工具篇-Spark-Streaming获取kafka数据的两种方式(转载)
转载自:https://blog.csdn.net/weixin_41615494/article/details/7952173
一、基于Receiver的方式
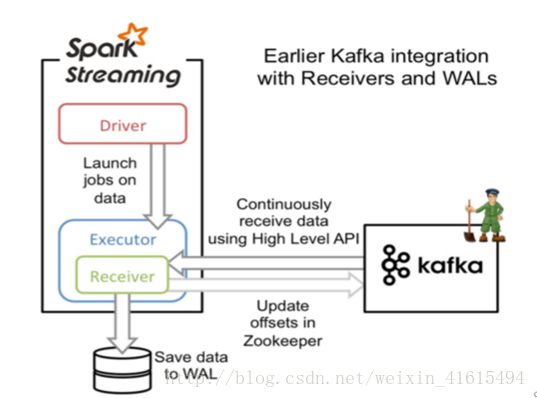
原理
Receiver从Kafka中获取的数据存储在Spark Executor的内存中,然后Spark Streaming启动的job会去处理那些数据,如果突然数据暴增,大量batch堆积,很容易出现内存溢出的问题。
在默认的配置下,这种方式可能会因为底层失败而丢失数据。如果要让数据零丢失,就必须启用Spark Streaming的预写日志机制(Write Ahead Log,WAL),该机制会同步地将接收到的Kafka数据写入分布式文件系统(比如HDFS)上的预写日志中,即使底层节点出现了失败,也可以使用预写日志中的数据进行恢复。
要点
1. Kafka中Topic的Partition与Spark中RDD的Partition没有关系。所以,在KafkaUtils.createStream()中,提高partition的数量只会增加一个Receiver中读取Partition线程的数量,不会增加Spark处理数据的并行度。可以创建多个Kafka输入DStream,使用不同的Consumer Group和Topic,来通过多个Receiver并行接收数据。
2. 如果基于容错的文件系统,比如HDFS,启用了预写日志机制,接收到的数据都会被复制一份到预写日志中。此时在KafkaUtils.createStream()中,设置的持久化级别是StorageLevel.MEMORY_AND_DISK_SER。
二、基于Direct的方式
原理
该方式在Spark 1.3中引入,来确保更加健壮的机制。这种方式会周期性地查询Kafka,获取每个Topic+Partition的最新的Offset,从而定义每个batch的offset的范围。当处理数据的job启动时,就会使用Kafka的简单consumer api来获取Kafka指定offset范围的数据。
优点
1. 简化并行读取:在Kafka Partition和RDD Partition之间,有一个一对一的映射关系,所以如果要读取多个partition,不需要创建多个输入DStream然后对它们进行Union操作,Spark会创建跟Kafka Partition一样多的RDD Partition,并且会并行从Kafka中读取数据。
2. 高性能:如果要保证零数据丢失,在基于Receiver的方式中,需要开启WAL机制,这种方式数据实际上被复制了两份效率低下,Kafka自己本身就有高可靠的机制,会对数据复制一份。而基于Direct的方式,不依赖Receiver,不需要开启WAL机制,只要Kafka中作了数据的复制,就可以通过Kafka的副本进行恢复。
对比(在实际生产环境中大都用Direct方式):
基于Receiver的方式,使用Kafka的高阶API在ZooKeeper中保存消费过的offset的,这是消费Kafka数据的传统方式。这种方式配合WAL机制可以保证数据零丢失的高可靠性,但是却无法保证数据被处理一次且仅一次,可能会重复处理。因为Spark和ZooKeeper之间可能是不同步的。
基于Direct的方式,使用Kafka的简单API,Spark Streaming自己就负责追踪消费的Offset,并保存在Checkpoint中,Spark自己一定是同步的,因此可以保证数据是消费一次且仅消费一次。
工具篇-Spark-Streaming获取kafka数据的两种方式(转载)的更多相关文章
- SparkStreaming获取kafka数据的两种方式:Receiver与Direct
简介: Spark-Streaming获取kafka数据的两种方式-Receiver与Direct的方式,可以简单理解成: Receiver方式是通过zookeeper来连接kafka队列, Dire ...
- Spark-Streaming获取kafka数据的两种方式:Receiver与Direct的方式
简单理解为:Receiver方式是通过zookeeper来连接kafka队列,Direct方式是直接连接到kafka的节点上获取数据 Receiver 使用Kafka的高层次Consumer API来 ...
- spark-streaming获取kafka数据的两种方式
简单理解为:Receiver方式是通过zookeeper来连接kafka队列,Direct方式是直接连接到kafka的节点上获取数据 一.Receiver方式: 使用kafka的高层次Consumer ...
- SparkStreaming与Kafka,SparkStreaming接收Kafka数据的两种方式
SparkStreaming接收Kafka数据的两种方式 SparkStreaming接收数据原理 一.SparkStreaming + Kafka Receiver模式 二.SparkStreami ...
- spark streaming 接收kafka消息之一 -- 两种接收方式
源码分析的spark版本是1.6. 首先,先看一下 org.apache.spark.streaming.dstream.InputDStream 的 类说明: This is the abstrac ...
- iOS 通过URL网络获取XML数据的两种方式
转载于:http://blog.csdn.net/crayondeng/article/details/8738768 下面简单介绍如何通过url获取xml的两种方式. 第一种方式相对简单,使用NSD ...
- Spark Streaming接收Kafka数据存储到Hbase
Spark Streaming接收Kafka数据存储到Hbase fly spark hbase kafka 主要参考了这篇文章https://yq.aliyun.com/articles/60712 ...
- jQuery异步获取json数据的2种方式
jQuery异步获取json数据有2种方式,一个是$.getJSON方法,一个是$.ajax方法.本篇体验使用这2种方式异步获取json数据,然后追加到页面. 在根目录下创建data.json文件: ...
- Spark Streaming中空batches处理的两种方法(转)
原文链接:Spark Streaming中空batches处理的两种方法 Spark Streaming是近实时(near real time)的小批处理系统.对给定的时间间隔(interval),S ...
随机推荐
- PE知识复习之PE文件空白区添加代码
PE知识复习之PE文件空白区添加代码 一丶简介 根据上面所讲PE知识.我们已经可以实现我们的一点手段了.比如PE的入口点位置.改为我们的入口位置.并且填写我们的代码.这个就是空白区添加代码. 我们也可 ...
- Maven教程(4)--Maven管理Oracle驱动包
由于Oracle授权问题,Maven3不提供Oracle JDBC driver,为了在Maven项目中应用Oracle JDBC driver,必须手动添加到本地仓库. 手动添加到本地仓库需要本地有 ...
- c#中的Unity容器
DIP是依赖倒置原则:一种软件架构设计的原则(抽象概念).依赖于抽象不依赖于细节 IOC即为控制反转(Inversion of Control):传统开发,上端依赖(调用/指定)下端对象,会有依赖,把 ...
- VSTO中Word转换Range为Image的方法
VSTO中Word转换Range为Image的方法 前言 VSTO是一套用于创建自定义Office应用程序的Visual Studio工具包,通过Interop提供的增强Office对象,可以对Wor ...
- Java开发笔记(七十三)常见的程序异常
一个程序开发出来之后,无论是用户还是程序员,都希望它稳定地运行,然而程序毕竟是人写的,人无完人哪能不犯点错误呢?就算事先考虑得天衣无缝,揣着一笔巨款跑去岛国买了栋抗震性能良好的海边别墅,谁料人算不如天 ...
- Secret Message ---- (Trie树应用)
Secret Message 总时间限制: 2000ms 内存限制: 32768kB 描述 Bessie is leading the cows in an attempt to escap ...
- 关于guns开源框架单元测试问题
首先在test文件夹里面删除红框里面的两个文件 然后再在需要测试的类里面右键类名生成测试文件 生成的测试文件加上这两句话 @RunWith(SpringJUnit4ClassRunner.class) ...
- js生成随机颜色
var shine=0.8; var arrays = ['[255,182,193,0.8]','[144,238,144,0.8]','[255,235,205,0.8]','[240,128,1 ...
- html的标签分类————可以上传的数据篇
html的标签可以分为: 块级标签:div(白板),H系列(加大加粗,H1—H7,字体一般逐渐变小,一般用作标题),p标签(段落之间有间距) 行内标签:span(白板) 此外,标签之间是可以嵌套的.为 ...
- 浅谈Semaphore类
Semaphore类有两个重要方法 1.semaphore.acquire(); 请求一个信号量,这时候信号量个数-1,当减少到0的时候,下一次acquire不会再执行,只有当执行一个release( ...