PyTorch在笔记本上实现CUDA加速
最近刚开始学习深度学习,参考了一篇深度学习的入门文章,原文链接:https://medium.freecodecamp.org/everything-you-need-to-know-to-master-convolutional-neural-networks-ef98ca3c7655。
文章内容就是kaggle上的一个competition,识别图像中是否存在航拍仙人掌,使用了Pytorch框架,原文代码有些许错误,经改正后代码如下:
import numpy as np
import pandas as pd
from pathlib import Path
from fastai import *
from fastai.vision import *
import torch
get_ipython().run_line_magic('matplotlib', 'inline') train_df=pd.read_csv("train.csv") #读取csv文件到train_df
data_folder=Path(".") #path为默认位置
train_images=ImageList.from_df(train_df,path=data_folder,folder='train')#记住读取方法
print(torch.cuda.is_available())
a=torch.ones(1,1)
print(a.cuda()) trfm=get_transforms(do_flip=True,flip_vert=True,max_rotate=10.0,max_zoom=1.1,max_lighting=0.2,max_warp=.2,p_affine=0.75,p_lighting=0.75)
#train_img = train_img.transform(transformations, size=128)#错误句子,直接删除 test_df=pd.read_csv("sample_submission.csv")
test_img=ImageList.from_df(test_df,path=data_folder,folder='test')
train_img = (train_images
.split_by_rand_pct(0.01)#把训练数据分出一小部分做验证集
.label_from_df()
.add_test(test_img)
.transform(trfm, size=128)
.databunch(path='.', bs=14, device= torch.device('cuda:0'))#进行批处理,bs由显存决定,太大跑不了。太小跑得慢
.normalize(imagenet_stats)#图像归一化
) learn = cnn_learner(train_img, models.densenet161, metrics=[error_rate, accuracy])#用 cnn_leaner 创建一个训练器
#用移动网络开热点下载快,用联通的网就下载的很慢 #单周期策略,暴力搜索(大了:训练过程快,容易错过误差边界,甚至会跳出可控范围,无法收敛;小了:训练慢)
learn.lr_find()
learn.recorder.plot() lr = 3e-02
learn.fit_one_cycle(5, slice(lr)) preds,_ = learn.get_preds(ds_type=DatasetType.Test)
test_df.has_cactus = preds.numpy()[:, 0] test_df.to_csv('submission.csv', index=False)
以上就是全部的代码,运行环境为win10 64位操作系统,Python3.7,Pytorch1.1.0,CUDA10.1.120,NVDIA驱动程序431.36。
开始时使用CUDA运行遇到困难,测试print(torch.cuda.is_available()) 总是显示false,经过一番折腾,找到了解决办法,如下:
1、Pytorch在国内通过pip安装会有问题,最好通过在PyTorch官网(https://pytorch.org/)下载后,然后本地安装whl文件(再次提醒,一定要本地安装,这样才能保证安装的Pytorch是完整包含CUDA的):
①官网图片,直接浏览器中打开如下https网站,可能会慢一些;或者将网站拷贝到迅雷中下载,这样可能会快一点。
另外一定要注意安装Python3.7的64位,并且win10/win7也要是64位,因为Pytorch仅支持64位!

②本地文件系统图片和通过命令行(管理员模式)安装图片,cmd中两个whl文件都要安装,我这里只演示一个,如果之前装过Pytorch但是没法调用CUDA,就先卸载(一定要用管理员模式的命令行)再安装,卸载指令为 pip uninstall torch 和 pip uninstall torchvision:
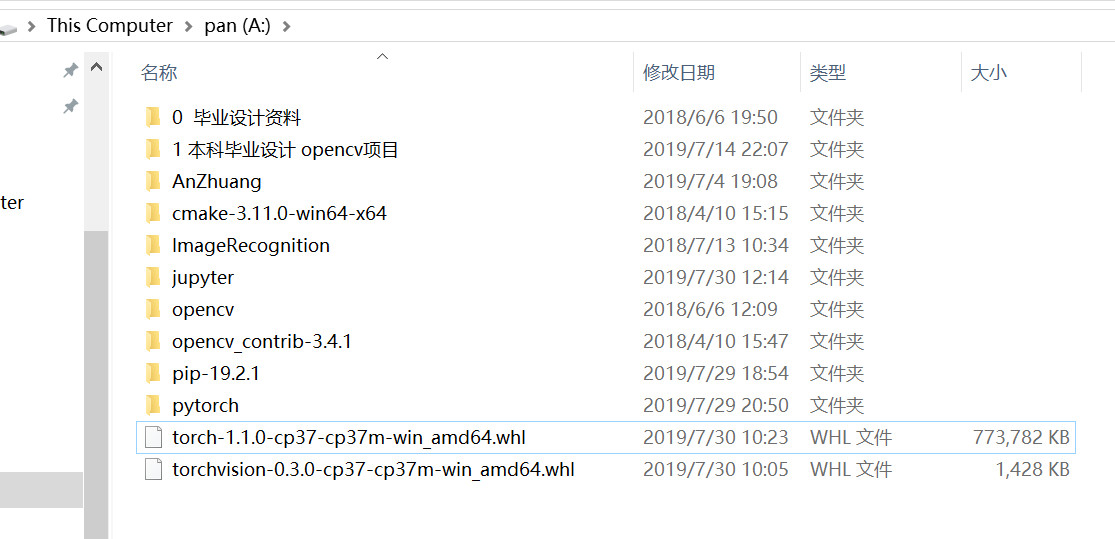
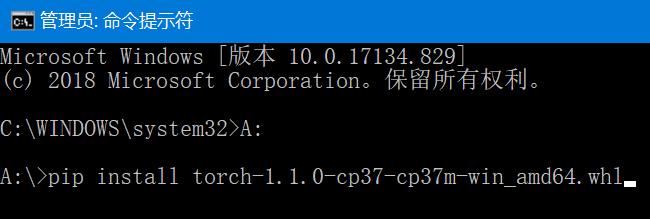
2、NVDIA官网(https://developer.nvidia.com/cuda-downloads)下载CUDA,首先应确认自己的电脑是否有NVDIA显卡,并确定是否支持CUDA,直接一路下一步安装即可,这里就不放图片了。
3、jupyter notebook中运行上述代码,若 print(torch.cuda.is_available()) 为True则证明CUDA调用成功,另外注意 bs 数值要根据自己的显存大小来设置。
note:笔记本一般都是双显卡(一个位集成显卡,一个为NVDIA独立显卡),做桌面模式win10可以自动切换使用独立显卡调用CUDA,并不用特意设置NVDIA控制面板,之前走过很多弯路,以为笔记本上没法用CUDA加速,后来发现就是版本或者安装的问题。
通过这样一番设置,应该就可以调用CUDA了,关键点有几个:64位,离线安装whl,NVDIA显卡。
下面就尽情享受CUDA的快感吧,cpu运行上述代码需要几个小时,用CUDA加速后几十分钟就完成了。
PyTorch在笔记本上实现CUDA加速的更多相关文章
- 适用于Linux 2的Windows子系统上的CUDA
适用于Linux 2的Windows子系统上的CUDA Announcing CUDA on Windows Subsystem for Linux 2 为了响应大众的需求,微软在2020年5月的构建 ...
- Linux 2 的 Windows 子系统上发布 CUDA
Linux 2 的 Windows 子系统上发布 CUDA 为响应大众需求,微软 宣布 在 2020 年 5 月的 建造 大会上推出了 建造 ( WSL 2 ) – GPU 加速功能.这一特性为许多计 ...
- 15分钟在笔记本上搭建 Kubernetes + Istio开发环境
11月13~15日,KubeCon 上海大会召开,云原生是这个秋天最火热的技术.很多同学来问如何上手 Kubernetes和Istio 服务网格开发.本文将帮助你利用Docker CE桌面版,15分钟 ...
- Pytorch 使用不同版本的 cuda
由于课题的原因,笔者主要通过 Pytorch 框架进行深度学习相关的学习和实验.在运行和学习网络上的 Pytorch 应用代码的过程中,不少项目会标注作者在运行和实验时所使用的 Pytorch 和 c ...
- 在C++工程上添加CUDA编译环境
1.直接在新建工程的时候选择CUDA,这样的工程既能编译C++也能编译CU 2.在已有的C++工程上添加CUDA编译环境 右键工程-->生成依赖项-->生成自定义-->勾选CUDA ...
- 深度学习-使用cuda加速卷积神经网络-手写数字识别准确率99.7%
源码和运行结果 cuda:https://github.com/zhxfl/CUDA-CNN C语言版本参考自:http://eric-yuan.me/ 针对著名手写数字识别的库mnist,准确率是9 ...
- linux笔记本上安装了双显卡驱动(intel+nvidia)
为了提高linux图形性能并降低功耗,独特的文章. 我用的系统Fedora 20 Xfce x64,在安装驱动程序,以确保系统是最新的版本号. 最好安装gcc.kernel-devel和其他包.己主动 ...
- Windows(华硕/联想)笔记本上安装黑苹果与win双系统教程
声明:电脑小白者请谨慎安装,如有需要可私聊或留言提供安装工具 首先说明:Windows PC的文件操作系统也就是磁盘格式是FAT32或 NTFS ,而 Mac 的文件操作系统格式是 HFS ,所以这时 ...
- 『PyTorch』第四弹_通过LeNet初识pytorch神经网络_上
总结一下相关概念: torch.Tensor - 一个近似多维数组的数据结构 autograd.Variable - 改变Tensor并且记录下来操作的历史记录.和Tensor拥有相同的API,以及b ...
随机推荐
- 10分钟安装Elasticsearch
关注公众号 itweknow,回复"ES"获取<Elasticsearch权威指南 中文版>. 最近在尝试着搭建一个ELK(一个开源的实时日志分析平台),而本文所讲的E ...
- VS调试时修改代码
最近碰到一个问题,就是vs在调试模式下无法修改代码之后再继续,这种严重影响工作效率的问题怎么能忍,所以决心把这个坑填满.网上搜了大堆有头无尾有尾无头的答案,我一个一个试了几乎都没啥用.最后通过不断的测 ...
- 《白帽子讲web安全》——吴瀚清 阅读笔记
浏览器安全 同源策略:浏览器的同源策略限制了不同来源的“document”或脚本,对当前的“document”读取或设置某些属性.是浏览器安全的基础,即限制不同域的网址脚本交互 <scr ...
- c语言和c++的交换函数
#include<iostream> using namespace std; namespace LiuGang{//在命名空间中写函数 void swap(int&aa,int ...
- Nginx安装之源码安装
nginx部署 1. 安装依赖 yum install gcc gccc++ pcre pcre-devel zlib zlib-devel openssl openssl-devel-y 2. 下载 ...
- Jupter NotebooK学习
1.参考资料 B站上学习视频 Jupyter 安装与使用 2.安装 在cmd窗口中输入(创建的文件会再当前的目录下):pip install jupyter 然后输入:jupyter notebook ...
- 10.源码分析---SOFARPC内置链路追踪SOFATRACER是怎么做的?
SOFARPC源码解析系列: 1. 源码分析---SOFARPC可扩展的机制SPI 2. 源码分析---SOFARPC客户端服务引用 3. 源码分析---SOFARPC客户端服务调用 4. 源码分析- ...
- tensorflow中的batch_norm以及tf.control_dependencies和tf.GraphKeys.UPDATE_OPS的探究
https://blog.csdn.net/huitailangyz/article/details/85015611#
- HTML连载33-背景定位
一.背景定位 同一个标签可以同时设置背景颜色和背景图片,如果颜色和图片同时存在,那么图片会覆盖颜色 1.在CSS中有一个叫做background-position:属性,就是专门用来控制背景图片的位置 ...
- C++11——智能指针
1. 介绍 一般一个程序在内存中可以大体划分为三部分——静态内存(局部的static对象.类static数据成员以及所有定义在函数或者类之外的变量).栈内存(保存和定义在函数或者类内部的变量)和动态内 ...