hadoop记录-浅析Hadoop中的DistCp和FastCopy(转载)
DistCp(Distributed Copy)是用于大规模集群内部或者集群之间的高性能拷贝工具。 它使用Map/Reduce实现文件分发,错误处理和恢复,以及报告生成。 它把文件和目录的列表作为map任务的输入,每个任务会完成源列表中部分文件的拷贝。
DistCp是Apache Hadoop自带的工具,目前存在两个版本,DistCp1和DistCp2,FastCopy是Facebook Hadoop中自带的,相比于Distcp,它能明显加快同节点数据拷贝速度,尤其是Hadoop 2.0稳定版(第一个稳定版为2.2.0,该版本包含的特性可参考我的这篇文章:Hadoop 2.0稳定版本2.2.0新特性剖析)发布后,当需要在不同NameNode间(HDFS Federation)迁移数据时,FastCopy将发挥它的最大用武之地。
DistCp第一版使用了MapReduce并发拷贝数据,它将整个数据拷贝过程转化为一个map-only Job以加快拷贝速度。由于DistCp本质上是一个MapReduce作业,它需要保证文件中各个block的有序性,因此它的最小数据切分粒度是文件,也就是说,一个文件不能被切分成不同部分让多个任务并行拷贝,最小只能做到一个文件交给一个任务。
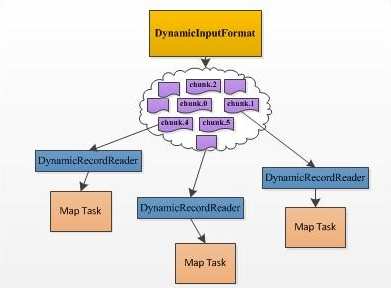
DistCp2针对DistCp1在易用性和性能等方面的不足,提出了一系列改进点,包括通过去掉不必要的检查缩短了目录扫描时间、动态分配各个Map Task的数据量、可对拷贝限速避免占用过多网络流量、支持HSFTP等。尤其值得一说的是动态分配Map Task处理数据量。DistCp1的实现跟我们平时写的大部分MapReduce程序一样,每个Map Task的待处理数据量在作业开始运行前已经静态分配好了,这就出现了我们经常看到的拖后腿的现象:由于一个Map Task分配的数据量过多,运行非常缓慢,所有Reduce Task都在等待这个Map Task运行完成。而对于DistCp而言,该现象更加常见,因为最小的数据划分单位是文件,文件有大有小,分到大文件的Map Task将运行的非常慢,比如你有两个待拷贝的文件,一个大小为1GB,另一个大小为1TB,如果你指定了超过2个的Map Task,则该DistCp只会启动两个Map Task,其中一个负责拷贝1GB的文件,另一个负责拷贝1TB的文件,可以想象其中一个任务将运行的非常慢。DistCp2通过动态分配Map Task数据量解决了该问题,它实现了一个DynamicInputFormat,该InputFormat将待拷贝的目录文件分解成很多的chunk,其中每个chunk的信息(位置,文件名等)写到一个以“.chunk.K”(K是一个数字)结尾的HDFS文件中,这样,每个文件可看做一份“任务”,“任务”数目要远大于启动的Map Task数目,运行快的Map Task能够多领取一些“任务”,而运行慢得则领取少一些,进而提高数据拷贝速度。尽管DistCp1中Map Task拷贝数据最小单位仍是文件,但相比于DistCp1,则要高效得多,尤其是在文件数据庞大,且大小差距较大的情况下。
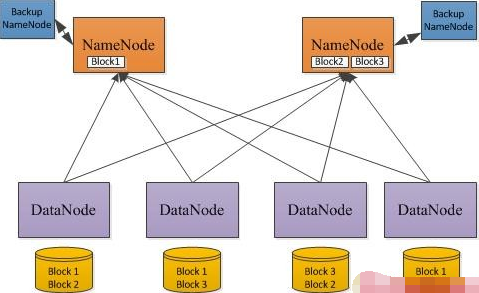
不管是DistCp1还是DistCp2,在数据拷贝过程中均存在数据低效问题,尤其在Hadoop 2.0时代表现突出。Hadoop 2.0引入了HDFS Federation(什么是HDFS Federation,),当我们进行Hadoop(1.0升级到2.0)升级或者将一个NameNode扩展到多个NameNode时,需将集群中的单个NameNode上的部分数据迁移到其他NameNode上,此时就需要用到DistCp这样的工具。在HDFS Federation设计中,一个HDFS集群中可以有多个NameNode,但DataNode是共享的,因此,在数据迁移过程中,大部分数据所在的节点不会变(在同一个DataNode上),只需将其指向新的NameNode(即数据位置不变,元数据转移到其他NameNode上)。如果使用DistCp,则需要将数据重新通过网络拷贝一份,然后将旧的删除,性能十分低下。考虑到数据仍在同一个节点上,则采用文件硬链接(Linux中的ln命令,硬连接可以用在Hadoop升级中,具体可参考我这篇文章:Hadoop 升级创建硬链接效率优化)就可以了, Facebook的FastCopy正是采用了这一方案。FastCopy已经被集成到了Facebook Hadoop中的DistCp中,有兴趣的读者可以试用一下。关于FastCopy更多细节,可阅读:“HDFS FastCopy”。
目前淘宝跨机房项目中,HDFS Federation转移数据使用到了FastCopy,并对其进行了部分优化
FaceBook在其内部的Hadoop版本中开发了一种叫做FastCopy的数据快速拷贝工具
hadoop记录-浅析Hadoop中的DistCp和FastCopy(转载)的更多相关文章
- hadoop记录-MapReduce之如何处理失败的task(转载)
1.1作业某个任务阻塞了,长时间占用资源不释放 1.2在MapTask任务运行完毕,ReduceTask运行过程中,某个MapTask节点挂了,或者某个MapTask结果存放的那磁盘坏掉了 在Task ...
- Hadoop记录-Apache hadoop+spark集群部署
Hadoop+Spark集群部署指南 (多节点文件分发.集群操作建议salt/ansible) 1.集群规划节点名称 主机名 IP地址 操作系统Master centos1 192.168.0.1 C ...
- Hadoop记录-部署hadoop环境shell实现
#!/bin/bash menu() { echo "---欢迎使用hadoop部署管理程序---" echo "# 1.初始化Linux环境" echo &q ...
- 浅析Java中的final关键字(转载)
自http://www.cnblogs.com/dolphin0520/p/3736238.html转载 一.final关键字的基本用法 在Java中,final关键字可以用来修饰类.方法和变量(包括 ...
- Hadoop InputFormat浅析
本文转载:http://hi.baidu.com/_kouu/item/dc8d727b530f40346dc37cd1 在执行一个Job的时候,Hadoop会将输入数据划分成N个Split,然后启动 ...
- [转帖]hadoop学习笔记:hadoop文件系统浅析
hadoop学习笔记:hadoop文件系统浅析 https://www.cnblogs.com/sharpxiajun/archive/2013/06/15/3137765.html 1.什么是分布式 ...
- hadoop学习笔记:hadoop文件系统浅析
1.什么是分布式文件系统? 管理网络中跨多台计算机存储的文件系统称为分布式文件系统. 2.为什么需要分布式文件系统了? 原因很简单,当数据集的大小超过一台独立物理计算机的存储能力时候,就有必要对它进行 ...
- hadoop文件系统浅析
1.什么是分布式文件系统? 管理网络中跨多台计算机存储的文件系统称为分布式文件系统. 2.为什么需要分布式文件系统了? 原因很简单,当数据集的大小超过一台独立物理计算机的存储能力时候,就有必要对它进行 ...
- hadoop记录-Hadoop参数汇总
Hadoop参数汇总 linux参数 以下参数最好优化一下: 文件描述符ulimit -n 用户最大进程 nproc (hbase需要 hbse book) 关闭swap分区 设置合理的预读取缓冲区 ...
随机推荐
- typescript类的修饰符
学习过java的小姐姐,小哥哥应该很好理解,但还是啰嗦的写出来! typescript里面定义属性的时候给我们提供了 三种修饰符 public :公有 在当前类里面. 子类 .类外面都可以访问 pro ...
- Java的多线程实现生产/消费模式
Java的多线程实现生产/消费模式 在Java的多线程中,我们经常使用某个Java对象的wait(),notify()以及notifyAll() 方法实现多线程的通讯,今天就使用Java的多线程实现生 ...
- iBatis第二章:搭建一个简单的iBatis开发环境
使用 iBatis 框架开发的基本步骤如下:1.新建项目(iBatis是持久层框架,可以运用到java工程或者web工程都可以) 这里我们建立一个 web 工程测试. 2.导入相应的框架 jar 包 ...
- SQL Server数据库————增删改查
--增删改查--增 insert into 表名(列名) value(值列表) --删 delect from 表名 where 条件 --改 update 表名 set 列名=值1,列名2=值2 w ...
- c/c++ 多线程 ubuntu18.04 boost编译与运行的坑
多线程 boost编译与运行的坑 背景:因为要使用boost里的多线程库,所以遇到了下面的坑. 系统版本:ubuntu18.04 一,安装boost 1,去boost官网下载 boost_1_XX_0 ...
- js坚持不懈之18:trim()方法
trim()方法,类似Python中的strip(),用去去除字符串对象前后的空格. <!DOCTYPE html> <html> <body> <scrip ...
- Win7下emacs简单配置
;;win7下.emacs在C:\Users\用户名\AppData\Roaming目录下 在.emacs文件中添加 ;; cancel welcome page取消欢迎界面(setq inhibit ...
- Centos7上安装单机版redis
Centos 7 上安装单机版redis Redis 官网下载 https://redis.io/download 1. 下载.解压.安装 cd /usr/local #wget http://dow ...
- selenium之元素定位-css
CSS定位方式和XPATH定位方式基本相同,只是CSS定位表达式有其自己的格式.CSS定位方式拥有比XPATH定位速度快,且比XPATH稳定的特性.下面详细介绍CSS定位方式的使用方法 被测网页的HT ...
- 我的第一个python web开发框架(38)——管理员管理功能
后台管理员的管理功能,它主要用来管理后台的登录账号,绑定权限,当然如果想将后台管理扩展成企业相关管理系统,比如用于公司人事管理,在这个基础上进行适当扩展就可以了. 我们先看看界面效果(也可以看着数据字 ...