HBase实践案例:知乎 AI 用户模型服务性能优化实践
用户模型简介
知乎 AI 用户模型服务于知乎两亿多用户,主要为首页、推荐、广告、知识服务、想法、关注页等业务场景提供数据和服务,
例如首页个性化 Feed 的召回和排序、相关回答等用到的用户长期兴趣特征,问题路由、回答排序中用到的 TPR「作者创作权威度」,广告定向投放用到的基础属性等。
主要功能
提供的数据和功能主要有:
- 用户兴趣:长期兴趣、实时兴趣、分类兴趣、话题兴趣、keyword 兴趣、作者创作权威度等,
- 用户 Embedding 表示:最近邻用户、人群划分、特定用户圈定等,
- 用户社交属性:用户亲密度、二度好友、共同好友、相似优秀回答者等,
- 用户实时属性: LastN 行为、LastLogin 等,
- 用户基础属性:用户性别预测、年龄段计算、职业预估等。
服务架构
整体主要分为 Streaming / 离线计算、在线服务和 HBase 多集群同步三部分组成,下面将依次进行介绍。
Streaming / 离线计算
Streaming 计算主要涉及功能 LastRead、LastSearch、LastDisplay,实时话题/ Keyword 兴趣、最后登录时间、最后活跃的省市等。

实时兴趣的计算流程
- 相应日志获取。从 CardshowLog、PageshowLog、QueryLog 中抽取<用户,contentToken,actionType >等内容。
- 映射到对应的内容维度。对于问题、回答、文章、搜索分别获取对应的 Topic 和 Keyword,搜索内容对应的 Topic。
在 Redis 中用 contentToken 置换 contentId 后,请求 ContentProfile 获取其对应话题和关键词;
对于 Query,调用 TopicMatch 服务,传递搜索内容给服务,服务返回其对应的 Topic;调用 Znlp 的 KeywordExtractorJar 包,传递搜索内容并获得其对应的 Keyword 。 - 用户-内容维度汇总。根据用户的行为,在<用户,topic,actionType>和<用户,keyword,actionType>层面进行 groupBy 聚合汇总后,
并以 hashmap 的格式存储到 Redis,作为计算用户实时兴趣的基础数据,按时间衰减系数 timeDecay 进行新旧兴趣的 merge 后存储。 - 计算兴趣。在用户的历史基础数据上,按一定的 decay 速度进行衰减,按威尔逊置信区间计算用户兴趣 score,并以 Sortedset 的格式存储到 Redis。
关于兴趣计算,已经优化的地方主要是:如何快速的计算平滑参数 alpha 和 beta,如何 daily_update 平滑参数,以及用卡方计算置信度时,
是否加入平滑参数等都会对最终的兴趣分值有很大的影响,当 display 为 1 曝光数量不足的情况下,兴趣 score 和 confidence 计算出现 的 bias 问题等。
在线服务
随之知乎日益增加的用户量,以及不断丰富的业务场景和与之相对应出现的调用量上升等,对线上服务的稳定性和请求时延要求也越来越高。
旧服务本身也存在一些问题,比如:
- 在线服务直连 HBase,当数据热点的时候,造成某些 Region Server 的负载很高,P95 上升,轻者造成服务抖动,监控图偶发有「毛刺」现象,重者造成服务几分钟的不可用,需要平台技术人员将 Region 从负载较高的 RegionServer 上移走。
- 离线任务每次计算完成后一次大批量同时写入离线和在线集群,会加重 HBase 在线集群Region Server 的负载,增大 HBase get 请求的时延,从而影响线上服务稳定性和 P95。
针对问题一,我们在原来的服务架构中增加缓存机制,以此来增强服务的稳定型、减小 Region Server 的负载。
针对问题二,修改了离线计算和多集群数据同步的方式,详见「HBase多集群存储机制」部分。
Cache机制具体实现
没有 Cache 机制时,所有的 get 和 batchGet 方法直接请求到 HBase,具体如下图:
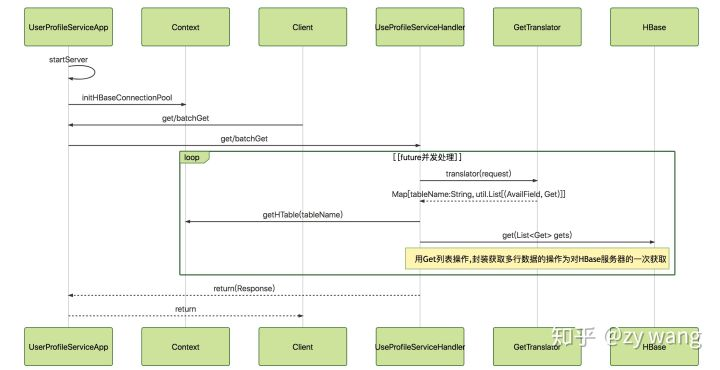
用户模型服务请求序列图
- UserProfileServiceApp 启动服务,将收到的请求交由 UserProfileServiceImpl 具体处理
- UserProfileServiceImp 根据请求参数,调用 GetTranslator 将 UserProfileRequest.GetRequest 转化成 HBase 中的
Get Object(在 Map 中维护每个 requestField 对应 HBase 中的 tablename,cf,column,prefix 等信息),以格式Map[String, util.List[(AvailField, Get)]]返回。 - UserProfileServiceImp 用 Future 异步向 HBase 发送 get 请求,获取到结果返回。
增加 Cache 机制的具体方法,在上面的第二步中,增加一个 CacheMap,用来维护 get 中 AvailField 对应 Cache 中的 key,
key 的组成格式为:「 tablename 缩写| columnfamily 缩写| columnname 缩写| rowkey 全写」。这里使用的 Redis 数据结构主要有两种,SortedSet 和 Key-Value对。
服务端收到请求后先去转化 requestField 为 Cache 中的 key,从 Cache 中获取数据。对于没有获取到 requestField 的转化成 GetObject,请求 HBase 获取,将结果保存到 Cache 中并返回。
最终效果
用户模型的访问量大概为 100K QPS,每个请求转化为多个 get 请求。 增加 Cache 前 get 请求的 P95 为30ms,增加 Cache 后降低到小于 15ms,Cache 命中率 90% 以上。
HBase 多集群存储机制
离线任务和 Streaming 计算主要采用 Spark 计算实现, 结果保存到 HBase 的几种方式:
方法一:每次一条
1. 每次写进一条,调用 API 进行存储的代码如下:
val hbaseConn = ConnectionFactory.createConnection(hbaseConf)
val table = hbaseConn.getTable(TableName.valueOf("word"))
x.foreach(value => {
var put = new Put(Bytes.toBytes(value.toString))
put.addColumn(Bytes.toBytes("f1"), Bytes.toBytes("c1"), Bytes.toBytes(value.toString))
table.put(put)
})
方法二:批量写入
2. 批量写入 HBase,使用的 API:
/**
* {@inheritDoc}
* @throws IOException
*/
@Override
public void put(final List<Put> puts) throws IOException {
getBufferedMutator().mutate(puts);
if (autoFlush) {
flushCommits();
}
}
方法三:MapReduce 的 saveAsNewAPIHadoopDataset 方式写入
3. saveAsNewAPIHadoopDataset 是通用的保存到 Hadoop 存储系统的方法,调用 org.apache.hadoop.mapreduce.RecordWriter 实现。
org.apache.hadoop.hbase.mapreduce.TableOutputFormat.TableRecordWriter 是其在 HBase 中的实现类。底层通过调用 hbase.client.BufferedMutator.mutate() 方式保存。
val rdd = sc.makeRDD(Array(1)).flatMap(_ => 0 to 1000000)
rdd.map(x => {
var put = new Put(Bytes.toBytes(x.toString))
put.addColumn(Bytes.toBytes("f1"), Bytes.toBytes("c1"), Bytes.toBytes(x.toString))
(new ImmutableBytesWritable, put)
}).saveAsHadoopDataset(jobConf) /**
* Writes a key/value pair into the table.
* @throws IOException When writing fails.
*/
@Override
public void write(KEY key, Mutation value)
throws IOException {
if (!(value instanceof Put) && !(value instanceof Delete)) {
throw new IOException("Pass a Delete or a Put");
}
mutator.mutate(value);
}
方法四:BulkLoad 方式
4. BulkLoad 方式,创建 HFiles,调用 LoadIncrementalHFiles 作业将它们移到 HBase 表中。
首先需要根据表名 getRegionLocator 得到 RegionLocator,根据 RegionLocator 得到 partition,因为在 HFile 中是有序的
所以,需要调用 rdd.repartitionAndSortWithinPartitions(partitioner) 将 rdd 重新排序。
HFileOutputFormat2.configureIncrementalLoad(job, table, regionLocator) 进行任务增量Load 到具体表的配置 实现并执行映射( 并减少) 作业,
使用 HFileOutputFormat2 输出格式将有序的放置或者 KeyValue 对象写入 HFile 文件。
Reduce 阶段通过调用 HFileOutputFormat2.configureIncrementalLoad 配置在场景后面。执行LoadIncrementalHFiles 作业将 HFile 文件移动到系统文件。
static void configureIncrementalLoad(Job job, Table table, RegionLocator regionLocator,
Class<? extends OutputFormat<?, ?>> cls) throws IOException {
Configuration conf = job.getConfiguration(); job.setOutputKeyClass(ImmutableBytesWritable.class);
job.setOutputValueClass(KeyValue.class);
job.setOutputFormatClass(cls); // Based on the configured map output class, set the correct reducer to properly
// sort the incoming values.
if (KeyValue.class.equals(job.getMapOutputValueClass())) {
job.setReducerClass(KeyValueSortReducer.class);
} else if (Put.class.equals(job.getMapOutputValueClass())) {
job.setReducerClass(PutSortReducer.class);
} else if (Text.class.equals(job.getMapOutputValueClass())) {
job.setReducerClass(TextSortReducer.class);
} else {
LOG.warn("Unknown map output value type:" + job.getMapOutputValueClass());
} conf.setStrings("io.serializations", conf.get("io.serializations"),
MutationSerialization.class.getName(), ResultSerialization.class.getName(),
KeyValueSerialization.class.getName()); configurePartitioner(job, startKeys);
// Set compression algorithms based on column families
configureCompression(table, conf);
configureBloomType(table, conf);
configureBlockSize(table, conf);
configureDataBlockEncoding(table, conf); TableMapReduceUtil.addDependencyJars(job);
TableMapReduceUtil.initCredentials(job);
LOG.info("Incremental table " + table.getName() + " output configured.");
} public static void configureIncrementalLoad(Job job, Table table, RegionLocator regionLocator)
throws IOException {
configureIncrementalLoad(job, table, regionLocator, HFileOutputFormat2.class);
}
val hFileLoader = new LoadIncrementalHFiles(conf)
hFileLoader.doBulkLoad(hFilePath, new HTable(conf, table.getName))
将 HFile 文件 Bulk Load 到已存在的表中。 由于 HBase 的 BulkLoad 方式是绕过了 Write to WAL,Write to MemStore 及 Flush to disk 的过程,所以并不能通过 WAL 来进行一些复制数据的操作。
由于 Bulkload 方式还是对集群 RegionServer 造成很高的负载,最终采用方案三,下面是两个集群进行数据同步。
存储同步机制
技术选型 HBase 常见的 Replication 方法有 SnapShot、CopyTable/Export、BulkLoad、Replication、应用层并发读写等。
应用层并发读写 优点:应用层可以自由灵活控制对 HBase写入速度,打开或关闭两个集群间的同步,打开或关闭两个集群间具体到表或者具体到列簇的同步,对 HBase 集群性能的影响最小,缺点是增加了应用层的维护成本。
初期没有更好的集群数据同步方式的时候,用户模型和内容模型自己负责两集群间的数据同步工作。

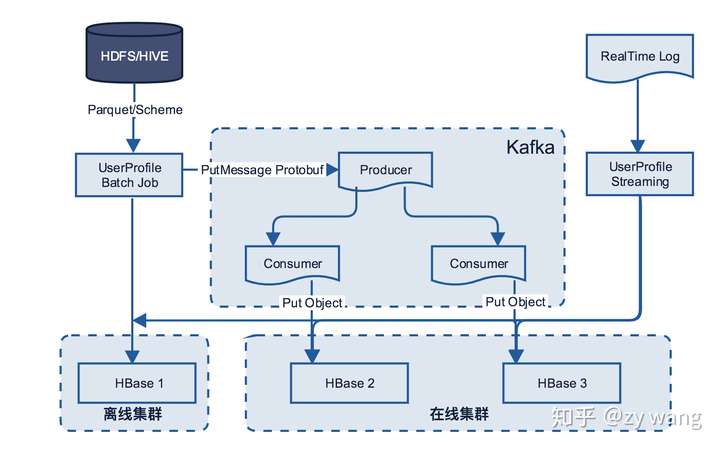
用户模型存储多机房同步架构图
具体实现细节
第一步:定义用于在 Kafka 的 Producer 和 Consumer 中流转的统一数据 Protobuf 格式
message ColumnValue {
required bytes qualifier = 1;
......
}
message PutMessage {
required string tablename = 1;
......
}
第二步:发送需要同步的数据到 Kafka,(如果有必要,需要对数据做相应的格式处理),这里对数据的处理,有两种方式。
第一种:如果程序中有统一的存储到 HBase 的工具(另一个项目是使用自定义的 HBaseHandler,业务层面只生成 tableName,rowKey,columnFamily,column 等值,
由 HBaseHandler 统一构建成 Put 对象,并保存 HBase 中),这种方式在业务层面改动较小,理论上可以直接用原来的格式发给 Kafka,但是如果 HBaseHandler 处理的格式和 PutMessage 格式有不符的地方,做下适配即可。
/**
* tableName: hbase table name
* rdd: RDD[(rowkey, family, column, value)]
*/
def convert(tableName: String, rdd: RDD): RDD = {
rdd.map {
case (rowKey: String, family: String, column: String, value: Array[Byte]) =>
val message = KafkaMessages.newBuilder()
val columnValue = ColumnValue.newBuilder()
columnValue.set
......
(rowKey, message.build().toByteArray)
}
}
第二种:程序在 RDD 中直接构建 HBase 的 Put 对象,调用 PairRDD 的 saveAsNewAPIHadoopDataset 方法保存到 HBase 中。
此种情况,为了兼容已有的代码,做到代码和业务逻辑的改动最小,发送到 Kafka 时,需要将 Put 对象转换为上面定义的 PutMessage Protobuf 格式,然后发送给 Kafka。
/**
* tableName: hbase table namne
* rdd: RDD[(rowKey, put)]
*/
def convert(tableName: String, familyNames: Array[String], rdd: RDD): RDD = {
rdd.map {
case (_, put: Put) =>
val message = PutMessage.newBuilder()
for(familyName <- familyNames){
if(put.getFamilyMap().get(Bytes.toBytes(familyName))!=null){
val keyValueList = put.getFamilyMap()
.asInstanceOf[java.util.ArrayList[KeyValue]].asScala
for( keyvalue <- keyValueList){
message.setRowkey(ByteString.copyFrom(keyvalue.getRow))
......
}
message.setTablename(tableName)
}
}
(null, message.build().toByteArray)
}
}
第三步:发送到 Kafka,不同的表发送到不同的 Topic,对每个 Topic 的消费做监控。
/**
* 发送 rdd 中的内容到 brokers 的指定 topic 中
* tableName: hbase table namne
* rdd: RDD[(rowKey, put)]
*/
def send[T](brokers: String,
rdd: RDD[(String, T)],
topic: String)(implicit cTag: ClassTag[T]): Unit = {
rdd.foreachPartition(partitionOfRecords => {
val producer = getProducer[T](brokers)
partitionOfRecords.map(r => new ProducerRecord[String, T](topic, r._1, r._2))
.foreach(m => producer.send(m))
producer.close()
})
}
第四步:另启动 Streaming Consumer 或者服务消费 Kafka 中内容,将 putMessage 的 Protobuf 格式转成 HBase 的 put 对象,同时写入到在线 HBase 集群中。 Streaming 消费Kafka ,不同的表发送到不同的 Topic,对每个 Topic 的消费做监控。
val toHBaseTagsTopic = validKafkaStreamTagsTopic.map {
record =>
val tableName_r = record.getTablename()
val put = new Put(record.getRowkey.toByteArray)
for (cv <- record.getColumnsList) {
put.addColumn(record.getFamily.toByteArray)
......
}
if(put.isEmpty){
(new ImmutableBytesWritable(), null)
}else{
(new ImmutableBytesWritable(), put)
}
}.filter(_._2!=null)
if(!isClean) {
toHbaseTagsTopic.foreachRDD { rdd =>
rdd.saveAsNewAPIHadoopDataset(
AccessUtils.createOutputTableConfiguration(
constants.Constants.NAMESPACE + ":" + constants.Constants.TAGS_TOPIC_TABLE_NAME
)
)
}
}
val consumer = new KafkaConsumer[String, Array[Byte]](probs)
consumer.subscribe(topics)
val records = consumer.poll(100)
for (p <- records.partitions) {
val recordsOfPartition = records.records(p)
recordsOfPartition.foreach { r =>
Try(KafkaMessages.parseFrom(r.value())) match {
case Success(record) =>
val tableName = record.getTableName
if (validateTables.contains(tableName)) {
val messageType = record.getType
......
try {
val columns = record.getColumnsList.map(c => (c.getColumn, c.getValue.toByteArray)).toArray
HBaseHandler.write(tableName)
......
} catch {
case ex: Throwable =>
LOG.error("write hbase fail")
HaloClient.increment(s"content_write_hbase_fail")
}
} else {
LOG.error(s"table $tableName is valid")
}
}
}
//update offset
val lastOffset = recordsOfPartition.get(recordsOfPartition.size - 1).offset()
consumer.commitSync(java.util.Collections.singletonMap(p, new OffsetAndMetadata(lastOffset + 1)))
}
结语
最后,目前采用的由应用控制和管理在线离线集群的同步机制,在随着平台多机房项目的推动下,平台将推出 HBase 的统一同步机制 HRP (HBase Replication Proxy),届时业务部门可以将更多的时间和精力集中在模型优化层面。
Reference
[1] HBase Cluster Replication
[2] 通过 BulkLoad 快速将海量数据导入到 HBase
[3] HBase Replication 源码分析
[4] HBase 源码之 TableRecordWriter
[5] HBase 源码之 TableOutputFormat
[6] Spark2.1.1写入 HBase 的三种方法性能对比
HBase实践案例:知乎 AI 用户模型服务性能优化实践的更多相关文章
- JVM内存模型和性能优化 转
JVM内存模型和性能优化 JVM内存模型优点 内置基于内存的并发模型: 多线程机制 同步锁Synchronization 大量线程安全型库包支持 基于内存的并发机制,粒度灵活控制,灵活度高于 ...
- 让Elasticsearch飞起来!——性能优化实践干货
原文:让Elasticsearch飞起来!--性能优化实践干货 版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明. 本文链接:https://blog ...
- etcd 性能优化实践
https://mp.weixin.qq.com/s/lD2b-DZyvRJ3qWqmlvHpxg 从零开始入门 K8s | etcd 性能优化实践 原创 陈星宇 阿里巴巴云原生 2019-12-16 ...
- 直播推流端弱网优化策略 | 直播 SDK 性能优化实践
弱网优化的场景 网络直播行业经过一年多的快速发展,衍生出了各种各样的玩法.最早的网络直播是主播坐在 PC 前,安装好专业的直播设备(如摄像头和麦克风),然后才能开始直播.后来随着手机性能的提升和直播技 ...
- 手游录屏直播技术详解 | 直播 SDK 性能优化实践
在上期<直播推流端弱网优化策略 >中,我们介绍了直播推流端是如何优化的.本期,将介绍手游直播中录屏的实现方式. 直播经过一年左右的快速发展,衍生出越来越丰富的业务形式,也覆盖越来越广的应用 ...
- 转:携程App的网络性能优化实践
http://kb.cnblogs.com/page/519824/ 携程App的网络性能优化实践 受益匪浅的一篇文章,让我知道网络交互并不是简单的传输和接受数据.真正的难点在于后面的性能优化 下面对 ...
- Redis各种数据结构性能数据对比和性能优化实践
很对不起大家,又是一篇乱序的文章,但是满满的干货,来源于实践,相信大家会有所收获.里面穿插一些感悟和生活故事,可以忽略不看.不过听大家普遍的反馈说这是其中最喜欢看的部分,好吧,就当学习之后轻松一下. ...
- Hadoop YARN:调度性能优化实践(转)
https://tech.meituan.com/2019/08/01/hadoop-yarn-scheduling-performance-optimization-practice.html 文章 ...
- 第17 章 : 深入理解 etcd:etcd 性能优化实践
深入理解 etcd:etcd 性能优化实践 本文将主要分享以下五方面的内容: etcd 前节课程回顾复习: 理解 etcd 性能: etcd 性能优化 -server 端: etcd 性能优化 -cl ...
随机推荐
- K60平台智能车开发工作随手记
(图片仅为示例,并不一定固定为这种造型) 第十二届全国大学生智能汽车竞赛有一个分项是光电四轮车的竞速(任务A),Seven她们组采购到的配件使用了freescale Crotex-M4内核的CPU,T ...
- 基础才是重中之重~lock和monitor的区别
回到目录 Monitor的介绍 1.Monitor.Enter(object)方法是获取锁,Monitor.Exit(object)方法是释放锁,这就是Monitor最常用的两个方法,当然在使用过程中 ...
- 基于N-Gram判断句子是否通顺
完整代码实现及训练与测试数据:click me 一.任务描述 自然语言通顺与否的判定,即给定一个句子,要求判定所给的句子是否通顺. 二.问题探索与分析 拿到这个问题便开 ...
- 【c#】RabbitMQ学习文档(四)Routing(路由)
(使用Net客户端) 在上一个教程中,我们构建了一个简单的日志系统,我们能够向许多消息接受者广播发送日志消息. 在本教程中,我们将为其添加一项功能 ,这个功能是我们将只订阅消息的一个子集成为可能. 例 ...
- JavaScript的事件及异常捕获
事件处理 [onClick]单击事件.[onMouseOver]鼠标经过事件.[onMouseOut]鼠标移出事件.[onChange]文本内容改变事件.[onSelect]文本被框选事件.[onFo ...
- Tomcat配置文件Executor元素属性介绍
该元素可用于Tomcat 6.0.11以及更高版本. 允许您为一个Service的所有Connector配置一个共享线程池.在运行多个Connector的状况下,这样处理非常有用,而且每个Connec ...
- [PHP] curl访问https与CA证书问题
CA证书,用来在调用HTTPS资源的时候,验证对方网站是否是CA颁布的证书,而不是自己随便生成的 curl命令1.需要下载CA证书 文件地址是 http://curl.haxx.se/ca/cacer ...
- [Linux] 搭建rsync服务端
rsync是unix/linux下同步文件的一个高效算法,它能同步更新两处计算机的文件与目录,并适当利用查找文件中的不同块以减少数据传输. Linux守护进程的运行方式:1.独立运行(stand-al ...
- 解决java web中safari浏览器下载后文件中文乱码问题
解决java web中safari浏览器下载后文件中文乱码问题 String fileName = "测试文件.doc"; String userAgent = request.g ...
- Java开发笔记(六十五)集合:HashSet和TreeSet
对于相同类型的一组数据,虽然Java已经提供了数组加以表达,但是数组的结构实在太简单了,第一它无法直接添加新元素,第二它只能按照线性排列,故而数组用于基本的操作倒还凑合,若要用于复杂的处理就无法胜任了 ...