Python3 网络爬虫(请求库的安装)
Python3 网络爬虫(请求库的安装)
爬虫可以简单分为几步:抓取页面,分析页面和存储数据
在页面爬取的过程中我们需要模拟浏览器向服务器发送请求,所以需要用到一些python库来实现HTTP的请求操作,我们用到的第三方库有requests Selenium 和aiohttp
requests 的安装
相关链接:
- GitHub :https://github.com/requests/requests
- PypI:https://pypi.python.org/pypi/requests
- 官方文档:http://www.python-requests.org
- 中文文档:http://docs.python-request.org/zh_CN/latest
安装:
最好用的安装方式:pip 安装
pip3 install requests
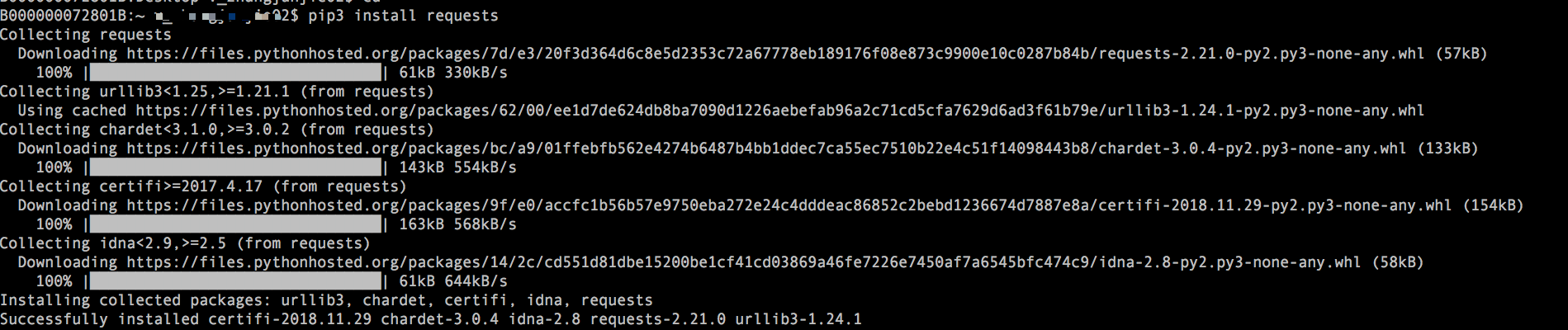
验证是否安装成功
打开控制台进入命令行模式,首先输入python3 然后输入import requests 如果什么报错或提示说明安装成功
#!/usr/bin/env python
# -*- coding:utf-8 -*-
#__author__=v_zhangjunjie02
import requests
Selenium 的安装
selenium是一种自动化测试工具,利用它可以驱动浏览器执行特定的动作,如点击,下拉等操作,对于一些JavaScript 渲染的页面来说,这种抓取方式非常有效,下面来看看selenium 的安装过程
相关链接
- 官方网站:http://www.seleniumhq.org
- GitHub :https://github.com/SeleniumHQ/selenium/tree/master/py
- PypI: https://pypi.python.org/pypi/selenium
- 官方文档:http://selenium-python.readthedocs.io
- 中文文档:http://selenium-python-zh.readthedocs.io
还是用pip 安装
pip3 install selenium

验证是否安装成功:
打开控制台进入命令行模式,首先输入python3 然后输入import selenium 如果什么报错或提示说明安装成功
ChromeDriver 的安装
前面我们已经安装好了Selenium库,但是它是一个自动的测试工具,需要浏览器来配合使用,下面我们是Chrome浏览器和ChromeDriver驱动的配置
首先下载chromedriver
随后安装chromedriver ,因为安装了Chromedriver 才能驱动Chrome完成相应的操作
Chromedriver 相关链接
- 官方网站:https://sites.google.com/a/chromium.org/chromedriver
- 下载地址:https://chromedriver.storage.googleapis.com/index.html
安装的chromedriver 要和Chrome 的版本一致
环境变量的配置:
1.下载完成后 将ChromeDriver 的可执行文件配置到环境变量下
在Windows下建议直接将chromedriver.exe 文件拖拽到Python的Script 目录下,此外还可以单独配置其所在路径到环境变量
在Linux 和Mac 下需要将可执行文件配置到环境变量,或将文件移动到所属环境变量的文件里
例如,要移动文件到/user/bin 目录 ,首先需要在命令行模式下进入其文件的所在路径,然后将其移动到/user/bin:
sudo mv chromedriver /user/bin
另外如果你的系统是Mac OS X EI Capitan 及更新版本的话,需要关闭Rootless 内核保护机制,具体参考http://www.pc6.com/edu/86809.html
当然,也可以将ChromeDriver 配置到$PATH :首先,可以将可执行文件放到某一目录,目录可以任意选择,例如将当前的可执行文件放到/user/local/chromedriver 目录下,接下来在Linux 下修改~/.profile 文件,在Mac 下可以修改~/.bash_profile文件添加如下内容
export PATH="$PATH:/usr/local/chromedriver"
保存后Linux下执行如下命令:
source ~/.profile
在mac 下执行:
source ~/.bash_profile
即可完成环境变量的添加
我们在程序中测试,执行如下代码:
from selenium import webdriver
browser=webdriver.Chrome()
运行之后,如果弹出一个空白的Chrome 浏览器,则证明所有的配置都没有问题,如果没有弹出,则需要检查之前的每一步配置
如果弹出后闪退,可能是Chrome 版本和chromedriver 版本不兼容导致的,更换对应的版本即可
GeckoDriver 的安装
GeckoDriver 是Firefox 浏览器的驱动
它的安装如下:
相关链接:
- GitHub:https://github.com/mozilla/geckodriver
- 下载地址:https://github.com/mozilla/geckodriver/releases
我们可以在github 上找到它的发行版本
环境变量配置同上
PhantomJS 的安装
phantomjs 是一个无界面,可脚本编程的WebKit浏览器引擎,它原生支持多种Web 标准:DOM操作,css 选择器,JSON ,Canvas 以及SVG
selenium支持phantomjs ,在运行的时候不会弹出一个浏览器,而且phantomjs 的运行效率也很高,还支持各种参数配置,使用非常方便:它的安装如下:
相关链接:
- 官方网站:http://phantomjs.org
- 官方文档:http://phantomjs.org/quick-start.html
- 下载地址:http://phantomjs.org/download.html
- API 接口说明:http://phantomjs.org/api/command-line.html
我们在官网上下载对应的安装包后,需要将可执行文件添加进环境变量(环境变量的添加方法,同上)
验证是否配置成功:在命令行输入phantomjs-v 如果输出对应的版本,说明配置成功
验证是否安装成功:
from selenium import webdriver
browser=webdriver.PhantomJS()
browser.get('https://www.baidu.com')
print(browser.current_url)
运行后不会有浏览器弹出,但是把url打印出来了,说明安装成功了
aiohttp 的安装
之前介绍的requests 库是一个阻塞式HTTP请求库,当我们发送一个请求后,程序会一直等待服务器响应,直到得到响应后程序才会做下一步处理,其实这个过程比较费时,如果程序可以在等待的过程中做一些其他的事情,如请求的调度,响应的处理等,那么爬取效率一定会大大提高
aiohttp 就是这样一个提供异步web服务的库,从python3.5 开始,Python加入了async/await 关键字,使的回调的方法更加直观和人性化,aiohttp 的异步操作借助于 async/await 关键字的写法变得更加简洁,架构更加清晰,使用异步请求库进行数据抓取时,会大大提高s效率(比如维护一个代理池,利用异步的方式检测大量代理的运行情况,会极大提升效率)
它的安装:
相关链接:
- 官方文档:http://aiohttp.readthedocs.io/en/stable
- GitHub:https://github.com/aio-libs/aiohttp
- PyPI:https://pypi.python.org/pypi/aiohttp
pip 安装
pip3 install aiohttp
另外,官方还推荐安装如下两个库:一个是字符编码检测库cchardet ,另一个是加速DNS的解析库aiodns 安装命令如下
pip3 install cchardet aiodns
测试安装:
在python命令下导入 import aiohttp 如果没有报错,说明安装成功
解析库的安装
抓取网页之后,下一步就是从网页中提取信息,提取信息的方式有多种多样,可以使用正则来提取,但是写起来相对比较繁琐,这里还有很多强大的解析库:如 lxml ,Beautiful Soup ,pyquery 等,此外还提供了大量的解析方法。如Xpath 解析和CSS 选择器解析等,利用它,们我们可以便捷高效的从网页中提取有用的信息
lxml 的安装
lxml 是python的一个解析库,支持HTML 和XML 的解析,支持Xpath 解析方式,而且解析效率非常高,它的安装如下:
相关链接:
官方网站:http://lxml.de
GitHub: https://github.com/lxml/lxml
PyPI: https://pypi.python.org/pypi/lxml
mac 下安装
使用pip 安装:pip3 install lxml
如果产生错误,可以执行如下命令将必要的类库安装
xcode-select --install
之后再重新尝试pip 安装就没有问题了
lxml 是一个非常重要的库,后面的Beautiful Soup Scrapy 都要用到此库,所以一定要安装成功
Beautiful Soup 的安装
Beautiful soup 是python的一个HTML 或XML的解析库,我们可以用它来方便的从网页中提取数据,它拥有强大的API和多样的解析方式,它的安装如下:
相关链接:
官方文档:https://www.crummy.com/software/BeautifulSoup/bs4/doc
中文文档:https://www.crummy.com/software/BeautifulSoup/bs4/doc.zh
PyPi:https://pypi.python.org/pypi/beautifulsoup4
准备工作:
Beautiful soup 的HTML ,XML的解析库依赖于 lxml 库,所以安装之前确保已经安装成功了 lxml 库
pip 安装
pip3 install beautifulsoup4
验证安装:
from bs4 import BeautifulSoup
soup=BeautifulSoup('<p>Hello</p>','lxml')
print(soup.p.string)
运行结果如下:
Hello
如果一致,说明安装成功
⚠️注意,这里我们虽然安装的是beautifulsoft4 这个包,但是引入的时候却引入bs4, 这是因为这个包源代码本身的库文件夹的名称就是bs4
pyquery 的安装
pyquery 同样是一个强大的网页解析工具,它提供了类似 jQuery 类似的语法来解析HTML文档,支持css 选择器,使用非常方便,它的安装如下:
相关链接:
GitHub:https://github.com/gawel/pyquery
PyPI : https://pypi.python.org/pypi/pyquery
官方文档:http://pyquery.readthedocs.io
pip 安装
pip3 install pyquery
验证同上
tesserocr 的安装
在爬虫的过程中难免会遇到各种各样的验证码,大多数验证码都是图形验证码,这时候我们可以直接用ocr 来识别
tesserocr是python的一个OCR库,但其实是对tesseract 做的一层Python API 的封装,所以它的核心是tesseract ,因此在安装tesserocr 之前,我们需要安装tesseract
相关链接
- tesserocr GitHub :https://github.com/sirfz/tesserocr
- tesserocr PyPI : https://pypi.python.org/pypi/tesserocr
- tesseract 下载地址:http://digi.bib.uni-mannheim.de/tesseract
- tesseract GitHub :https://github.com/tesseract-ocr/tesseract
- tesseract 语言包:https://github.com/tesseract-ocr/tessdata
- tesseract 文档:https://github.com/tesseract-ocr/tesseract/wiki/Documentation
Mac 下安装
brew 的安装参考:https://brew.sh/
或在终端执行/usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"
首先使用Homebrew 安装ImageMagick 和tesseract
brew install imagemagick
brew install tesseract --all-languages
接下来我们再安装tesserocr
pip3 install tesserocr pillow
这样我们便完成了tessercor 的安装
数据库的安装
MySql的安装
MySql 是一个轻量级的关系型数据库,
相关链接
- 官方网站:http://www.mysql.com/cn
- 下载地址:https://www.mysql.com/cn/downloads
- 中文教程:http://www.runoob.com/mysql/mysql-tutorial.html
mac 下安装
brew instal mysql
启动,停止和重启MySQl服务的命令
sudo mysql.server start
sudo mysql.server stop
sudo mysql.server restart
MongoDB 的安装
mongoDB 是由c++ 语言编写的非关系型数据库,是一个基于分布式文件存储的开源数据库系统,其内容存储形式类似json 对象,他的字段值可以包含其他文档,数组及文档数组,非常灵活
mangoDB 支持多种平台,包括windows,linux ,MAX OS 在其官方网站上(http://www.mangodb.com/download-center)均可找到对应的安装包
它的安装过程
- 官方网站:https://www.mongodb.com
- 官方文档:https://docs.mangodb.com
- GitHub:https://github.com/mongodb
- 中文教程:http://www.runoob.com/mongodb/mongodb-tutorial.html
Mac 下安装
brew install mongodb
然后新建一个文件夹/data/db 用于存放MongoDB 数据
这里启动MongoDB 服务的命令如下
brew services start mongodb
sudo mongod
停止和重启MongoDB 服务的命令分别是
brew services stop mongodb
brew services restart mongodb
可视化工具
这里推荐一个可视化工具 RoboMongo/Robo 3T 官方网站为:https://robomongo.org/下载链接:https://robomongo.org/download
Redis的安装
redis 是一个基于内存非常高效的非关系型数据库,它的安装如下
相关链接
- 官方网站:https://redis.io
- 官方文档:https://redis.io/documentation
- 中文文档:http://www.redis.cn
- GItHub: https://github.com/antirez/redis
- 中文教程:http://www.runoob.com/redis/redis-tutorial.html
- Redis Desktop Manager:https://redisdesktop.com
- Redis Desktop Manager GitHub : https://github.com/uglide/RedisDesktopManager
mac 下安装
brew install redis
启动Redis 服务的命令如下
brew services start redis
redis-server /use/local/etc/redis.conf
在mac 下Redis 的配置文件路径是/user/local/etc/redis.conf 可以通过修改它来配置访问密码
修改配置文件后,需要重启Redis 服务,停止和重启Redis 服务的命令分别如下
brew services stop redis
brew services restart redis
另外,在mac 下可以安装Redis Desktop Manager 可视化管理工具来管理Redis
存储库的安装
PyMySql的安装
相关链接
- GitHub :https://github.com/PyMySQL/PyMySQL
- 官方文档:http://pymysql.readthedocs.io/
- PyPI: https://pypi.python.org/pypi/PyMySQL
pip安装
pip3 install pymysql
PyMongo 的安装
pip3 install pymongo
redis-py的安装
pip3 install redis
RedisDump 的安装
它是一个用于将redis 数据导入导出的工具,基于Ruby实现,要想安装它先的安装Ruby、
1.相关链接:
GitHub :https://github.com/delano/redis-dump
官方文档:http://delanotes.com/redis-dump
2.安装Ruby
参考:http://www.ruby-lang.org/zh_cn/documentation
3.gem 安装
gem install redis-dump
4.验证安装
redis-dump
redis-load
如果这两条命令可以成功调用,说明安装成功
web库的安装
flask 的安装
相关链接
Github:https://github.com/pallets/flask
官方文档:http://flask.pocoo.org
中文文档:http://docs.jinkan.org/docs/flask
PyPi: https://pypi.python.org/pypi/Flask
安装
pip3 install flask
tornado的安装
tornado是一个支持异步的web框架,通过使用非阻塞I/O 流,它可以支持成千上万的开放链接,效率非常高
1.相关链接
GitHub : https://github.com/tornadoweb/tornado
PyPI : https://pypi.python.org/pypi/tornado
官方文档: http://www.tornadoweb.org
安装
pip install tornado
mitmproxy 的安装
mitmproxy 是一个支持http和https 的抓包程序,类似于fiddler 和charles 只不过,它是通过控制台的形式去操作
此外mitproxy 还有两个相关组件,mitmdump ,它是mitmproxy 的命令行接口,利用它可以对接python脚本,实现监听后的处理;一个是mitmweb 它是一个web程序,通过它可以清楚的观察到mitmproxy 捕获的请求
它们的安装如下:
- GitHub :https://github.com/mitmproxy/mitmproxy
- 官方网站:https://mitmproxy.org
- PyPI:https://pypi.python.org/pypi/mitmproxy
- 官方文档:http://docs.mitmproxy.org
- mitmdump 脚本: http://docs.mitmproxy.org/en/stable/scripting/overview.html
- 下载地址:https://github.com/mitmproxy/mitmproxy/releases
- DockerHub: https://hub.docker.com/r/mitmproxy/mitmproxy
安装方式一:mac 下安装
pip3 install mitmproxy
如果不行执行
brew install mitmproxy
证书设置:
对于mitmproxy 来说,如果想捕获https 请求需要设置证书,mitmproxy 在安装后会提供一套CA证书,只要客户端信任了mitmproxy 提供的证书,就可以通过mitmproxy 捕获https请求
首先运行以下命令产生CA证书
mitmdump
接下来在用户目录下的.mitmproxy 目录里找到CA 证书,证书一共有5个
Appium 的安装
Appium是移动端的自动化测试工具,利用它可以驱动Android 和 IOS 等设备完成自动化的测试 其官方网站为:http://appium.io
1.相关链接:
GitHub : https://github.com/appium/appium
官方网站:http://appium.io
官方文档:http://appium.io/introduction.html
下载链接:https://github.com/appium/appium-desktop/release
Python Client :https://github.com/appium/python-clent
安装appium
appium 负责驱动移动端来完成一系列操作对于ios 来说,它使用苹果的UIAutonation 来实现驱动,对于Android 来说,它使用UIAutomator 和Selendroid 来实现驱动
同时Appiumd 相当于一个服务器,我们可以向它发送一些操作指令,他会根据不同的指令对移动端设备完成不同的操作
安装Appium 有两种方式,一种是直接下载Appium Desktop 来安装,另一种是通过node.js 来安装
Appium Desktop
链接地址:https://github.com/appium/appium-desktop/releases
推荐使用node.js 安装
使用node.js 安装先要安装node.js 参考链接:http://www.runoob.com/nodejs/nodejs-install-setup.html
然后使用命令npm install -g appium 安装,这条命令执行完后就完成了appium 的安装
Android 开发环境的配置
Android 环境的配置
下载Android Studio (https://developer.android.com/studio/index.html?hl=zh-cn
安卓SDK的下载
下载完Android Studio后直接在Android 的设置页面勾选要安装的SDK 即可
另外需要配置下环境变量,参考地址:https://developer.android.com/studio/intro/index.html
爬虫框架的安装
pyspidei 的安装
- 官方文档:http://docs.pyspider.org/
- PyPi:https://pypi.python.org/pypi/pyspider
- GitHub:https://github.com/binux/pyspider
- 官方教程:http://docs.pyspider.org/en/latest/tutorial
- 在线实例:http://demo.pyspider.org
准备工作:pyspider 是支持javascript 渲染的,而且这个过程依赖于PhantomJS 所以需要先安装PhantomJS
使用pip 安装
pip3 install pyspider
验证安装:
命令行执行
pyspider all
在浏览器中输入http://localhost:5000/
Python3 网络爬虫(请求库的安装)的更多相关文章
- Python爬虫--- 1.1请求库的安装与使用
来说先说爬虫的原理:爬虫本质上是模拟人浏览信息的过程,只不过他通过计算机来达到快速抓取筛选信息的目的所以我们想要写一个爬虫,最基本的就是要将我们需要抓取信息的网页原原本本的抓取下来.这个时候就要用到请 ...
- 崔庆才Python3网络爬虫开发实战电子版书籍分享
资料下载地址: 链接:https://pan.baidu.com/s/1WV-_XHZvYIedsC1GJ1hOtw 提取码:4o94 <崔庆才Python3网络爬虫开发实战>高清中文版P ...
- Python3网络爬虫开发实战PDF高清完整版免费下载|百度云盘
百度云盘:Python3网络爬虫开发实战高清完整版免费下载 提取码:d03u 内容简介 本书介绍了如何利用Python 3开发网络爬虫,书中首先介绍了环境配置和基础知识,然后讨论了urllib.req ...
- 转:【Python3网络爬虫开发实战】 requests基本用法
1. 准备工作 在开始之前,请确保已经正确安装好了requests库.如果没有安装,可以参考1.2.1节安装. 2. 实例引入 urllib库中的urlopen()方法实际上是以GET方式请求网页,而 ...
- 《Python3 网络爬虫开发实战》开发环境配置过程中踩过的坑
<Python3 网络爬虫开发实战>学习资料:https://www.cnblogs.com/waiwai14/p/11698175.html 如何从墙内下载Android Studio: ...
- 关于python请求库Selenium安装所遇到的问题
今天,初次接触python,在网上买了一本关于爬虫的书,因为之前电脑上存在python,所以就对着书直接进行的请求库的安装,安装的时候,主要遇到了下边一个问题,在安装Selenium的时候,出现以下提 ...
- 《Python3 网络爬虫开发实战》学习资料
<Python3 网络爬虫开发实战> 学习资料 百度网盘:https://pan.baidu.com/s/1PisddjC9e60TXlCFMgVjrQ
- python3网络爬虫系统学习:第一讲 基本库urllib
在python3中爬虫常用基本库为urllib以及requests 本文主要描述urllib的相关内容 urllib包含四个模块:requests——模拟发送请求 error——异常处理模块 pars ...
- [Python3网络爬虫开发实战] 1.8.4-Scrapy-Redis的安装
Scrapy-Redis是Scrapy的分布式扩展模块,有了它,我们就可以方便地实现Scrapy分布式爬虫的搭建.本节中,我们将介绍Scrapy-Redis的安装方式. 相关链接 GitHub:htt ...
随机推荐
- HTTP协议详解(二)
接着第一篇学习.... 5 头域(首部) 每个头域由一个域名,冒号(:)和域值三部分组成.域名是大小写无关的,域值前可以添加任何数量的空格符,头域可以被扩展为多行,在每行开始处,使用至少一个空格或制表 ...
- docker bulid命令
使用当前目录的 Dockerfile 创建镜像,标签为 runoob/ubuntu:v1. docker build -t runoob/ubuntu:v1 . 使用URL github.com/cr ...
- php 获取用户的IP、地址、来源
js方法获取用户的 ip 和 地址 <script src="http://pv.sohu.com/cityjson?ie=utf-8"></script> ...
- 解决百度上传WebUploader在IE浏览器下点击无反应的问题
原因1:IE浏览器不支持H5方式上传,需要使用flash的方式上传 解决方法:在页面head标签添加<meta http-equiv="X-UA-Compatible" co ...
- Javal连接字符串为Json
public static String concatJson(String[] keys,String[] values,String[] alreadyJsonKeys){ if(keys==nu ...
- About The Order of The Declarations And Definition When Making a Member Function a Friend.关于使类成员成为另一个类友元函数的声明顺序和定义。
If only member function clear of WindowMgr is a friend of Screen, there are some points need to note ...
- outlook2013 关闭时最小化到任务栏的完美解决方法
使用 Keep Outlook Running 加载项 文件->选项->加载项 点击最下面的“转到”按钮 *用管理员身份运行Outlook才可以将 Keep Outlook Running ...
- 二.Nginx反向代理和静态资源服务配置
2018年03月31日 10:30:12 麦洛_ 阅读数:1362更多 所属专栏: nginx 版权声明:本文为博主原创文章,未经博主允许不得转载. https://blog.csdn.net/M ...
- ASP.NET MVC 执行流程介绍
Routing 组件 Controller Controller中可用的ActionResult MVC-View(使用的抽象工厂模式的视图引擎) 视图模型
- [原创]windows 部署SS server 出现的错误.
安装过程: .Download and install Python MSI installer in 64bit Windows. .During installation you should i ...