关于MySql 数据库InnoDB存储引擎介绍
熟悉MySQL的人,都知道InnoDB存储引擎,如大家所知,Redo Log是innodb的核心事务日志之一,innodb写入Redo Log后就会提交事务,而非写入到Datafile。之后innodb再异步地将新事务的数据异步地写入Datafile,真正存储起来。
那么innodb引擎有了redo log和buffer pool以后,为什么能够在提升性能的同时,还能保证不丢数据呢? Buffer Pool, Redo Log以及Datafile之间的具体关系是什么呢。
另外Innodb还有一大堆概念,Dirty Page, LRU, LSN,Checkpoint等等,这些概念在Innodb里是什么运作的呢?
下面通过一张图来告诉大家
Buffer Pool, Redo Log以及Datafile的关系
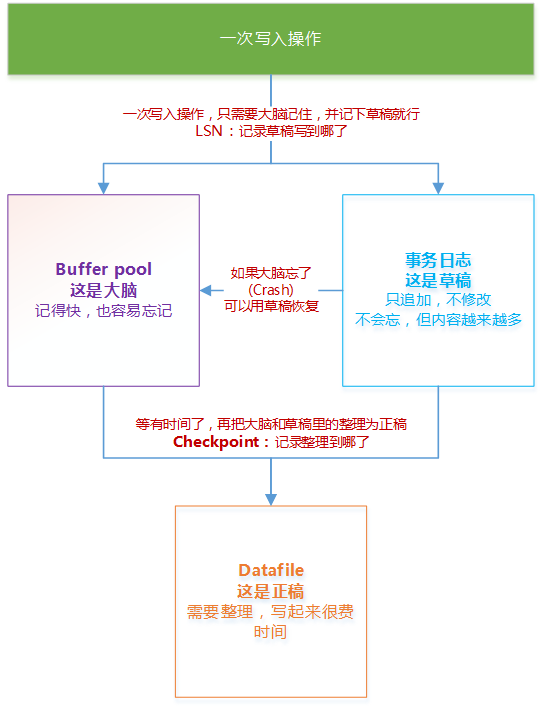 Innodb的原理
Innodb的原理
大家可以把innodb的事务写入过程看成写作一篇文章的过程。Innodb的写入过程其实和我们写作的过程是非常类似的。
试想,领导让我们写一篇文章,发表在论坛上。然后我们想到了一个绝佳的点子,并决定要放到文章里,可是手上还有其他事情,一时半会儿写不完,又担心过后忘了,领导还等着我们答复,此时我们会怎么做呢?我们一定会先大概构思个提纲,并把提纲和一些关键细节记录到本子上,作为草稿,然后立刻告诉领导自己要写什么东西,让其确认。最后等晚上有时间了,再根据草稿去斟词酌句,编写正稿。
在这个过程中,我们用到的几个关键的东西:
我们的大脑,用来临时暂时记住我们的点子
草稿,我们需要草稿来保证不会把点子和关键的细节给忘了
正稿,这是我们最终要输出的东西
有了这几个东西,我们不仅能确保我们不会错过一篇漂亮的文章,还能快速告诉领导自己一定可以搞定这件事情。
Innodb实际上也用到了这几个关键的东西:
Buffer Pool:就是我们的大脑
事务日志:就是我们的草稿
Datafile:就是我们的正稿
只要按照之前写文章的过程,来进行整个事务的写入操作,不仅能保证不丢失数据,而且能够快速响应。
一次写入操作是一次事务,innodb首先把事务数据写入到Buffer Pool和事务日志中,也就是在大脑中记忆下来,并写下草稿。然后就可以提交事务,响应客户端了。之后innodb在“有时间的时候”,异步地把这次写入的数据从Buffer Pool,或者事务日志中正式地写入到Datafile中,形成“正稿”。
其中,innodb为了保证事务日志这个“草稿”一定能无损地还原成正稿,还不能占用太多空间,事务日志需要有以下特点:
事务日志中一定保存了要写入的所有数据内容
事务日志只会把新事务追加在日志最后,而不会去修改之前的内容
一旦事务数据被写到datafile,事务日志中的“草稿”就可以删除了
通过上面3个特点我们可以看出,在形成“正稿”之前,“草稿”是不会被删除的;同时,“草稿”的空间是可以被循环利用的;最后,只要“草稿”在,我们一定能写出“正稿”。
这里还需要说明的,是Recovery流程。也就是如果在形成“正稿”前,数据库Crash了,我们需要重启整个进程,服务器,甚至只能把数据复制到另外一台服务器来进行恢复。这个时候,事务日志这个“草稿”就发挥了它最大的作用——数据恢复。这也和我们在工作生活中常出现的问题——把事情忘了——非常类似。
Buffer Pool本质就是存储于内存中的一个数据结构,内存和人的大脑一样,是“健忘”的。数据库Crash时,Buffer Pool中的数据极大可能“灰飞烟灭”了。因此,事务日志就如我们贴心的“记事本”,它把我们的记忆,保存为“草稿”,当我们忘了的时候,就可以翻开,把记忆重新回想起来。

LSN和Checkpoint
上面介绍了一次写入事务的情况,而数据库在使用过程中,事务都是连续不断,根据上面所述innodb逻辑,写“草稿”和写“正稿”速度和进度绝大部分情况下是不一样的。
再继续上面“写作文章”例子,如果我们的文章很长,一天写不完,而白天都有其他工作,我们只能记录草稿,只有晚上回去才能继续写正稿。那么我们就面临一个问题:我们昨天写到哪了。
最常见的办法就是,每天晚上去对照一下草稿的内容和正稿的内容,以此来判断写到哪了,但这比较花时间,因为正稿中可能包含了很多华丽的语句,我们需要思考一下才能对比上内容。
另外一个更简单的办法,就是每天晚上写完正稿后,我们在草稿上做个标记,标记下最后一条被写为正稿的内容,这样第二天晚上,我们就可以从这个标记的后面一条开始,继续写我们的正稿,而不需要去对比内容。
显然第二个方法效率更高,而且没有什么额外的风险。因此innodb就使用了这个办法。LSN是草稿上每一条记录的编号,我们每天晚上标记下最后一条写到正稿的记录编号,这个标记的编号,就是Checkpoint。Innodb根据这个checkpoint,就可以很快知道上次回放到哪里,同时也可以把这个编号之前的草稿,全部删掉了。
转载原文:http://www.360doc.com/content/18/0523/10/45882429_756316759.shtml
关于MySql 数据库InnoDB存储引擎介绍的更多相关文章
- MySQL数据库InnoDB存储引擎中的锁机制
MySQL数据库InnoDB存储引擎中的锁机制 http://www.uml.org.cn/sjjm/201205302.asp 00 – 基本概念 当并发事务同时访问一个资源的时候,有可能 ...
- MySQL数据库InnoDB存储引擎多版本控制(MVCC)实现原理分析
文/何登成 导读: 来自网易研究院的MySQL内核技术研究人何登成,把MySQL数据库InnoDB存储引擎的多版本控制(简称:MVCC)实现原理,做了深入的研究与详细的文字图表分析,方便大家理解I ...
- MySQL数据库InnoDB存储引擎
MySQL数据库InnoDB存储引擎Log漫游 http://blog.163.com/zihuan_xuan/blog/static/1287942432012366293667/
- mysql之innodb存储引擎介绍
一.Innodb体系架构 1.1.后台线程 后台任务主要负责刷新内存中的数据,保证缓冲池的数据是最近的数据,此外还将修改的数据刷新到文件磁盘,保证在数据库发生异常的情况下Innodb能恢复到正常的运行 ...
- MySQL数据库InnoDB存储引擎中的锁机制(转载)
http://www.uml.org.cn/sjjm/201205302.asp 00 – 基本概念 当并发事务同时访问一个资源的时候,有可能导致数据不一致.因此需要一种致机制来将访问顺序化. 锁就是 ...
- InnoDB存储引擎介绍-(2)redo和undo学习
01 – Undo LogUndo Log 是为了实现事务的原子性,在MySQL数据库InnoDB存储引擎中,还用Undo Log来实现多版本并发控制(简称:MVCC). - 事务的原子性(Atomi ...
- 1009MySQL数据库InnoDB存储引擎Log漫游
00 – Undo Log Undo Log 是为了实现事务的原子性,在MySQL数据库InnoDB存储引擎中,还用Undo Log来实现多版本并发控制(简称:MVCC). - 事务的原子性(Atom ...
- 0728MySQL数据库InnoDB存储引擎重做日志漫游REDOLOG,UNDOLOG
转自http://www.mysqlops.com/2012/04/06/innodb-log1.html 00 – Undo LogUndo Log 是为了实现事务的原子性,在MySQL数据库Inn ...
- MySQL数据库MyISAM存储引擎转为Innodb
MySQL数据库MyISAM存储引擎转为Innodb 之前公司的数据库存储引擎全部为MyISAM,数据量和访问量都不是很大,所以一直都没什么问题.但是最近出现了MySQL数据表经常被锁的情况,直接导 ...
随机推荐
- python:json.decoder.JSONDecodeError: Expecting property name enclosed in double quotes问题解决
有如下一个文件,内容如下 { "test1": "/root/test/test1.template", "test2": "/r ...
- 常见问题解决办法=》.net后台
1:后台返回前端长度过大的问题 除了在web.config中设置最大值外还可以修改返回值 [web.config中配置最大值有时候无效,直接修改返回值效果会好一些] List<User> ...
- 在WPF中开启摄像头扫描二维码(Media+Zxing)
近两天项目中需要添加一个功能,是根据摄像头来读取二维码信息,然后根据读出来的信息来和数据库中进行对比显示数据. 选择技术Zxing.WPFMediaKit.基本的原理就是让WPFmediaKit来对摄 ...
- .net(C#数据库访问) Mysql,Sql server,Sqlite,Access四种数据库的连接方式
便签记录Mysql,Sql server,Sqlite,Access四种数据库的简单连接方式 //using MySql.Data.MySqlClient; #region 执行简单SQL语句,使用M ...
- 医院信息集成平台(ESB)数据集成建设方案
一.数据资产目录建设 依据卫生部信息化工作领导小组办公室卫生部统计信息中心2011年3月发布的<基于电子病历的医院信息平台建设技术解决方案——业务部分>. 临床服务域 包含12个二级类目: ...
- Android.mk语法说明
版权申明: 本文原创首发于以下网站,您可以自由转载,但必须加入完整的版权声明 博客园:https://www.cnblogs.com/MogooStudio/ csdn博客:https://blog. ...
- dataguard ORA-12514: TNS:listener does not currently know of service requested in connect descriptor
错误的意思是listener 不知道连接解析器中的请求服务,这里要说静态监听和动态监听了动态注册是在instance启动的时候PMON进程根据init.ora中的instance_name,servi ...
- 阅读webpack代码笔记:antd-layout的webpack.config.prod.js
'use strict'; const autoprefixer = require('autoprefixer');//自动补全css前缀 const path = require('path'); ...
- 网络爬虫引发的问题及robots协议
一.网络爬虫的尺寸 1.以爬取网页,玩转网页为目的进行小规模,数据量小对爬取速度不敏感的可以使用request库实现功能(占90%) 2.以爬取网站或爬取系列网站为目的,比如说获取一个或多个旅游网站的 ...
- IT兄弟连 HTML5教程 CSS3属性特效 渐变2 线性渐变实例
3 线性渐变实例 一.颜色从顶部向底部渐变 制作从顶部到底部直线渐变有三种方法,第一种是起点参数不设置,因为起点参数的默认值为“top”:第二种方法起点参数设置为“top”:第三种起点参数使用“-90 ...