ChunJun&OceanBase联合方案首次发布:构建一体化数据集成方案
8月27日,ChunJun社区与OceanBase社区联合组织的开源线下Meetup成功举办,会上重磅发布了「OceanBase&ChunJun:构建一体化数据集成方案」。
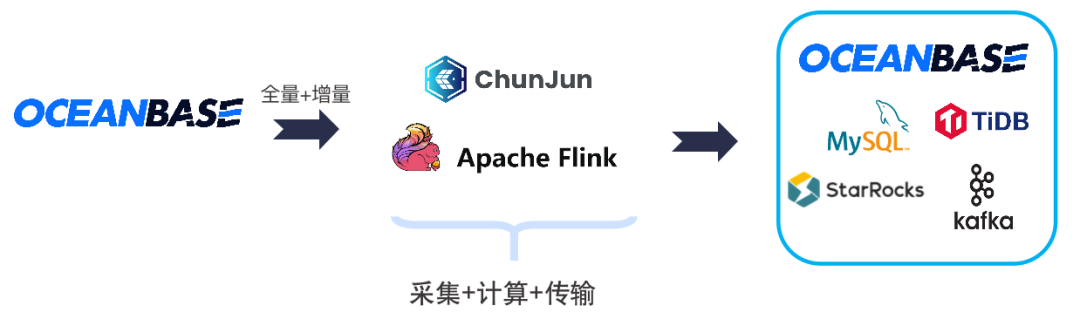
这是OceanBase&ChunJun联合解决方案的首次发布,将针对分库分表的实时数据集成、跨集群/租户的数据集成、不同数据源的实时数据集成、日志类型数据的全增量一体化处理等诸多场景,提供高可靠数据集成解决方案。
下面为大家带来具体介绍,欢迎分享给更多的开发者和爱好者共同学习、探讨。
课件获取:
关注公众号“ChunJun”,后台私信“Meetup”获得分享课件
视频回看:
https://www.bilibili.com/video/BV1mG41137ZV?spm_id_from=333.999.0.0
ChunJun&OceanBase是什么
ChunJun:一款稳定、高效、易用的数据集成框架
ChunJun 是一款高效、稳定、易用的数据集成框架,目前基于Apache Flink 实时计算引擎实现批流一体的数据读取和写入。
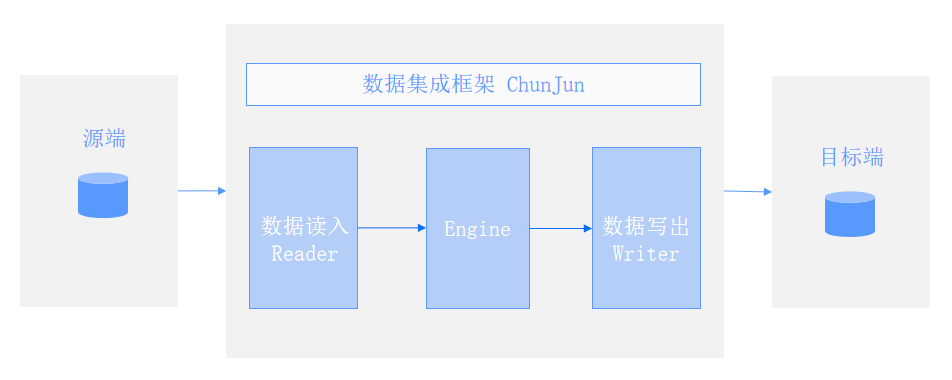
ChunJun的核心能力
• 多数据源:目前已支持30+数据源,涵盖了各类数据库、文件系统等
•灵活的任务运行模式:支持开箱即用的local模式运行,也支持flink standalone、yarn、k8s等模式;支持Taier、DolphinScheduler、Dlinky等大数据调度平台
• 数据还原:支持 DML 和 DDL 同步,可以最大程度保证源端和目标端的数据和结构统一
• 断点续传:依托Flink的Checkpoint机制,可以从失败的位点重试
• 速率控制:支持多种分片方式,用户可根据自身业务调整分片逻辑;支持调整读取和写入的并发度,控制每秒读取的数据量
• 脏数据管理:支持多种方式存储脏数据,控制脏数据生命周期,并提供统计数据
OceanBase:企业级开源分布式 HTAP数据库
企业级开源分布式 HTAP(Hybrid Transaction/Analytical Processing)数据库,具有原生分布式架构,支持金融级高可用、透明水平扩展、分布式事务、多租户和语法兼容等企业级特性。
OceanBase的核心能力
• 高可用:基于 Paxos 协议,强一致性;少数副本故障,数据不丢,服务不停;RPO=0; RTO<30s
•高扩展:在线进行水平扩、缩容;自动实现负载均衡
• 低成本:不依赖高端硬件,降低成本;极致的压缩比,节省成本
• HTAP:一套计算引擎同时支持混合负载;一套数据库,读写分离
• 高兼容:兼容 MySQL 协议与语法;降低业务改造迁移成本
• 多租户:一套环境独立运行多套业务;保证租户数据安全
ChunJun OceanBase Connector 实现
OceanBase CDC
OceanBase作为分布式数据库,日志信息分布在集群当中不同的机器上,需要有一个工具把这些日志信息进行汇总,拿到正确、完整的日志信息。
OceanBase社区版利用CDC 组件架构进行这项工作,它主要是通过oblogproxy来提供日志拉取的服务,如果想集成OceanBase增量数据的处理,可以在自己的业务应用中去集成oblogclient来进行处理,目前已对接了ChunJun、Flink CDC、Cloud Canal等数据集成框架。
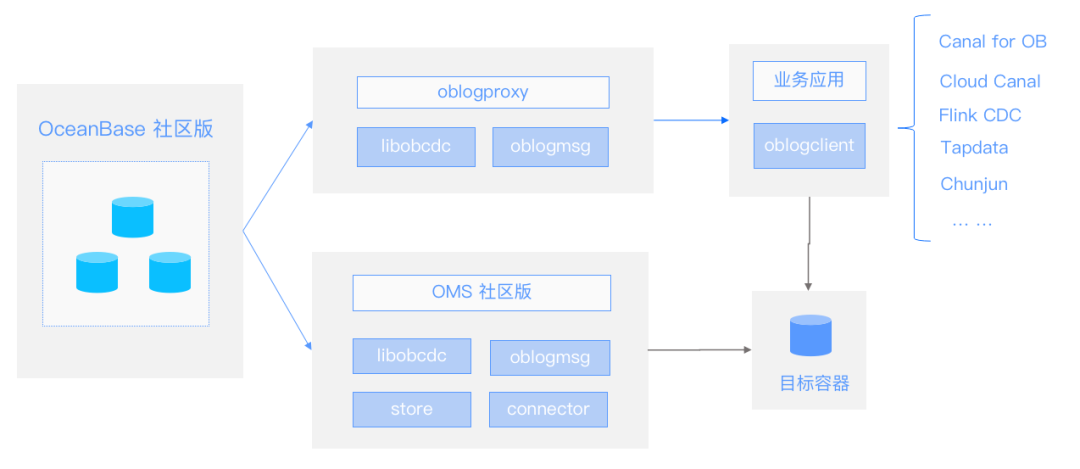
OceanBase 社区版 CDC 组件架构
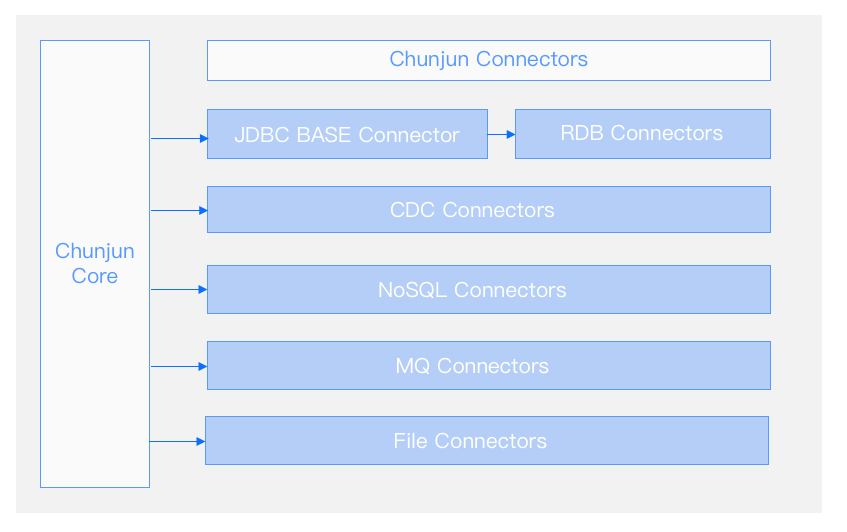
ChunJun Connectors 的工作模式
ChunJun中的读取和写入主要是通过Connector中的一些结构和模块来实现的,包含RDB、CDC 、NoSQL、MQ、File 等。
• RDB Connectors:基于 JDBC Connector,通过轮询支持了源表包含自增列且增量数据只有 insert 操作时的全增量一体化读取及写入。
• CDC Connectors:基于数据库的Binlog 或 Redolog,实现增量数据的读取。
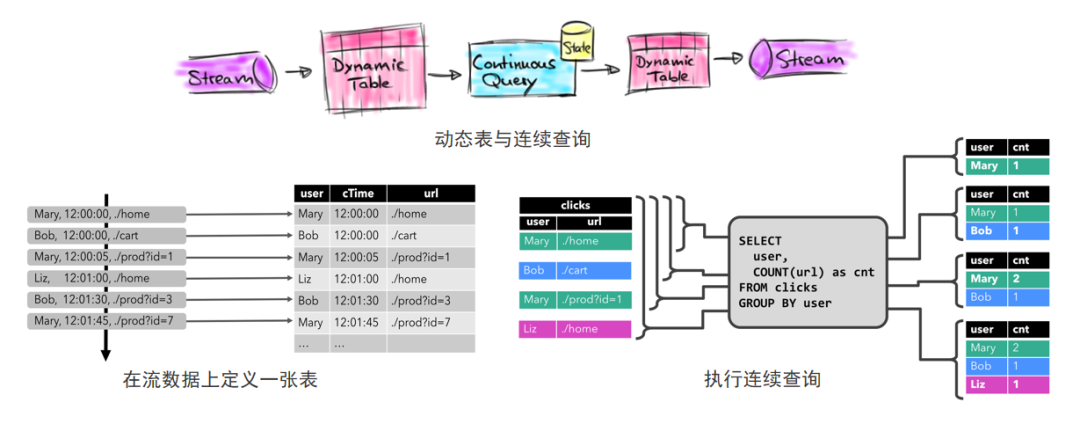
Flink 流数据与动态表
ChunJun上的这些数据最终会在Flink进行处理,在Flink当中通过定义动态表的结构,可以将流数据在执行SQL前先转换为可以操作的表,然后通过连续查询来获取一个不断更新的执行结果。
下图就是数据从数据流转成动态表,在流数据上定义一张标,通过执行连续查询来获取不断更新的结果。
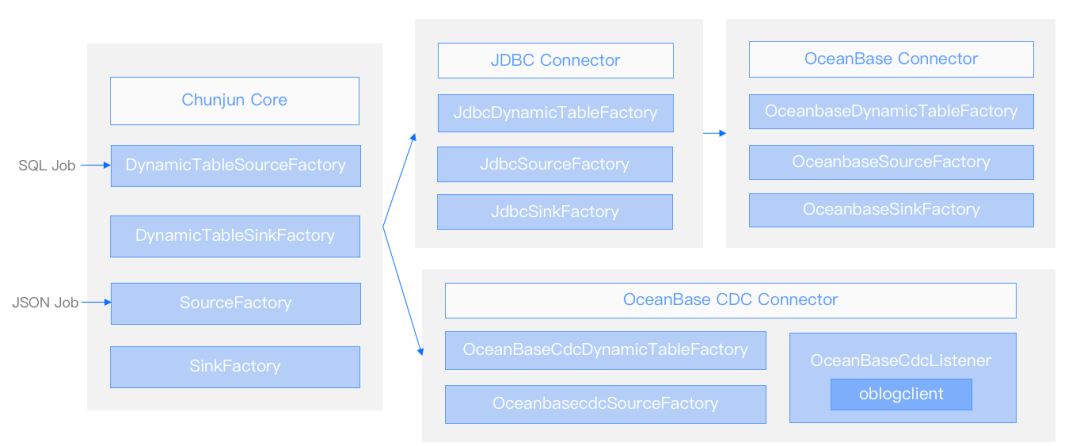
ChunJun OceanBase Connector 的实现
在ChunJun中主要是通过Chunjun Core模块来满足将数据读取到Flink及从Flink中写出去,其中DynamicTableSourceFactory及DynamicTableSinkFactory支持SQL类型的任务,SourceFactory及SinkFactory用来支持Json类型的任务。
如下图所示,ChunJun OceanBase Connector 的实现主要通过两种方式:一种是从Chunjun Core到JDBC Connector再到OceanBase Connector;另外一种是从Chunjun Core直接到OceanBase CDC Connector。
ChunJun & OceanBase 应用
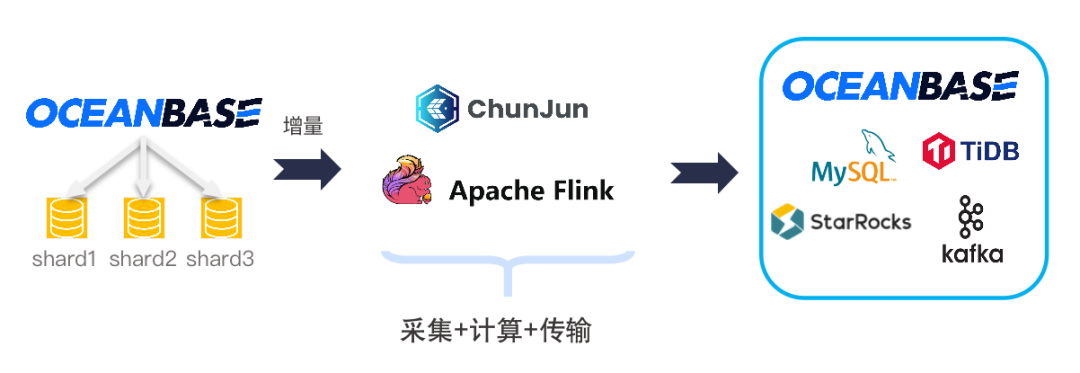
场景1:针对分库分表的实时数据集成
使用 Oceanbase CDC Connector,库表名利用Fnmatch通配,实现分库分表数据源的实时数据集成。这个场景可以做增量同步,也可以做单数据流的ETL操作。
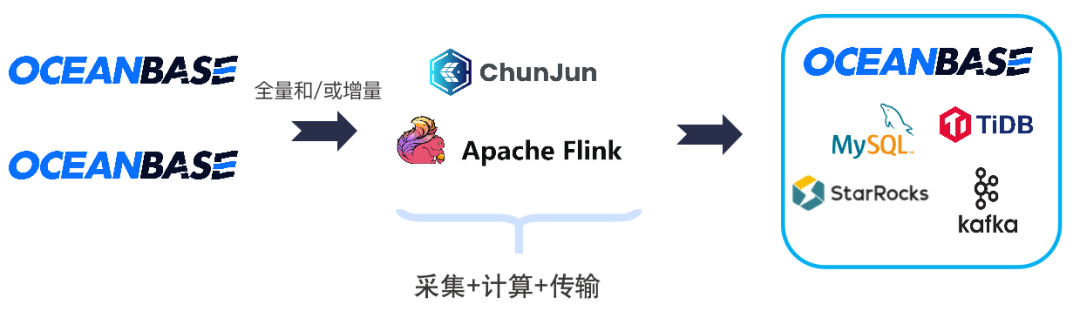
场景2:跨集群/租户的数据集成
目前,不同租户的数据在一个连接当中获取不到,如果想对OB当中不同租户的数据做一个统一处理,需通过多个数据库的连接来实现分别读取,这时可以利用ChunJun中与OceanBase相关的connector,读取不同集群、租户数据到 Flink。
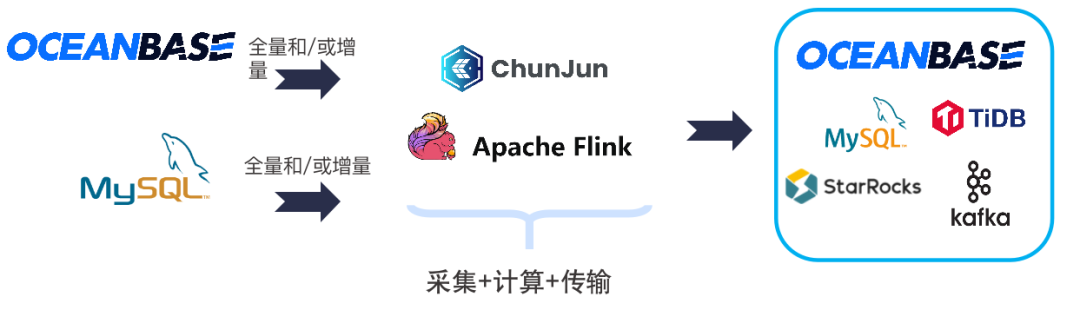
场景3:不同数据源的实时数据集成
可以对不同种类数据源进行数据汇聚,使用不同类型数据库的 connector,读取不同数据源的数据到 Flink。
场景4:日志类型数据的全增量一体化处理
对于只有 insert 增量变动的数据源,基于自增列进行全增量一体化的处理。
ChunJun&OceanBase未来展望
● 提高代码质量
· 增加测试 case,覆盖所有的启动方式和常见的业务场景
· 完全适配 MySQL 5.1.4x 和 8.0 驱动
● 20+种丰富的任务类型
· 增加非 transformer 模式 sync 任务的支持
· 增加 OceanBase 企业版 Oracle 模式的支持
● 提高方案可靠性
· 增加数据读取的事务性支持
· 简化 oblogproxy 的部署,支持 Docker 部署
· 增加详细的使用文档
袋鼠云开源框架钉钉技术交流qun(30537511),欢迎对大数据开源项目有兴趣的同学加入交流最新技术信息,开源项目库地址:https://github.com/DTStack/Taier
ChunJun&OceanBase联合方案首次发布:构建一体化数据集成方案的更多相关文章
- DataPipeline丨构建实时数据集成平台时,在技术选型上的考量点
文 | 陈肃 DataPipeline CTO 随着企业应用复杂性的上升和微服务架构的流行,数据正变得越来越以应用为中心. 服务之间仅在必要时以接口或者消息队列方式进行数据交互,从而避免了构建单一数 ...
- CDC+ETL实现数据集成方案
欢迎咨询,合作! weix:wonter 名词解释: CDC又称变更数据捕获(Change Data Capture),开启cdc的源表在插入INSERT.更新UPDATE和删除DELETE活动时会插 ...
- 深耕教育行业,RealSeer联合黑晶科技发布“AR超级教室”
近日,RealSeer开发者大赛见面会最后一站在北京举行,现场云集了不少AR创业者和开发者,各位大咖嘉宾都拿出干货与大家分享交流,公话未来AR行业发展趋势.现场RealMax联合黑晶科技发布了新品&q ...
- Hadoop生态圈-构建企业级平台安全方案
Hadoop生态圈-构建企业级平台安全方案 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 能看到这篇文章的小伙伴,估计你对大数据集群的部署对于你来说应该是手到擒来了吧.我之前分享过 ...
- 正确创建本地C++发布构建PDBS
在调试版本中遇到的一个问题是编译本地的C++应用程序.例如,许多局部变量消失了,因为代码生成器没有将它们放在堆栈上,而是将它们放在寄存器中,就像在调试生成中发生的那样.此外,release积极地构建对 ...
- 深度对比Apache CarbonData、Hudi和Open Delta三大开源数据湖方案
摘要:今天我们就来解构数据湖的核心需求,同时深度对比Apache CarbonData.Hudi和Open Delta三大解决方案,帮助用户更好地针对自身场景来做数据湖方案选型. 背景 我们已经看到, ...
- 用Apache Kafka构建流数据平台的建议
在<流数据平台构建实战指南>第一部分中,Confluent联合创始人Jay Kreps介绍了如何构建一个公司范围的实时流数据中心.InfoQ前期对此进行过报道.本文是根据第二部分整理而成. ...
- 用Apache Kafka构建流数据平台
近来,有许多关于“流处理”和“事件数据”的讨论,它们往往都与像Kafka.Storm或Samza这样的技术相关.但并不是每个人都知道如何将这种技术引入他们自己的技术栈.于是,Confluent联合创始 ...
- <自动化测试方案_9>第九章、持续集成平台搭建
第九章.持续集成平台搭建 (一)什么是持续集成 参考文章地址:https://blog.csdn.net/qq_32261399/article/details/76651376 敏捷软件开发(英语: ...
- 痞子衡嵌入式:kFlashFile v1.0 - 一个基于Flash的掉电数据存取方案
大家好,我是痞子衡,是正经搞技术的痞子.今天给大家带来的是痞子衡的个人小项目 - kFlashFile. 痞子衡最近在参与一个基于 i.MXRT1170 的项目,项目有个需求,需要在 Flash 里实 ...
随机推荐
- DNS+scapy学习
DNS前置知识 大部分介绍转自这篇文章. 官方解释: DNS ( Domain Name System ,域名系统) ,因特网上作为域名和IP地址相互映射的一个分布式数据库,能够使用户更方便的访问互联 ...
- Tiki靶机练习
Scan 先arp-scan -l扫描附件主机ip nmap -sS -sV -n -T4 -p- 192.168.93.132 Starting Nmap 7.94SVN ( https://nma ...
- 分析 AIX 和 Linux 性能的免费工具。
一.软件介绍1.分析工具nmon 工具可以帮助在一个屏幕上显示所有重要的性能优化信息,并动态地对其进行更新.这个高效的工具可以工作于任何哑屏幕.telnet 会话.甚至拨号线路.另外,它并不会消耗大量 ...
- Delphi 判断操作系统是32位或是64位
function IsWin64: Boolean; var Kernel32Handle: THandle; IsWow64Process: function(Handle: Windows.THa ...
- 【Unity】改变游戏运行时Window的窗口标题
[Unity]改变游戏运行时Window的窗口标题 零.需求 Unity打包好的Windows程序,启动后如何更改窗口标题?因为看着英文的感觉不太好,故有此想法.什么?你说为啥不改项目产品名?产品名会 ...
- python调用百度ocr接口,实现图片内文字识别
第一步,到百度智能云申请接口资源 打开地址:https://cloud.baidu.com/?from=console,点击产品下的通用场景文字识别 立即使用,跳转页领取免费资源(土豪可直接购买) 选 ...
- 请详细描述 MySQL 的 B+ 树中查询数据的全过程
MySQL 的 B+ 树中查询数据的全过程 在 MySQL 中,B+ 树被广泛用于实现索引,特别是 InnoDB 存储引擎中的聚簇索引.B+ 树是一种平衡树,具有良好的查询性能.本文将详细描述在 B+ ...
- 你常用哪些工具来分析 JVM 性能?
常用的 JVM 性能分析工具 JVM 性能分析工具主要用于监控.调试和优化 Java 程序的性能,尤其是在垃圾回收.内存泄漏.线程调度等方面.以下是一些常用的 JVM 性能分析工具: 1. jvisu ...
- vscode配置xdebug断点调试thinkphp
vscode配置xdebug断点调试thinkphp其实和配置其他php框架的断点调试一样,步骤如下: 下载xdebug,重命名为php_xdebug.dll并移动到php.ini目录: (不知道下载 ...
- 暂时永久免费高配云服务可跑32b模型
谷歌IDX免费云主机,16核CPU,64G内存,300G硬盘! 需要谷歌账号一个,且能google,无需绑卡. 到手第一时间安装一个ollama+qwen2.5-coder:32b, 无限cursor ...