微博Feed流
一、微博核心业务图
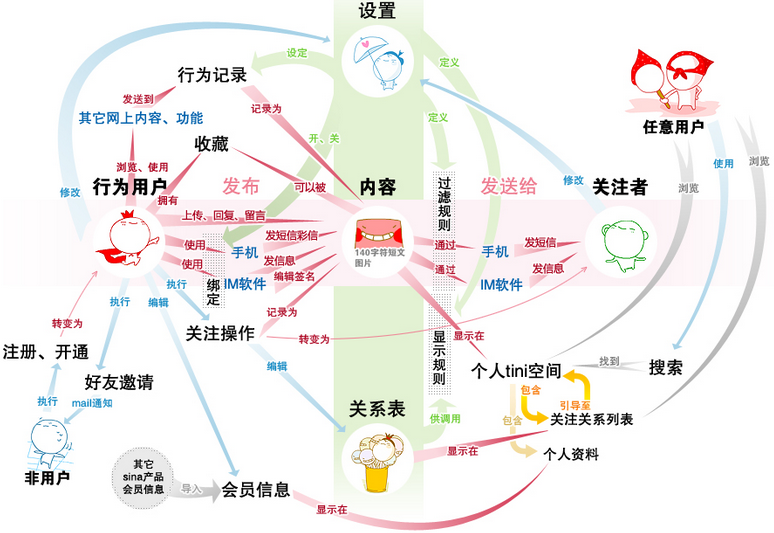
二、微博的架构设计图
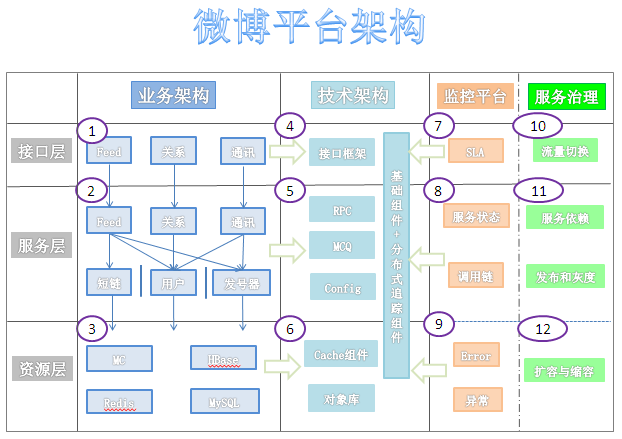
三、简述
先来看看Feed流中的一些概念:
- Feed:Feed流中的每一条状态或者消息都是Feed,比如微博中的一条微博就是一个Feed。
- Feed流:持续更新并呈现给用户内容的信息流。每个人微博关注页等等都是一个Feed流。
- Timeline:Timeline其实是一种Feed流的类型,微博,朋友圈都是Timeline类型的Feed流。
- 关注页Timeline:展示其他人Feed消息的页面,比如微博的首页等。
- 个人页Timeline:展示自己发送过的Feed消息的页面,比如微博的个人页等。
Feed流的主要模式:
- 推(Push)
- 拉(Pull)
- 推拉结合(Hybrid)
推模式
又称写扩散。该方式为每个用户维护一个订阅列表,记录该用户订阅的消息索引(一般为消息ID、类型、发表时间等元数据)。每当用户发布消息时,都会去更新其关注者的订阅列表。
优点:存储空间可能不是很大,用户查询自己关注的所有人Feed时,速度快,性能非常高。
缺点:
1. 推送量会非常大。比如微博红人何炅(粉丝1亿+)发一篇微博,如果采用推模式,就会产生一亿+条数据。
2. 资源浪费。试想,一个大量用户的微博系统如果使用推模式,是不是会产生非常巨大的数据呢?更何况活跃用户只有几千万,剩下几个亿的用户他们可能是半年来一次,或者说更短如两周过来一次;这些数据推给他可能根本没有机会看到,存在很大的资源浪费。
拉模式
又称读扩散。该方式为每个用户维护一个Feed列表,记录该用户所有关注的动态索引。只需要用户发表微博时,存储一条微博数据到Feed表中。用户每次查询Feed时都会去查询Feed表,产生:
优点:这种模式实现起来比较简单,只是在查询的时候需要多考虑下缓存的结构;
缺点:
1. 当用户登陆时,必须很快返回数据的时候,运算量非常大。Feeds表会产生很大的压力,对于一个大系统,Feed表会产生比较大的数据,如果粉丝人数比较多,数据库的压力就会非常大。
2. 一般在线的用户,客户端都会定期扫描,又会增加很大的压力,这在查询性能上没有推模式的效率高。
共性问题:不管推模式还是拉模式都存在如果关注数量或者粉丝数量过多,会导致遍历时间太长的问题。综合所有考虑,因为我们要做的是一个要求实时度很高的系统,把不必要系统开销去掉。怎么去解决 ?
推拉结合模式
这是一种折中的解决方案:在线推、离线拉。用户发布状态时,即便微博大V,同时在线的粉丝可能只有几万甚至几千。推拉模式只推给在线的粉丝,离线的粉丝上线后手动拉取状态即可同步内容。同时,每个用户都会维护一个类似发件箱与收件箱的东西,来保存自己发过的状态和Feed状态,以完成推和拉。
微博是一个广场,所有人都可以关注、发送、转载等,相比较限制人数为5000人的朋友圈,其复杂程度高于朋友圈的timeline,因此考虑到时效性和内存的代价,应该会把用户分为热用户和冷用户,并针对不同用户采取不同的方式。
参考文章:
https://www.cnblogs.com/zl0372/articles/feed_6.html
https://juejin.im/entry/5b166320f265da6e61788a25
https://www.cnblogs.com/sunli/archive/2010/08/24/twitter_feeds_push_pull.html
https://www.cnblogs.com/taozi32/p/9955007.html
微博Feed流的更多相关文章
- feed 流数据请求时机的两个思路
最近 SF 首页 进行了大改版,效果如下: 其他地方都没什么难点,中间的 feed 流思考了不少时间,效果需要类似微博或者知乎 feed 流.之前一直没有做过类似的功能,现总结两个方案. 方案一 方案 ...
- 如何打造千万级Feed流系统
from:https://www.cnblogs.com/taozi32/p/9711413.html 在互联网领域,尤其现在的移动互联网时代,Feed流产品是非常常见的,比如我们每天都会用到的朋友圈 ...
- feed流拉取,读扩散,究竟是啥?
from:https://mp.weixin.qq.com/s?__biz=MjM5ODYxMDA5OQ==&mid=2651961214&idx=1&sn=5e80ad6f2 ...
- 常用Feed流架构实现
业务中很多需求都会用到类似feed流的架构. 例如 微信朋友圈 微博 动态 1对N消息. 一般feed流的架构实现有下面几种. 假如现在的业务场景是微博,然后当前的数据情况是: 用户A关注了用户B和C ...
- Feed流系统设计-总纲
https://mp.weixin.qq.com/s/ccxM2thPbzg5vDWgGVJ5vQ 作者:少强 简介 差不多十年前,随着功能机的淘汰和智能机的普及,互联网开始进入移动互联网时代,最具代 ...
- 数据人看Feed流-架构实践
背景 Feed流:可以理解为信息流,解决的是信息生产者与信息消费者之间的信息传递问题.我们常见的Feed流场景有:1 手淘,微淘提供给消费者的首页商品信息,用户关注店铺的新消息等2 微信朋友圈,及时获 ...
- Feed 流系统杂谈
什么是 Feed 流 Feed 流是社交和资讯类应用中常见的一种形态, 比如微博知乎的关注页.微信的订阅号和朋友圈等.Feed 流源于 RSS 订阅, 用户将自己感兴趣的网站的 RSS 地址登记到 R ...
- Feed流系统重构-架构篇
重构,于我而言,很大的快乐在于能够解决问题. 第一次重构是重构一个c#版本的彩票算奖系统.当时的算奖系统在开奖后,算奖经常超时,导致用户经常投诉.接到重构的任务,既兴奋又紧张,花了两天时间,除了吃饭睡 ...
- 从小白到架构师(4): Feed 流系统实战
「从小白到架构师」系列努力以浅显易懂.图文并茂的方式向各位读者朋友介绍 WEB 服务端从单体架构到今天的大型分布式系统.微服务架构的演进历程.读了三篇万字长文之后各位想必已经累了(主要是我写累了), ...
随机推荐
- ASP.NET Core 如何用 Cookie 来做身份验证
前言 本示例完全是基于 ASP.NET Core 3.0.本文核心是要理解 Claim, ClaimsIdentity, ClaimsPrincipal,读者如果有疑问,可以参考文章 理解ASP.NE ...
- 一段不错的iframe自适应的代码直接拿来用了
一段不错的iframe自适应的代码直接拿来用了 <?php echo " <!DOCTYPE html> <html lang='en'> <head&g ...
- JQuery学习笔记(1)——选择器
JQuery本质上还是JavaScript,是JavaScript的一个框架,可以让我们更简洁地去使用JavaScript 使用之前,记得在html头部引用JQuery 通过选择器获得JQuery对象 ...
- 织梦DEDECMS本地后台操作卡顿的解决方法
打开/data/common.inc.php,把默认的$cfg_dbhost = ‘localhost‘修改为$cfg_dbhost = ‘127.0.0.1’;保存.然后你会发现后台操作起来流畅多了 ...
- PlayJava Day009
今日所学: /* 2019.08.19开始学习,此为补档. */ 1.Date工具类: Date date = new Date() ; //当前时间 SimpleDateFormat sdf = n ...
- async/await简单使用
function process(i) { var p = new Promise(function(resolve,reject){ setTimeout(function(){ console.l ...
- XCode证书问题
1. 确认下证书是不是开发证书,如果是发布证书就会出现这样的提示. 2. 证书失效了,去开发者中心重新生成一个. 3. 包标识符不与描述文件包含的包标识符不一致,按照它的提示换一下就好了,最好不要点 ...
- 仓库管理移动应用解决方案——C#开发的移动应用开源解决方案
产品简介 SmoWMS是一款仓库管理移动解决方案,通过Smobiler平台开发,包含了仓库管理中基础的入库.出库.订单管理.调拨.盘点.报表等功能.支持扫码条码扫描.RFID扫描等仓库中常见的场景. ...
- PHP统计二维数组个数
count($arr) $arr = [ ['id'=>1,'name'=>'Tom'], ['id'=>2,'name'=>'Sun'], ['id'=>3,'name ...
- Java jdom解析xml文件带冒号的属性
Java jdom解析xml文件带冒号的属性 转载请标明出处: https://dujinyang.blog.csdn.net/article/details/99644824 本文出自:[奥特曼超人 ...