已知词频生成词云图(数据库到生成词云)--generate_from_frequencies(WordCloud)
词云图是根据词出现的频率生成词云,词的字体大小表现了其频率大小。
写在前面:
用wc.generate(text)直接生成词频的方法使用很多,所以不再赘述。
但是对于根据generate_from_frequencies()给定词频如何画词云图的资料找了很久,下面只讲这种方法。
generate_from_frequencies适用于我已知词及其对应的词频是多少(已有数据库),不需要分词的情况下。
官方文档说generate_from_frequencies函数的参数是array of tuple,但是我试了很久都不行,最后发现居然应该是dict 字典形式!
即形如:{ word1: fre1, word2: fre2, word3: fre3,......, wordn: fren }
注意:
词云wordcloud的中文显示,需要特殊处理,在网上看了不少是说加字体路径之类的方法我试了都不行,最后只好采用改变编码的形式才解决好。
fp = pd.read_csv(read_name, encoding='gbk') # 读取词频csv文件, 编码为gbk
还有,示例词云的轮廓背景图由china_map.jpg给出,如下图:
一、数据文件准备
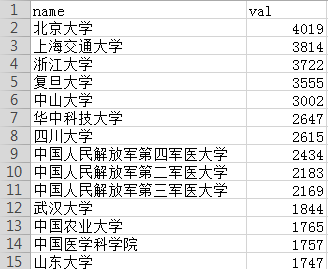
support_institution.csv
数据库字段分组查询数量
select support_institution name,count(support_institution) value from nsfc GROUP BY name ORDER BY value DESC;
查询结果部分截图:

导出为csv文件:support_institution.csv
二、导入模块包
可参考Windows下安装Python、matplotlib包 及相关
https://blog.csdn.net/mikasa3/article/details/78942650
1、numpy
2、pandas
3、wordcloud
4、matplotlib
三、完整代码
import numpy as np
import pandas as pd
from wordcloud import WordCloud, ImageColorGenerator
import matplotlib.pyplot as plt
from PIL import Image def draw_cloud(read_name):
image = Image.open('china_map.jpg') # 作为背景轮廓图
graph = np.array(image)
# 参数分别是指定字体、背景颜色、最大的词的大小、使用给定图作为背景形状
wc = WordCloud(font_path='simkai.ttf', background_color='black', max_words=100, mask=graph)
fp = pd.read_csv(read_name, encoding='gbk') # 读取词频文件, 因为要显示中文,故编码为gbk
name = list(fp.name) # 词
value = fp.val # 词的频率
for i in range(len(name)):
name[i] = str(name[i])
dic = dict(zip(name, value)) # 词频以字典形式存储
wc.generate_from_frequencies(dic) # 根据给定词频生成词云
image_color = ImageColorGenerator(graph)
plt.imshow(wc)
plt.axis("off") # 不显示坐标轴
plt.show()
wc.to_file('nsfc依托单位词云.png') # 图片命名 if __name__ == '__main__':
draw_cloud("support_institution.csv")
四、运行结果
词云图:

五、补充:WordCloud的参数详解
WordCloud(font_path='',
width=400,
height=200,
margin=2,
ranks_only=None,
prefer_horizontal=0.9,
mask=None, scale=1,
color_func=None,
max_words=200,
min_font_size=4,
stopwords=None,
random_state=None,
background_color='black',
max_font_size=None,
font_step=1,
mode='RGB',
relative_scaling=0.5,
regexp=None,
collocations=True,
colormap=None,
normalize_plurals=True
)
wordcloud参数
font_path : string
# 字体路径,需要展现什么字体就把该字体路径+后缀名写上,如:font_path = '黑体.ttf' width : int (default=400)
# 输出的画布宽度,默认为400像素 height : int (default=200)
# 输出的画布高度,默认为200像素 prefer_horizontal : float (default=0.90)
# 词语水平方向排版出现的频率,默认 0.9 (所以词语垂直方向排版出现频率为 0.1 ) mask : nd-array or None (default=None)
# 如果参数为空,则使用二维遮罩绘制词云。如果 mask 非空,设置的宽高值将被忽略,遮罩形状被 mask 取代。除全白(#FFFFFF)的部分将不会绘制,其余部分会用于绘制词云。
# 如:bg_pic = imread('读取一张图片.png'),背景图片的画布一定要设置为白色(#FFFFFF),然后显示的形状为不是白色的其他颜色。可以用ps工具将自己要显示的形状复制到一个纯白色的画布上再保存,就ok了。 scale : float (default=1)
# 按照比例进行放大画布,如设置为1.5,则长和宽都是原来画布的1.5倍。 min_font_size : int (default=4)
# 显示的最小的字体大小 font_step : int (default=1)
# 字体步长,如果步长大于1,会加快运算但是可能导致结果出现较大的误差。 max_words : number (default=200)
# 要显示的词的最大个数 stopwords : set of strings or None
# 设置需要屏蔽的词,如果为空,则使用内置的STOPWORDS background_color : color value (default=”black”)
# 背景颜色,如background_color='white',背景颜色为白色。 max_font_size : int or None (default=None)
# 显示的最大的字体大小 mode : string (default=”RGB”)
# 当参数为“RGBA”并且background_color不为空时,背景为透明。 relative_scaling : float (default=.5)
# 词频和字体大小的关联性 color_func : callable, default=None
# 生成新颜色的函数,如果为空,则使用 self.color_func regexp : string or None (optional)
# 使用正则表达式分隔输入的文本 collocations : bool, default=True
# 是否包括两个词的搭配 colormap : string or matplotlib colormap, default=”viridis”
# 给每个单词随机分配颜色,若指定color_func,则忽略该方法。
wordcloud参数详解
PS:以下内容可以不看,当然,看我也拦不住 ○( ^皿^)っHiahiahia…
上面的中国地图显示的词云并不好看(可能因为词语过长),所以补充一个好看的作品(*^▽^*)
2019国务院政府工作报告词云。
文本地址:
http://www.gov.cn/guowuyuan/baogao.htm
全文代码:
# coding:utf-8
import jieba # 分词
import matplotlib.pyplot as plt # 数据可视化
from wordcloud import WordCloud, ImageColorGenerator, STOPWORDS # 词云
import numpy as np # 科学计算
from PIL import Image # 处理图片 def draw_cloud(text, graph, save_name):
textfile = open(text).read() # 读取文本内容
wordlist = jieba.cut(textfile, cut_all=False) # 中文分词
space_list = " ".join(wordlist) # 连接词语
backgroud = np.array(Image.open(graph)) # 背景轮廓图
mywordcloud = WordCloud(background_color="white", # 背景颜色
mask=backgroud, # 写字用的背景图,从背景图取颜色
max_words=100, # 最大词语数量
stopwords=STOPWORDS, # 停用词
font_path="simkai.ttf", # 字体
max_font_size=200, # 最大字体尺寸
random_state=50, # 随机角度
scale=2,
collocations=False, # 避免重复单词
)
mywordcloud = mywordcloud.generate(space_list) # 生成词云
ImageColorGenerator(backgroud) # 生成词云的颜色
plt.imsave(save_name, mywordcloud) # 保存图片
plt.imshow(mywordcloud) # 显示词云
plt.axis("off") # 关闭保存
plt.show() if __name__ == '__main__':
draw_cloud(text="government.txt", graph="china_map.jpg", save_name='2019政府工作报告词云.png')
词云图:

已知词频生成词云图(数据库到生成词云)--generate_from_frequencies(WordCloud)的更多相关文章
- 词云图value传递数据不显示(已解决)
问题描述: 今天在做词云图时,虽然词云图能够展现出来,但是后台传递过来的数据(每个词出现的次数)却不显示. 错误原因: 错误的将tooltip写在了series内部,如图: 解决方案: 将toolti ...
- (数据科学学习手札71)在Python中制作个性化词云图
本文对应脚本及数据已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 一.简介 词云图是文本挖掘中用来表征词频的数据可视化 ...
- Note of Jieba ( 词云图实例 )
Note of Jieba jieba库是python 一个重要的第三方中文分词函数库,但需要用户自行安装. 一.jieba 库简介 (1) jieba 库的分词原理是利用一个中文词库,将待分词的内容 ...
- 用Python制作酷炫词云图,原来这么简单!
一.简介词云图是文本挖掘中用来表征词频的数据可视化图像,通过它可以很直观地展现文本数据中地高频词:! 图1 词云图示例 在Python中有很多可视化框架可以用来制作词云图,如pyecharts,但这些 ...
- python 数据分析--词云图,图形可视化美国竞选辩论
这篇博客从用python实现分析数据的一个完整过程.以下着重几个python的moudle的运用"pandas",""wordcloud"," ...
- MongoDB与阿里云达成战略合作,最新数据库独家上线阿里云!
11月26日,开源数据库厂商MongoDB与阿里云在北京达成战略合作,作为合作的第一步,最新版MongoDB 4.2数据库产品正式上线阿里云平台. 目前阿里云成为全球唯一可提供最新版MongoDB服务 ...
- Excel催化剂开源第27波-Excel离线生成词云图
在数据分析领域,词云图已经成为在文本分析中装逼的首选图表,大家热烈地讨论如何在Python上做数据分析.做词云图. 数据分析从来都是Excel的主战场,能够让普通用户使用上的技术才是最有价值的技术,一 ...
- python 爬取豆瓣电影短评并wordcloud生成词云图
最近学到数据可视化到了词云图,正好学到爬虫,各种爬网站 [实验名称] 爬取豆瓣电影<千与千寻>的评论并生成词云 1. 利用爬虫获得电影评论的文本数据 2. 处理文本数据生成词云图 第一步, ...
- Python模块---Wordcloud生成词云图
wordcloud是Python扩展库中一种将词语用图片表达出来的一种形式,通过词云生成的图片,我们可以更加直观的看出某篇文章的故事梗概. 首先贴出一张词云图(以哈利波特小说为例): 在生成词云图之前 ...
随机推荐
- C# 位运算及实例计算
前言: 平时在实际工作中很少用到这个,虽然都是一些比较基础的东西,但一旦遇到了,又不知所云.刚好最近接触了一些相关这方面的项目,所以也算是对 这些内容重新温习实践了一遍.所以这篇不仅作为个人备忘,也分 ...
- kali Linux渗透测试技术详解
kali Linux渗透测试技术详解 下载:https://pan.baidu.com/s/1g7dTFfzFRtPDmMiEsrZDkQ 提取码:p23d <Kali Linux渗透测试技术详 ...
- 浅入深出Vue:组件
组件在 vue开发中是必不可少的一环,用好组件这把屠龙刀,就能解决不少问题. 组件是什么 官方的定义: 组件是可复用的 Vue 实例,并且可带有一个名字. 官方的定义已经非常简明了,组件就是一个实例. ...
- POJ 2175:Evacuation Plan(费用流消圈算法)***
http://poj.org/problem?id=2175 题意:有n个楼,m个防空洞,每个楼有一个坐标和一个人数B,每个防空洞有一个坐标和容纳量C,从楼到防空洞需要的时间是其曼哈顿距离+1,现在给 ...
- Python爬虫入门:爬取豆瓣电影TOP250
一个很简单的爬虫. 从这里学习的,解释的挺好的:https://xlzd.me/2015/12/16/python-crawler-03 分享写这个代码用到了的学习的链接: BeautifulSoup ...
- JavaScript-浏览器的三种弹窗方式
//BOM 弹窗 //同步 阻断 alert("alert弹窗"); //返回布尔值 (是/否) var bcf = confirm("confirm弹窗"); ...
- ES6中用&&跟||来简化if{}else{}的写法
目录 ES6中用&&跟||来简化if{}else{}的写法 1. if else的写法 2. ES6中 && ||的用法 3 ES6实例 4 开发环境 ES6中用&am ...
- CDQZ集训DAY7 日记
并没有考试然而心情比考试还糟糕…… 上午讲的基本就听不懂,讲课人迷之停顿.根本让人跟不上趟,声音好奇怪的说……好不容易讲到反演,Hzoi集体上线,等待装逼时刻的到来.然而,讲课人再次迷之停顿,讲一个p ...
- CDQZ集训DAY4 日记
早上起来之后发现座位被zzh占了,得知座位改为先来后到,什么鬼…… 于是去了另一个有耳机的机房,然而并没有什么卵用. T1上来感觉很有意思,先切50分再说.T2好像是原题的说,切了原题30分后大胆猜测 ...
- windows切换mac遇到的问题
1. 前端代码需要安装npm包 所以需要对整个文件夹都赋予管理员权限 2. 在npm i的时候如果权限不足 查看是哪一行调用了哪个文件夹,赋予权限 3. Dsp-fe 本地环境 除了需要配置host ...