使用Query Store监控性能
Query Store是SQL Server 2016中引入的、语句级别的性能监控和调优工具,它不仅自动捕获查询(Query)、执行计划(Plan)、运行时统计信息(Runtime)和等待(Wait)统计的信息,而且还可以识别出由于执行计划更改而导致的性能差异,简化了性能故障排除的流程,降低了性能优化的难度。从字面上来解释,Query Store是“查询的仓库”,它是由SQL Server引擎自动维护,用于捕获数据库中执行的查询,以及跟其执行性能相关联的数据。不同于DMV把数据存储到内存中,Query Store会把捕获的性能数据存储到文件(Disk)中,为了最优化数据的写入,Query Store使用异步更新方式,新捕获的数据会存储到内存中,每隔一定时间(分时)就把捕获的数据存储到硬盘(Disk)中。
一,启用Query Store
Query Store默认是关闭的,启用Query Store对查询性能还是有一定的影响的,
ALTER DATABASE { database_name | CURRENT }
SET QUERY_STORE
{
= OFF
| = ON [ ( <query_store_option_list> [,...n] ) ]
| CLEAR [ ALL ]
}
<query_store_option_list> ::=
{
OPERATION_MODE = { READ_WRITE | READ_ONLY }
| CLEANUP_POLICY = ( STALE_QUERY_THRESHOLD_DAYS = number )
| DATA_FLUSH_INTERVAL_SECONDS = number
| MAX_STORAGE_SIZE_MB = number
| INTERVAL_LENGTH_MINUTES = number
| SIZE_BASED_CLEANUP_MODE = { AUTO | OFF }
| QUERY_CAPTURE_MODE = { ALL | AUTO | CUSTOM | NONE }
| MAX_PLANS_PER_QUERY = number
| WAIT_STATS_CAPTURE_MODE = { ON | OFF }
| QUERY_CAPTURE_POLICY = ( <query_capture_policy_option_list> [,...n] )
}
<query_capture_policy_option_list> :: =
{
STALE_CAPTURE_POLICY_THRESHOLD = number { DAYS | HOURS }
| EXECUTION_COUNT = number
| TOTAL_COMPILE_CPU_TIME_MS = number
| TOTAL_EXECUTION_CPU_TIME_MS = number
}
参数注释:
- CLEAR:清空Query Store的数据
- OPERATION_MODE:READ_WRITE是指Query Store会持续收集和持久化数据,而READ_ONLY是指只能从Query Store读取信息,而不会更新Query Store。
- CLEANUP_POLICY:定义数据留存的时间窗口,超过该窗口,过期的数据从Query Store中清理出去。
- DATA_FLUSH_INTERVAL_SECONDS:定义数据持久化到硬盘的频率,默认值是900s(15min)。为了优化性能,Query Store收集的数据采用异步写方式,每隔一定的时间会把捕获的数据写到硬盘中。
- MAX_STORAGE_SIZE_MB:设置Query Store的最大存储空间,如果Query Store达到最大存储空间的限制,Query Store会把操作模式(OPERATION_MODE)更改为READ_ONLY,不再写入新的数据。
- INTERVAL_LENGTH_MINUTES:每隔一定的时间窗口对运行时的执行统计数据进行聚合,然后把聚合值存储到Query Store中。
- SIZE_BASED_CLEANUP_MODE :基于Query Store占用的空间大小控制是否启动清理程序,清理程序会自动删除Query Store中过时的数据,以释放Query Store的空间
- QUERY_CAPTURE_MODE :定义捕获查询的捕获模式,默认值是ALL,表示捕获所有的查询,AUTO表示基于执行次数和资源消耗来捕获相关的查询。
- MAX_PLANS_PER_QUERY:定义为每个查询维护的计划数量,默认值是200
- WAIT_STATS_CAPTURE_MODE :是否捕获等待统计(wait stats),从SQL Server 2017(14.x)开始支持该选项。
- QUERY_CAPTURE_POLICY:定义捕获Query的策略,
- STALE_CAPTURE_POLICY_THRESHOLD :定义评估的时间间隔(evaluation interval period ),根据以下的选项来确定是否一个query应该被捕获,evaluation period的默认值是1day
- EXECUTION_COUNT:默认值是30,在evaluation period内,如果一个query的执行次数超过指定的数值,那么捕获该query。
- TOTAL_COMPILE_CPU_TIME_MS:默认值是1000ms,在evaluation period内,如果一个query的编译时间超过指定的时间,那么捕获该query。
- TOTAL_EXECUTION_CPU_TIME_MS:默认值是100,在evaluation period内,如果一个query的执行时间超过指定的时间,那么捕获该query。
例如,使用以下的脚本来启用TestDB的Query Store:
ALTER DATABASE [TestDB]
SET QUERY_STORE = ON
(
OPERATION_MODE = READ_WRITE,
CLEANUP_POLICY = ( STALE_QUERY_THRESHOLD_DAYS = 90 ),
DATA_FLUSH_INTERVAL_SECONDS = 900,
MAX_STORAGE_SIZE_MB = 1000,
INTERVAL_LENGTH_MINUTES = 60,
SIZE_BASED_CLEANUP_MODE = AUTO,
MAX_PLANS_PER_QUERY = 200,
WAIT_STATS_CAPTURE_MODE = ON,
QUERY_CAPTURE_MODE = CUSTOM,
QUERY_CAPTURE_POLICY = (
STALE_CAPTURE_POLICY_THRESHOLD = 24 HOURS,
EXECUTION_COUNT = 30,
TOTAL_COMPILE_CPU_TIME_MS = 1000,
TOTAL_EXECUTION_CPU_TIME_MS = 100
)
);
在启用Query Store之后,用户可以通过系统视图来查看各个选项的配置情况:
sys.database_query_store_options
当然,也可以使用SSMS对Query Store的各个选项进行配置和查看:
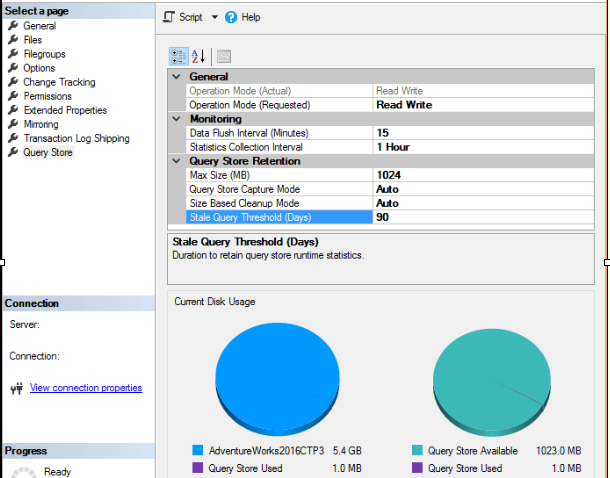
二,Query Store捕获的信息
从总体上来说,Query Store包含四个Store,分别是query store、plan store、runtime stats store和wait stats store:
- query store 用于捕获查询的信息,
- plan store用于捕获执行计划的信息,
- runtime stats store用于捕获执行计划的变更记录和统计信息等,
- stats store 用于捕获等待统计信息。
除了捕获信息,Query Store还可以根据plan的性能信息,强制查询使用特定的计划。
1,计划强制(Plan Forcing)
由于一些不可预知的原因,例如统计信息更改,架构更改,索引的创建/删除等,SQL Server中任意一个查询的执行计划通常都会随着时间的推移而变化。由于内存压力,计划也会从计划缓存中逐出,这导致计划缓存只存储查询的最新的执行计划。由执行计划更改引起的查询性能的下降,就无迹可寻,解决起来很费时间。
由于Query Store为每个查询保留多个执行计划,因此,它可以指示查询处理器(Query Processor)对查询强制使用特定的执行计划,这称为计划强制(Plan Forcing)。Query Store中的计划强制(Plan Forcing)的工作类似于USE PLAN查询提示的机制,但是不需要在用户在应用程序中做任何更改,计划强制可以在很短的时间内解决由计划更改导致的查询性能下降的问题。
2,等待统计(Wait Stats)
等待统计信息是解决查询性能问题的另一信息来源,长期以来,等待统计信息仅在实例级别可用,这使得很难将等待回溯到特定查询语句上。 从SQL Server 2017(14.x)和 Azure SQL数据库开始,查询存储能够追踪特定语句的等待信息。
ALTER DATABASE AdventureWorks2012
SET QUERY_STORE = ON ( WAIT_STATS_CAPTURE_MODE = ON );
3,查询处理的过程
Query Store会在Query的编译和执行阶段收集数据:
- 当query第一次编译时,query的text和plan存储到Query Store中;
- 当query重编译时,如果query产生新的plan,Query Store会存储新的plan,并把先前的plan的执行信息保留下来。
- 一旦query开始执行,Query Store开始收集query执行时(runtime)的数据。为了减少数据的数量,Query Store每隔一段时间对runtime进行聚合,只存储统计数据,而不直接存储详细数据。
- 在编译(Compile)和重编译(Recompile)检查阶段,SQL Server首先检查Query Store中是否有Plan可以用于当前查询,如果存在一个forced plan,并且不同于过程缓存(Procedure Cache)中的计划,那么该查询被重编译(recompile)。
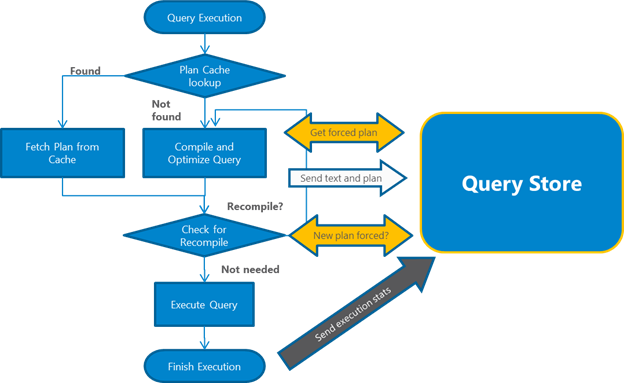
4,捕获数据的持久化过程
为了最小化IO消耗,Query Store新捕获的数据会先暂存到内存中。写操作会排队,之后数据会被刷新到硬盘中。
对于Query和Plan 信息,Query Store以最小的时延写入到硬盘;对于runtime stats,Query Store首先在内存中保留一定的时间,该时间由DATA_FLUSH_INTERVAL_SECONDS 确定,然后把收集的多个数据一起写入到硬盘中。
三,Query Store 界面化查询
在启用Query Store之后,刷新SSMS的Object Explorer面板,用户会发现,SSMS新增加了一个Query Store的目录,这是SSMS为了方便用户查询数据而内置的查询界面:

以回归查询(Regressed Queries)来举例,Regressed Queries面板显示的是查询和相应的Plan,从Metric列表中选择需要显示的度量,就可以查看不同的界面:

四,Query Store相关的视图
如果不满足于查询界面提供的数据,也可以编写TSQL代码来查看Query Store追踪的数据。跟Query Store相关的视图分为四类:Query、Plan、Runtime Stats和Wait Stats。注意,Wait Stats 是从SQL Server 2017(14.x)开始支持的。
1,关于Query的信息
query的唯一标识字段是query_id
select q.query_id
,t.query_text_id
,t.query_sql_text
,q.object_id as parent_object
,q.is_internal_query
,q.query_parameterization_type
,q.query_parameterization_type_desc
,q.count_compiles
,q.avg_compile_duration
,q.avg_bind_cpu_time
,q.avg_bind_duration
,q.avg_compile_memory_kb
,q.avg_optimize_cpu_time
,q.avg_optimize_duration
from sys.query_store_query as q
inner join sys.query_store_query_text as t
on q.query_text_id = t.query_text_id ;
2,关于Plan的信息
plan关联的query,可以通过字段query_id来关联
select p.plan_id
,p.query_id
,t.query_sql_text
,p.query_plan
,p.is_parallel_plan
,p.is_forced_plan
,p.force_failure_count
,p.last_force_failure_reason
,p.last_force_failure_reason_desc
,p.count_compiles
,p.avg_compile_duration
from sys.query_store_plan p
inner join sys.query_store_query q
on p.query_id=q.query_id
inner join sys.query_store_query_text t
on q.query_text_id=t.query_text_id
3,关于Plan 的 Runtime 统计
runtime stats通过plan_id 关联到特定的query
select r.runtime_stats_id
,r.plan_id
,r.runtime_stats_interval_id
,i.start_time as interval_start_time
,i.end_time as interval_end_time
,r.execution_type
,r.execution_type_desc
,r.count_executions
,r.avg_duration
,r.avg_cpu_time
,r.avg_dop
,r.avg_logical_io_reads
,r.avg_logical_io_writes
,r.avg_physical_io_reads
,r.avg_query_max_used_memory
,r.avg_rowcount
from sys.query_store_runtime_stats r
inner join sys.query_store_runtime_stats_interval i
on r.runtime_stats_interval_id=i.runtime_stats_interval_id
4,关于等待的统计信息
该视图统计的等待是跟单个执行计划有关的
select w.wait_stats_id
,w.plan_id
,w.runtime_stats_interval_id
,w.wait_category
,w.wait_category_desc
,w.execution_type
,w.execution_type_desc
,w.avg_query_wait_time_ms
,w.min_query_wait_time_ms
,w.max_query_wait_time_ms
from sys.query_store_wait_stats w
inner join sys.query_store_plan p
on w.plan_id=p.plan_id
参考文档:
Monitoring performance by using the Query Store
Query Store Catalog Views (Transact-SQL)
使用Query Store监控性能的更多相关文章
- SQL Server 2016新特性:Query Store
使用Query Store监控性能 SQL Server Query Store特性可以让你看到查询计划选择和性能.简化了性能调优,可以快速的发现因为查询计划的选择导致的性能的差别.Query Sto ...
- Azure SQL Database (26) 使用Query Store对Azure SQL Database监控
<Windows Azure Platform 系列文章目录> 我们在使用Azure SQL Database的时候,需要对数据库的性能进行监控,这时候就可以有两种方法: 1.第一种方法, ...
- sql server 2016新特性 查询存储(Query Store)的性能影响
前段时间给客户处理性能问题,遇到一个新问题, 客户的架构用的是 alwayson ,并且硬件用的是4路96核心,内存1T ,全固态闪存盘,sql server 2016 . 问题 描述 客户经常出现 ...
- SQL Server ->> SQL Server 2016新特性之 --- Query Store
前言 SQL Server 2016引入新的查询语句性能监控.调试和优化工具/功能 -- Query Store.以前我们发现一条查询语句性能突然下降,我们要去找出问题的所在往往需要通过调用一些DMV ...
- Linux下通过server-status监控性能
Linux下通过server-status监控性能 前提:安装好Apache,在opt/路径下 查看Apache的工作模式 可以知道是 prefork.c模式 配置server-status 性能 进 ...
- 文件监控性能问题【BUG】
文件监控性能问题[BUG] 背景:JAVA写了一个文件夹目录监控的程序,使用的是org.apache.commons.io.monitor 包,项目稳定运行了一个月,现场反馈,文件夹数据处理越来越慢, ...
- Linux中常用的监控性能的命令(sar、mpstat,vmstat, iostat,)详解
Linux中常用的监控性能的命令有: sar:能查看CPU的平均信息,还能查看指定CPU的信息.与mpstat相比,sar能查看CPU历史信息 mpstat:能查看所有CPU的平均信息,还能查看指定C ...
- ElasticStack系列之十五 & query cache 引起性能问题思考
问题描述 一个线上集群,执行的 Query DSL 都是一样的,只是参数不同.统计数据显示 98% ~ 99% 的查询相应速度都很快,只需要 4 ~ 6ms,但是有 1% 左右的查询响应时间在 100 ...
- java-JProfiler(五)-监控性能
原文地址:http://blog.csdn.net/chendc201/article/details/22897999 一.基础认识 1. 在Live Memory视图里右击相关类,选中Mark C ...
随机推荐
- 基于Groovy搭建Ngrinder脚本调试环境
介绍 最近公司搭建了一套压力测试平台,引用的是开源的项目 Ngrinder,做了二次开发,在脚本管理方面,去掉官方的SVN,引用的是Git,其他就是做了熔断处理等. 对技术一向充满热情的我,必须先来拥 ...
- django-模板之过滤器Add(十三)
1.add 若前后类型不匹配,就返回空. 其他的一些过滤器: first:返回列表的第一个值: last:返回列表的最后一个值: length:返回变量值的长度: linebrakebr:将纯文本中的 ...
- zookeeper+springboot+dubbo简单实现
第一步:在虚拟机中搭建zookeeper. 第二步:本地创建3个maven工程,分别为wxh-dubbo-api(对外暴露的接口),wxh-dubbo-provider(服务提供者,接口的具体实现), ...
- NodeJs 实现 WebSocket 即时通讯(版本一)
服务端代码 var ws = require("nodejs-websocket"); console.log("开始建立连接...") var game1 = ...
- 微信授权就是这个原理,Spring Cloud OAuth2 授权码模式
上一篇文章Spring Cloud OAuth2 实现单点登录介绍了使用 password 模式进行身份认证和单点登录.本篇介绍 Spring Cloud OAuth2 的另外一种授权模式-授权码模式 ...
- webPack 4.0的零基础学习
webPack 也更新到了4.0阶段,今天看了一下官网,总结一下,零基础的学习路径吧. (1)首先需要下载 webPake和webpack cli npm install webpack webpac ...
- python-nmap使用及案例
nmap概念及功能 概念 NMap,也就是Network Mapper,最早是Linux下的网络扫描和嗅探工具包. nmap是一个网络连接端扫描软件,用来扫描网上电脑开放的网络连接端.确定哪些服务运行 ...
- 【原创】go语言学习(二十一)Select和线程安全
目录 select语义介绍和使用 线程安全介绍 互斥锁介绍和实战 读写锁介绍和实战 原子操作介绍 select语义介绍和使用 1.多channel场景 A. 多个channel同时需要读取或写入,怎么 ...
- 0818NOIP模拟测试25——B卷简记
幸亏考场上没考这个,T1结论T2不会T3板子.估计会死的更惨 T1是学长讲过的Cat变式,沿直线y=x+1翻折方案数相减,现推,15分钟弄出来没什么问题. 只要不要把m,n读反就行. T3是个tarj ...
- 「考试」weight
正解是树剖. 首先Kru求最小生成树. 然后分别考虑树边和非树边的答案. 首先是非树边,非树边链接的两个点在MST上能够构成一条链. 这条链上最大的那条边-1就是这条边的答案. 为什么. 模拟Kru的 ...