(数据科学学习手札63)利用pandas读写HDF5文件
一、简介
HDF5(Hierarchical Data Formal)是用于存储大规模数值数据的较为理想的存储格式,文件后缀名为h5,存储读取速度非常快,且可在文件内部按照明确的层次存储数据,同一个HDF5可以看做一个高度整合的文件夹,其内部可存放不同类型的数据。在Python中操纵HDF5文件的方式主要有两种,一是利用pandas中内建的一系列HDF5文件操作相关的方法来将pandas中的数据结构保存在HDF5文件中,二是利用h5py模块来完成从Python原生数据结构向HDF5格式的保存,本文就将针对pandas中读写HDF5文件的方法进行介绍。
二、利用pandas操纵HDF5文件
2.1 写出
pandas中的HDFStore()用于生成管理HDF5文件IO操作的对象,其主要参数如下:
path:字符型输入,用于指定h5文件的名称(不在当前工作目录时需要带上完整路径信息)
mode:用于指定IO操作的模式,与Python内建的open()中的参数一致,默认为'a',即当指定文件已存在时不影响原有数据写入,指定文件不存在时则新建文件;'r',只读模式;'w',创建新文件(会覆盖同名旧文件);'r+',与'a'作用相似,但要求文件必须已经存在;
complevel:int型,用于控制h5文件的压缩水平,取值范围在0-9之间,越大则文件的压缩程度越大,占用的空间越小,但相对应的在读取文件时需要付出更多解压缩的时间成本,默认为0,代表不压缩
下面我们创建一个HDF5 IO对象store:
import pandas as pd
store = pd.HDFStore('demo.h5')
'''查看store类型'''
print(store)

可以看到store对象属于pandas的io类,通过上面的语句我们已经成功的初始化名为demo.h5的的文件,本地也相应的出现了如下的文件:

接下来我们创建pandas中不同的两种对象,并将它们共同保存到store中,首先创建series对象:
import numpy as np #创建一个series对象
s = pd.Series(np.random.randn(5), index=['a', 'b', 'c', 'd', 'e'])
s
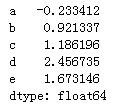
接着我们创建一个dataframe对象:
#创建一个dataframe对象
df = pd.DataFrame(np.random.randn(8, 3),
columns=['A', 'B', 'C'])
df
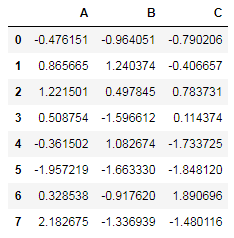
第一种方式利用键值对将不同的数据存入store对象中,这里为了代码简洁使用了元组赋值法:
store['s'],store['df'] = s,df
第二种方式利用store对象的put()方法,其主要参数如下:
key:指定h5文件中待写入数据的key
value:指定与key对应的待写入的数据
format:字符型输入,用于指定写出的模式,'fixed'对应的模式速度快,但是不支持追加也不支持检索;'table'对应的模式以表格的模式写出,速度稍慢,但是支持直接通过store对象进行追加和表格查询操作
使用put()方法将数据存入store对象中:
store.put(key='s',value=s);store.put(key='df',value=df)
既然是键值对的格式,那么可以查看store的items属性(注意这里store对象只有items和keys属性,没有values属性):
store.items

调用store对象中的数据直接用对应的键名来索引即可:
store['df']
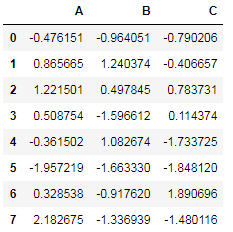
删除store对象中指定数据的方法有两种,一是使用remove()方法,传入要删除数据对应的键:
store.remove('s')
print(store.keys())
二是使用Python中的关键词del来删除指定数据:
del store['s']
print(store.keys())
打印出的结果都如下:

这时若想将当前的store对象持久化到本地,只需要利用close()方法关闭store对象即可:
store.close()
'''查看store连接状况,False则代表已关闭'''
store.is_open

这时本地的h5文件也相应的存储进store对象关闭前包含的文件:

除了通过定义一个确切的store对象的方式,还可以从pandas中的数据结构直接导出到本地h5文件中:
#创建新的数据框
df_ = pd.DataFrame(np.random.randn(5,5))
#导出到已存在的h5文件中,这里需要指定key
df_.to_hdf(path_or_buf='demo.h5',key='df_')
#创建于本地demo.h5进行IO连接的store对象
store = pd.HDFStore('demo.h5')
#查看指定h5对象中的所有键
print(store.keys())

2.2 读入
在pandas中读入HDF5文件的方式主要有两种,一是通过上一节中类似的方式创建与本地h5文件连接的IO对象,接着使用键索引或者store对象的get()方法传入要提取数据的key来读入指定数据:
store = pd.HDFStore('demo.h5')
'''方式1'''
df1 = store['df']
'''方式2'''
df2 = store.get('df')
df1 == df2

可以看出这两种方式都能顺利读取键对应的数据。
第二种读入h5格式文件中数据的方法是pandas中的read_hdf(),其主要参数如下:
path_or_buf:传入指定h5文件的名称
key:要提取数据的键
需要注意的是利用read_hdf()读取h5文件时对应文件不可以同时存在其他未关闭的IO对象,否则会报错,如下例:
print(store.is_open)
df = pd.read_hdf('demo.h5',key='df')

把IO对象关闭后再次提取:
store.close()
print(store.is_open)
df = pd.read_hdf('demo.h5',key='df')
df
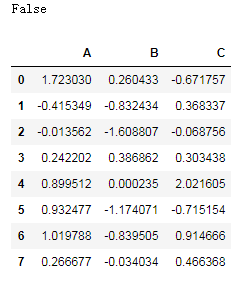
2.3 速度比较
这一小节我们来测试一下对于存储同样数据的csv格式文件、h5格式的文件,在读取速度上的差异情况:
这里我们首先创建一个非常大的数据框,由一亿行x5列浮点类型的标准正态分布随机数组成,接着分别用pandas中写出HDF5和csv格式文件的方式持久化存储:
import pandas as pd
import numpy as np
import time store = pd.HDFStore('store.h5')
#生成一个1亿行,5列的标准正态分布随机数表
df = pd.DataFrame(np.random.rand(100000000,5))
start1 = time.clock()
store['df'] = df
store.close()
print(f'HDF5存储用时{time.clock()-start1}秒')
start2 = time.clock()
df.to_csv('df.csv',index=False)
print(f'csv存储用时{time.clock()-start2}秒')
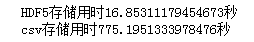
在写出同样大小的数据框上,HDF5比常规的csv快了将近50倍,而且两者存储后的文件大小也存在很大差异:

csv比HDF5多占用将近一倍的空间,这还是在我们没有开启HDF5压缩的情况下,接下来我们关闭所有IO连接,运行下面的代码来比较对上述两个文件中数据还原到数据框上两者用时差异:
import pandas as pd
import time start1 = time.clock()
store = pd.HDFStore('store.h5',mode='r')
df1 = store.get('df')
print(f'HDF5读取用时{time.clock()-start1}秒')
start2 = time.clock()
df2 = pd.read_csv('df.csv')
print(f'csv读取用时{time.clock()-start2}秒')
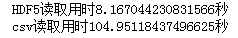
HDF5用时仅为csv的1/13,因此在涉及到数据存储特别是规模较大的数据时,HDF5是你不错的选择。
以上就是本文的全部内容,如有笔误望指出!
(数据科学学习手札63)利用pandas读写HDF5文件的更多相关文章
- (数据科学学习手札68)pandas中的categorical类型及应用
一.简介 categorical是pandas中对应分类变量的一种数据类型,与R中的因子型变量比较相似,例如性别.血型等等用于表征类别的变量都可以用其来表示,本文就将针对categorical的相关内 ...
- (数据科学学习手札52)pandas中的ExcelWriter和ExcelFile
一.简介 pandas中的ExcelFile()和ExcelWriter(),是pandas中对excel表格文件进行读写相关操作非常方便快捷的类,尤其是在对含有多个sheet的excel文件进行操控 ...
- (数据科学学习手札131)pandas中的常用字符串处理方法总结
本文示例代码及文件已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 在日常开展数据分析的过程中,我们经常需要对 ...
- (数据科学学习手札124)pandas 1.3版本主要更新内容一览
本文示例代码及文件已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 就在几天前,pandas发布了其1.3版本 ...
- (数据科学学习手札69)详解pandas中的map、apply、applymap、groupby、agg
*从本篇开始所有文章的数据和代码都已上传至我的github仓库:https://github.com/CNFeffery/DataScienceStudyNotes 一.简介 pandas提供了很多方 ...
- (数据科学学习手札72)用pdpipe搭建pandas数据分析流水线
1 简介 在数据分析任务中,从原始数据读入,到最后分析结果出炉,中间绝大部分时间都是在对数据进行一步又一步的加工规整,以流水线(pipeline)的方式完成此过程更有利于梳理分析脉络,也更有利于查错改 ...
- (数据科学学习手札55)利用ggthemr来美化ggplot2图像
一.简介 R中的ggplot2是一个非常强大灵活的数据可视化包,熟悉其绘图规则后便可以自由地生成各种可视化图像,但其默认的色彩和样式在很多时候难免有些过于朴素,本文将要介绍的ggthemr包专门针对原 ...
- (数据科学学习手札47)基于Python的网络数据采集实战(2)
一.简介 马上大四了,最近在暑期实习,在数据挖掘的主业之外,也帮助同事做了很多网络数据采集的内容,接下来的数篇文章就将一一罗列出来,来续写几个月前开的这个网络数据采集实战的坑. 二.马蜂窝评论数据采集 ...
- (数据科学学习手札40)tensorflow实现LSTM时间序列预测
一.简介 上一篇中我们较为详细地铺垫了关于RNN及其变种LSTM的一些基本知识,也提到了LSTM在时间序列预测上优越的性能,本篇就将对如何利用tensorflow,在实际时间序列预测任务中搭建模型来完 ...
随机推荐
- python之强大的日志模块
1.简单的将日志打印到屏幕 import logging logging.debug('This is debug message')logging.info('This is info mess ...
- 使用 LaTex 制作个人简历(CV,英文版)
\documentclass[12pt]{article} \textwidth=6.5in \textheight=9in \topmargin=-1.1in \headheight=0in \he ...
- VoIP应用在Ubuntu 14.04下编译FFmpeg libX264及PJSIP
PJSIP是一个开源的SIP协议栈.它支持多种SIP的扩展功能,可说算是最目前流行的SIP协议栈之一了. 它实现了SIP.SDP.RTP.STUN.TURN和ICE.PJSIP作为基于SIP的一个多 ...
- springboot 修改连接地址和端口
spring boot 默认 http://localhost:8080 修改为本地IP地址和修改端口在application.properties中添加以下: server.port=9090 se ...
- cocos2d 滚动背景 举 无限
void Bird::update(float time){ auto bg=this->getChildByTag(200); auto bg1=this->getChildByTag( ...
- abp项目 从sql server迁移至mysql
官方资料:https://aspnetboilerplate.com/Pages/Documents/EF-MySql-Integration 实验发现,还差了两步 整理一下,步骤如下: 1.引用My ...
- 服务器做RAID10
将接上Raid card的机器开机,根据提示按组合键进入Raid配置界面(一般是按Ctrl+H,具体的根据提示进行即可) 点击Configuration Wizard,选择new configur ...
- XF堆栈布局
<?xml version="1.0" encoding="utf-8" ?> <ContentPage xmlns="http:/ ...
- Qt 显示 GIF
Qt 中,静态图片 PNG,JPG 等可以用其创建 QPixmap,调用 QLabel::setPixmap() 来显示,但是能够具有动画的 GIF 却不能这么做,要在 QLabel 上显示 GIF, ...
- 【转】关于List排序的时效性
不多说了,就是说明List排序的时效性,仅仅用来备忘,改造自: http://blog.csdn.net/wanzhuan2010/article/details/6205884,感谢原作者 usin ...