Ubuntu16.04下Hadoop的本地安装与配置
一、系统环境
os : Ubuntu 16.04 LTS 64bit
jdk : 1.8.0_161
hadoop : 2.6.4
部署时使用的用户名为hadoop,下文中需要使用用户名的地方请更改为自己的用户名。
二、安装步骤
1、安装并配置ssh
1.1 安装ssh
输入命令: $ sudo apt-get install openssh-server ,安装完成后使用命令 $ ssh localhost 登录本机。首次登录会有提示,输入yes,接着输入当前用户登录电脑的密码即可。
1.2 配置ssh无密码登录
首先使用命令 $ exit 退出上一步的ssh,然后使用ssh-keygen生成密钥,最后将密钥加入授权即可,命令如下:
$ exit # 退出刚才的 ssh localhost
$ cd ~/.ssh/ # 若没有该目录,请先执行一次ssh localhost
$ ssh-keygen -t rsa # 会有提示,都按回车就可以
$ cat ./id_rsa.pub >> ./authorized_keys # 加入授权
配置完成之后再使用 $ ssh localhost 登录就不需要密码了。
2、安装并配置java
2.1 安装java
去官方网站下载jdk-8u161-linux-x64.tar.gz ,使用如下命令解压并安装到/usr/local/目录下:
$ cd ~/下载
$ sudo tar -xzf jdk-8u161-linux-x64.tar.gz -C /usr/local
$ cd /usr/local
$ sudo mv jdk1.8.0_161/ java
2.2 配置环境变量
使用命令 $ vim ~/.bashrc 编辑文件~/.bashrc,在该文件开头添加以下内容:
export JAVA_HOME=/usr/local/java
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib
export PATH=$PATH:$JAVA_HOME/bin
最后使用命令 $ source ~/.bashrc 让环境变量生效。使用java -version检查是否配置正确,正确配置如下图:

3、hadoop的安装与配置
3.1 hadoop下载与安装
去hadoop官网下载hadoop-2.6.4.tar.gz ,使用以下命令安装到/usr/local/目录下:
$ sudo tar -xzf hadoop-2.6..tar.gz -C /usr/local
$ cd /usr/local
$ sudo mv hadoop-2.6./ hadoop
$ sudo chown -R hadoop ./hadoop #前一个hadoop为用户名,更改为自己的用户名即可
将以下代码添加到~/.bashrc中:
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
然后使用命令 source ~/.bashrc 让环境变量生效,使用命令 hadoop version 检查环境变量是否添加成功,成功如下:

3.2 hadoop单机配置
安装后的hadoop默认为单机配置,无需其他配置即可运行。使用hadoop自带的单词统计的例子体验以下:
$ cd /usr/local/hadoop
$ mkdir ./input
$ cp ./etc/hadoop/*.xml ./input # 将配置文件作为输入文件
$ ./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep ./input ./output 'dfs[a-z.]+'
$ cat ./output/* # 查看运行结果
结果为:
dfsadmin
3.3 hadoop伪分布式配置
hadoop的配置文件存放在/usr/local/hadoop/etc/hadoop下,要修改该目录下的文件core-site.xml和hdfs-site.xml来达到实现伪分布式配置。
修改core-site.xml,将<configure></configure>修改为:
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
修改hdfs-site.xml,将<configure></configure>修改为:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>
配置完成后在/usr/local/hadoop下使用命令 $ ./bin/hdfs namenode -format 实现namenode的格式化,成功后会有“successfully formatted”及“Exiting with status 0”的提示,如下图:
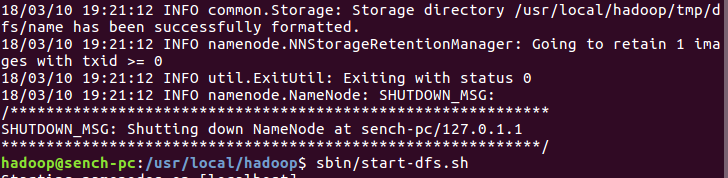
接着使用sbin/start-dfs.sh来开启namenode和datanode,开启后使用命令jps查看是否开启成功,如下图:
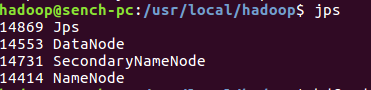
namenode和datanode都要出现才算成功。
4、配置yarn(非必须)
在/usr/local/hadoop下操作
$ cp etc/hadoop/mapred-site.xml.template etc/hadoop/mapred-site.xml
然后修改etc/hadoop/mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
修改etc/hadoop/yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
启动资源管理器
$ ./sbin/start-yarn.sh
$ ./sbin/mr-jobhistory-daemon.sh start historyserver #查看历史任务
启动成功后可以在http://localhost:8088/cluster访问集群资源管理器。
此时使用jps可以看到:
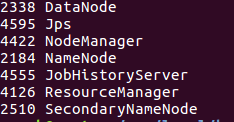
关闭资源管理器
$ ./sbin/stop-yarn.sh
$ ./sbin/mr-jobhistory-daemon.sh stop historyserver
三、参考
1、http://dblab.xmu.edu.cn/blog/install-hadoop/
Ubuntu16.04下Hadoop的本地安装与配置的更多相关文章
- Ubuntu16.04下LAMP环境的安装与配置
Ubuntu16.04下LAMP环境的安装与配置 最近做个实验需要用到Ubuntu环境的靶场,所以这里介绍下Ubuntu环境下LAMP的安装与配置,话不多说,我们gkd! 1.Apache2的安装 首 ...
- ubuntu16.04下ftp服务器的安装与配置
由于要将本地程序上传至云服务器中,所以需要给云服务器端安装ftp服务器.记录一下ftp的安装过程,以便以后使用.服务器端所用系统为Ubuntu16.04. 1. 安装ftp服务器, apt-get i ...
- Ubuntu16.04下Mongodb官网安装部署步骤(图文详解)(博主推荐)
不多说,直接上干货! 在这篇博客里,我采用了非官网的安装步骤,来进行安装.走了弯路,同时,也是不建议.因为在大数据领域和实际生产里,还是要走正规的为好. Ubuntu16.04下Mongodb(离线安 ...
- Ubuntu16.04下Mongodb(离线安装方式|非apt-get)安装部署步骤(图文详解)(博主推荐)
不多说,直接上干货! 说在前面的话 首先,查看下你的操作系统的版本. root@zhouls-virtual-machine:~# cat /etc/issue Ubuntu LTS \n \l r ...
- Ubuntu16.04下ZeroC ICE的安装与使用示例(Qt C++ 和 Java)
项目需求:在Ubuntu16.04系统下安装并使用ICEgrid 3.7进行c++和Java Springboot开发环境的通信,下面逐一介绍各个步骤的详解: 一:Ice Lib的安装 参考官网地址: ...
- ubuntu16.04下笔记本电脑扩展双屏安装过程
想给笔记本电脑外界一个显示屏,因为科研需要,我的笔记本是windows10加Ubuntu16.04双系统,主要使用Ubuntu系统. 首先是硬件 一个外置显示屏是必须的了,然后我的笔电上只有HDMI接 ...
- Ubuntu16.04下Python2:pip安装opendr库
在Ubuntu16.04/Python2环境安装opendr遇到了问题,并且报错不清楚. 使用dis_to_free的方法很好地解决问题. sudo apt install libosmesa6-de ...
- Ubuntu14.04或16.04下Hadoop及Spark的开发配置
对于Hadoop和Spark的开发,最常用的还是Eclipse以及Intellij IDEA. 其中,Eclipse是免费开源的,基于Eclipse集成更多框架配置的还有MyEclipse.Intel ...
- Ubuntu16.04 下 hadoop的安装与配置(伪分布式环境)
一.准备 1.1创建hadoop用户 $ sudo useradd -m hadoop -s /bin/bash #创建hadoop用户,并使用/bin/bash作为shell $ sudo pass ...
随机推荐
- shell之数组和关联数组
数组和关联数组 #!/bin/bash #定义数组1 array_var1=(1 2 3 4 5 6)# #定义数组2 array_var[0]="test1" array_var ...
- codeforces 1077F2. Pictures with Kittens (hard version)单调队列+dp
被队友催着上(xun)分(lian),div3挑战一场蓝,大号给基佬紫了,结果从D开始他开始疯狂教我做人??表演如何AKdiv3???? 比赛场上:A 2 分钟,B题蜜汁乱计数,结果想得绕进去了20多 ...
- 自古枪兵幸运E
好梗 求方程的解.n个可以奇数可以偶数,m个必须是偶数 两种方法: 都是O(nlogn)logn是LUCAS定理 法一: 有奇数有偶数,如果都是偶数,那么可以直接除以二然后组合数学 所以枚举有几个奇数 ...
- 主席树[可持久化线段树](hdu 2665 Kth number、SP 10628 Count on a tree、ZOJ 2112 Dynamic Rankings、codeforces 813E Army Creation、codeforces960F:Pathwalks )
在今天三黑(恶意评分刷上去的那种)两紫的智推中,突然出现了P3834 [模板]可持久化线段树 1(主席树)就突然有了不详的预感2333 果然...然后我gg了!被大佬虐了! hdu 2665 Kth ...
- git的git bash使用
一.git配置 在你使用git之前,需要先进行配置,即要报名号,否则不能提交代码 $ git config --global user.name # 你是谁 $ git config --global ...
- Dubbo2.6.5入门——管控台的安装
首先去下载管控台:GitHub 然后解压到本地,截止到目前2019-01-18,最新管控台基于Dubbo2.7.0-SNAPSHOT版本,但是2.7.0还没有正式发布,不过影响不大. Dubbo Op ...
- Ajax与JSON共同使用的小实例
实现的效果: 点击“点击”按钮,可以通过Ajax从服务器调过来相应的文档文件,而不需重新加载页面. 通过json可以将调过来的文档(String)转换为相应的json对象,从而对文档中数据进行操作. ...
- $m$ 整除 $10^k$ 的一个充分条件
若 (1) 既约分数 $\cfrac{n}{m}$ 满足 $0<\cfrac{n}{m}<1$; (2) 分数 $\cfrac{n}{m}$ 可以化为小数部分的一个循环节有 $k$ 位数字 ...
- Linux中安装C++编译器codeBlock,并配置opencv链接库
1.Linux中安装codeBlock https://blog.csdn.net/xinyunyishui/article/details/50967395 2.CodeBlock中的中文显示不完全 ...
- Nginx 站点设置目录列表显示
Nginx 站点目录列表显示. 可以编辑添加在 server { } 模块 或者 location { } 模块下. autoindex on; # 开启目录文件列表 autoindex_exact_ ...