大数据之路day01_1--Java下载、安装等配置
从今天开始,我就正式的走上大数据的道路了,如果说我为啥要去学习大数据,可能我的初衷是以后可以接触到人工智能方面的技术,后来在自学的过程中发现,学习人工智能,需要扎实的算法,以及对大量数据的处理,再者,渐渐的我想先系统的学习以下大数据这块的知识,从Java环境搭建到最后的机器学习,到深度学习,一步一个脚印的去实现,只有把基础打好了,后面的露才会好走,谁也不可能一口吃成胖子。马云的成功,在我看来,他发现了未来技术成长曲线,坚持自己想法,并与之去实现。从一开始的无人问津到后来的一个小举动引到各大媒体的注意,这是成功的表现,亦是对自己的考验。梦想还是要有的,万一实现了呢!
1、下载并且安装JDK (网速慢的可以用我的网盘) 注意:尽量不要去下载最新的JDK,有不少的代码并不兼容。后期还要进行修改,很烦的。
链接:https://pan.baidu.com/s/1nhEc7FXv7ES5L893YL1cXA
提取码:224n
一路傻瓜式默认安装,其中遇到装JRE的时候的安装目录是自己创建的,可以不下载,但是不大,就下吧。(这里简单的说一下,JRE是运行JAVA的,JDK是用来开发的)
2、配置环境变量
上一步安装后我的是这样:

接下来开始配置环境变量:
(1)右击此电脑--->点击属性
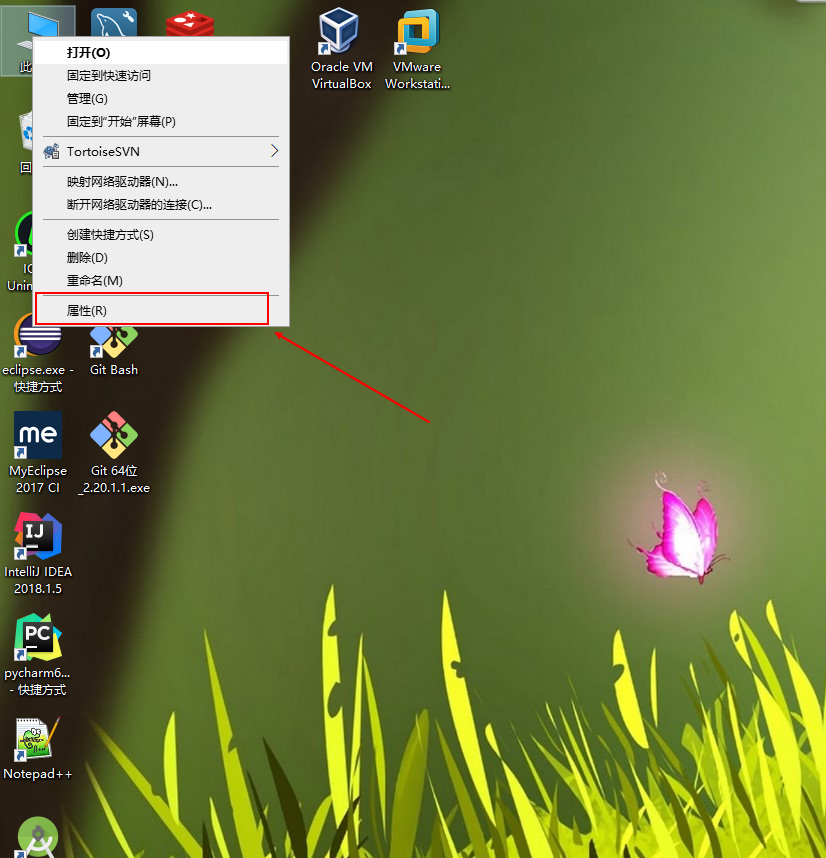
(2)点击高级系统设置---->环境变量
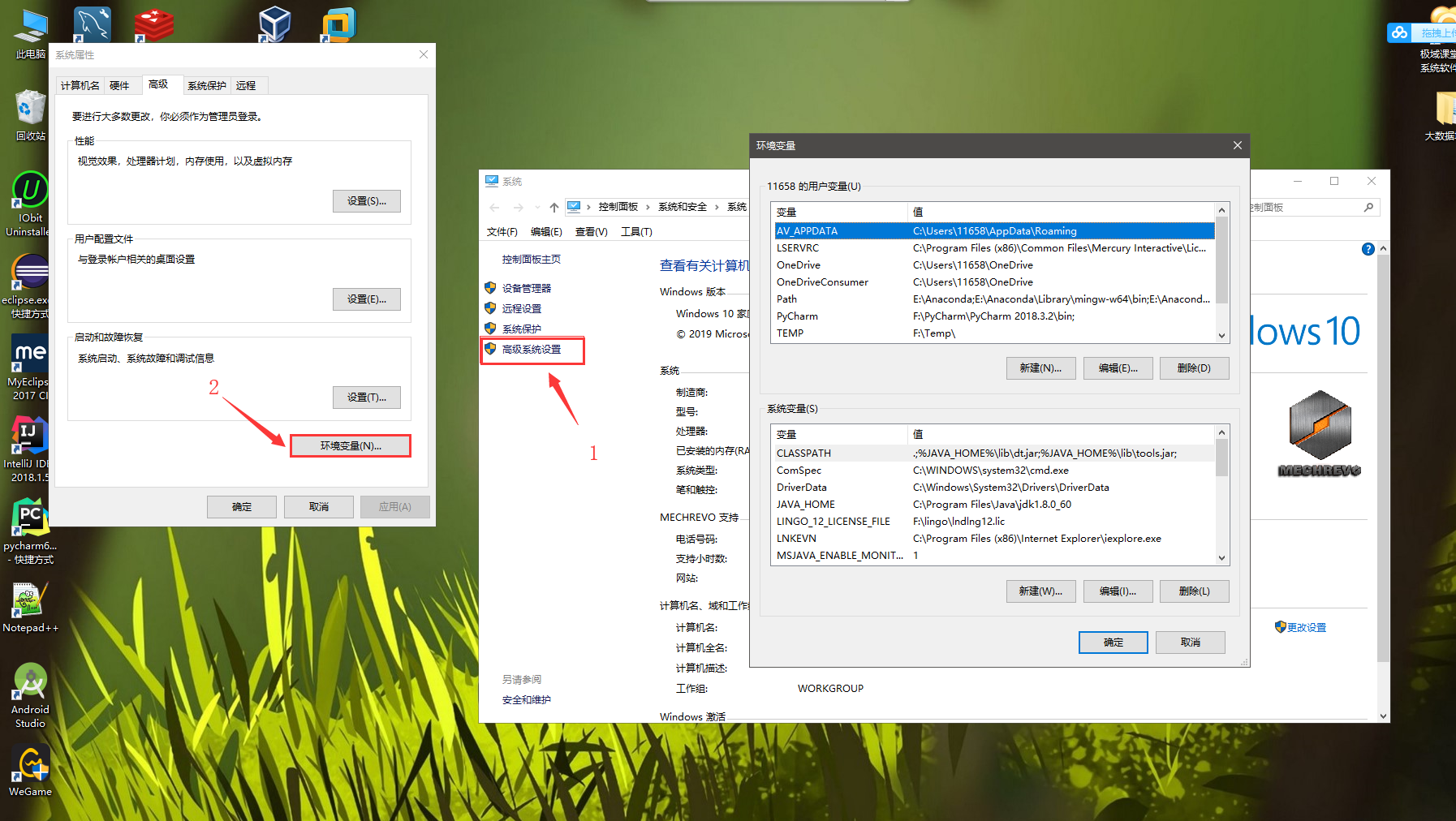
(3)在系统变量里我们要配置三个变量 JAVA_HOME 、 CLASSPATH 、 Path (没有的变量自己新建)
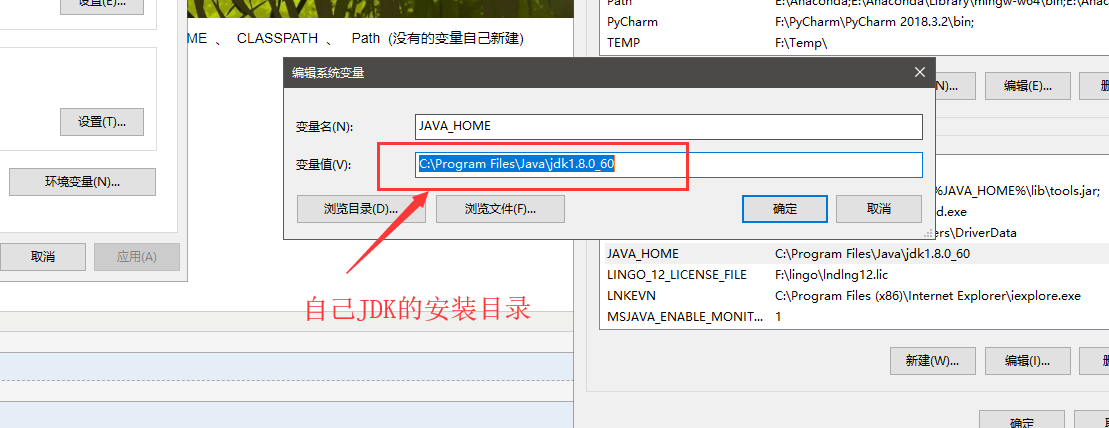
a、JAVA_HOME 这是我对应的变量值: C:\Program Files\Java\jdk1.8.0_60 (不要直接复制,因为每个人的安装路径可能不一样)
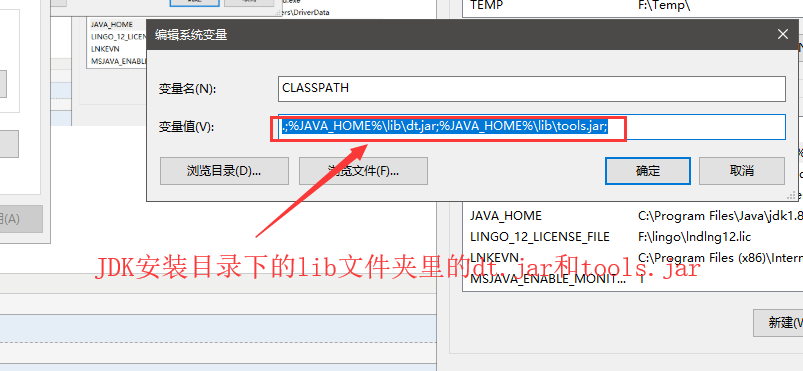
b、CLASSPATH 这是我对应的变量值: .;%JAVA_HOME%\lib\dt.jar;%JAVA_HOME%\lib\tools.jar;(在JAVA_HOME填对的情况下,这个可以直接复制)
c、Path 这是我对应的变量值: %JAVA_HOME%\bin; 和 %JAVA_HOME%\jre\bin
(4)win+R 键打开输入cmd
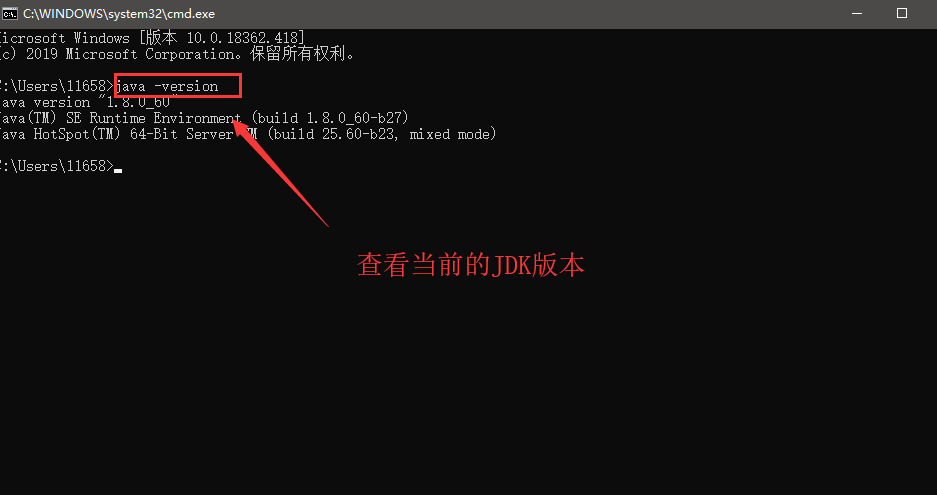
分别输入以下命令回车
a、java -version
b、javac
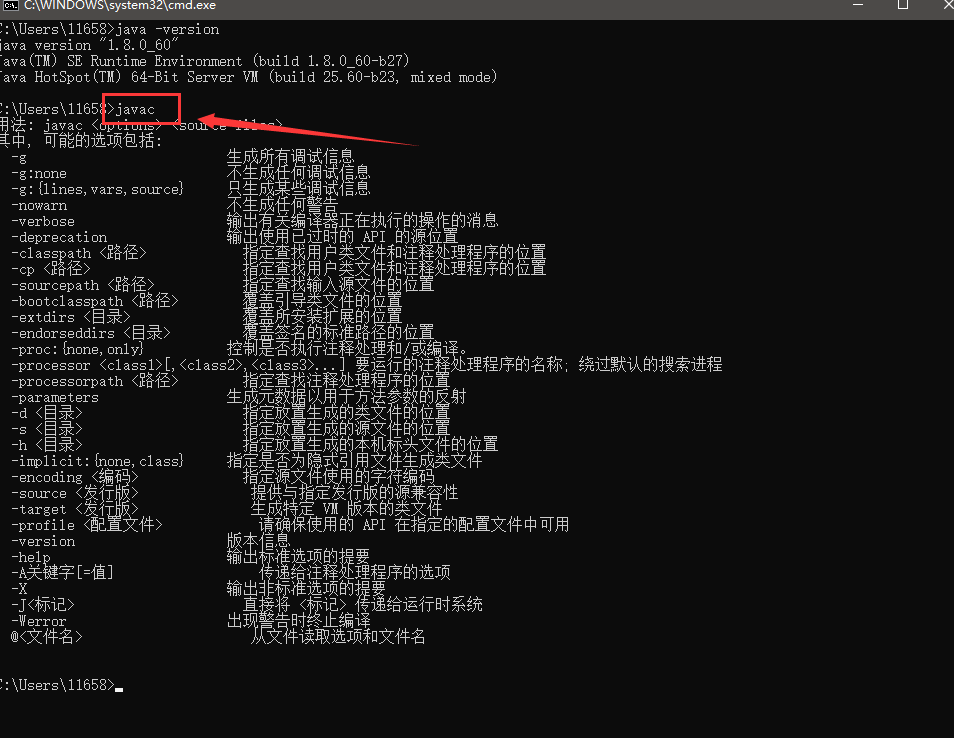
c、java
(5)如果以上的命令输入结果和我截图一样,说明安装JDK,并且环境变量配置成功!!!!下一步,编写我们的第一个程序(“Hello World !”)。
大数据之路day01_1--Java下载、安装等配置的更多相关文章
- CentOS6安装各种大数据软件 第八章:Hive安装和配置
相关文章链接 CentOS6安装各种大数据软件 第一章:各个软件版本介绍 CentOS6安装各种大数据软件 第二章:Linux各个软件启动命令 CentOS6安装各种大数据软件 第三章:Linux基础 ...
- 大数据之路week05--day02(Maven安装,环境变量的配置及基本使用)
今天我们就来学习一下maven,怎么说呢,maven更像是一种管理的工具,实现的原理是使用插件. 举个例子,比如说,一个公司需要做一个项目,这个项目又分成了很多的模块,每个模块又分成了许多的业务等等, ...
- C#码农的大数据之路 - 使用Ambari自动化安装HDP2.6(基于Ubuntu16.04)并运行.NET Core编写的MR作业
准备主机 准备3台主机,名称作用如下: 昵称 Fully Qualified Domain Name IP 作用 Ubuntu-Parrot head1.parrot 192.168.9.126 Am ...
- 大数据高可用集群环境安装与配置(04)——安装JAVA运行环境
Hadoop运行在java环境,所以在安装Hadoop之前,需要安装好jdk 提前下载好jdk安装包(jdk-8u161-linux-x64.tar.gz),将它上传到指定的安装目录当中,然后运行安装 ...
- 大数据高可用集群环境安装与配置(07)——安装HBase高可用集群
1. 下载安装包 登录官网获取HBase安装包下载地址 https://hbase.apache.org/downloads.html 2. 执行命令下载并安装 cd /usr/local/src/ ...
- 大数据高可用集群环境安装与配置(06)——安装Hadoop高可用集群
下载Hadoop安装包 登录 https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/ 镜像站,找到我们要安装的版本,点击进去复制下载链接 ...
- 大数据高可用集群环境安装与配置(09)——安装Spark高可用集群
1. 获取spark下载链接 登录官网:http://spark.apache.org/downloads.html 选择要下载的版本 2. 执行命令下载并安装 cd /usr/local/src/ ...
- 大数据高可用集群环境安装与配置(08)——安装Ganglia监控集群
1. 安装依赖包和软件 在所有服务器上输入命令进行安装操作 yum install epel-release -y yum install ganglia-web ganglia-gmetad gan ...
- 大数据高可用集群环境安装与配置(10)——安装Kafka高可用集群
1. 获取安装包下载链接 访问https://kafka.apache.org/downloads 找到kafka对应版本 需要与服务器安装的scala版本一致(运行spark-shell可以看到当前 ...
- 大数据高可用集群环境安装与配置(05)——安装zookeeper集群
1. 下载安装包 登录官网下载安装包 https://mirrors.tuna.tsinghua.edu.cn/apache/zookeeper/ 2. 执行命令下载并安装 cd /usr/local ...
随机推荐
- Linux-rhel-server-7.4-Mysql-5.7安装记录
解压下载的tar包: tar -xf mysql-5.7.19-1.el7.x86_64.rpm-bundle.tar 安装一下rpm包: sudo rpm -ivh mysql-community- ...
- 服务器时间误差导致的google sign-in后台验证错误(远程调试java程序)
https://developers.google.com/identity/sign-in/web/backend-auth import com.google.api.client.googlea ...
- link 和 @import 的区别是什么?
link语法结构: <link href="url" rel="stylesheet" type="text/css"> @im ...
- B-概率论-熵和信息增益
目录 熵和信息增益 一.熵(Entropy) 二.条件熵(Conditional Entropy) 三.联合熵(Joint Entropy) 四.相对熵(Relative Entropy) 4.1 相 ...
- flask 微电影网站
flask简介 轻量级web应用框架 WSGI工具箱才用Werkzeug 模版引擎则使用Jinja2 Flask使用BSD授权 1.virtualenv的使用 (1)创建虚拟环境:virtualenv ...
- netty源码解解析(4.0)-25 ByteBuf内存池:PoolArena-PoolChunk
PoolArena实现了用于高效分配和释放内存,并尽可能减少内存碎片的内存池,这个内存管理实现使用PageRun/PoolSubpage算法.分析代码之前,先熟悉一些重要的概念: page: 页,一个 ...
- 机器学习:eclipse中调用weka的Classifier分类器代码Demo
weka中实现了很多机器学习算法,不管实验室研究或者公司研发,都会或多或少的要使用weka,我的理解是weka是在本地的SparkML,SparkML是分布式的大数据处理机器学习算法,数据量不是很大的 ...
- Python3+RobotFramework+pycharm环境搭建
我的环境为 python3.6.5+pycharm 2019.1.3+robotframework3.1.2 1.安装python3.x 略 之后在cmd下执行:pip install robot ...
- 12.Nginx代理与负载均衡
1.什么是代理? 代为办理 --> 代理 2.Nginx正向代理.反向代理 正向代理: --> 上网 | 路由器替代 反向代理: --> 正向与反向代理的区别: 区别在于形式上服务的 ...
- ESP8266开发之旅 网络篇④ Station——ESP8266WiFiSTA库的使用
1. 前言 在前面的篇章中,博主给大家讲解了ESP8266的软硬件配置以及基本功能使用,目的就是想让大家有个初步认识.并且,博主一直重点强调 ESP8266 WiFi模块有三种工作模式: St ...