探索 LanceDB 在多种存储方案下的查询效率
随着 LLM 和多模态 AI 的兴起,非结构化数据的规模呈指数级增长,这对数据存储、检索和分析提出了更高的要求。LanceDB 是 AI 原生多模态数据湖产品,采用自研的开源数据格式 Lance,以解决传统数据格式在大规模非结构化数据场景中的局限性,已被多家 AI 公司,如 Runway 和 Midjourney 等采纳。
LanceDB 在存储后端方面提供了多种选择,以满足用户在成本、延迟、可扩展性和可靠性方面的不同需求。近期,我们对 LanceDB 在不同存储方案中的性能进行了测试,测试涵盖 JuiceFS、本地 NVMe、AWS EBS、EFS、FSx for Lustre 等方案。结果表明,JuiceFS 在性能上优于 AWS EFS 和 FSx for Lustre,接近 EBS,能够稳定支持 LanceDB 的查询。
01 项目简介
LanceDB 概述
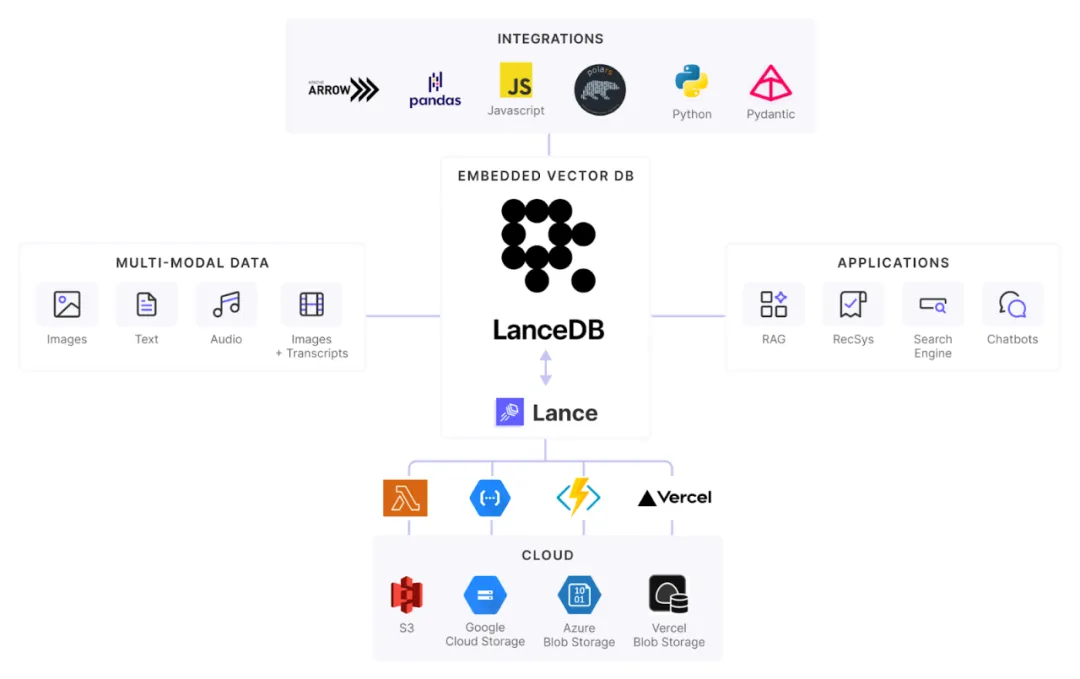
LanceDB 是一个专为多模态数据设计的高性能向量数据库,旨在高效管理和搜索大规模的向量数据,特别适合用于 AI/ML 等应用场景,尤其是在多模态数据(如图像与文本嵌入)场景。
JuiceFS 概述
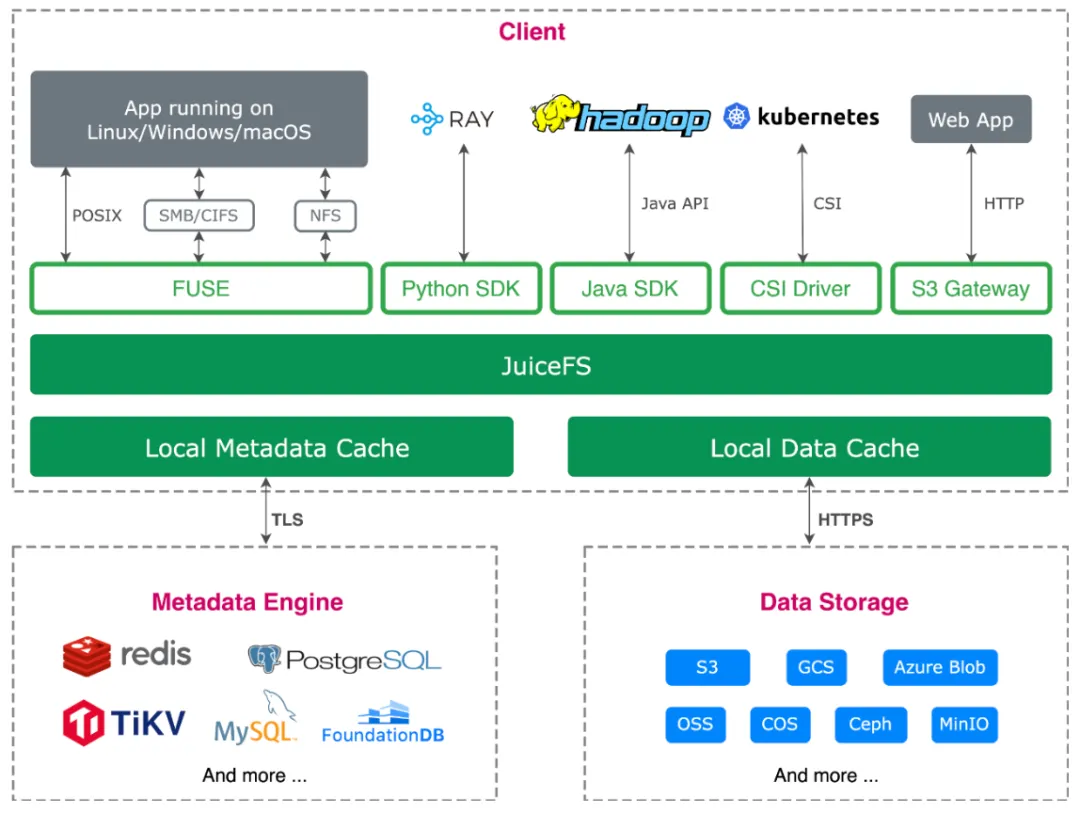
JuiceFS 是一个为云原生环境设计的分布式 POSIX 文件系统。它采用元数据与数据分离架构,从而实现了对跨多个存储后端的大型数据集的高效管理。JuiceFS 提供了极高的可扩展性,适用于需要多个节点并行访问数据的场景,如大规模的 AI/ML 工作负载。
02 多模态数据集测试
在本次测试中,我们的主要评估 JuiceFS 与多种存储介质,在性能上的差异。我们所使用的 multimodal_clip_diffusiondb 数据集包含大约 5.8GB 的多模态数据(例如图像和文本嵌入)。测试通过运行 100 条不同的查询请求,比较在不同存储方案下的查询性能。测试代码和数据可以在此链接中找到。
数据表模式如下:
prompt: string
seed: uint32
step: uint16
cfg: float
sampler: string
width: uint16
height: uint16
timestamp: timestamp[s]
image_nsfw: float
prompt_nsfw: float
vector: fixed_size_list<item: float>[512]
child 0, item: float
image: binary
测试步骤如下:
- 将数据集位置更新为测试目标的本地路径(例如,JuiceFS 的挂载路径,或 EFS 或 FSx for Lustre)。
- 启动
multimodal_clip_diffusiondb作为 HTTP 服务,获取来自服务器的100 个不同提示词,并将其保存为 JSON 文件。
以下是一个 JSON 文件示例:
$ cat close.json
{
"data": [
"close"
],
"event_data": null,
"fn_index": 0,
"session_hash": "ejnrxozcc9l"
}
- 使用脚本并行调用全文搜索 API,执行 100 个不同关键词的查询请求。实际效果等同于运行下方代码中的逻辑。
$ cat run.sh:
#!/bin/bash
for i in data/*.json
do
curl 'http://127.0.0.1:7860/run/predict' -X POST -H 'User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:130.0) Gecko/20100101 Firefox/130.0' -H 'Accept: */*' -H 'Accept-Language: en-CA,en-US;q=0.7,en;q=0.3' -H 'Accept-Encoding: gzip, deflate, br, zstd' -H 'Referer: http://127.0.0.1:7860/' -H 'Content-Type: application/json' -H 'Origin: http://127.0.0.1:7860' -H 'Connection: keep-alive' -H 'Sec-Fetch-Dest: empty' -H 'Sec-Fetch-Mode: cors' -H 'Sec-Fetch-Site: same-origin' -H 'Priority: u=0' -H 'Pragma: no-cache' -H 'Cache-Control: no-cache' --data @$i
done
查询服务背后的访问代码:
import lancedb
db = lancedb.connect('~/datasets/demo')
tbl = db.open_table('diffusiondb')
tbl.search('{query}').limit(9).to_df()
03 测试结果
我们将 LanceDB 数据集复制到多个存储位置进行测试:
- 本地 NVMe 存储:数据存储在本地 PCIe 4.0x4 NVMe SSD 上。
- EBS(弹性块存储)
- JuiceFS
- AWS EFS(Elastic File System)
- AWS FSx for Lustre:1.2TB、3000MB/s 规格。
以下是使用不同存储配置下查询完成所需时间:
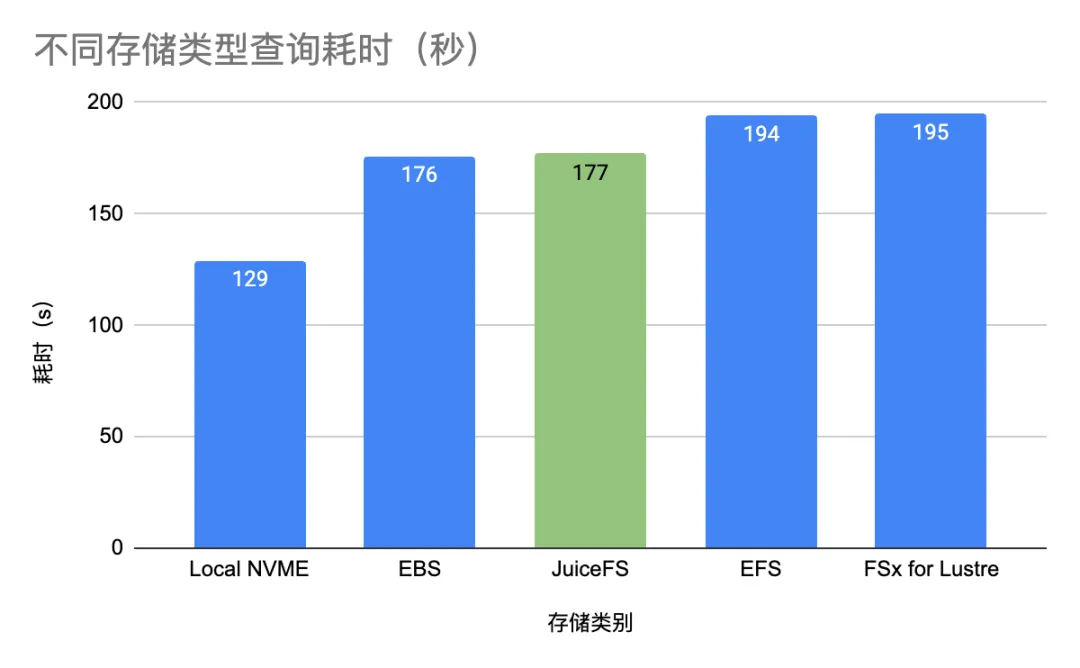
- 本地 NVMe 性能最佳,为 129 秒。
- JuiceFS 性能接近 EBS:JuiceFS 的查询耗时为 177 秒,略高于 EBS 的 176 秒。
- EFS 和 FSx for Lustre 的查询耗时分别为 194 秒和 195 秒,明显高于 JuiceFS 和 EBS。
04 小结
通过本次测试,我们验证了 LanceDB 在结合不同存储方案下的实际查询性能表现。JuiceFS 相比 AWS EFS 和 FSx for Lustre 有更好的性能。
JuiceFS 提供了出色的可扩展性和云原生适应性,满足分布式 AI/ML 应用对高效存储和数据访问的需求。对于大规模数据集、跨多个节点共享数据以及进行高并发查询的应用,JuiceFS + LanceDB 是一个值得探索的解决方案。
探索 LanceDB 在多种存储方案下的查询效率的更多相关文章
- mysql中存储字段类型的查询效率
检索性能从快到慢的是(此处是听人说的): 第一:tinyint,smallint,mediumint,int,bigint第二:char,varchar第三:NULL 解释(转载): 整数类型1.TI ...
- 浅谈PageHelper插件分页实现原理及大数据量下SQL查询效率问题解决
前因:项目一直使用的是PageHelper实现分页功能,项目前期数据量较少一直没有什么问题.随着业务扩增,数据库扩增PageHelper出现了明显的性能问题.几十万甚至上百万的单表数据查询性能缓慢,需 ...
- 莱特币ltc在linux下的多种挖矿方案详解
莱特币ltc在linux下的多种挖矿方案详解 4.0.1 Nvidia显卡Linux驱动Nvidia全部驱动:http://www.nvidia.cn/Download/index.aspx?lang ...
- Linux 下的两种分层存储方案
背景介绍 随着固态存储技术 (SSD),SAS 技术的不断进步和普及,存储介质的种类更加多样,采用不同存储介质和接口的存储设备的性能出现了很大差异.SSD 相较于传统的机械硬盘,由于没有磁盘的机械转动 ...
- Android Learning:数据存储方案归纳与总结
前言 最近在学习<第一行android代码>和<疯狂android讲义>,我的感触是Android应用的本质其实就是数据的处理,包括数据的接收,存储,处理以及显示,我想针对这几 ...
- [转]App离线本地存储方案
App离线本地存储方案 原文地址:http://ask.dcloud.net.cn/article/166 HTML5+的离线本地存储有如下多种方案:HTML5标准方案:cookie.localsto ...
- MySQL不同存储引擎下optimize的用法
optimize命令是mysql的常用优化命令,但是在InnoDB与MyISAM这两个存储引擎中却有很大的分别.本文将对这两个常用的存储引擎进行区分跟实例解析 1.查看mysql当前的存储引擎 一般情 ...
- Github 29K Star的开源对象存储方案——Minio入门宝典
对象存储不是什么新技术了,但是从来都没有被替代掉.为什么?在这个大数据发展迅速地时代,数据已经不单单是简单的文本数据了,每天有大量的图片,视频数据产生,在短视频火爆的今天,这个数量还在增加.有数据表明 ...
- Redis百亿级Key存储方案(转)
1 需求背景 该应用场景为DMP缓存存储需求,DMP需要管理非常多的第三方id数据,其中包括各媒体cookie与自身cookie(以下统称supperid)的mapping关系,还包括了supperi ...
- MongoDb gridfs-ngnix文件存储方案
在各类系统应用服务端开发中,我们经常会遇到文件存储的问题. 常见的磁盘文件系统,DBMS传统文件流存储.今天我们看一下基于NoSQL数据库MongoDb的存储方案.笔者环境 以CentOS ...
随机推荐
- Node v18.6 发布的这个新特性未来可能改变前端工程化
@charset "UTF-8"; .markdown-body { line-height: 1.75; font-weight: 400; font-size: 15px; o ...
- 一款基于 .NET 开源、可以拦截并修改 WinSock 封包的 Windows 软件
前言 今天大姚给大家分享一款基于 .NET 开源(MIT license).可以拦截并修改 WinSock 封包的 Windows 软件:WinsockPacketEditor. 工具介绍 Winso ...
- Qt图像处理技术七:轮廓提取
Qt图像处理技术七:轮廓提取 效果图 原理 图像先二值化让rgb数值相同,只有(0,0,0)或者(255,255,255) 取每个点的周围8个点,如果周围8个点与该点rgb值相同,则需要将该点描黑为( ...
- 如何实现本地大模型与MCP集成
1.概述 本文将围绕构建兼具本地运行大型语言模型(LLM)与MCP 集成能力的 AI 驱动工具展开,为读者提供从原理到实践的全流程指南.通过深度整合本地大模型的隐私性.可控性优势与 MCP 工具的自动 ...
- MySQL-Canal-Kafka数据复制详解
摘要 MySQL被广泛用于海量业务的存储数据库,在大数据时代,我们亟需对其中的海量数据进行分析,但在MySQL之上进行大数据分析显然是不现实的,这会影响业务系统的运行稳定.如果我们要实时地分析这些数据 ...
- MySQL 情节:SQL 语句的表演
本文由 ChatMoney团队出品 第一幕:解析与优化 - "翻译官与谋士" SQL 解析器是第一个上场的角色,任务就是把 SQL 请求翻译成 MySQL 能听懂的语言.就像你点餐 ...
- Linux安装最新Erlang、RabbitMQ
进入RabbitMQ官网 简介: RabbitMQ是一个免费的开源企业消息代理软件. 它是用Erlang编写的,并实现了高级消息队列协议(AMQP). 它提供所有主要编程语言的客户端库. 它支持多种消 ...
- JavaScript的"数值计算困局":生态缺位下的破局之路
本文原创首发于公众号[我做开发那些年]与网站[乔文小屋],现同步转载至本平台,点击阅读原文 声明:如需转载本文至其他平台,请注明文章来源及公众号信息,感谢您对原创内容的尊重与支持! *背景*:最近在尝 ...
- java Set HashSet详解
Set集合 就像把对象随意扔进罐子里,无法记住元素的添加顺序.Set某种程度就是Collection,方法没有不同,只是行为稍微不同,(不允许重复元素),如果一定要往里加两个相同元素,添加失败add( ...
- vite使用短链接
增加改配置项 vite.config.js import { defineConfig } from 'vite' import vue from '@vitejs/plugin-vue' impor ...