java并发编程实践——王宝令(极客时间)学习笔记
1、并发
分工:如何高效地拆解任务并分配给线程
同步:线程之间如何协作
互斥:保证同一时刻只允许一个线程访问共享资源
Fork/Join 框架就是一种分工模式,CountDownLatch 就是一种典型的同步方式,而可重入锁则是一种互斥手段。
2、可见性、原子性、有序性

(1)可见性:缓存导致
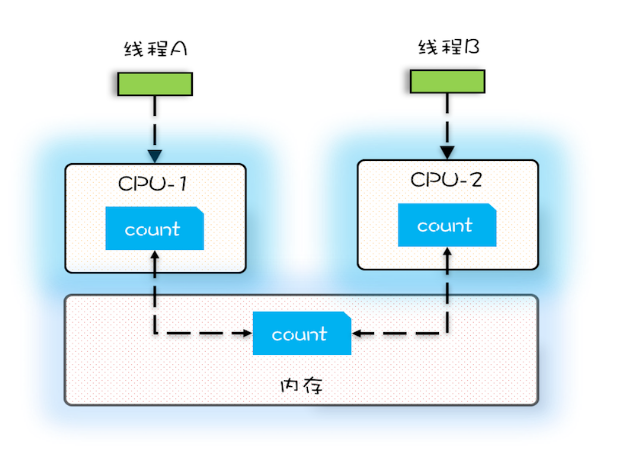
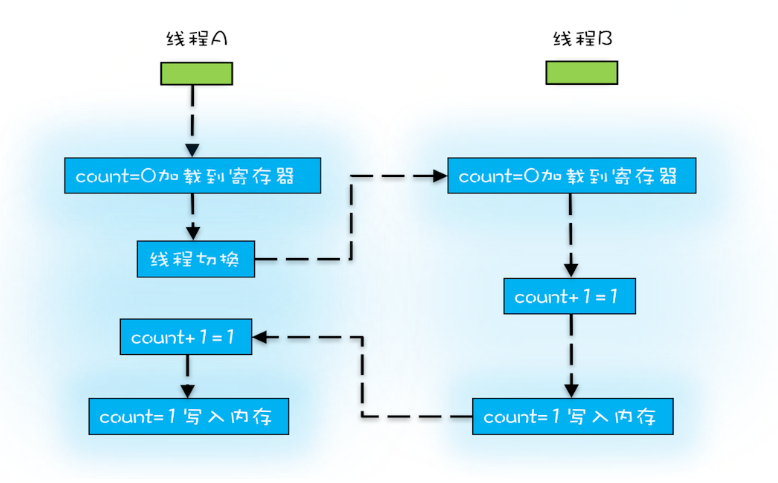
(2)原子性:线程切换
count+=1

(3)有序性:编译优化
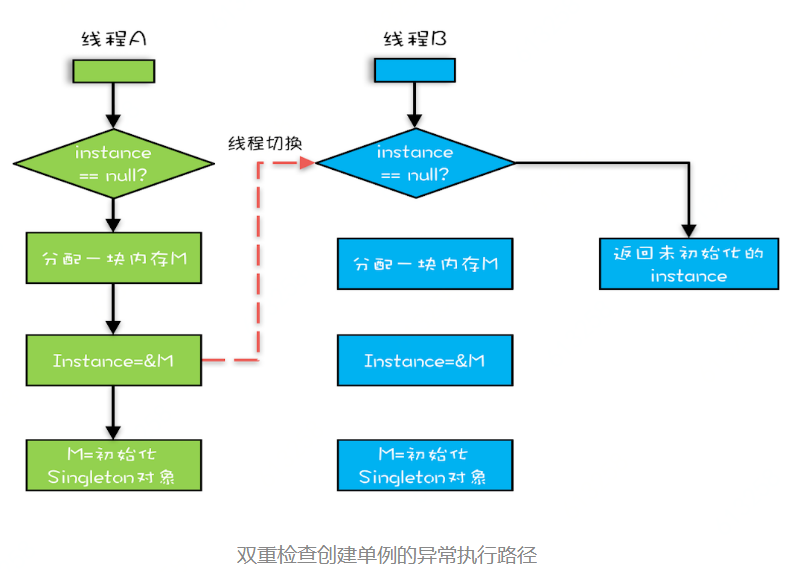
3、java内存模型
(1)可见性:缓存导致-----按需禁用缓存
(2)有序性:编译优化-----按需禁用
volatile int x=0;(该变量的读写,不使用cpu缓存,直接使用内存读取或者写入)
(3)原子性:同一时刻,只有一个线程执行,互斥。
synchronized
4、死锁
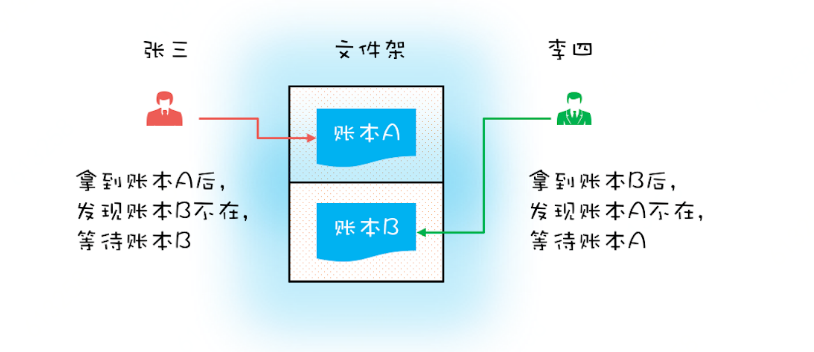
死锁发生的条件:
(1)互斥,共享资源x和y只能被一个线程占用
(2)占有且等待,线程 T1 已经取得共享资源 X,在等待共享资源 Y 的时候,不释放共享资源 X;
破坏占用且等待条件:一次性申请所有资源
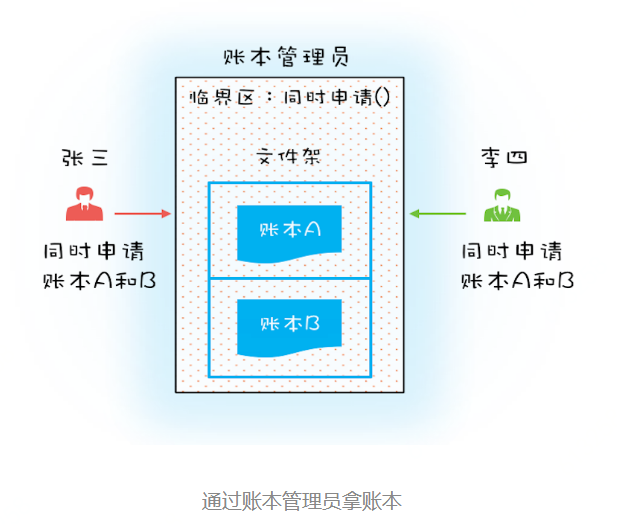
(3)不可抢占,其他线程不能强行抢占线程 T1 占有的资源;
破坏不可强占条件
(4)循环等待,线程 T1 等待线程 T2 占有的资源,线程 T2 等待线程 T1 占有的资源,就是循环等待。
破坏循环等待条件:
wait和sleep区别
1:wait释放资源,sleep不释放资源
2:wait需要被唤醒,sleep不需要
3:wait需要获取到监视器,否则抛异常,sleep不需要
4:wait是object顶级父类的方法,sleep则是Thread的方法
5.CountDownLatch和CyclicBarrier:如何让多线程步调一致?(主线程等待子线程结束)
Thread t1 = new Thread(() -> {
try {
Thread.sleep(1000);
System.out.println(Thread.currentThread().getName());
} catch (InterruptedException e) {
e.printStackTrace();
}
});
t1.start();
Thread t2 = new Thread(() -> {
try {
Thread.sleep(2000);
System.out.println(Thread.currentThread().getName());
} catch (InterruptedException e) {
e.printStackTrace();
}
});
t2.start();
//实现等待
t1.join();
t2.join();
System.out.println("=============");
线程池
Executor executor = Executors.newFixedThreadPool(2);
CountDownLatch latch = new CountDownLatch(2);
executor.execute(()->{
try {
Thread.sleep(1000);
System.out.println(Thread.currentThread().getName());
latch.countDown();
} catch (InterruptedException e) {
e.printStackTrace();
} });
executor.execute(()->{
try {
Thread.sleep(2000);
System.out.println(Thread.currentThread().getName());
latch.countDown();
} catch (InterruptedException e) {
e.printStackTrace();
}
});
latch.await();
System.out.println("=============");
CountDownLatch 主要用来解决一个线程等待多个线程的场景。(CountDownLatch 的计数器是不能循环利用的,也就是说一旦计数器减到 0,再有线程调用 await(),该线程会直接通过。)
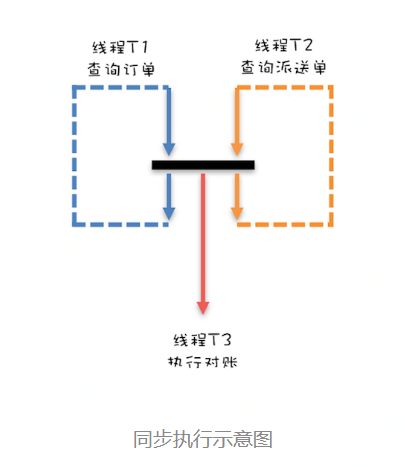
CyclicBarrier ---------- A线程执行,B线程执行,A、B其中一个线程等到AB执行完成再执行(不是主线程,且是异步的)
参考:https://www.cnblogs.com/dolphin0520/p/3920397.html
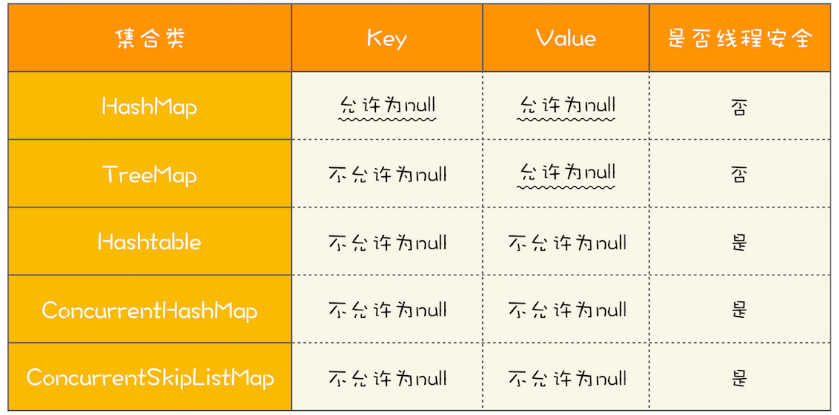
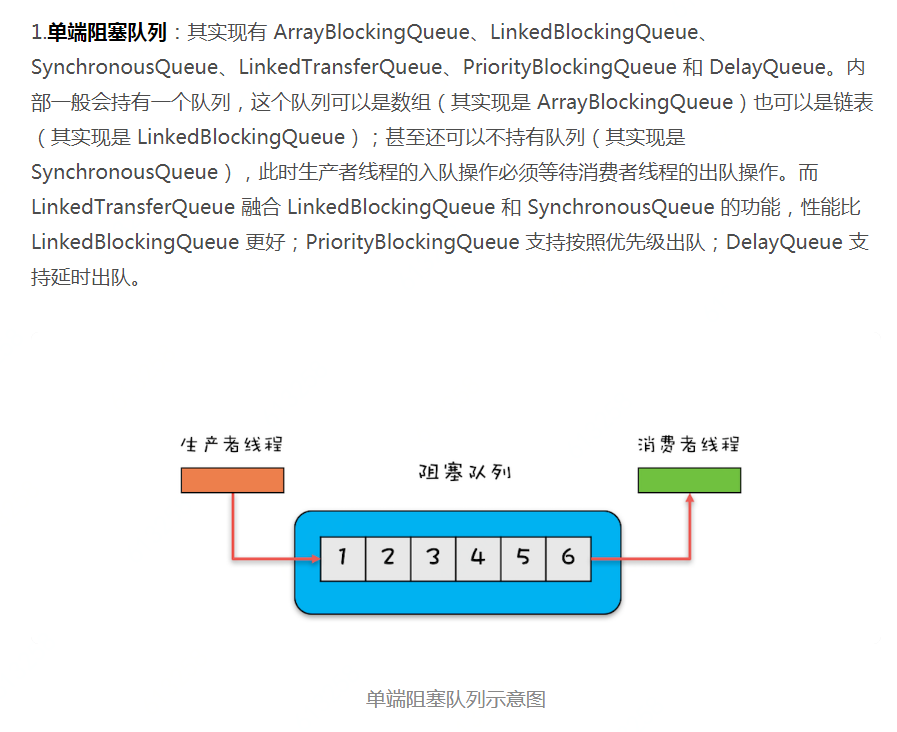
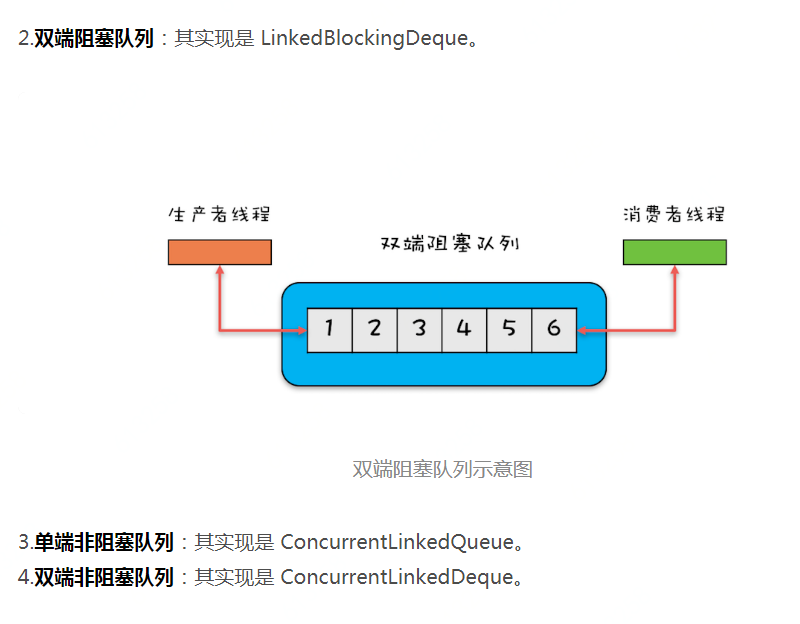
6.并发容器
List、Map、Set、Queue
非线程安全:ArrayList、HashMap
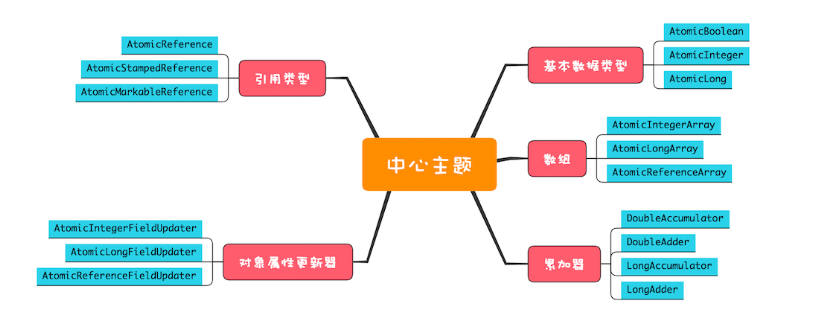
7.原子类
8.线程池、Executor
ThreadPoolExecutor
线程池实际上是生产者 - 消费者模式
ThreadPoolExecutor(
int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)
9.Future
ExecutorService executor
= Executors.newFixedThreadPool(1);
// 创建 Result 对象 r
Result r = new Result();
r.setAAA(a);
// 提交任务
Future<Result> future =
executor.submit(new Task(r), r);
Result fr = future.get();
// 下面等式成立
fr === r;
fr.getAAA() === a;
fr.getXXX() === x class Task implements Runnable{
Result r;
// 通过构造函数传入 result
Task(Result r){
this.r = r;
}
void run() {
// 可以操作 result
a = r.getAAA();
r.setXXX(x);
}
}
// 创建 FutureTask
FutureTask<Integer> futureTask
= new FutureTask<>(()-> 1+2);
// 创建线程池
ExecutorService es =
Executors.newCachedThreadPool();
// 提交 FutureTask
es.submit(futureTask);
// 获取计算结果
Integer result = futureTask.get();
// 创建 FutureTask
FutureTask<Integer> futureTask
= new FutureTask<>(()-> 1+2);
// 创建并启动线程
Thread T1 = new Thread(futureTask);
T1.start();
// 获取计算结果
Integer result = futureTask.get();
// 创建任务 T2 的 FutureTask
FutureTask<String> ft2
= new FutureTask<>(new T2Task());
// 创建任务 T1 的 FutureTask
FutureTask<String> ft1
= new FutureTask<>(new T1Task(ft2));
// 线程 T1 执行任务 ft1
Thread T1 = new Thread(ft1);
T1.start();
// 线程 T2 执行任务 ft2
Thread T2 = new Thread(ft2);
T2.start();
// 等待线程 T1 执行结果
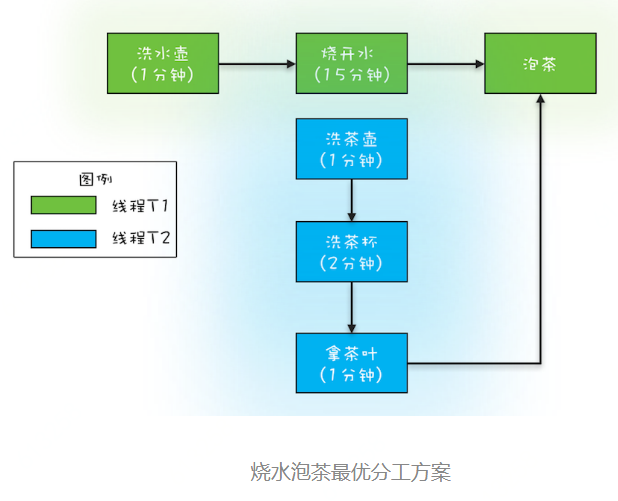
System.out.println(ft1.get()); // T1Task 需要执行的任务:
// 洗水壶、烧开水、泡茶
class T1Task implements Callable<String>{
FutureTask<String> ft2;
// T1 任务需要 T2 任务的 FutureTask
T1Task(FutureTask<String> ft2){
this.ft2 = ft2;
}
@Override
String call() throws Exception {
System.out.println("T1: 洗水壶...");
TimeUnit.SECONDS.sleep(1); System.out.println("T1: 烧开水...");
TimeUnit.SECONDS.sleep(15);
// 获取 T2 线程的茶叶
String tf = ft2.get();
System.out.println("T1: 拿到茶叶:"+tf); System.out.println("T1: 泡茶...");
return " 上茶:" + tf;
}
}
// T2Task 需要执行的任务:
// 洗茶壶、洗茶杯、拿茶叶
class T2Task implements Callable<String> {
@Override
String call() throws Exception {
System.out.println("T2: 洗茶壶...");
TimeUnit.SECONDS.sleep(1); System.out.println("T2: 洗茶杯...");
TimeUnit.SECONDS.sleep(2); System.out.println("T2: 拿茶叶...");
TimeUnit.SECONDS.sleep(1);
return " 龙井 ";
}
}
// 一次执行结果:
T1: 洗水壶...
T2: 洗茶壶...
T1: 烧开水...
T2: 洗茶杯...
T2: 拿茶叶...
T1: 拿到茶叶: 龙井
T1: 泡茶...
上茶: 龙井
10.CompletableFuture
// 任务 1:洗水壶 -> 烧开水
CompletableFuture<Void> f1 =
CompletableFuture.runAsync(()->{
System.out.println("T1: 洗水壶...");
sleep(1, TimeUnit.SECONDS); System.out.println("T1: 烧开水...");
sleep(15, TimeUnit.SECONDS);
});
// 任务 2:洗茶壶 -> 洗茶杯 -> 拿茶叶
CompletableFuture<String> f2 =
CompletableFuture.supplyAsync(()->{
System.out.println("T2: 洗茶壶...");
sleep(1, TimeUnit.SECONDS); System.out.println("T2: 洗茶杯...");
sleep(2, TimeUnit.SECONDS); System.out.println("T2: 拿茶叶...");
sleep(1, TimeUnit.SECONDS);
return " 龙井 ";
});
// 任务 3:任务 1 和任务 2 完成后执行:泡茶
CompletableFuture<String> f3 =
f1.thenCombine(f2, (__, tf)->{
System.out.println("T1: 拿到茶叶:" + tf);
System.out.println("T1: 泡茶...");
return " 上茶:" + tf;
});
// 等待任务 3 执行结果
System.out.println(f3.join()); void sleep(int t, TimeUnit u) {
try {
u.sleep(t);
}catch(InterruptedException e){}
}
// 一次执行结果:
T1: 洗水壶...
T2: 洗茶壶...
T1: 烧开水...
T2: 洗茶杯...
T2: 拿茶叶...
T1: 拿到茶叶: 龙井
T1: 泡茶...
上茶: 龙井
11.CompletionService
参考: http://blog.csdn.net/lmj623565791/article/details/27250059 https://www.cnblogs.com/hrhguanli/p/3998865.html
普通情况下,我们使用Runnable作为主要的任务表示形式,可是Runnable是一种有非常大局限的抽象,run方法中仅仅能记录日志,打印,或者把数据汇总入某个容器(一方面内存消耗大,还有一方面须要控制同步,效率非常大的限制),总之不能返回运行的结果;比方同一时候1000个任务去网络上抓取数据,然后将抓取到的数据进行处理(处理方式不定),我认为最好的方式就是提供回调接口,把处理的方式最为回调传进去;可是如今我们有了更好的方式实现:CompletionService + Callable
Callable的call方法能够返回运行的结果;
CompletionService将Executor(线程池)和BlockingQueue(堵塞队列)结合在一起,同一时候使用Callable作为任务的基本单元,整个过程就是生产者不断把Callable任务放入堵塞对了,Executor作为消费者不断把任务取出来运行,并返回结果;
优势:
a、堵塞队列防止了内存中排队等待的任务过多,造成内存溢出(毕竟一般生产者速度比較快,比方爬虫准备好网址和规则,就去运行了,运行起来(消费者)还是比較慢的)
b、CompletionService能够实现,哪个任务先运行完毕就返回,而不是按顺序返回,这样能够极大的提升效率;
package com.zhy.concurrency.completionService; import java.util.Random;
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.Callable;
import java.util.concurrent.CompletionService;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.ExecutorCompletionService;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.Future;
import java.util.concurrent.LinkedBlockingDeque; /**
* 将Executor和BlockingQueue功能融合在一起,能够将Callable的任务提交给它来运行, 然后使用take()方法获得已经完毕的结果
*
* @author zhy
*
*/
public class CompletionServiceDemo
{ public static void main(String[] args) throws InterruptedException,
ExecutionException
{
/**
* 内部维护11个线程的线程池
*/
ExecutorService exec = Executors.newFixedThreadPool(11);
/**
* 容量为10的堵塞队列
*/
final BlockingQueue<Future<Integer>> queue = new LinkedBlockingDeque<Future<Integer>>(
10);
//实例化CompletionService
final CompletionService<Integer> completionService = new ExecutorCompletionService<Integer>(
exec, queue); /**
* 模拟瞬间产生10个任务,且每一个任务运行时间不一致
*/
for (int i = 0; i < 10; i++)
{
completionService.submit(new Callable<Integer>()
{
@Override
public Integer call() throws Exception
{
int ran = new Random().nextInt(1000);
Thread.sleep(ran);
System.out.println(Thread.currentThread().getName()
+ " 歇息了 " + ran);
return ran;
}
});
} /**
* 马上输出结果
*/
for (int i = 0; i < 10; i++)
{
try
{
//谁最先运行完毕,直接返回
Future<Integer> f = completionService.take();
System.out.println(f.get());
} catch (InterruptedException e)
{
e.printStackTrace();
} catch (ExecutionException e)
{
e.printStackTrace();
}
} exec.shutdown(); } }
输出结果:
pool-1-thread-4 歇息了 52
52
pool-1-thread-1 歇息了 59
59
pool-1-thread-10 歇息了 215
215
pool-1-thread-9 歇息了 352
352
pool-1-thread-5 歇息了 389
389
pool-1-thread-3 歇息了 589
589
pool-1-thread-2 歇息了 794
794
pool-1-thread-7 歇息了 805
805
pool-1-thread-6 歇息了 909
909
pool-1-thread-8 歇息了 987
987
2.ExecutorService.invokeAll
ExecutorService的invokeAll方法也能批量运行任务,并批量返回结果,可是呢,有个我认为非常致命的缺点,必须等待全部的任务运行完毕后统一返回,一方面内存持有的时间长;还有一方面响应性也有一定的影响,毕竟大家都喜欢看看刷刷的运行结果输出,而不是苦苦的等待;
package com.zhy.concurrency.executors; import java.util.ArrayList;
import java.util.List;
import java.util.Random;
import java.util.concurrent.Callable;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.Future; public class TestInvokeAll
{ public static void main(String[] args) throws InterruptedException,
ExecutionException
{
ExecutorService exec = Executors.newFixedThreadPool(10); List<Callable<Integer>> tasks = new ArrayList<Callable<Integer>>();
Callable<Integer> task = null;
for (int i = 0; i < 10; i++)
{
task = new Callable<Integer>()
{
@Override
public Integer call() throws Exception
{
int ran = new Random().nextInt(1000);
Thread.sleep(ran);
System.out.println(Thread.currentThread().getName()+" 歇息了 " + ran );
return ran;
}
}; tasks.add(task);
} long s = System.currentTimeMillis(); List<Future<Integer>> results = exec.invokeAll(tasks); System.out.println("运行任务消耗了 :" + (System.currentTimeMillis() - s) +"毫秒"); for (int i = 0; i < results.size(); i++)
{
try
{
System.out.println(results.get(i).get());
} catch (Exception e)
{
e.printStackTrace();
}
} exec.shutdown(); } } 运行结果:
pool-1-thread-10 歇息了 1
pool-1-thread-5 歇息了 59
pool-1-thread-6 歇息了 128
pool-1-thread-1 歇息了 146
pool-1-thread-3 歇息了 158
pool-1-thread-7 歇息了 387
pool-1-thread-9 歇息了 486
pool-1-thread-8 歇息了 606
pool-1-thread-4 歇息了 707
pool-1-thread-2 歇息了 817
运行任务消耗了 :819毫秒
146
817
158
707
59
128
387
606
486
1
12.Fork/Join 单机版本的MapReduce
分治任务
static void main(String[] args){
// 创建分治任务线程池
ForkJoinPool fjp =
new ForkJoinPool(4);
// 创建分治任务
Fibonacci fib =
new Fibonacci(30);
// 启动分治任务
Integer result =
fjp.invoke(fib);
// 输出结果
System.out.println(result);
}
// 递归任务
static class Fibonacci extends
RecursiveTask<Integer>{
final int n;
Fibonacci(int n){this.n = n;}
protected Integer compute(){
if (n <= 1)
return n;
Fibonacci f1 =
new Fibonacci(n - 1);
// 创建子任务
f1.fork();
Fibonacci f2 =
new Fibonacci(n - 2);
// 等待子任务结果,并合并结果
return f2.compute() + f1.join();
}
}
13.ThreadLocal
http://www.iocoder.cn/JUC/sike/ThreadLocal/
java并发编程实践——王宝令(极客时间)学习笔记的更多相关文章
- MYSQL实战-------丁奇(极客时间)学习笔记
1.基础架构:一条sql查询语句是如何执行的? mysql> select * from T where ID=10: 2.基础架构:一条sql更新语句是如何执行的? mysql> upd ...
- DDL创建数据库,表以及约束(极客时间学习笔记)
DDL DDL是DBMS的核心组件,是SQL的重要组成部分. DDL的正确性和稳定性是整个SQL发型的重要基础. DDL的基础语法及设计工具 DDL的英文是Data Definition Langua ...
- SQL的概念与发展 - 极客时间学习笔记
了解SQL SQL的两个重要标准是SQL92和SQL99. SQL语言的划分 DDL,也叫Data Definition Language,也就是数据定义语言,用来定义数据库对象,包括数据库.数据表和 ...
- MySQL的过滤(极客时间学习笔记)
数据过滤 SQL的数据过滤, 可以减少不必要的数据行, 从而可以达到提升查询效率的效果. 比较运算符 在SQL中, 使用WHERE子句对条件进行筛选, 筛选的时候比较运算符是很重要. 上面的比较运算符 ...
- MySQL的select(极客时间学习笔记)
查询语句 首先, 准备数据, 地址是: https://github.com/cystanford/sql_heros_data, 除了id以外, 24个字段的含义如下: 查询 查询分为单列查询, 多 ...
- Mysql中的sql是如何执行的 --- 极客时间学习笔记
MySQL中的SQL是如何执行的 MySQL是典型的C/S架构,也就是Client/Server架构,服务器端程序使用的mysqld.整体的MySQL流程如下图所示: MySQL是有三层组成: 连接层 ...
- [Java 并发] Java并发编程实践 思维导图 - 第一章 简单介绍
阅读<Java并发编程实践>一书后整理的思维导图.
- [Java 并发] Java并发编程实践 思维导图 - 第二章 线程安全性
依据<Java并发编程实践>一书整理的思维导图.
- 读Java并发编程实践中,向已有线程安全类添加功能--客户端加锁实现示例
在Java并发编程实践中4.4中提到向客户端加锁的方法.此为验证示例,写的不好,但可以看出结果来. package com.blackbread.test; import java.util.Arra ...
随机推荐
- 【代码笔记】Web-CSS-CSS样式列表(url)
一,效果图. 二,代码. <!DOCTYPE html> <html> <head> <meta charset="utf-8"> ...
- iOS-----------关于组件化
打一个比较形象的比喻,把APP比作我们的人体,把胳膊.大腿.心.肝.肺这些人体器官比作组件,各个器官分别负责他们各自的功能,但是他们之间也有主次之分,试想我们的胳膊.大腿等是不能独立完成某个任务的 ...
- linux下的qt串口通信
1.linux下的qt串口通信跟windows唯一的差别就是端口号的名字,windows下面是COM,而linux是ttyUSB0的路径 2.一般情况下linux插上USB转串口线就可以在/dev/目 ...
- Android预置Apk方法
这一套8.0过时了 需要修改pms代码 否则apk会被pms删除掉 因为工作需要,经常要开发和合入系统App,所以在此开篇作为收集和记录Android合入系统应用的方法,以备日后查阅. 一.预置apk ...
- PJSUA2开发文档--第十二章 PJSUA2 API 参考手册
12 PJSUA2 API 参考手册 12.1 endpoint.hpp PJSUA2基本代理操作. namespace pj PJSUA2 API在pj命名空间内. 12.1.1 class En ...
- SQL Server非域(跨域)环境下镜像(Mirror)的搭建步骤及注意事项
在实际的生产环境下,我们经常需要跨域进行数据备份,而创建Mirror是其中一个方案.但跨域创建Mirror要相对复杂的多,需要借助证书进行搭建. 下面我们将具体的步骤总结如下: 第一部分 创建证书 S ...
- 指定IP地址进行远程访问服务器设置方法(windows系统)
我们有很多服务器经常受到外界网络的干扰,入侵者们通过扫描3389端口爆破密码非法进入我们的服务器,这时,我们可以配置服务器IP 安全策略来限制一些IP访问,大大提高了服务器的安全. 实验环境: ...
- Thread中的join()方法
package com.qjc.thread; public class JoinExcemple { // join方法就是用来同步的 public static void main(String[ ...
- 【Linux基础】查看硬件信息-内存和硬盘
1.使用free命令查看内存使用 (1)内存总量大小:查看Mem中的total值3697M free -m total used free shared buffers cached -/+ buf ...
- day 9~11 函数
今日内容 '''函数四个组成部分函数名:保存的是函数的地址,是调用函数的依据函数体:就是执行特定功能的代码块函数返回值:代码块执行的结果反馈函数参数:完成功能需要的条件信息1.函数的概念2.函数的定 ...