Python进阶5---StringIO和BytesIO、路径操作、OS模块、shutil模块
StringIO

StringIO操作


BytesIO

BytesIO操作

file-like对象

路径操作
路径操作模块
3.4版本之前:os.path模块

3.4版本开始
建议使用pathlib模块,提供Path对象来操作。包括目录和文件
pathlib模块
from pathlib import Path
目录操作
初始化

路径拼接和分解

#在windows下的Pycharm中运行
p = Path()
print(type(p)) #<class 'pathlib.WindowsPath'>
p = p / 'a'
print(p) #a
p1 = 'b' / p
print(p1) #b\a
p2 = Path('c')
p3 = p2 / p1
print(p3) #c\b\a
print(p3.parts) #('c', 'b', 'a')
print(p3.joinpath('etc','init.d',Path('httpd'))) #c\b\a\etc\init.d\httpd

p = Path('/etc')
print(str(p),bytes(p))

p = Path('/a/b/c/d')
print(p.parent.parent)
for x in p.parents:
print(x)

#四个属性,两个方法
p = Path('E:\learnshare\ArticleSpider\e.xex.txt')
print(p.name) #e.xex.txt
print(p.stem) #e.xex
print(p.suffix) #.txt
print(p.suffixes) #['.xex','.txt']
print(p.with_name('c.y'))#E:\learnshare\ArticleSpider\c.y
print(p.with_suffix('.xxyy'))#E:\learnshare\ArticleSpider\e.xex.xxyy



调用iterdir()方法后返回一个生成器对象



通配符
glob(pattern)通配给定的模式
rglob(pattern)通配给定的模式,递归目录
from pathlib import Path
print(1,list(Path().glob('test*')))#返回当前目录对象下的test开头的文件
print(2,list(Path().glob('*/test*')))#返回当前目录的下一级目录以test开头的文件
print(3,list(Path().glob('**/test*')))#递归当前目录以及其下所有目录,返回以test开头的文件
print(4,list(Path().rglob('test*')))#同上一样
匹配
match(pattern)
模式匹配,成功返回True

文件操作



OS模块


fd表示文件描述符


shutil模块
到目前为止
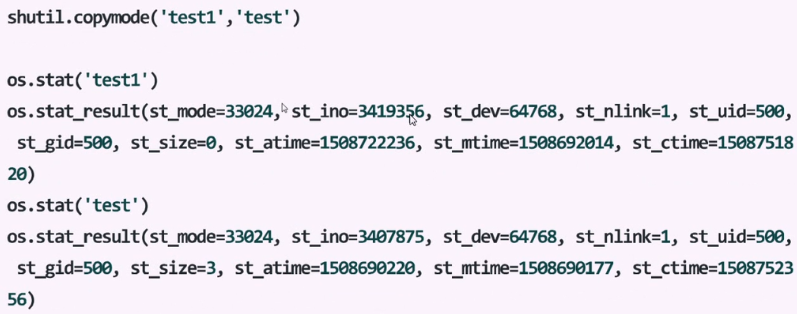
文件拷贝:使用打开2个文件对象,源文件读取内容,写入目标文件中来完成拷贝过程。但是这样会丢失stat数据信息(权限等),因为根本就没有复制过去。
目录怎么办呢?
Python提供了一个方便的库shutil(高级文件操作)
Copy复制

import shutil
with open('test1.txt','r+') as f1:
f1.write('abcd\n1234')
f1.flush()
with open('test2.txt','w+')as f2:
shutil.copyfileobj(f1,f2)
#注意:由于指针的缘故,可参见源码如下。上述代码中abcd\n1234内容确实会写入到test1.txt,但是并没有复制到test2.txt中。
#copyfileobj源码
def copyfileobj(fsrc, fdst, length=16*1024):
"""copy data from file-like object fsrc to file-like object fdst"""
while 1:
buf = fsrc.read(length)
if not buf:
break
fdst.write(buf)






#copytree源码,这里主要了解一下ignore函数的使用技巧,过滤掉不需要拷贝的!
def copytree(src, dst, symlinks=False, ignore=None, copy_function=copy2,
names = os.listdir(src)
if ignore is not None:
ignored_names = ignore(src, names)
else:
ignored_names = set() os.makedirs(dst)
errors = []
for name in names:
if name in ignored_names:
continue
srcname = os.path.join(src, name)
dstname = os.path.join(dst, name)
...return dst
def fn(src,file_names):
filter(lambda x:x.startwith('t'),file_names)
#上面的语句等同于下面的语句
fn = lambda src,names:filter(lambda x:x.startwith('t').file_names)
#filter(function, iterable)
#注意: Pyhton2.7 返回列表,Python3.x 返回迭代器对象
#假设D:/temp下有a,b目录
def ignore(src,names):
ig = filter(lambda x:x.startwith('a'),names) #忽略a
return set(ig) shutil.copytree('o:/temp','o:/tt/o',ignore=ignore)
rm删除

shutil.rmtree('D:/tmp') #类似rm -rf
move移动

#在同一盘符下,其实质上就是rename,跨盘符的话才是真正的移动
os.rename('D:/temp/x.txt','D:/t.txt')
os.rename('test3','/tmp/py/test')

shutil对压缩包的处理是调用ZipFile和ZipFile两个模块来处理的
参考:https://www.cnblogs.com/zjltt/p/6957663.html
csv文件
csv文件简介(文本格式,半结构化数据)

手动生成CSV文件
from pathlib import Path
p = Path('F:\\百度网盘下载资料\\Python全栈开发\\python进阶1\\19Python的文件IO(三)(6)\\test.csv')
parent = p.parent
if not parent.exists():
parent.mkdir(parents=True)
csv_body = '''\
id,name,age,comment
1,zs,18,"I'm 18"
2,ls,20,"This is a testing"
3,ww,232,"中 国"
'''
p.write_text(csv_body)
csv模块

from pathlib import Path
import csv
p = Path('F:\\test.csv')
with open(str(p)) as f:
reader = csv.reader(f)
print(next(reader)) row = [4,'cty',22,'tom']
rows = [
(1,'',3,''),
(11,'',22,"\"123123")
]
with open(str(p),'a+') as f:
writer = csv.writer(f)
writer.writerow(row)
writer.writerows(rows)
ini文件
作为配置文件,ini文件格式很流行

中括号里面的部分称为section。
每一个section内,都是key=value形成的键值对,key称为option选项。
configparser




from configparser import ConfigParser cfg = ConfigParser()
cfg.read('mysql.ini')
print(cfg.sections())
print(cfg.has_section('deploy'))
print(cfg.items('deploy')) for k,v in cfg.items('deploy'):
print(k,type(v)) tmp = cfg.get('deploy','a')
print(tmp,type(tmp))
print(cfg.get('deploy','a',fallback='python')) print(cfg.getint('mysql','aa')) if cfg.has_section('mysql'):
cfg.remove_section('mysql') cfg.add_section('cy')
cfg.set('cy','ly','')
cfg.set('cy','ggz','') # 上面的删除和新增功能需要重新写入文件才会生效
with open('mysql.ini','w') as f:
cfg.write(f) print(cfg.getint('cy','ggz'))
print(cfg.remove_option('cy','ly')) with open('mysql.ini','w') as f:
cfg.write(f)
注意:配置文件一般加载后常驻于内存中,且读取操作远远多于写入操作。
Python进阶5---StringIO和BytesIO、路径操作、OS模块、shutil模块的更多相关文章
- 【Python初级】StringIO和BytesIO读写操作的小思考
from io import StringIO; f = StringIO(); f.write('Hello World'); s = f.readline(); print s; 上面这种方法“无 ...
- Python入门篇-StringIO和BytesIO
Python入门篇-StringIO和BytesIO 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.StringIO(用于文本处理) 1>.使用案例 #!/usr/bin ...
- Python中os和shutil模块实用方法集…
Python中os和shutil模块实用方法集锦 类型:转载 时间:2014-05-13 这篇文章主要介绍了Python中os和shutil模块实用方法集锦,需要的朋友可以参考下 复制代码代码如下: ...
- Python中os和shutil模块实用方法集锦
Python中os和shutil模块实用方法集锦 类型:转载 时间:2014-05-13 这篇文章主要介绍了Python中os和shutil模块实用方法集锦,需要的朋友可以参考下 复制代码代码如下: ...
- python day 9: xlm模块,configparser模块,shutil模块,subprocess模块,logging模块,迭代器与生成器,反射
目录 python day 9 1. xml模块 1.1 初识xml 1.2 遍历xml文档的指定节点 1.3 通过python手工创建xml文档 1.4 创建节点的两种方式 1.5 总结 2. co ...
- 【Python】[IO编程]文件读写,StringIO和BytesIO,操作文件和目录,序列化
IO在计算机中指Input/Output,也就是输入和输出. 1.文件读写,1,读文件[使用Python内置函数,open,传入文件名标示符] >>> f = open('/User ...
- python IO编程-StringIO和BytesIO
链接:https://www.liaoxuefeng.com/wiki/0014316089557264a6b348958f449949df42a6d3a2e542c000/0014319187857 ...
- python 文件,文件夹,路径操作
判断路径或文件os.path.isabs(...) # 判断是否绝对路径os.path.exists(...) # 判断是否真实存在os.path.isdir(...) # 判断是否是个目录os.pa ...
- day18 时间:time:,日历:calendar,可以运算的时间:datatime,系统:sys, 操作系统:os,系统路径操作:os.path,跨文件夹移动文件,递归删除的思路,递归遍历打印目标路径中所有的txt文件,项目开发周期
复习 ''' 1.跨文件夹导包 - 不用考虑包的情况下直接导入文件夹(包)下的具体模块 2.__name__: py自执行 '__main__' | py被导入执行 '模块名' 3.包:一系列模块的集 ...
- 路径操作OS模块和Path类(全)一篇够用!
路径操作 路径操作模块 os模块 os属性 os.name # windows是nt, linux是posix os.uname() # *nix支持 sys.platform #sys模块的属性, ...
随机推荐
- .Net 控制台中文(简体/繁体)乱码问题
加上这句就可以了: Console.OutputEncoding = System.Text.Encoding.UTF8; class Program { static void Main(strin ...
- 学JAVA第九天,for循环算质数及for遍历数组的方法。
昨天终于收到了评论,老开心了!!! 算质数之前是我最怕的一件事,以前上学不好好学,之前学C#的时候也没好好研究, 直到今天老师逼我要用JAVA算质数,硬着头皮琢磨老半天才琢磨透,现在看来也挺简单的. ...
- Java基础:HashMap假死锁问题的测试、分析和总结
前言 前两天在公司的内部博客看到一个同事分享的线上服务挂掉CPU100%的文章,让我联想到HashMap在不恰当使用情况下的死循环问题,这里做个整理和总结,也顺便复习下HashMap. 直接上测试代码 ...
- 【学习笔记】tensorflow实现一个简单的线性回归
目录 准备知识 Tensorflow运算API 梯度下降API 简单的线性回归的实现 建立事件文件 变量作用域 增加变量显示 模型的保存与加载 自定义命令行参数 准备知识 Tensorflow运算AP ...
- REST风格下如何放行静态资源
在配置DispatcherServlet(前端控制器)时,如果把拦截路径配置成rest风格(即斜杠/),则会将静态资源也一并拦截(比如.css .js ,jpg)为了避免这个情况,可以把拦截路径设置成 ...
- form表单中多个button按钮必须声明type类型
最近在做一个后台管理系统,发现了一个小bug: 问题描述:form表单中有多个button按钮(以下图为例),如果第一个button不写type属性,那么点击第一个button按钮会触发submit事 ...
- #WEB安全基础 : HTML/CSS | 0x10.1更多表单
来认识更多的表单吧,增加知识面 我只创建了一个index.html帮助你认识它们 以下是代码 <!DOCTYPE html> <html> <head> <m ...
- 记一次与iframe之间的抗争
iframe这个标签之前了解过这个东西,知道它可以引入外来的网页,但是实际开发中没有用到过.这一次有一个需求是说准备要在网页中嵌套另外一个网站,用iframe这个标签,让我测试一下这个可不可以在自己的 ...
- jQuery遍历—each()方法遍历对象和数组
打开控制台后可以看到以下输出:
- 从0开始的Python学习007函数&函数柯里化
简介 函数是可以重用的程序段.首先这段代码有一个名字,然后你可以在你的程序的任何地方使用这个名称来调用这个程序段.这个就是函数调用,在之前的学习中我们已经使用了很多的内置函数像type().range ...