nsq (三) 消息传输的可靠性和持久化[二]diskqueue
剖析nsq消息队列-目录
上一篇主要说了一下nsq是如何保证消息被消费端成功消费,大概提了一下消息的持久化,--mem-queue-size 设置为 0,所有的消息将会存储到磁盘。
总有人说nsq的持久化问题,消除疑虑的方法就是阅读原码做benchmark测试,个人感觉nsq还是很靠谱的。
nsq自己实现了一个先进先出的消息文件队列go-diskqueue是把消息保存到本地文件内,很值得分析一下他的实现过程。
整体处理逻辑
go-diskqueue 会启动一个gorouting进行读写数据也就是方法ioLoop
会根据你设置的参数来进行数据的读写,流程图如下
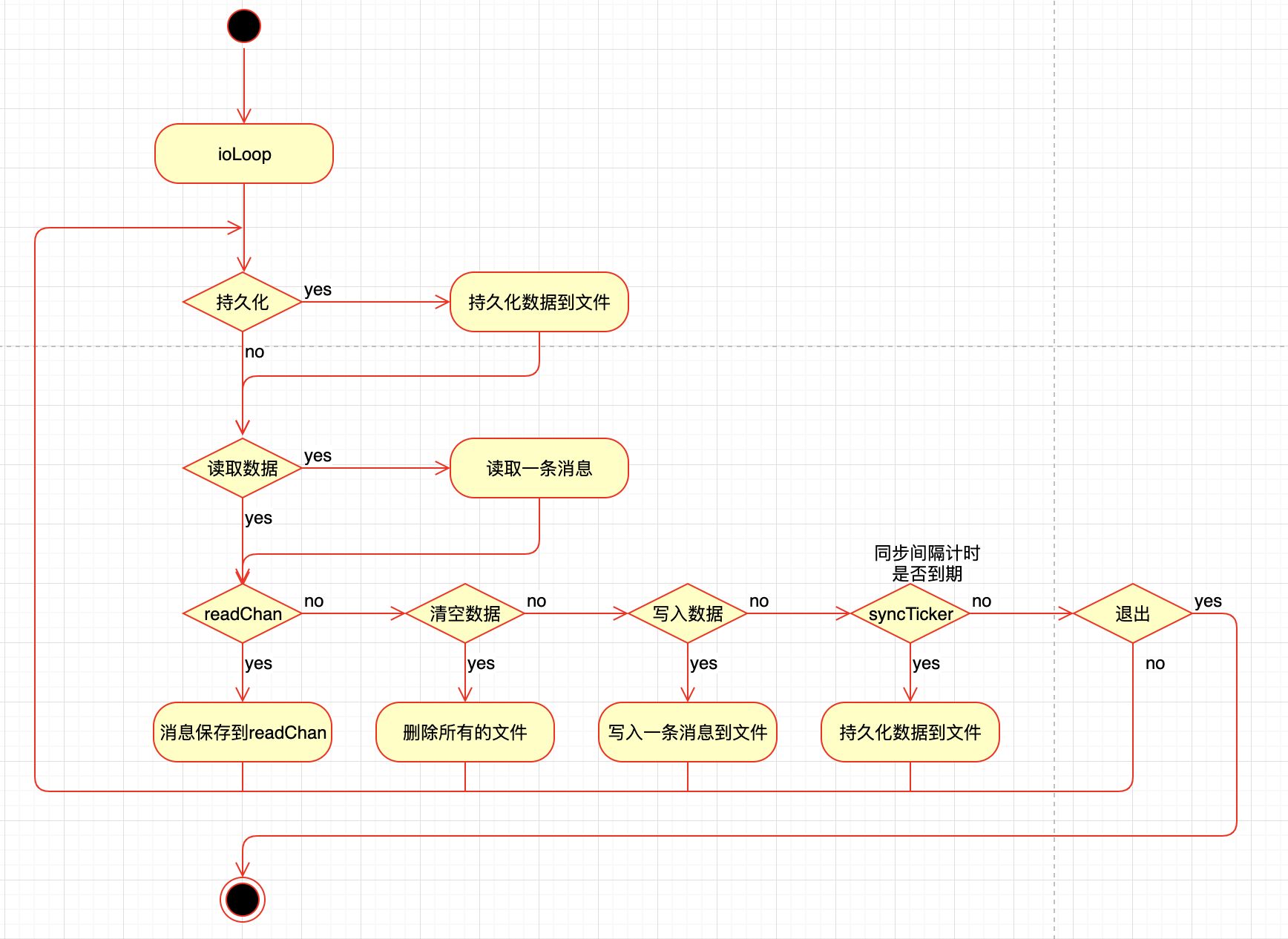
这个图画的也不是特别的准确
ioLoop用的是select并不是if else当有多个条件为true时,会随机选一个进行执行
nsq 生成的数据大致如下:
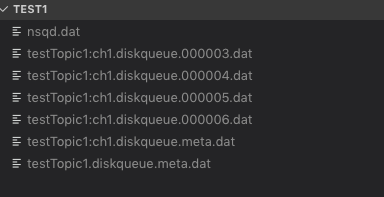
xxxx.diskqueue.meta.dat 元数据保存了未读消息的长度,读取和存入数据的编号和读取位置
xxxx.diskqueue.编号.dat 消息保存的文件,每一个消息的存储:4Byte消息的长度+消息
参数说明
一些主要的参数和约束说明
这些参数的使用在后面的处理逻辑中会提到
// diskQueue implements a filesystem backed FIFO queue
type diskQueue struct {
// run-time state (also persisted to disk)
// 读取数据的位置
readPos int64
// 写入数据的位置
writePos int64
// 读取文件的编号
readFileNum int64
// 写入文件的编号
writeFileNum int64
// 未处理的消息总数
depth int64
// instantiation time metadata
// 每个文件的大小限制
maxBytesPerFile int64 // currently this cannot change once created
// 每条消息的最小大小限制
minMsgSize int32
// 每条消息的最大大小限制
maxMsgSize int32
// 缓存消息有多少条后进行写入
syncEvery int64 // number of writes per fsync
// 自动写入消息文件的时间间隔
syncTimeout time.Duration // duration of time per fsync
exitFlag int32
needSync bool
// keeps track of the position where we have read
// (but not yet sent over readChan)
// 下一条消息的位置
nextReadPos int64
// 下一条消息的文件编号
nextReadFileNum int64
// 读取的文件
readFile *os.File
// 写入的文件
writeFile *os.File
// 读取的buffer
reader *bufio.Reader
// 写入的buffer
writeBuf bytes.Buffer
// exposed via ReadChan()
// 读取数据的channel
readChan chan []byte
//.....
}
数据
元数据
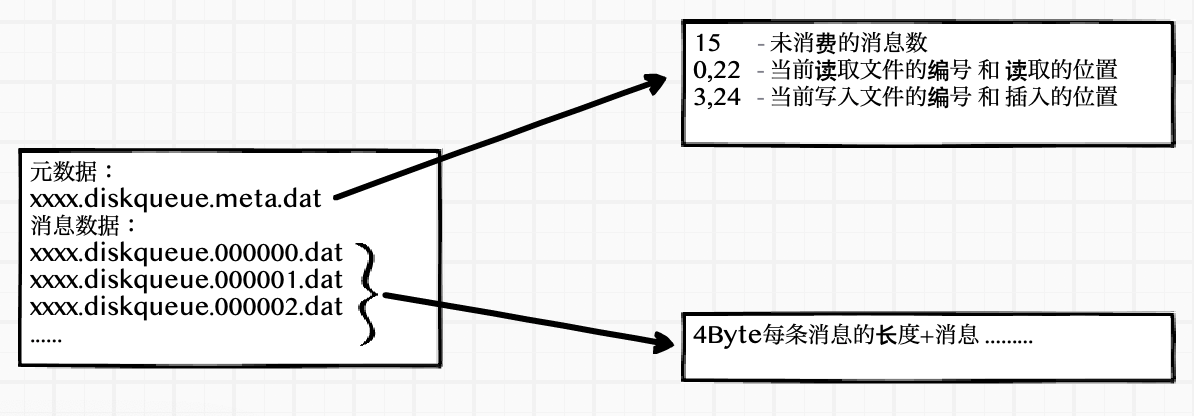
读写数据信息的元数据保存在xxxxx.diskqueue.meta.data文件内主要用到代码里的字段如下
未处理的消息总数 depth
读取文件的编号 readFileNum 读取数据的位置 readPos
写入文件的编号 writeFileNum 写入数据的位置 writePos
真实数据如下
15
0,22
3,24
保存元数据信息
func (d *diskQueue) persistMetaData() error {
// ...
fileName := d.metaDataFileName()
tmpFileName := fmt.Sprintf("%s.%d.tmp", fileName, rand.Int())
// write to tmp file
f, err = os.OpenFile(tmpFileName, os.O_RDWR|os.O_CREATE, 0600)
// 元数据信息
_, err = fmt.Fprintf(f, "%d\n%d,%d\n%d,%d\n",
atomic.LoadInt64(&d.depth),
d.readFileNum, d.readPos,
d.writeFileNum, d.writePos)
// 保存
f.Sync()
f.Close()
// atomically rename
return os.Rename(tmpFileName, fileName)
}
得到元数据信息
func (d *diskQueue) retrieveMetaData() error {
// ...
fileName := d.metaDataFileName()
f, err = os.OpenFile(fileName, os.O_RDONLY, 0600)
// 读取数据并赋值
var depth int64
_, err = fmt.Fscanf(f, "%d\n%d,%d\n%d,%d\n",
&depth,
&d.readFileNum, &d.readPos,
&d.writeFileNum, &d.writePos)
//...
atomic.StoreInt64(&d.depth, depth)
d.nextReadFileNum = d.readFileNum
d.nextReadPos = d.readPos
return nil
}
消息数据
写入一条数据
ioLoop 中发现有数据写入时,会调用writeOne方法,把消息保存到文件内
select {
// ...
case dataWrite := <-d.writeChan:
count++
d.writeResponseChan <- d.writeOne(dataWrite)
// ...
func (d *diskQueue) writeOne(data []byte) error {
var err error
if d.writeFile == nil {
curFileName := d.fileName(d.writeFileNum)
d.writeFile, err = os.OpenFile(curFileName, os.O_RDWR|os.O_CREATE, 0600)
// ...
if d.writePos > 0 {
_, err = d.writeFile.Seek(d.writePos, 0)
// ...
}
}
dataLen := int32(len(data))
// 判断消息的长度是否合法
if dataLen < d.minMsgSize || dataLen > d.maxMsgSize {
return fmt.Errorf("invalid message write size (%d) maxMsgSize=%d", dataLen, d.maxMsgSize)
}
d.writeBuf.Reset()
// 写入4字节的消息长度,以大端序保存
err = binary.Write(&d.writeBuf, binary.BigEndian, dataLen)
if err != nil {
return err
}
// 写入消息
_, err = d.writeBuf.Write(data)
if err != nil {
return err
}
// 写入到文件
_, err = d.writeFile.Write(d.writeBuf.Bytes())
// ...
// 计算写入位置,消息数量加1
totalBytes := int64(4 + dataLen)
d.writePos += totalBytes
atomic.AddInt64(&d.depth, 1)
// 如果写入位置大于 单个文件的最大限制, 则持久化文件到硬盘
if d.writePos > d.maxBytesPerFile {
d.writeFileNum++
d.writePos = 0
// sync every time we start writing to a new file
err = d.sync()
// ...
}
return err
}
写入完消息后,会判断当前的文件大小是否已经已于maxBytesPerFile如果大,就持久化文件到硬盘,然后重新打开一个新编号文件,进行写入。
什么时候持久化文件到硬盘
调用sync()方法会持久化文件到硬盘,然后重新打开一个新编号文件,进行写入。
有几个地方调用会调用这个方法:
- 一个写入文件的条数达到了
syncEvery的值时,也就是初始化时设置的最大的条数。会调用sync() syncTimeout初始化时设置的同步时间间隔,如果这个时间间隔到了,并且写入的文件条数>0的时候,会调用sync()- 还有就是上面说过的
writeOne方法,写入完消息后,会判断当前的文件大小是否已经已于maxBytesPerFile如果大,会调用sync() - 当读取文件时,把整个文件读取完时,会删除这个文件并且会把
needSync设置为true,ioLoop会调用sync() - 还有就是
Close的时候,会调用sync()
func (d *diskQueue) sync() error {
if d.writeFile != nil {
// 把数据 flash到硬盘,关闭文件并设置为 nil
err := d.writeFile.Sync()
if err != nil {
d.writeFile.Close()
d.writeFile = nil
return err
}
}
// 保存元数据信息
err := d.persistMetaData()
// ...
d.needSync = false
return nil
}
读取一条数据
元数据保存着 读取文件的编号 readFileNum 和读取数据的位置 readPos
并且diskQueue暴露出了一个方法来,通过channel来读取数据
func (d *diskQueue) ReadChan() chan []byte {
return d.readChan
}
ioLoop里,当发现读取位置小于写入位置 或者读文件编号小于写文件编号,并且下一个读取位置等于当前位置时才会读取一条数据,然后放在一个外部全局变量 dataRead 里,并把 读取的channel 赋值监听 r = d.readChan,当外部有人读取了消息,则进行moveForward操作
func (d *diskQueue) ioLoop() {
var dataRead []byte
var err error
var count int64
var r chan []byte
for {
// ...
if (d.readFileNum < d.writeFileNum) || (d.readPos < d.writePos) {
if d.nextReadPos == d.readPos {
dataRead, err = d.readOne()
if err != nil {
d.handleReadError()
continue
}
}
r = d.readChan
} else {
r = nil
}
select {
// ...
case r <- dataRead:
count++
// moveForward sets needSync flag if a file is removed
d.moveForward()
// ...
}
}
// ...
}
readOne 从文件里读取一条消息,4个bit的大小,然后读取具体的消息。如果读取位置大于最大文件限制,则close。在moveForward里会进行删除操作
func (d *diskQueue) readOne() ([]byte, error) {
var err error
var msgSize int32
// 如果readFile是nil,打开一个新的
if d.readFile == nil {
curFileName := d.fileName(d.readFileNum)
d.readFile, err = os.OpenFile(curFileName, os.O_RDONLY, 0600)
// ...
d.reader = bufio.NewReader(d.readFile)
}
err = binary.Read(d.reader, binary.BigEndian, &msgSize)
// ...
readBuf := make([]byte, msgSize)
_, err = io.ReadFull(d.reader, readBuf)
totalBytes := int64(4 + msgSize)
// ...
d.nextReadPos = d.readPos + totalBytes
d.nextReadFileNum = d.readFileNum
// 如果读取位置大于最大文件限制,则close。在moveForward里会进行删除操作
if d.nextReadPos > d.maxBytesPerFile {
if d.readFile != nil {
d.readFile.Close()
d.readFile = nil
}
d.nextReadFileNum++
d.nextReadPos = 0
}
return readBuf, nil
}
moveForward方法会查看读取的编号,如果发现下一个编号 和当前的编号不同时,则删除旧的文件。
func (d *diskQueue) moveForward() {
oldReadFileNum := d.readFileNum
d.readFileNum = d.nextReadFileNum
d.readPos = d.nextReadPos
depth := atomic.AddInt64(&d.depth, -1)
// see if we need to clean up the old file
if oldReadFileNum != d.nextReadFileNum {
// sync every time we start reading from a new file
d.needSync = true
fn := d.fileName(oldReadFileNum)
err := os.Remove(fn)
// ...
}
d.checkTailCorruption(depth)
nsq (三) 消息传输的可靠性和持久化[二]diskqueue的更多相关文章
- nsq (三) 消息传输的可靠性和持久化[一]
上两篇帖子主要说了一下nsq的拓扑结构,如何进行故障处理和横向扩展,保证了客户端和服务端的长连接,连接保持了,就要传输数据了,nsq如何保证消息被订阅者消费,如何保证消息不丢失,就是今天要阐述的内容. ...
- 四种途径提高RabbitMQ传输消息数据的可靠性(一)
前言 RabbitMQ虽然有对队列及消息等的一些持久化设置,但其实光光只是这一个是不能够保障数据的可靠性的,下面我们提出这样的质疑: (1)RabbitMQ生产者是不知道自己发布的消息是否已经正确达到 ...
- 深入浅出 JMS(三) - ActiveMQ 消息传输
深入浅出 JMS(三) - ActiveMQ 消息传输 一.消息协商器(Message Broker) broke:消息的交换器,就是对消息进行管理的容器.ActiveMQ 可以创建多个 Broker ...
- RabbitMQ系列(四)--消息如何保证可靠性传输以及幂等性
一.消息如何保证可靠性传输 1.1.可能出现消息丢失的情况 1.Producer在把Message发送Broker的过程中,因为网络问题等发生丢失,或者Message到了Broker,但是出了问题,没 ...
- RabbitMQ原理与相关操作(三)消息持久化
现在聊一下RabbitMQ消息持久化: 问题及方案描述 1.当有多个消费者同时收取消息,且每个消费者在接收消息的同时,还要处理其它的事情,且会消耗很长的时间.在此过程中可能会出现一些意外,比如消息接收 ...
- RabbitMQ(三):消息持久化策略
原文:RabbitMQ(三):消息持久化策略 一.前言 在正常的服务器运行过程中,时常会面临服务器宕机重启的情况,那么我们的消息此时会如何呢?很不幸的事情就是,我们的消息可能会消失,这肯定不是我们希望 ...
- RabbitMQ的消息传输保障三个层级
这里只简单介绍一下三个层级,笔记摘录自<RabbitMQ实战指南>朱忠华作者 消息可靠传输一般是业务系统接入消息中间件时候首要考虑的问题,一般消息中间件的消息传输保障分为三个层级 1 A ...
- 转:TCP为什么要3次握手和4次挥手时等待2MSL、 TCP如何保证消息顺序以及可靠性到达
关于tcp三次握手.四次挥手可以看这里:TCP与UDP的差别以及TCP三次握手.四次挥手 1.TCP为甚要3次握手? 在谢希仁著<计算机网络>第四版中讲“三次握手”的目的是“为了防止已失效 ...
- Rsyslog的三种传输协议简要介绍
rsyslog的三种传输协议 rsyslog 可以理解为多线程增强版的syslog. rsyslog提供了三种远程传输协议,分别是: 1. UDP 传输协议 基于传统UDP协议进行远程日志传输,也是传 ...
随机推荐
- 各种常见文件的hex文件头
我们在做ctf时,经常需要辨认各种文件头,跟大家分享一下一些常见的文件头. 扩展名 文件头标识(HEX) 文件描述 123 00 00 1A 00 05 10 04 Lotus 1-2-3 spr ...
- x509: certificate is valid for 10.96.0.1, 172.18.255.243, not 120.79.23.226
服务器:阿里云服务器 master:120.79.23.226 node:39.108.131.246 系统:Centos 7.4 node节点加入集群中是报错: x509: certificate ...
- 模块的 __name__
模块的 __name__ 每个模块都有一个名称,而模块中的语句可以找到它们所处的模块的名称.这对于确定模块是独立运行的还是被导入进来运行的这一特定目的来说大为有用.正如先前所提到的,当模块第一次被导入 ...
- Windows SDK version 8.1 下载地址
Windows SDK version 8.1 下载地址 https://go.microsoft.com/fwlink/p/?LinkId=323507
- Redis中是如何实现分布式锁的?
分布式锁常见的三种实现方式: 数据库乐观锁: 基于Redis的分布式锁: 基于ZooKeeper的分布式锁. 本地面试考点是,你对Redis使用熟悉吗?Redis中是如何实现分布式锁的. 要点 Red ...
- docker-以安装软件的方式介绍docker部分命令的使用
[root@ipha-dev71- docker]# docker search python # 搜索镜像 [root@ipha-dev71- docker]# docker pull centos ...
- pytest中unicode编码问题(如test_fix.py::Test1::test_s1[\u6d4b\u8bd5-\u6d4b\u8bd5])
现象: 采用如下方式可将其正确显示为中文 ss = r"test_fix.py::Test1::test_s1[\u6d4b\u8bd5-\u6d4b\u8bd5]" print( ...
- Java中String类的特殊性
java中特殊的String类型 Java中String是一个特殊的包装类数据有两种创建形式: String s = "abc"; String s = new String(&q ...
- The command ("dfs.browser.action.delete") is undefined 解决Hadoop Eclipse插件报错
Hadoop Eclipse插件 报错. 使用 hadoop-eclipse-kepler-plugin-2.2.0.jar 如下所示 Error Log 强迫症看了 受不了 The command ...
- Redis(十三)Python客户端redis-py
一.安装redis-py的方法 使用pip install安装redis-py C:\Users\BigJun>pip3 install redis Collecting redis Downl ...