浅谈python之利用pandas和openpyxl读取excel数据
在学接口自动化测试时, 需要从excel中读取测试用例的数据, 假如我的数据是这样的:
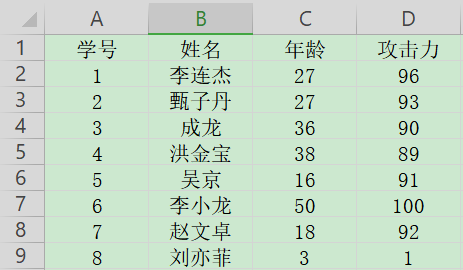
最好是每行数据对应着一条测试用例, 为方便取值, 我选择使用pandas库, 先安装 pip install pandas.
然后导入:
import pandas as pd
df=pd.read_excel('../test_data/test_data.xlsx',sheet_name='hehe')
默认第一行数据是表头,先来简单了解一下pandas的用法:
输入:
print(df.head()) # 矩阵式输出,无法利用数据,忽略
print(df.ix[0]) # 索引从第二行开始,0表示表中的第二行,表头与行数据成映射关系
输出:
学号 姓名 年龄 攻击力
0 1 李连杰 27 96
1 2 甄子丹 27 93
2 3 成龙 36 90
3 4 洪金宝 38 89
4 5 吴京 16 91
学号 1
姓名 李连杰
年龄 27
攻击力 96
输入:
print(df.ix[0,1]) # 第二行第二个数据,B2
print(df.ix[1].values) # 第3行数据
print(df.ix[[1,2]].values) # 第3,4行数据,注意输出多行里面应该要嵌套列表
输出:
李连杰
[2 '甄子丹' 27 93]
[ [2 '甄子丹' 27 93]
[3 '成龙' 36 90] ]
输入:
print(df.ix[[1,2],['年龄']].values) #3,4行里输出表头为'年龄'的列的数据,嵌套列表
print(df.ix[:,['攻击力']].values) # 输出所有行的表头为'攻击力'的列的数据,即D2-D9,嵌套列表
print(df.ix[:].values) # 输出所有行
print(df.values) # 输出所有行,结果与上一样
输出:
[[27]
[36]]
[[ 96]
[ 93]
[ 90]
[ 89]
[ 91]
[100]
[ 92]
[ 1]]
[[1 '李连杰' 27 96]
[2 '甄子丹' 27 93]
[3 '成龙' 36 90]
[4 '洪金宝' 38 89]
[5 '吴京' 16 91]
[6 '李小龙' 50 100]
[7 '赵文卓' 18 92]
[8 '刘亦菲' 3 1]]
输入:
print(df.index.values) # 输出行号
print(df.columns.values) # 输出所有列标题
print(df['年龄'].values) #输出指定标题列的数据
print(df.sample(3).values) #随机输出三行数据
输出:
[0 1 2 3 4 5 6 7]
['学号' '姓名' '年龄' '攻击力']
[27 27 36 38 16 50 18 3]
[[3 '成龙' 36 90]
[6 '李小龙' 50 100]
[7 '赵文卓' 18 92]]
输入:
print(df.ix[1,['学号','年龄']].to_dict()) # 字典的形式输出第三行特定列
输出:
{'学号': 2, '年龄': 27}
有表头的情况下, 输出的数据若有多个元素,都是<class 'numpy.ndarray'>的类型的,即[[] [] [] []],大列表嵌套多个小列表,小列表之间没有逗号隔开, 输出的数据若只有一个元素,那就是str或者int.
然而, 在自动化测试中我们需要的可能是这样的数据:
[{'学号': 1, '姓名': '李连杰', '年龄': 27, '攻击力': 96}, {'学号': 2, '姓名': '甄子丹', '年龄': 27, '攻击力': 93}]
即大列表嵌套多字典, 每条字典就是一个测试用例的数据, 那么怎么取出这种类型的呢?
df=pd.read_excel('../test_data/test_data.xlsx') #默认第一个sheet
test_data=[]
for i in df.index.values:#获取行号的索引,并对其进行遍历:
#根据i来获取每一行指定的数据 并利用to_dict转成字典
row_data=df.ix[i,['学号','姓名','年龄','攻击力']].to_dict()
test_data.append(row_data)
print("最终获取到的数据是:{0}".format(test_data))
输出:
最终获取到的数据是:[{'学号': 1, '姓名': '李连杰', '年龄': 27, '攻击力': 96},
{'学号': 2, '姓名': '甄子丹', '年龄': 27, '攻击力': 93},
{'学号': 3, '姓名': '成龙', '年龄': 36, '攻击力': 90},
{'学号': 4, '姓名': '洪金宝', '年龄': 38, '攻击力': 89},
{'学号': 5, '姓名': '吴京', '年龄': 16, '攻击力': 91},
{'学号': 6, '姓名': '李小龙', '年龄': 50, '攻击力': 100},
{'学号': 7, '姓名': '赵文卓', '年龄': 18, '攻击力': 92},
{'学号': 8, '姓名': '刘亦菲', '年龄': 3, '攻击力': 1}]
怎么样,大功告成了吧, 然而你会说, 好麻烦呀,有简单点的方法吗?哈哈,有!
我们来看to_dict方法:

作用是把数据格式转换成字典型的,两个参数,into不管它,前面orient有很多值,我先输出几个看看:
import pandas as pd
p=pd.read_excel('../test_data/test_data.xlsx') print("orient='list'-->",p.to_dict(orient='list')) # <class 'dict'>将表头作为key,将每列的值放在列表中,将列表作为value
print("orient='index'-->:",p.to_dict(orient='index')) # 将行的索引值作为key,将存放数据的字典作为value
print("orient='records'-->",p.to_dict(orient='records')) # 大列表嵌套多字典,适合测试用例
print(p.to_dict(orient='dict'))
print(p.to_dict(orient='split'))
结果:
orient='list'--> {'学号': [1, 2, 3, 4, 5, 6, 7, 8], '姓名': ['李连杰', '甄子丹', '成龙', '洪金宝', '吴京', '李小龙', '赵文卓', '刘亦菲'], '年龄': [27, 27, 36, 38, 16, 50, 18, 3], '攻击力': [96, 93, 90, 89, 91, 100, 92, 1]}
orient='index'-->: {0: {'学号': 1, '姓名': '李连杰', '年龄': 27, '攻击力': 96}, 1: {'学号': 2, '姓名': '甄子丹', '年龄': 27, '攻击力': 93}, 2: {'学号': 3, '姓名': '成龙', '年龄': 36, '攻击力': 90}, 3: {'学号': 4, '姓名': '洪金宝', '年龄': 38, '攻击力': 89}, 4: {'学号': 5, '姓名': '吴京', '年龄': 16, '攻击力': 91}, 5: {'学号': 6, '姓名': '李小龙', '年龄': 50, '攻击力': 100}, 6: {'学号': 7, '姓名': '赵文卓', '年龄': 18, '攻击力': 92}, 7: {'学号': 8, '姓名': '刘亦菲', '年龄': 3, '攻击力': 1}}
orient='records'--> [{'学号': 1, '姓名': '李连杰', '年龄': 27, '攻击力': 96}, {'学号': 2, '姓名': '甄子丹', '年龄': 27, '攻击力': 93}, {'学号': 3, '姓名': '成龙', '年龄': 36, '攻击力': 90}, {'学号': 4, '姓名': '洪金宝', '年龄': 38, '攻击力': 89}, {'学号': 5, '姓名': '吴京', '年龄': 16, '攻击力': 91}, {'学号': 6, '姓名': '李小龙', '年龄': 50, '攻击力': 100}, {'学号': 7, '姓名': '赵文卓', '年龄': 18, '攻击力': 92}, {'学号': 8, '姓名': '刘亦菲', '年龄': 3, '攻击力': 1}]
{'学号': {0: 1, 1: 2, 2: 3, 3: 4, 4: 5, 5: 6, 6: 7, 7: 8}, '姓名': {0: '李连杰', 1: '甄子丹', 2: '成龙', 3: '洪金宝', 4: '吴京', 5: '李小龙', 6: '赵文卓', 7: '刘亦菲'}, '年龄': {0: 27, 1: 27, 2: 36, 3: 38, 4: 16, 5: 50, 6: 18, 7: 3}, '攻击力': {0: 96, 1: 93, 2: 90, 3: 89, 4: 91, 5: 100, 6: 92, 7: 1}}
{'index': [0, 1, 2, 3, 4, 5, 6, 7], 'columns': ['学号', '姓名', '年龄', '攻击力'], 'data': [[1, '李连杰', 27, 96], [2, '甄子丹', 27, 93], [3, '成龙', 36, 90], [4, '洪金宝', 38, 89], [5, '吴京', 16, 91], [6, '李小龙', 50, 100], [7, '赵文卓', 18, 92], [8, '刘亦菲', 3, 1]]}
发现我们测试需要的数据格式也在其中, 那就是orient='records', 所以两行代码解决了从excel中取出测试数据的事情, 好开心!
p=pd.read_excel('../test_data/test_data.xlsx')
print(p.to_dict(orient='records'))
取出数据测试完毕后想写回测试结果该怎么办呢,这就要谈谈另一个模块了:openpyxl
这里我把读取数据写成一个类, 利用openpyxl也可以拿出大列表嵌套多字典的数据类型, 但稍微麻烦了点, 不过它还可以写回数据. 如下:
from openpyxl import load_workbook
from tools.read_config import ReadConfig class ReadExcel:
button = ReadConfig().read_config('case.config','MOD','button')
def read_excel_openpyxl(self,file_name,sheet_name):
'''从excel读取数据并以大列表嵌套多字典的形式输出'''
wb=load_workbook(file_name)
sheet=wb[sheet_name]
tit = []
test_data = []
row = sheet.max_row + 1
column = sheet.max_column + 1
for i in range(1, row):
ele = {}
for j in range(1, column):
if i == 1:
res = sheet.cell(i, j).value
tit.append(res)
else:
ele[tit[j - 1]] = sheet.cell(i, j).value
test_data.append(ele) # 此时的test_data里面第一个是空列表 test_data_new = []
for item in test_data:
if item != {}: # 去除空列表
test_data_new.append(item)
return self.get_which_row(test_data_new) def write_back_unittest(self,file_name,sheet_name,value,row,cloumn):
'''unittest框架用这个'''
wb=load_workbook(file_name)
sheet=wb[sheet_name]
sheet.cell(row,cloumn).value=value
wb.save(file_name) def get_which_row(self,test_data_new):
'''根据button值决定取出哪些行的数据作为测试用例'''
test_data_final=[]
if self.button == 'all':
return test_data_new
else:
for i in eval(self.button): # 配置文件里button的值是字符串类型,切记!!!
test_data_final.append(test_data_new[i-1])
return test_data_final
END
浅谈python之利用pandas和openpyxl读取excel数据的更多相关文章
- 【python接口自动化】- openpyxl读取excel数据
前言:目前我们进行测试时用于存储测试数据的软件几乎都是excel,excel方便存储和管理数据,读取数据时也比较清晰,测试时我们需要从excel从读取测试数据,结束后还需把测试结果写入到excel中, ...
- openpyxl读取Excel数据
#! Python3 #-*- coding:utf8 -*- import openpyxl #载入表格内容 wb=openpyxl.load_workbook('e:\\work\\newFile ...
- 【原创】python+selenium,用xlrd,读取excel数据,执行测试用例
# -*- coding: utf-8 -*- import unittest import time from selenium import webdriver import xlrd,xlwt ...
- 浅谈Python时间模块
浅谈Python时间模块 今天简单总结了一下Python处理时间和日期方面的模块,主要就是datetime.time.calendar三个模块的使用.希望这篇文章对于学习Python的朋友们有所帮助 ...
- 浅谈Python在信息学竞赛中的运用及Python的基本用法
浅谈Python在信息学竞赛中的运用及Python的基本用法 前言 众所周知,Python是一种非常实用的语言.但是由于其运算时的低效和解释型编译,在信息学竞赛中并不用于完成算法程序.但正如LRJ在& ...
- 浅谈python字符串存储形式
http://blog.csdn.net/zhonghuan1992 钟桓 2014年8月31日 浅谈python字符串存储形式 记录一下自己今的天发现疑问而且给出自己现有知识有的回答. 长话短说,用 ...
- 开发技术--浅谈Python函数
开发|浅谈Python函数 函数在实际使用中有很多不一样的小九九,我将从最基础的函数内容,延伸出函数的高级用法.此文非科普片~~ 前言 目前所有的文章思想格式都是:知识+情感. 知识:对于所有的知识点 ...
- 开发技术--浅谈python数据类型
开发|浅谈python数据类型 在回顾Python基础的时候,遇到最大的问题就是内容很多,而我的目的是回顾自己之前学习的内容,进行相应的总结,所以我就不玩基础了,很多在我实际生活中使用的东西,我会在文 ...
- 开发技术--浅谈python基础知识
开发|浅谈python基础知识 最近复习一些基础内容,故将Python的基础进行了总结.注意:这篇文章只列出来我觉得重点,并且需要记忆的知识. 前言 目前所有的文章思想格式都是:知识+情感. 知识:对 ...
随机推荐
- spring的事物管理配置
基于注解的事务管理器配置(AOP) 首先要引入AOP和TX的名称控件 <!-- 使用annotation定义事务 --> <tx:annotation-driven transact ...
- CSS雪碧图(精灵图)使用
1:CSS雪碧图:CSS雪碧图 即 CSS Sprites,也有人叫它CSS精灵图. 2:雪碧图的由来:一个网站的页面需要大量的小图片或者小图标,但是大量的图片如果放在服务器上,每次当打开网站并且向服 ...
- IS Kali: installed chiess messy code problem
apt-get install ttf-wqy-microhei ttf-wqy-zenhei xfonts-wqy init 6
- C#数据采集用到的几个方法
这两天在做数据采集,因此整理了下数据采集要用到的一些方法.因为我采集的数据比较简单,所以没有用到框架.比较有名的两个框架 HtmlAgilityPack 和 Jumony,感兴趣的可以研究下.当然,火 ...
- grep的使用及正则表达式
1.常用选项: -E :开启扩展(Extend)的正则表达式. -i :忽略大小写(ignore case). -v :反过来(invert),只打印没有匹配的,而匹配的反而不打印. -n :显示行号 ...
- 人生第一次研读MFC截图工具的笔记心得
截图工具: 其中用到了动态链接库DLL技术(Dynamic Link Library)技术,键盘钩子技术,光标捕获技术,类橡皮类CRectTracker 头文件:后缀名为.cpp,主要是定义和声明之类 ...
- 解读并加工BeautifulReport 报告模板
使用unittest框架的脚本执行完成后,会生成一个html格式的报告 这个报告是提前制作了一个html的模板,然后将对应的内容写入到模板中,并生成一个最终的报告,这个报告模板在通过 pip inst ...
- HTML和css常见问题解答2
1.将一个块级元素水平和垂直居中有几种方法?分别是什么? 四种方式: (1).要让div等块级元素水平和垂直居中,必需知道该div等块级元素的宽度和高度,然后设置位置为绝对位置,距离页面窗口左边框和上 ...
- PC端视频播放器
视频播放器:Potplayer 它是一款纯净的.无广告.极速
- 各种数和各种反演(所谓FFT的前置知识?)
每次问NC做多项式的题需要什么知识点. 各种数. 各种反演. 多项式全家桶. 然后我就一个一个地学知识点.然而还差好多,学到后面的前面的已经忘了(可能是我太菜吧不是谁都是NC啊) 然后发现每个知识点基 ...