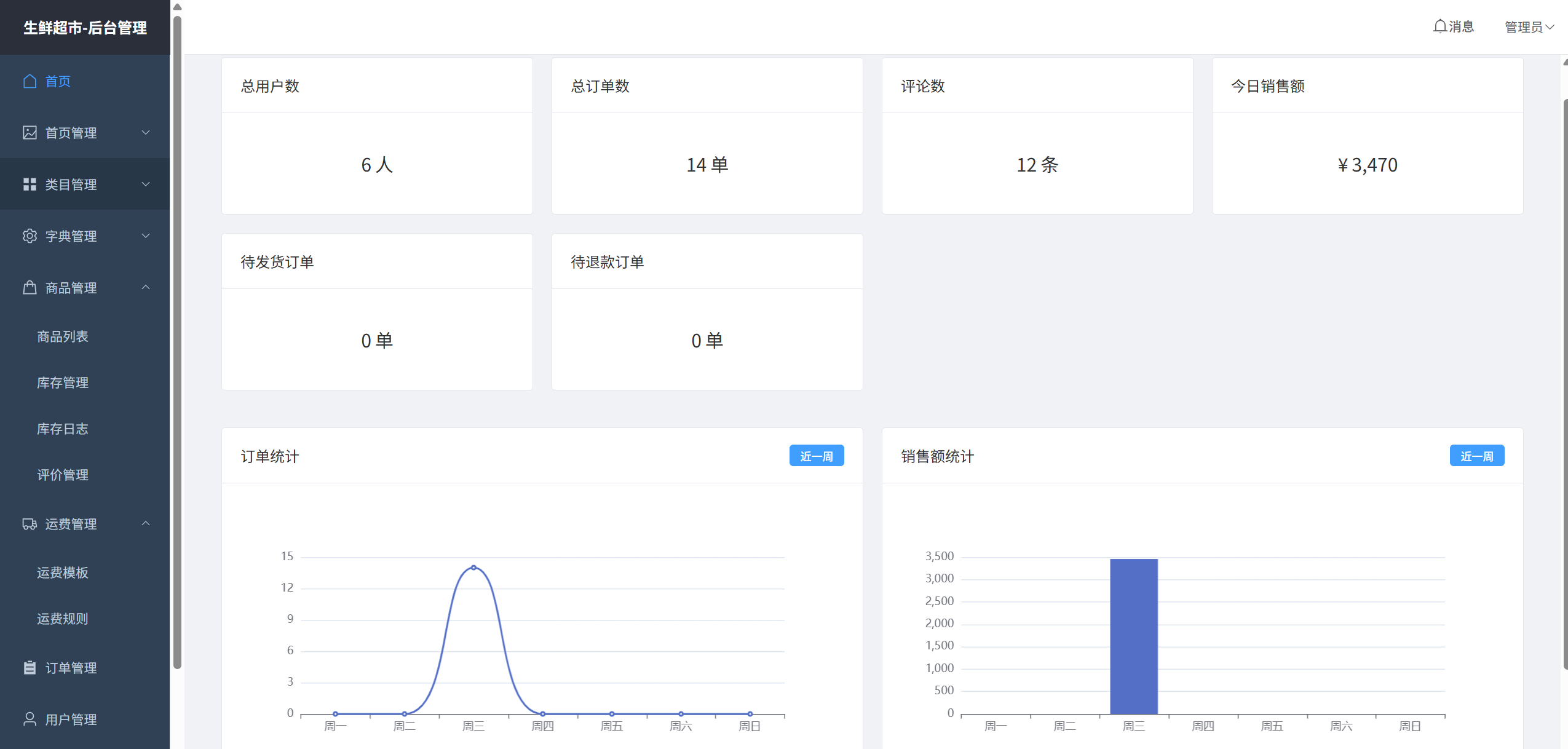
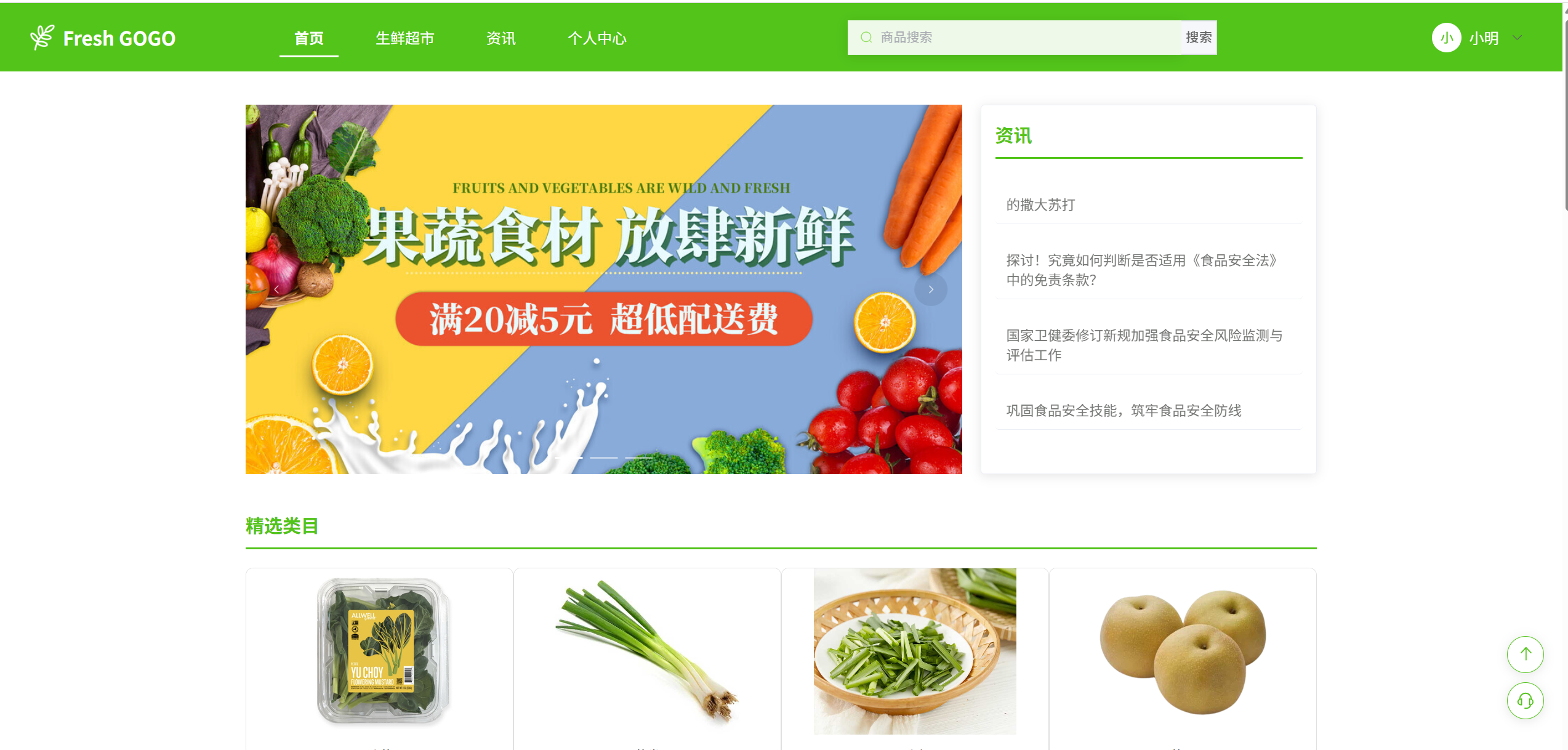
首页管理
首页有 “轮播图,资讯,精选类目,精品推荐,新品上架” 几大模块。
轮播图: 在后台的轮播图管理,能够对前端首页的轮播广告进行管理, 支持点击跳转到外部链接。
资讯: 查询最近10条食品资讯。这个可以在后台管理的菜单 “资讯管理” 里面配置食品资讯文章。
精选类目: 这个可以在后台管理的首页管理的精品分类管理里面配置,目前配置的分类有:叶菜,葱类,香辛,茄果,瓜类,鸡鸭禽,虾蟹,豆类。
精品推荐: 查询销量的top前8个生鲜商品。销量会在用户支付接口调用后新增商品销量,并且用户退款不支持减去销量。
新品上架: 查询商品按照创建时间倒叙的top前8个生鲜商品。
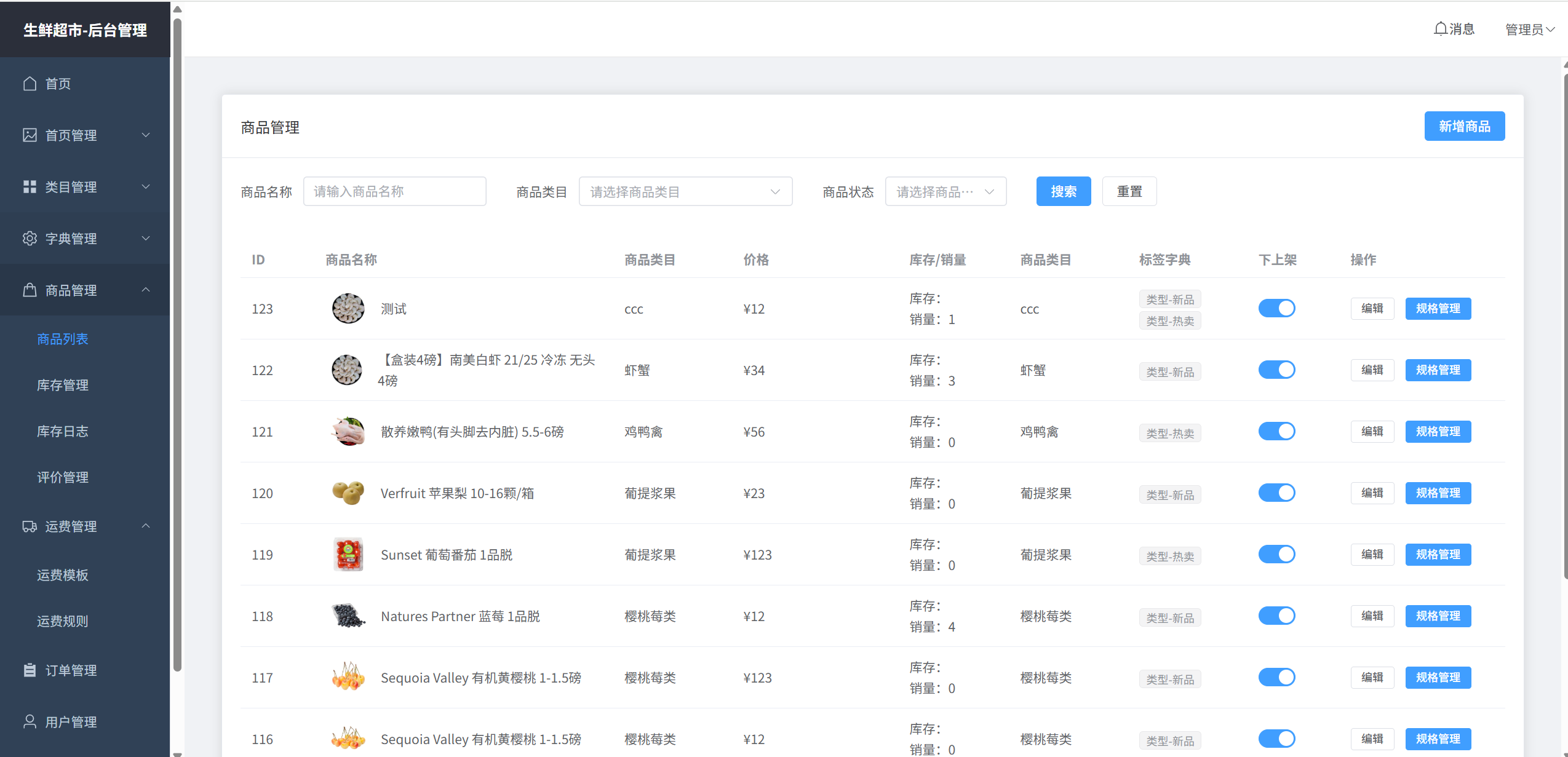
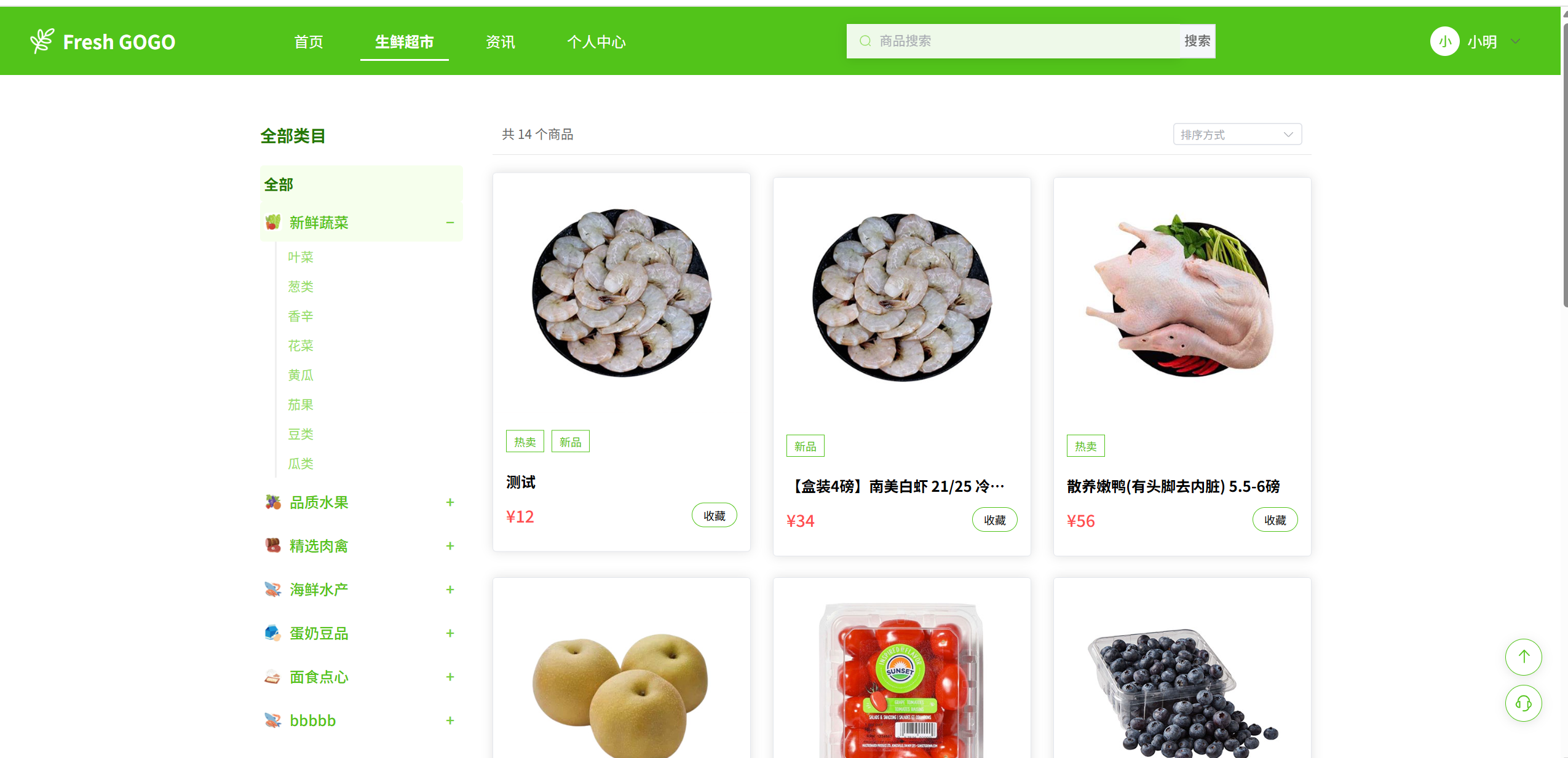
生鲜商品管理
这个是系统的核心, 商品的很多属性,主要有: 生鲜商品的售卖标题,所属的二级分类,商品详情的属性,商品详情,spu规格等。在后台管理的商品管理里面可以对商品进行上下架,商品新增,修改,切不可删除。因为商品关联了很多表,如果不卖该商品了,只能作下架处理。
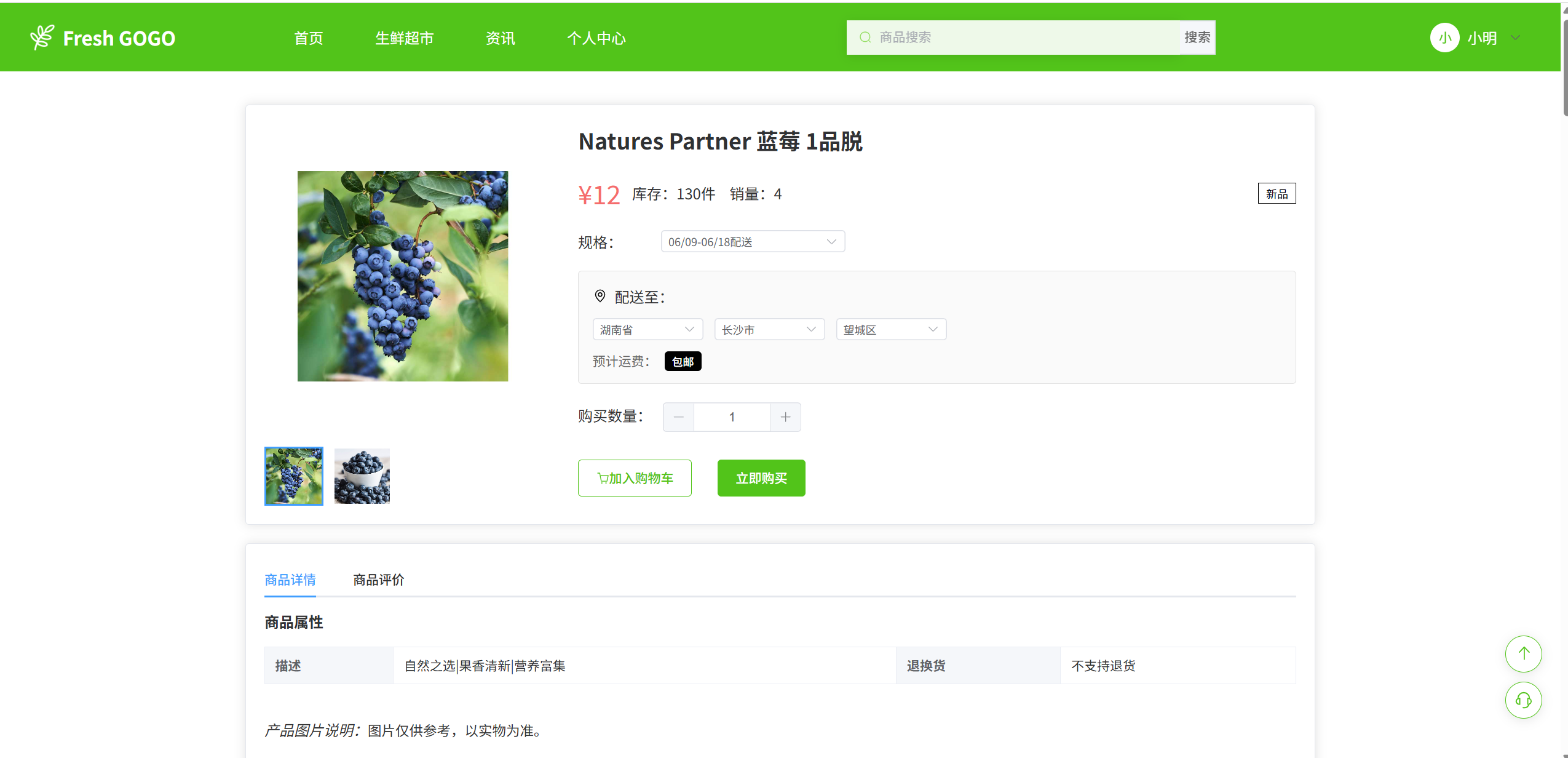
规格库存,价格等管理
spu(规格)是商品的最小单元,比如当用户购买韭菜时,有可能是打包成了1KG , 10KG等很多系列,这些都是不同的规格, 每个规格有不同的库存和价格。用户购买时,都需要选中到具体的哪个规格才能保证下单。
在后台管理的库存管理,就可以对所有商品的spu规格进行管理,可以对每个spu上传不同的商详图片。可以新增,减少库存。还有详细的库存日志可查。
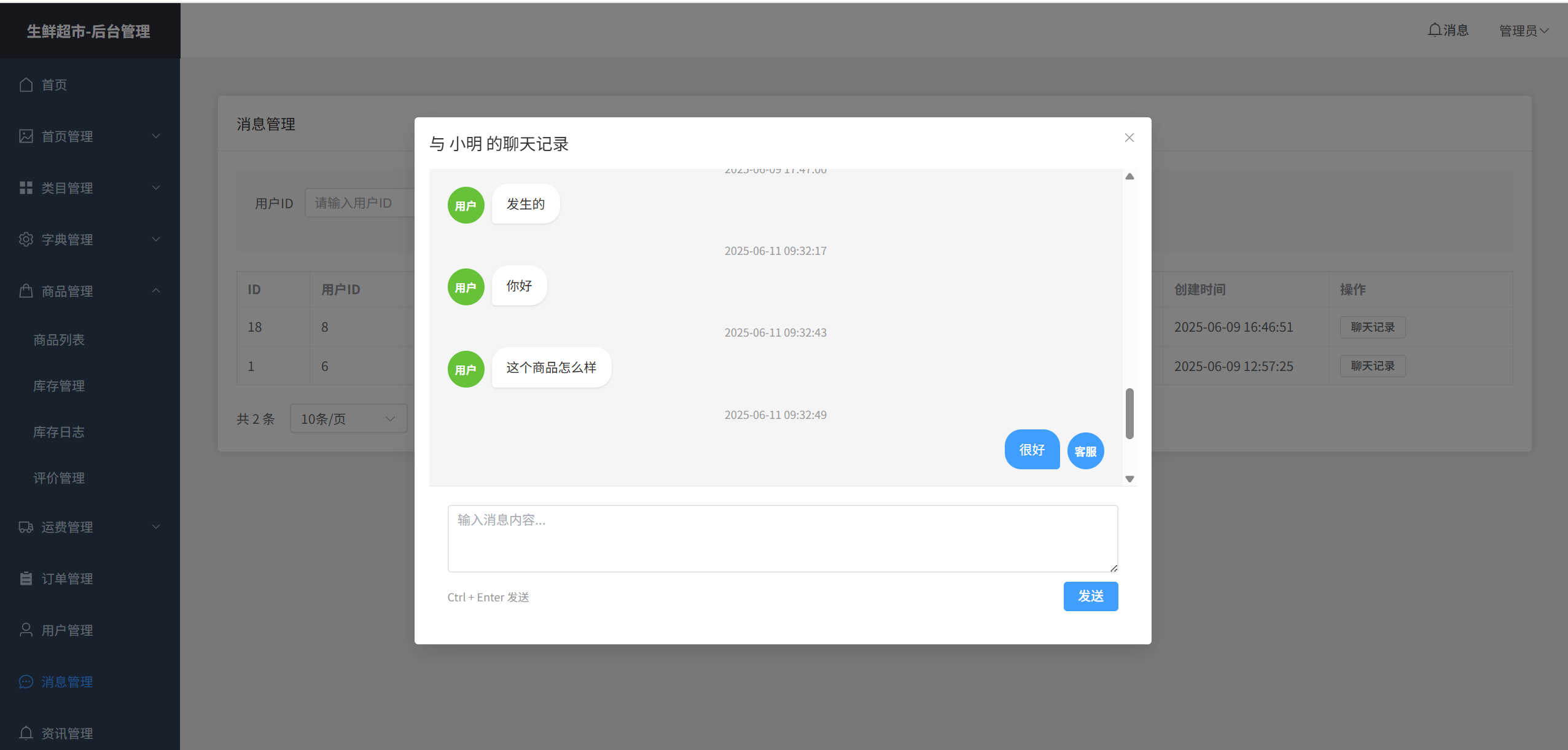
客服管理
每个用户当登录成功后,在页面的右下角可以联系客服, 当发送消息成功后, 后端台管理就能够看到右上角的消息红点,点击消失,跳转到和客户的聊天列表, 就可以查看聊天记录,聊天记录类似微信,qq等的聊天面板,只能发送文字。用户和管理员可以实时的进行聊天。
评价管理
评价是商城不可或缺的一部分,很多用户就是看评价下单的,我们的评价有内容,还支持多张图片,还有评分等级。可以说是一个很丰富的评价体系 。这个评分还参与了用户协同过滤推荐系统。用户只有当订单处与完成状态时,才可以对商品进行评价。
在后台管理的商品管理下面的评价管理可以查看和删除用户的评价。
用户管理
用户有头像,用户名,邮箱,密码,是否禁用,当前收获地址等属性。用户前端注册是通过邮箱验证码来注册,所以系统初始化时,需要在后台管理的字典管理的系统字典里面设置好邮箱服务器,然后才可以进行正确的注册。
用户登录可以通过用户名或者邮箱登录。当后台管理将用户禁用后,登录失效。
前端可以对用户的用户名,头像进行修改, 还可以修改默认的收获地址。
运费管理
运费首先是有一个运费模板,商品上架时选中这个运费模板, 如果模板是包邮的,则前端显示电子手机商品的邮费就是包邮,下单接口也会计算这个邮费。
如果模板里面是不包邮的,那么就需要关联多个运费规则,每个运费规则有省市区 和 运费 两个属性,这样当用户下单的收获地址匹配到了运费规则 的地区,就可以拿到运费进行计算 订单价格。
资讯管理
这个板块是生鲜商城的一个吸引模块, 主要承载一些食品安全的资讯文章,可以在后台进行新增和编辑,还有删除 文章。
购物车+收藏
用户浏览生鲜商品时, 可以对生鲜商品进行收藏,添加购物车处理,收藏后可以在后台管理的用户列表的操作列看到查看收藏。前端用户自己也可以进行收藏取消等。
同一个商品购物车添加有数量有上限。
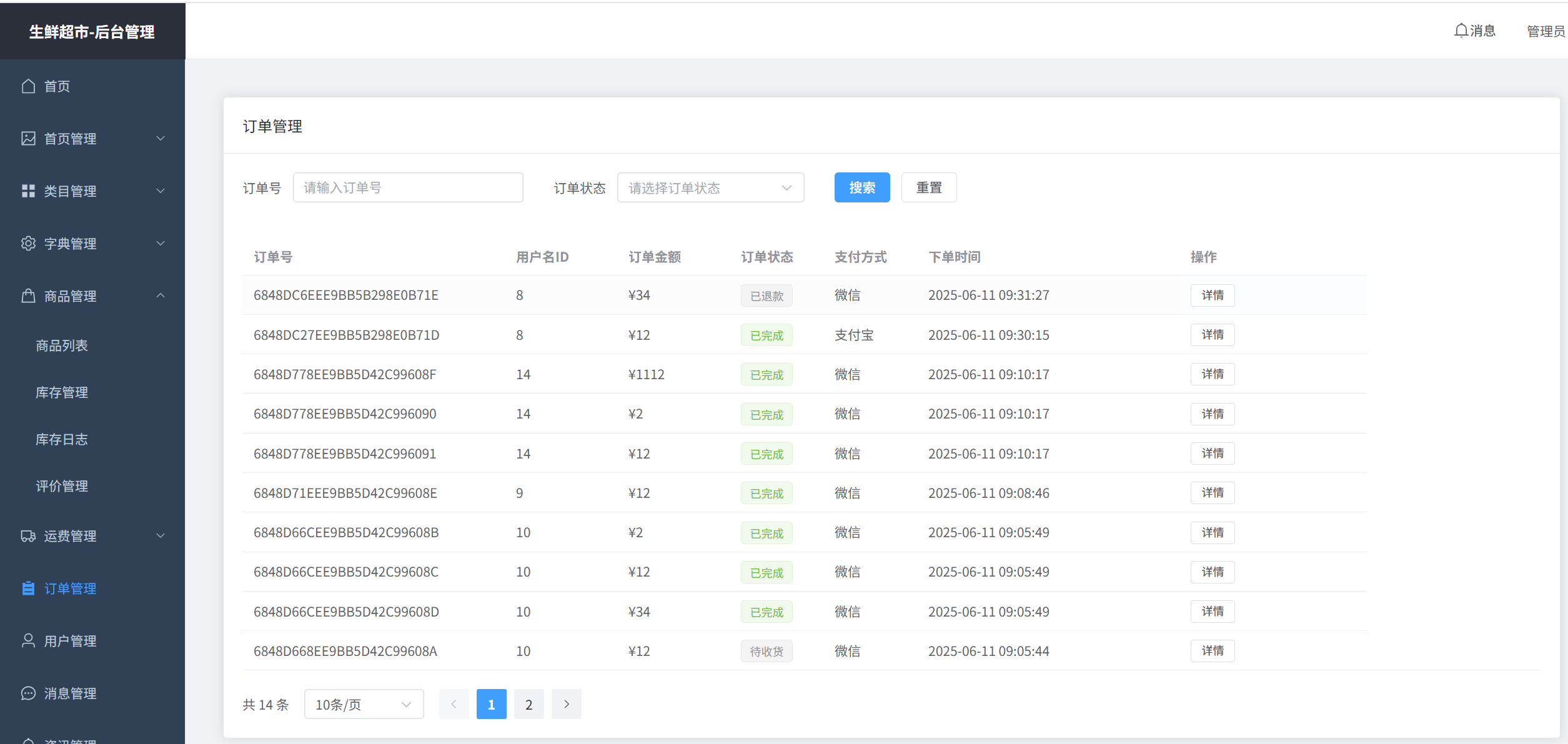
订单管理
我们将订单的状态设计成以下几种:0-待付款 1-待发货 2-待收货 3-待评价 4-已完成 5-退款中 6-已退款 7-已取消。 订单状态扭转流程:
1. 用户点击购买商品或从购物车点击,则商品进入待付款状态,此时,商品库存被锁,也就是实实在在的扣减了销售库存。
2. 当30分钟超过后,用户未支付上面的待付款订单,则订单状态扭转为已取消,库存回流,此笔订单结束。
3. 当用户30分钟内支付后,订单扭转为代发货。
4. 管理员登录管理后台,将待发货订单进行发货操作后,订单状态变成待收货。
5. 用户可以对待收获订单进行收获和退款操作,如果是退款,则变成退款中,管理员进行退款确认,确认后,订单变成已退款,退款成功后,库存回流。此订单结束。
6. 如果用户确认收获,则订单变成待评价,用户可以进行评价,评价完成后,订单变成已完成,此订单结束。
收货地址管理
每个用户新注册是没有收货地址的,如果此时下单生鲜商品,也是无法下单。需要在个人中心去新增收获地区,收货地址有:省市区,具体的联系人,手机号,具体地址信息。
用户可以增加很多收货地址, 同时用户可以在修改资料时,切换已经存在的收货地址。
技术栈说明
后端技术栈
- java语言采用JDK17 。 数据库有Mysql8 ,Redis 。 项目用到了SpringBoot3+Mybatis-plus+SpringMVC 框架。
- 客服系统采用了websocket实时通信技术。
- 项目使用前后端分离开发,解决跨域问题。
- 系统分为:controller,service,mapper 三层,是典型的三层架构设计方式。
- 项目采用RESTful API风格设计后端接口
- 项目采用统一响应格式,JSON结构标准化,例如:{"code": 0, "message": "success","data": {...} }
- 文件图片存储,是存储在本地磁盘上的。
- 项目中的类名、变量名、包名等严格遵循Java设计规范。
- 项目的token生成采用了JWT技术。
- 注册时的邮箱验证码技术。
前端技术栈
Vue 3 + Vue Router 4 + Element Plus
- 采用模块化开发,按功能划分API文件
- 使用ES6+语法和模块系统
- 响应式设计,适配移动端H5
- 统一的错误处理和消息提示
- 支持Token认证的用户系统
- 项目使用ECharts 数据可视化
-富文本编辑器
核心功能实现
客服在线聊天设计
在线聊天使用了websocket技术,首先需要一个配置类:
@Configuration
@EnableWebSocket
public class WebSocketConfig implements WebSocketConfigurer { @Autowired
private ChatWebSocketService chatWebSocketService; @Override
public void registerWebSocketHandlers(WebSocketHandlerRegistry registry) {
registry.addHandler(chatWebSocketService, "/api/chat")
.setAllowedOrigins("*");
}
}
/api/chat 指定了监听地址。ChatWebSocketService 为消息处理的逻辑类。
@Component
@Slf4j
public class ChatWebSocketService extends TextWebSocketHandler { @Autowired
WebsocketMapping websocketMapping; @Autowired
MessageHandleService messageHandleService; @Value("${admin-id}")
String adminId ; @Override
public void afterConnectionEstablished(WebSocketSession session) throws Exception {
} @Override
protected void handleTextMessage(WebSocketSession session, TextMessage message) {
String payload = message.getPayload();
log.info("收到消息 {}", payload);
// 转换
WebsocketResponse websocketMasg = JSON.parseObject(payload, WebsocketResponse.class); if (websocketMasg.getType() == 0) {
// 握手
if(websocketMasg.getBody().equals("")){
//管理员
websocketMapping.up(adminId,session);
}else{
//用户端
websocketMapping.up(websocketMasg.getBody().toString(), session);
}
} else if (websocketMasg.getType() == 1) {
// 心跳
} else if (websocketMasg.getType() == 2) {
// 问答
messageHandleService.handleMessage(websocketMasg);
}
} @Override
public void afterConnectionClosed(WebSocketSession session, CloseStatus status) throws Exception {
// 连接关闭时的处理
String uid = websocketMapping.exception(session);
log.info("用户断开 id:{}", uid);
}
}
聊天的信息会存储到chat_msg表里面:
CREATE TABLE `chat_msg` (
`id` int NOT NULL AUTO_INCREMENT,
`user_id` int NOT NULL COMMENT '用户id',
`msg_type` tinyint NOT NULL COMMENT '0-用户发出的 1-用户接受的消息',
`admin_id` varchar(50) COLLATE utf8mb4_bin NOT NULL COMMENT '管理员id',
`content` mediumtext CHARACTER SET utf8mb4 COLLATE utf8mb4_bin NOT NULL COMMENT '聊天内容',
`create_time` datetime DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
PRIMARY KEY (`id`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=39 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin COMMENT='消息记录表';
库存系统的设计
库存最大的问题就是超卖,也就是说有多个人同时并发下单,库存需要保持一致性,不会扣减到小于0的情况。普通的设计就是加一个全局锁。每个人下单都需要等待上一个人下单完成。
这样严重影响效率。这里我们库存的设计流程如下:
1. 首先我们将库存分为 数据库库存 和 销售库存。 数据库库存就是存储到数据库的商品库存值,销售库存就是用户下单,页面所在的库存值。
2. 后台管理上架商品时,会设置一个初始库存,我们将初始库存存储到数据库库存 和 销售库存 。
3.当用户下单时,不是直接扣减的数据库库存,而是通过redis的 decrement 方法,对销售库存进行扣减。但是redis的扣减操作这里还不是一个原子性操作,需要先从redis查出库存,然后进行decrment操作。这两步操作我们用reddsion的分布式锁来控制原子性,同时,我们将加锁的维度控制到了商品id。这样大大提高了并发效率。
4. 库存扣减后,我们又通过redis消费队列,实现了对数据库库存的同步。这样保持了redis库存和数据库库存的一致性。
5. 后台我们设计的是对商品只能加加库存,和减少库存的操作,而不是直接修改库存值。如果你直接修改库存值,就有可能会导致库存数据不一致,难以跟踪。
6. 我们还设计了库存的扣减,新增日志,方便对库存进行跟踪管理。
库存扣减的部分代码:

/**
* 扣减库存(使用Redisson分布式锁)
* @param quantity 扣减数量
* @return true-扣减成功,false-扣减失败(库存不足)
*/
public boolean deductInventory(Integer spuId, int quantity) {
String lockKey = "lock:inventory:" + spuId;
String inventoryKey = "inventory:" + spuId; RLock lock = redissonClient.getLock(lockKey); try {
// 尝试加锁,最多等待10秒,锁过期时间30秒
boolean locked = lock.tryLock(10, 30, TimeUnit.SECONDS);
if (locked) {
String stock = (String) redisTemplate.opsForValue().get(inventoryKey);
if (StringUtils.isEmpty(stock)) {
return false;
}
if (Integer.parseInt(stock) < quantity) {
return false;
}
// 扣减库存
redisTemplate.opsForValue().decrement(inventoryKey, quantity);
return true;
}
return false;
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
return false;
} finally {
// 释放锁
if (lock.isHeldByCurrentThread()) {
lock.unlock();
}
}
}
用户协同过滤算法的设计
协同过滤(Collaborative Filtering, CF)是推荐系统中最经典的算法之一,其核心思想是通过用户的历史行为数据(如评分、点击、购买等)发现用户或物品的相似性,并基于这种相似性进行推荐。协同过滤分为两大类:基于用户的协同过滤和基于物品的协同过滤。
算法的步骤
1. 获取所有用户行为数据,构建用户-物品评分矩阵。
2. 目标用户与其它用户的相似度计算: 将用户对商品的评分视为向量,计算余弦相似度。
3. 选取与目标用户相似度最高的 k 个用户作为邻居 。
4. 通过邻居用户的评分进行加权平均预测(权重为用户相似度)。
5. 将预测评分按降序排序,选择评分最高的N个物品作为推荐结果。
举例说明

用户评分矩阵的构建
需要借助Array2DRowRealMatrix算法工具,Array2DRowRealMatrix 是 Apache Commons Math 库中的一个类,用于表示二维实数矩阵,并提供矩阵运算功能。
maven依赖如下:
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-math3</artifactId>
<version>3.6.1</version>
</dependency>
构建评分矩阵的代码:
// 获取所有用户的行为数据,用于构建用户-物品评分矩阵
List<UserBehavior> allBehaviors = userBehaviorRepository.selectList(null); if(CollectionUtils.isEmpty(allBehaviors)) {
return Collections.emptyList();
} // 构建用户和物品的索引映射,方便后续构建评分矩阵
Map<Long, Integer> userIndex = new HashMap<>();
Map<Long, Integer> itemIndex = new HashMap<>();
// 提取用户id
List<Long> users = allBehaviors.stream().map(UserBehavior::getUserId).distinct().collect(Collectors.toList());
// 提取物品id
List<Long> items = allBehaviors.stream().map(UserBehavior::getItemId).distinct().collect(Collectors.toList());
for (int i = 0; i < users.size(); i++) {
userIndex.put(users.get(i), i);
}
for (int i = 0; i < items.size(); i++) {
itemIndex.put(items.get(i), i);
}
// 初始化评分矩阵,行表示用户,列表示物品 一个 users.size() x items.size() 大小的矩阵
RealMatrix ratingMatrix = new Array2DRowRealMatrix(users.size(), items.size());
// 根据用户行为数据填充评分矩阵
for (UserBehavior behavior : allBehaviors) {
if (behavior.getRating() != null) {
int uIndex = userIndex.get(behavior.getUserId());
int iIndex = itemIndex.get(behavior.getItemId());
// 设置 矩阵的 行,列 值 为 评分
ratingMatrix.setEntry(uIndex, iIndex, behavior.getRating());
}
}
余弦相似度计算
/**
* 计算两个向量的余弦相似度
* 余弦相似度用于衡量两个用户的评分模式的相似程度
* @param vector1 第一个用户的评分向量
* @param vector2 第二个用户的评分向量
* @return 相似度值,范围[-1,1],值越大表示越相似
*/
private double calculateCosineSimilarity(double[] vector1, double[] vector2) {
double dotProduct = 0.0;
double norm1 = 0.0;
double norm2 = 0.0; for (int i = 0; i < vector1.length; i++) {
dotProduct += vector1[i] * vector2[i];
norm1 += vector1[i] * vector1[i];
norm2 += vector2[i] * vector2[i];
} if (norm1 == 0 || norm2 == 0) return 0; return dotProduct / (Math.sqrt(norm1) * Math.sqrt(norm2));
}
根据余弦相似度计算取5个相似的用户作为邻居
// 计算目标用户与其他用户的相似度
int userIdx = userIndex.get(user.getId());
Map<Integer, Double> userSimilarities = new HashMap<>(); for (int i = 0; i < users.size(); i++) {
if (i != userIdx) {
// 计算 当前用户 与其他的每一个用户的评分向量的 余弦相似度
double similarity = calculateCosineSimilarity(ratingMatrix.getRow(userIdx), ratingMatrix.getRow(i));
userSimilarities.put(i, similarity);
}
} // 选择最相似的5个用户作为邻居用户
List<Integer> similarUsers = userSimilarities.entrySet().stream()
// 按相似度值降序排序
.sorted(Map.Entry.<Integer, Double>comparingByValue().reversed())
// 取前5个最相似用户
.limit(5)
// 提取用户索引
.map(Map.Entry::getKey)
.collect(Collectors.toList());
最后是计算加权平均,当中还需要进行 归一化处理, 来避免了因用户群体整体相似度偏高/偏低导致的预测偏差,使得推荐结果更贴近用户的真实偏好。 整体代码较长,我就不贴了。
商品的设计
手机商品的相关表结构如下:
CREATE TABLE `product` (
`product_id` int NOT NULL AUTO_INCREMENT COMMENT '商品id',
`product_name` varchar(100) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '商品名称',
`category_id` int NOT NULL COMMENT '类目id',
`product_title` varchar(300) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '商品标题',
`product_intro` text CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '商品详情',
`product_picture` varchar(200) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL COMMENT '商品封面图',
`spu0_price` double NOT NULL COMMENT '参考价,商品第一个spu的价格',
`product_sales` int NOT NULL COMMENT '销量',
`state` tinyint DEFAULT '0' COMMENT '0-上架 1- 下架',
PRIMARY KEY (`product_id`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=67 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin ROW_FORMAT=DYNAMIC COMMENT='商品'; CREATE TABLE `product_spu` (
`id` int NOT NULL AUTO_INCREMENT COMMENT 'id',
`product_id` int NOT NULL COMMENT '商品id',
`spu_name` varchar(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin NOT NULL COMMENT '规格的key名称,比如尺码',
`spu_value` varchar(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin NOT NULL COMMENT '规格的key的值,比如尺码的大小是S',
`spu_price` double NOT NULL COMMENT '商品售卖价',
`spu_stock` int NOT NULL COMMENT 'spu库存',
`state` tinyint DEFAULT '0' COMMENT '0-上架 1- 下架',
PRIMARY KEY (`id`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=101 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin ROW_FORMAT=DYNAMIC COMMENT='商品最小单元'; CREATE TABLE `spu_picture` (
`id` int NOT NULL AUTO_INCREMENT COMMENT '主键id',
`spu_id` int NOT NULL COMMENT '商品id',
`product_picture` varchar(200) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL COMMENT '商品图片',
PRIMARY KEY (`id`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=136 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin COMMENT='商品图片';
订单表设计如下:
CREATE TABLE `orders` (
`order_id` varchar(200) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin NOT NULL,
`user_id` int NOT NULL COMMENT '用户id',
`spu_id` int NOT NULL COMMENT '商品id',
`spu_name` varchar(255) COLLATE utf8mb4_bin DEFAULT NULL COMMENT 'spu的名称',
`spu_value` varchar(255) COLLATE utf8mb4_bin DEFAULT NULL COMMENT 'spu的值',
`product_num` int NOT NULL COMMENT '商品数量',
`order_state` int NOT NULL COMMENT '订单状态 0-待付款 1-待发货 2-待收货 3-待评价 4-已完成 5-退款中 6-已退款 7-已取消',
`product_price` double NOT NULL COMMENT '下单商品价格',
`shipping_price` double NOT NULL COMMENT '下单运费价格',
`refund_cause` varchar(2255) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin DEFAULT NULL COMMENT '退款原因',
`order_remark` varchar(2000) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin NOT NULL COMMENT '订单备注',
`pay_type` int DEFAULT NULL COMMENT '支付方式:0-支付宝 1-微信',
`address` varchar(2000) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin NOT NULL COMMENT '收获地址',
`create_time` datetime DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
PRIMARY KEY (`order_id`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin ROW_FORMAT=DYNAMIC COMMENT='订单';
运费的设计
首先需要有一个模板表 , 上架商品时, 直接选中到这个运费模板
CREATE TABLE `shipping_template` (
`template_id` int NOT NULL AUTO_INCREMENT,
`name` varchar(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin NOT NULL COMMENT '模板名称',
`is_free_shipping` tinyint(1) DEFAULT '0' COMMENT '是否包邮(0否1是)',
PRIMARY KEY (`template_id`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=5 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin ROW_FORMAT=DYNAMIC COMMENT='运费模板表';
每个模板有着自己的运费规则, 规则里面重要的就是城市信息。每个城市的运费都不一样。
CREATE TABLE `shipping_rule` (
`id` int NOT NULL AUTO_INCREMENT,
`template_id` int NOT NULL COMMENT '运费模板ID',
`city_id` int NOT NULL COMMENT '地区编码(可多级)',
`first_fee` double NOT NULL COMMENT '该地域的运费',
PRIMARY KEY (`id`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin ROW_FORMAT=DYNAMIC COMMENT='运费规则表';
项目部署安装
执行sql
用户需要自己安装好mysql数据库,注意,必须是mysql8 ,否则代码运行会出错。
然后用navicate等连接工具,连接到mysql服务,然后新建一个 wxhadluo-fresh 数据库, 然后执行 “wxhadluo-phone.sql” 里面的表创建和数据导入。
Redis安装
项目需要安装redis,直接下载一个windows版本的redis启动redis-ser即可。
前端部署
管理后端
安装node , 版本:v22.15.0 , 安装完成后。 进入到项目 hadluo-shop-webadmin 目录下,这个项目是vue的管理后台, 右键,运行cmd,运行下面命令:
npm run dev
由于我已经跟你npm install好了,所以你无需执行,直接run就可以了!!
用户前端
进入到项目 hadluo-shop-h5 目录下,这个项目是vue的前端, 右键,运行cmd,运行下面命令:
npm run dev
由于我已经跟你npm install好了,所以你无需执行,直接run就可以了!! 运行项目
到此前端项目部署完成。
启动后端项目
将maven设置的settings.xml改成你自己的配置。
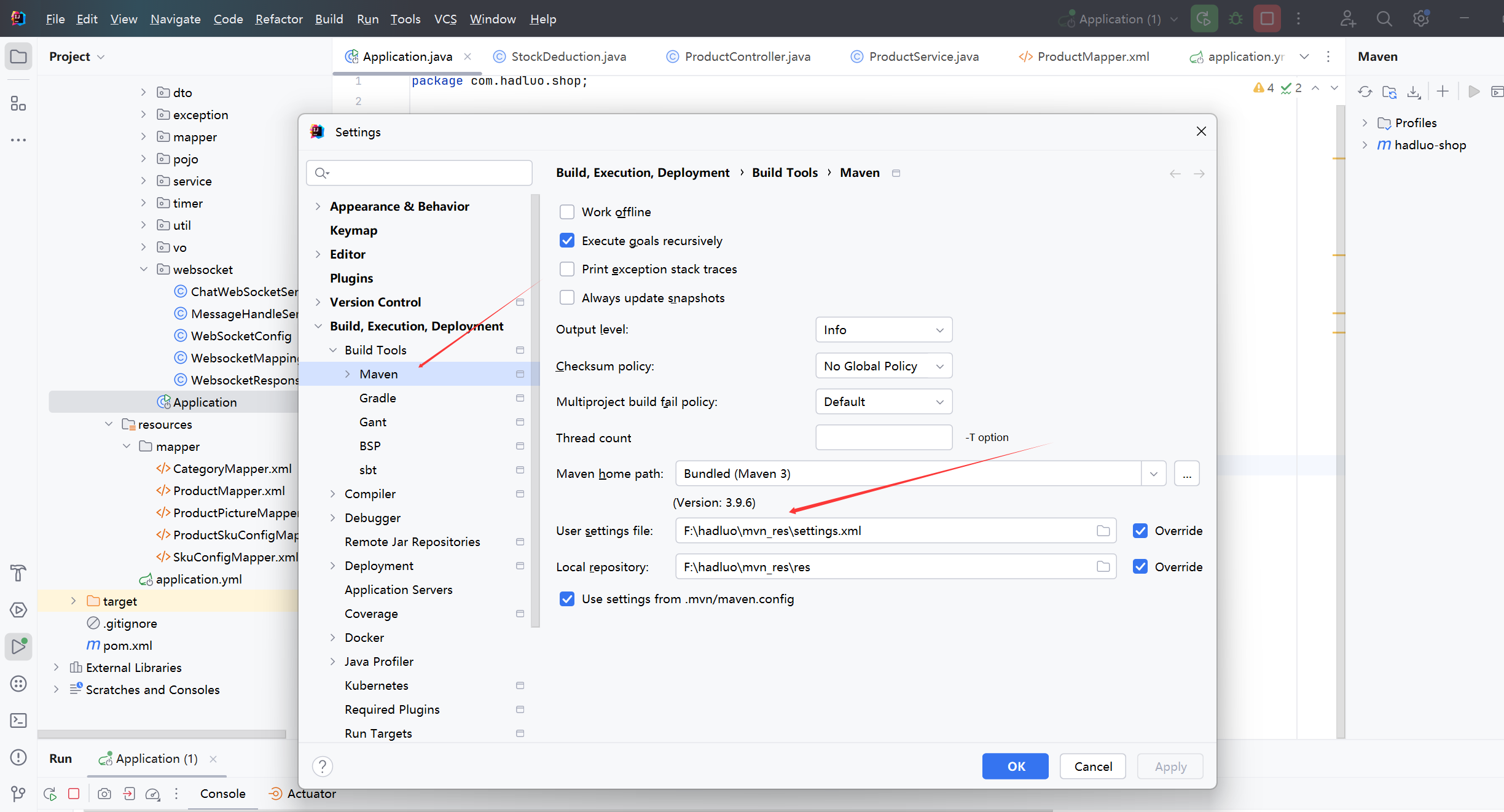
然后刷新maven,等待项目下载依赖包完成。。。。。
然后部署后端 , 打开idea, 导入maven工程 hadluo-bookshop。
打开resources目录, 修改 application.yml 配置文件,主要修改下面几个信息:
数据库信息:
spring:
datasource:
url: jdbc:mysql://127.0.0.1:3306/wxhadluo-fresh?characterEncoding=UTF8&serverTimezone=Asia/Shanghai
username: root
password: qq123456
redis信息
data:
redis:
host: 127.0.0.1
port: 6379
图片存储磁盘路径(这个可以不要动,需要把wxhadluo-fresh(图片目录)放到D:\ftp下面,项目的图片才可以正常展示)
# 文件上传路径配置
file:
upload:
path: D:\ftp\wxhadluo-fresh #文件上传的路径
url-prefix: http://localhost:${server.port}/file/get # 文件下载接口的地址 ,不要动
然后启动 main 启动类 : Application.class
浏览器访问
管理后端:
http://localhost:3001/
管理员账号密码在配置文件中:
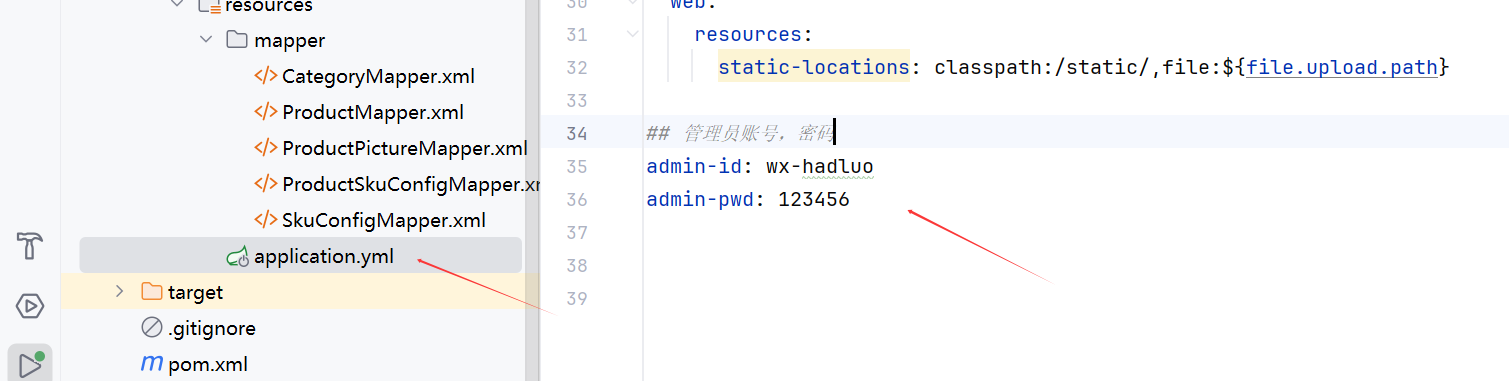
前端:
http://localhost:3000/
前端用户表在user表里面, 密码是加密的。是123456
你也可以自己注册。
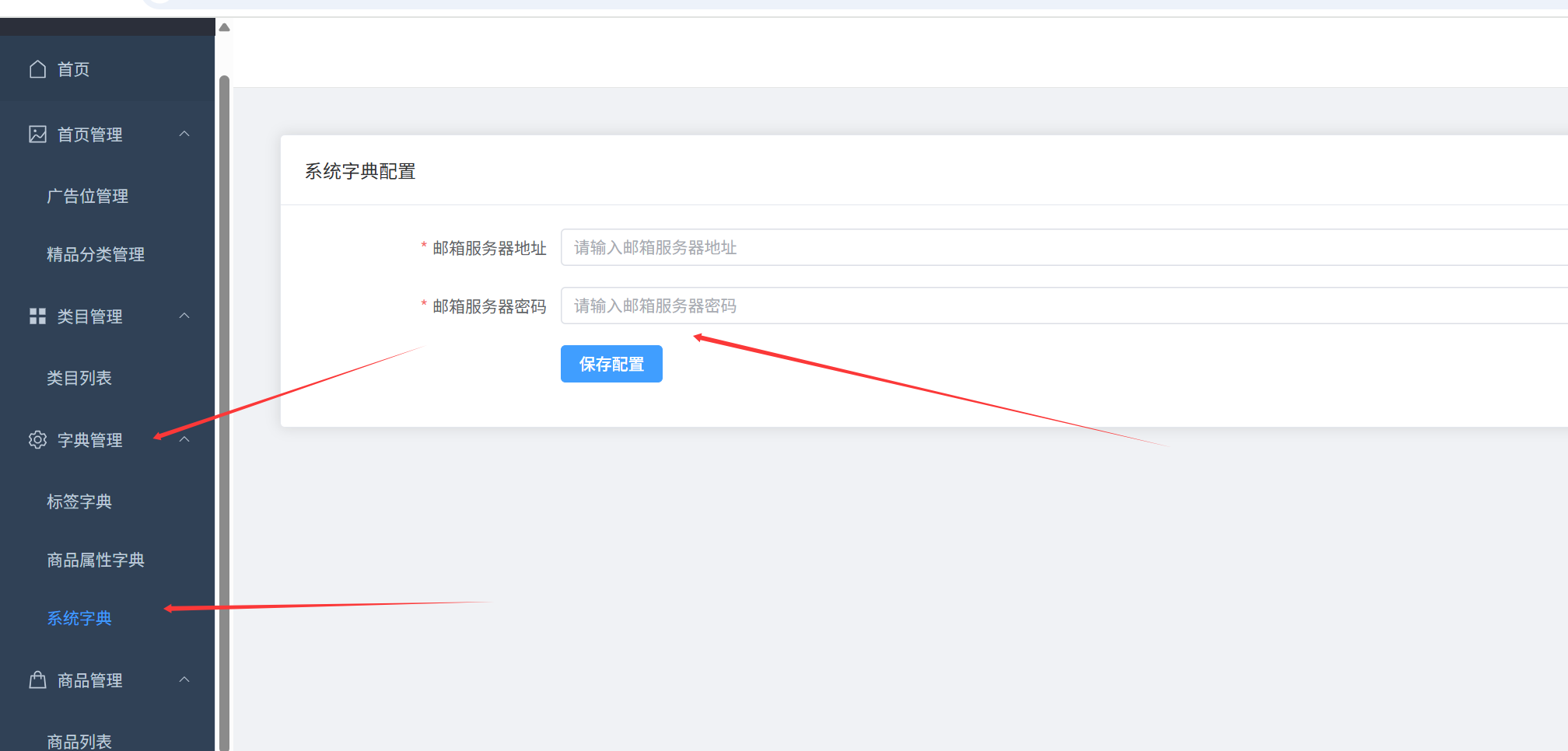
注册时,需要邮箱验证码,需要先在后端管理的字典管理的系统字典,配置你的qq邮箱服务器和密钥(不知道密钥的,可以自己百度下 如何生成qq邮箱服务器密钥)。
生鲜超市源码+springboot3+vue3+JDK17(带用户协同过滤个性化推荐算法)的更多相关文章
- [阿里DIN] 深度兴趣网络源码分析 之 如何建模用户序列
[阿里DIN] 深度兴趣网络源码分析 之 如何建模用户序列 目录 [阿里DIN] 深度兴趣网络源码分析 之 如何建模用户序列 0x00 摘要 0x01 DIN 需要什么数据 0x02 如何产生数据 2 ...
- [源码解析] PyTorch 如何实现后向传播 (4)---- 具体算法
[源码解析] PyTorch 如何实现后向传播 (4)---- 具体算法 目录 [源码解析] PyTorch 如何实现后向传播 (4)---- 具体算法 0x00 摘要 0x01 工作线程主体 1.1 ...
- React16源码解读:开篇带你搞懂几个面试考点
引言 如今,主流的前端框架React,Vue和Angular在前端领域已成三足鼎立之势,基于前端技术栈的发展现状,大大小小的公司或多或少也会使用其中某一项或者多项技术栈,那么掌握并熟练使用其中至少一种 ...
- 想要看懂鸿蒙OS源码?朱老师带你从框架分析开始
HarmonyOS V2.0是面向轻量级设备的鸿蒙L0/L1级设备端操作系统,于2020.9开源至今已有2个多月,但是很多同学在学习鸿蒙源码时仍然感觉难以下手,找不到突破口. 2020.11.25(本 ...
- 使用 IntelliJ IDEA 导入 Spark 最新源码及编译 Spark 源代码(博主强烈推荐)
前言 其实啊,无论你是初学者还是具备了有一定spark编程经验,都需要对spark源码足够重视起来. 本人,肺腑之己见,想要成为大数据的大牛和顶尖专家,多结合源码和操练编程. 准备工作 1.sca ...
- 【JUnit4.10源码分析】6.1 排序和过滤
abstract class ParentRunner<T> extends Runner implements Filterable,Sortable 本节介绍排序和过滤. (尽管JUn ...
- Ribbon源码分析(一)-- RestTemplate 以及自定义负载均衡算法
如果只是想看ribbon的自定义负载均衡配置,请查看: https://www.cnblogs.com/yangxiaohui227/p/13186004.html 注意: 1.RestTemplat ...
- Apache Spark源码走读之22 -- 浅谈mllib中线性回归的算法实现
欢迎转载,转载请注明出处,徽沪一郎. 概要 本文简要描述线性回归算法在Spark MLLib中的具体实现,涉及线性回归算法本身及线性回归并行处理的理论基础,然后对代码实现部分进行走读. 线性回归模型 ...
- STL源码剖析读书笔记--第6章&第7章--算法与仿函数
老实说,这两章内容还蛮多的,但是其实在应用中一点点了解比较好.所以我决定这两张在以后使用过程中零零散散地总结,这个时候就说些基本概念好了.实际上,这两个STL组件都及其重要,我不详述一方面是自己偷懒, ...
- (转)OpenFire源码学习之八:MUC用户聊天室
转:http://blog.csdn.net/huwenfeng_2011/article/details/43413817 MUC 房间属性设置 以上属性存储在MUCPersistenceManag ...
随机推荐
- Maui 实践:不要把 DataPackagePropertySetView 看作一层皮
-- 再论为控件动态扩展 DragDrop 能力 夏群林 原创 2025.7.18 一.Drag / Drop 之间传递的参数 前文提到,拖放的实现需要 DragGestureRecognizer 与 ...
- Behavioral Approach of Management Science: OB(Organizational Behavior)
Managers GTD(get things done) by WWP(working with people). This explains why some writers have chose ...
- XPath定位手册
XPath定位手册 一.XPath核心定位方法 1.基础路径定位 (1)绝对路径定位 从根节点开始的完整路径,以/开头: /html/body/div/form/input[@name='passwo ...
- 华为HCIE-AI笔试题解析
HCIE-AI笔试题 1.以下关于Google论文中标准transformer structure优点描述正确的有哪些选项?(多选) A.可以获取输入的全局依赖信息. B.Transformer的En ...
- vue项目发布到docker nginx的方法总结
我总结了以下两种方法可用 一.通过制作镜像,使用镜像生成docker 这个是比较常用的方法,制作镜像(images)后,如果还要生成docker可以直接使用镜像比较方便以下是操作步骤 1.创建目录 ...
- (译) 理解 Elixir 中的宏 Macro, 第五部分:组装 AST
Elixir Macros 系列文章译文 [1] (译) Understanding Elixir Macros, Part 1 Basics [2] (译) Understanding Elixir ...
- SpringBoot中使用TOTP实现MFA(多因素认证)
一.MFA简介 定义:多因素认证(MFA)要求用户在登录时提供至少两种不同类别的身份验证因子,以提升账户安全性 核心目标:解决单一密码认证的脆弱性(如暴力破解.钓鱼攻击),将账户被盗风险降低 ...
- Good Night Mr. Lawrence
坂本先生离开了,今天才知道. 也许每年圣诞节都会在欢乐中想起他,那一个个陪伴着我的音符. 3.28.
- Python零基础从入门到精通详细教程2-变量与常量
1.简介 程序就是用来处理数据的,而变量就是用来存储数据的.好呀,那我们今天就来聊聊 Python 中的变量吧!这可是编程里的一个重要概念哦. 2.变量的定义 变量,英文名叫做variable,是计算 ...
- 如何让Typecho搭建的网站首页文章随机显示?各位大佬支支招!
我想让我搭建的这个网多星宇博客站([www.0731119.xyz](http://www.0731119.xyz))实现首页文章每次进来随机出现,不知道怎么搞,请问给位大佬怎么搞? 最近在大家了这个 ...