强化学习:如何计算被环境系统截断的terminated state的value值 —— (Bootstrap returns from value estimates if episode is terminated by timeout)
本文主题:如何计算强化学习中被环境系统截断的terminated state的value值
首先解释一下什么是强化学习中的terminated state的value值,强化学习就是一个智能体(agent)不断和环境交互的过程,而这个交互的过程分为无限步数和有限步数,即使面对有限步数的情况下往往由于步数过长我们也是将其视作无限步数的情况来对待处理的,也正是因此我们才需要对agent与环境的交互过程进行截断,于是便有了截断的terminated state的value值。
被截断的状态,即episode的最后一个状态的state的value值就是截断的terminated state的value值。
对待该问题的讨论分为两个情况,一种是非并行采样的情况,即agent与环境的交互是非并行的,另一种则是并行采样的情况。
串行采样(交互)/非并行情况:
环境系统返回给agent的截断terminated state是真实的 terminated state,此时我们可以根据state value的状态值估计函数获得估计值,比如在actor-critic算法总critic部分的拟合函数给出的值;但是在很多论文中在这种串行的环境下很多时候是不对terminated state是否被环境系统截断作区分的,如果这个terminated state是episode的自然结束的state,那么对应的state value为0,如果\(s_{t+1}\)是episode自然结束的state,那么\(v(s_{t+1})=0\),那么对应\(v(s_t)\)的计算则为\(v(s_t)=v(s_t)+[\alpha*(r+v(s_{t+1})-v(s_t)]\),即\(v(s_t)=v(s_t)+[\alpha*(r-v(s_t)]\),而如果对截断作区分的话那么截断的terminated state的\(V\)值就需要拟合函数的计算获得,即\(v(s_{t+1})\neq0\),从而有\(v(s_t)=v(s_t)+[\alpha*(r+v(s_{t+1})-v(s_t)]\)。
个人在处理这个问题的时候习惯于不对截断的terminated state作区分,也就是默认认为terminated state的\(V\)值为0,并且该种处理方法在多种论文和代码实现上均被采用,当然这样做就会导致一个问题,那就是不对截断的terminated state区分必然导致在强化学习算法计算过程中人为因素的引入多余偏差,而至于这种偏差是否会导致算法性能变差也并没有系统的研究论文。
不过必须要说的是,虽然做串行采样的论文是不对截断状态作区分的,但是有一小群的人却坚持对截断的terminated state作区分,并坚持使用这种减少方差的方法。
说下个人观点:
对不对这个截断的terminated state作区分主要看这个不作区分的话对算法性能是否有影响,如果这个episode的长度比较长,比如一个episode的长度是50,100,更或者是200,并且被截断的状态数量所占比例不是很高,那么不对截断的terminated state作区分也不会对算法性能有太多影响;但是如果episode长度比较短,比如步数在5步内,10步内这种,并且大比例的episode的最终状态是被截断的,并且截断的状态很有可能在其他的episode中以非终点状态的形式出现,那么不对截断的terminated state作区分就会明显影响强化学习算法性能。不过以我个人的经验来说,极少会遇到episode长度短,并且episode的最终状态大比例的是截断的terminated state,因此在我个人的应用环境背景下来说不对截断的terminated state作区分是完全可以接受和允许的。
并行采样(交互)/并行情况:
该种情况下与串行的情况最大的不同在于各大强化学习算法框架和加速库为了追求更高的计算效率和编码的模块性,于是把episode的初始化放在了并行环境的自动处理的环节中,也就是说该种情况下强化学习计算框架默认不返回信息显示状态是否为episode的最终结尾状态还是截断的terminated state,并且在不区分episode的最终状态和截断的terminated state的同时在返回状态信息时会自动返回下一个episode初始化时的状态;并且即使有的算法框架在自动对环境进行重新初始化并返回新episode的初始state的同时会返回上一个episode是否是被截断的信息,比如在返回的info信息中带有is_timeout的信息,如果这个字段为true,那么意味着上个episode的结束是被环境截断的,如果在done=true的同时is_timeout=false那么则意味着上个episode是自然终止的而不是因为超时而被环境截断的。
在强化学习的经典环节cart-pole的小车平衡杆问题中默认的limited time=200,也就是说如果一个episode的步数/长度小于200,那么这个episode必然是自然终止的,但是如果episode长度为200,那么大概率是被环境截断的,至于是不是一定是被环境截断的就需要看info信息中是否有is_timeout的信息。
本文讨论的并行采样的情况下是基于上述的并行强化学习算法的背景的,也就是说不论上一个episode是自然结束还是被环境截断的,返回的next state均为下一个episode的初始状态。
关于并行采样情况下如何处理截断状态的\(V\)值,本文根据下面资料进行展开:
Bootstrap returns from value estimates if episode is terminated by timeout. More info here: https://github.com/Denys88/rl_games/issues/128
注意,以下内容讨论的都是并行采样情况下区分截断的terminated state,如果不区分的话那么和串行采样时一样可以将最终state的\(V\)值设置为0,并且要说明一点,那就是在并行采样的强化学习环境中大多数的环境都不太会进行环境截断的,比如mujoco环境,大多数情况下和串行采样时一样都不对截断环境作区分的,因为像mujoco这样的高难度仿真环境里面episode的结束往往都是因为自然结束而不是被环境截断,毕竟环境难道大,算法难以大比例的进入到需要环境截断的情况。
对于一些特定的环境问题,被环境截断是有一定比例,因此这种情况下就需要对截断状态作区分的。
地址:
https://github.com/Denys88/rl_games/issues/128
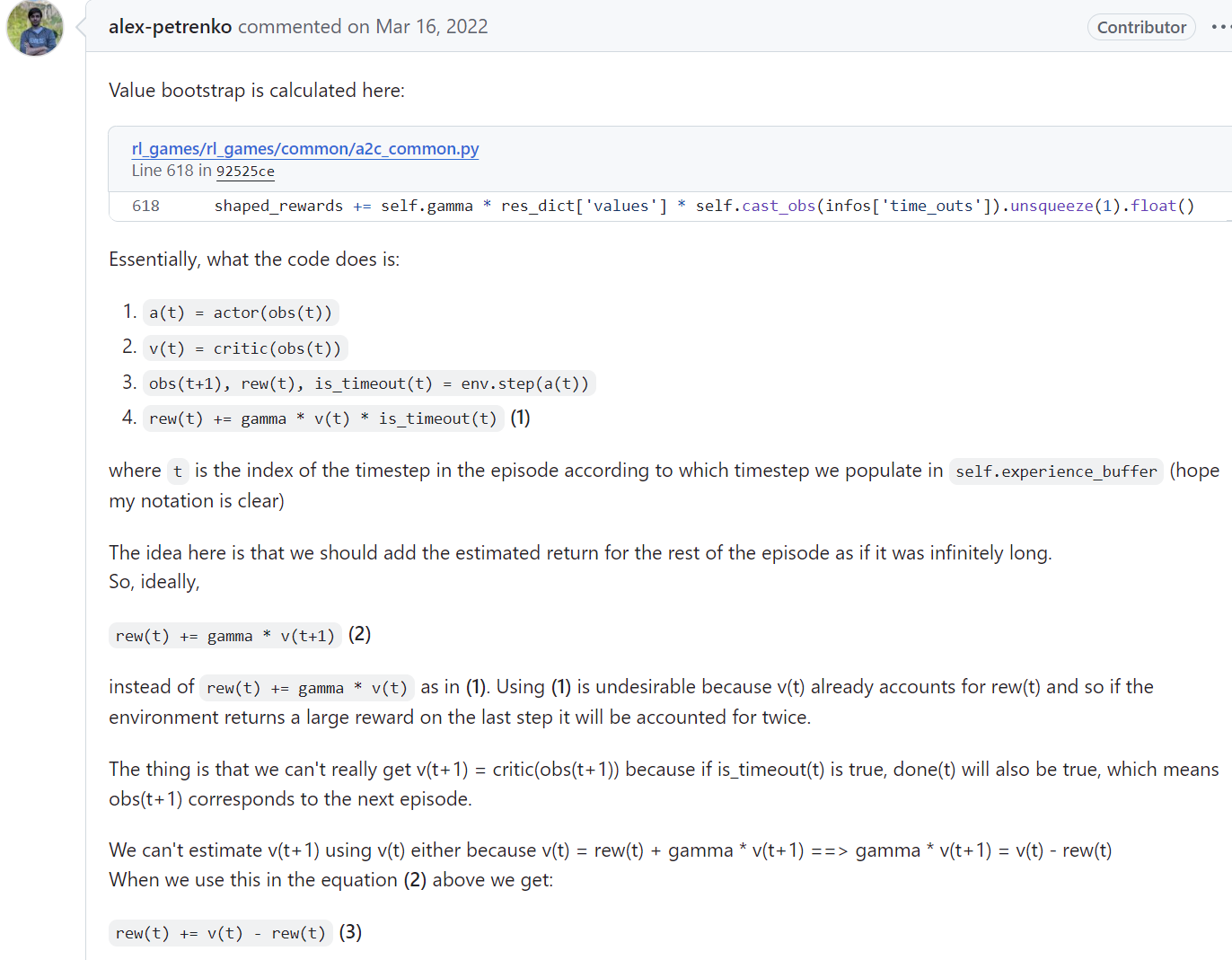

这里主要是讨论上面这个GitHub上的一个讨论帖子,这个帖子就并行采样时如何处理在区分terminated state时处理\(is\_timeout=true\)时的episode最后状态的\(V\)值。之前已经交代过,在并行采样的过程中默认的在episode结束时环境系统自动进行初始化,此时返回的\(next\_state\)其实是下一个episode的初始state。尤其在强化学习算法训练学习时需要进行bootstrap returns from value estimates,而这时是需要获得episode结束时的最后一个状态,也就是说在episode的\(done=true\)时,不论episode是否被截断其最后一个状态都需要返回的,但是由于在并行采样时为了提高并行采样的效率都是默认在episode结束时自动初始化并返回新episode的初始state的,因此无法满足bootstrap计算时的要求的。
为了解决在并行采样时大多数强化学习算法设计时为提高计算效率而不返回episode最后state的问题所导致无法正确使用bootstrap方法计算value return的问题,上面帖子中给出了https://github.com/Denys88/rl_games/blob/92525ce54da0c8a6f60c9d3f88e21ef47e5b24e7/rl_games/common/a2c_common.py#L618中的一个解决方法,那就是使用episode最后状态的前一个状态进行计算,也就是上面帖子中不使用\(V(s_{t+1})\)而是使用\(V(s_t)\)进行计算,该种方法在episode最后一步返回的reward较小时不会带来明显的计算偏差,但是如果在episode的最后一步的reward值较大的情况下,那么就必然导致\(V(s_{t+1})\)和\(V(s_t)\)之间有较大差距,这样情况下使用\(V(s_t)\)近似替代\(V(s_{t+1})\)进行bootstrap return计算就会带来较大的计算偏差;同时帖子中也分析了在不改变并行采样时自动初始化下个episode并返回新episode初始状态来替代之前episode结束时的状态的这种方法是无法避免这种计算偏差的,即使episode最后一步的reward比较平滑也无法真正避免这种偏差,因此真正的避免该偏差的方法就是对episode最后一个状态进行返回和出来,如下面中的做法:
由于根据bootstrap value的计算方法可以知道:
\(v(s_{t})=r_{last\_step}+\gamma*v(s_{t+1})\)
因此episode最后一步reward平滑是指
\(v(s_{t}) \approx r_{last\_step}+\gamma*v(s_t)\)
那么也就是说最后一步reward平滑时
$r_{last_step} \approx (1 - \gamma)*v(s_{t}) $
因此必有:
\(v(s_{t}) \approx r_{last\_step}/(1 - \gamma)\)
又由于:
\(v(s_{t}) = r_{last\_step}+\gamma*r_{last\_step+1}+{\gamma}^2*r_{last\_step+1}+{\gamma}^3*r_{last\_step+2}+......\)
可以得到:
\(r_{last\_step} \approx \frac{(1 - \gamma)}{\gamma} * (\gamma*r_{last\_step+1}+{\gamma}^2*r_{last\_step+1}+{\gamma}^3*r_{last\_step+2}+......)\)
而上面的这个表达就是在进行bootstrap value计算时使用后一个state替代前一个state时低偏差所要求的reward的平滑形式。
在实际的应用问题中,能完美符合上面的这种平滑形式的还是比较少的,但是一般待解决的问题的episode长度较长,从而导致根据episode最后一个state的\(V\)值进行bootstrap value计算的比例在总的计算样本中的比例占比较少,因此在多数问题中episode的最后一个state的\(V\)估计值即使有偏差也并不会造成算法计算过程中的明显偏差,因此在很多的并行强化学习算法采样时是不对该问题进行处理的。
强化学习:如何计算被环境系统截断的terminated state的value值 —— (Bootstrap returns from value estimates if episode is terminated by timeout)的更多相关文章
- 深度强化学习 之 运行环境 mujoco 报错 ERROR: GLEW initalization error: Missing GL version
使用 mujoco环境 运行代码,报错 ERROR: GLEW initalization error: Missing GL version 一直无法解决,发现网址: https://blog. ...
- 基于C#的机器学习--惩罚与奖励-强化学习
强化学习概况 正如在前面所提到的,强化学习是指一种计算机以“试错”的方式进行学习,通过与环境进行交互获得的奖赏指导行为,目标是使程序获得最大的奖赏,强化学习不同于连督学习,区别主要表现在强化信号上,强 ...
- 深度强化学习资料(视频+PPT+PDF下载)
https://blog.csdn.net/Mbx8X9u/article/details/80780459 课程主页:http://rll.berkeley.edu/deeprlcourse/ 所有 ...
- 强化学习一:Introduction Of Reinforcement Learning
引言: 最近和实验室的老师做项目要用到强化学习的有关内容,就开始学习强化学习的相关内容了.也不想让自己学习的内容荒废掉,所以想在博客里面记载下来,方便后面复习,也方便和大家交流. 一.强化学习是什么? ...
- AI之强化学习、无监督学习、半监督学习和对抗学习
1.强化学习 @ 目录 1.强化学习 1.1 强化学习原理 1.2 强化学习与监督学习 2.无监督学习 3.半监督学习 4.对抗学习 强化学习(英语:Reinforcement Learning,简称 ...
- 强化学习(十八) 基于模拟的搜索与蒙特卡罗树搜索(MCTS)
在强化学习(十七) 基于模型的强化学习与Dyna算法框架中,我们讨论基于模型的强化学习方法的基本思路,以及集合基于模型与不基于模型的强化学习框架Dyna.本文我们讨论另一种非常流行的集合基于模型与不基 ...
- David Silver强化学习Lecture2:马尔可夫决策过程
课件:Lecture 2: Markov Decision Processes 视频:David Silver深度强化学习第2课 - 简介 (中文字幕) 马尔可夫过程 马尔可夫决策过程简介 马尔可夫决 ...
- 强化学习(Reinforcement Learning)中的Q-Learning、DQN,面试看这篇就够了!
1. 什么是强化学习 其他许多机器学习算法中学习器都是学得怎样做,而强化学习(Reinforcement Learning, RL)是在尝试的过程中学习到在特定的情境下选择哪种行动可以得到最大的回报. ...
- 强化学习之六:Deep Q-Network and Beyond
本文是对Arthur Juliani在Medium平台发布的强化学习系列教程的个人中文翻译,该翻译是基于个人分享知识的目的进行的,欢迎交流!(This article is my personal t ...
- 强化学习实战 | 自定义Gym环境之扫雷
开始之前 先考虑几个问题: Q1:如何展开无雷区? Q2:如何计算格子的提示数? Q3:如何表示扫雷游戏的状态? A1:可以使用递归函数,或是堆栈. A2:一般的做法是,需要打开某格子时,再去统计周围 ...
随机推荐
- AtCoder Beginner Contest 311
Toyota Programming Contest 2023#4(AtCoder Beginner Contest 311) A - First ABC (atcoder.jp) 记录一下\(ABC ...
- 安装 yarn 和 pnpm
yarn 2 和 pnpm 都是使用 Corepack 管理的,Corepack 是一个管理包管理器的工具.你可以在 Corepack 官网查看相关介绍. 首先启用 Corepack: corepac ...
- Https通信的SSL证书工作流程原理(转)
前言 浏览器与服务器之间的https加密通信会包括以下一些概念:非对称加密.对称加密.RSA.证书申请.根证书.https证书加密,就是在传输层tcp和应用层http之间加了一层ssl层来对传输内容进 ...
- Python 在PDF中添加条形码、二维码
在PDF中添加条码是一个常见需求,特别是在需要自动化处理.跟踪或检索PDF文件时.作为一种机器可读的标识符,PDF中的条码可以包含各种类型的信息,如文档的唯一标识.版本号.日期等.以下是一篇关于如何使 ...
- 2023/11/16 NOIP 模拟赛
T1 基于1的算术 标签 暴力枚举 思路1 赛时想了个假的 DP,只拿了 77 分,,, 小于 \(10^{15}\) 的仅由 \(1\) 组成的数只有 \(15\) 个,直接枚举即可. 想了一个做法 ...
- SimCLR: 一种视觉表征对比学习的简单框架《A Simple Framework for Contrastive Learning of Visual Representations》(对比学习、数据增强算子组合,二次增强、投影头、实验细节很nice),好文章,值得反复看
现在是2024年5月18日,好久没好好地看论文了,最近在学在写代码+各种乱七八糟的事情,感觉要和学术前沿脱轨了(虽然本身也没在轨道上,太菜了),今天把师兄推荐的一个框架的论文看看(视觉CV领域的). ...
- TypeScript 高级教程 – TypeScript 类型体操 (第三篇)
前言 在 第一部 – 把 TypeScript 当强类型语言使用 和 第二部 – 把 TypeScript 当编程语言使用 后, 我们几乎已经把 TypeScript 的招数学完了. 第三部就要开始做 ...
- Git 客户端基本使用及新手常见问题
Git作为一个版本管理工具,在企业中的应用越来越普遍.作为一个测试工程师,不可避免会需要接触到Git的相关操作,以下整理Git客户端的常见操作,以及应用中新手常碰到的一些问题. 1.环境安装及配置 G ...
- SpringMVC —— 入门案例执行流程
启动服务器初始化过程 1.服务器启动,执行ServletContainersInitConfig类,初始化web容器 2.执行createServletApplicationContext方法, ...
- CodeMaid:一款基于.NET开发的Visual Studio代码简化和整理实用插件
前言 今天大姚给大家分享一款由.NET开源.免费.强大的Visual Studio代码简化.整理.格式化实用插件:CodeMaid. 工具介绍 CodeMaid是一款由.NET开源.免费.强大的Vis ...