phper使用MySQL 针对千万级的大表要怎么优化?
有需要学习交流的友人请加入交流群的咱们一起,群内都是1-7年的开发者,希望可以一起交流,探讨PHP,swoole这块的技术 或者有其他问题 也可以问,获取swoole或者php进阶相关资料私聊管理即可
首先采用Mysql存储千亿级的数据,确实是一项非常大的挑战。Mysql单表确实可以存储10亿级的数据,只是这个时候性能非常差,项目中大量的实验证明,Mysql单表容量在500万左右,性能处于最佳状态。
针对大表的优化,主要是通过数据库分库分表来解决,目前比较普遍的方案有三个:分区,分库分表,NoSql/NewSql。实际项目中,这三种方案是结合的,目前绝大部分系统的核心数据都是以RDBMS存储为主,NoSql/NewSql存储为辅。
分区
首先来了解一下分区方案。
分区表是由多个相关的底层表实现的。这些底层表也是由句柄对象表示,所以我们也可以直接访问各个分区,存储引擎管理分区的各个底层表和管理普通表一样(所有的底层表都必须使用相同的存储引擎),分区表的索引只是在各个底层表上各自加上一个相同的索引。这个方案对用户屏蔽了sharding的细节,即使查询条件没有sharding column,它也能正常工作(只是这时候性能一般)。
不过它的缺点很明显:很多的资源都受到单机的限制,例如连接数,网络吞吐等。如何进行分区,在实际应用中是一个非常关键的要素之一。
下面开始举例:以客户信息为例,客户数据量5000万加,项目背景要求保存客户的银行卡绑定关系,客户的证件绑定关系,以及客户绑定的业务信息。
此业务背景下,该如何设计数据库呢。项目一期的时候,我们建立了一张客户业务绑定关系表,里面冗余了每一位客户绑定的业务信息。
基本结构大致如下:
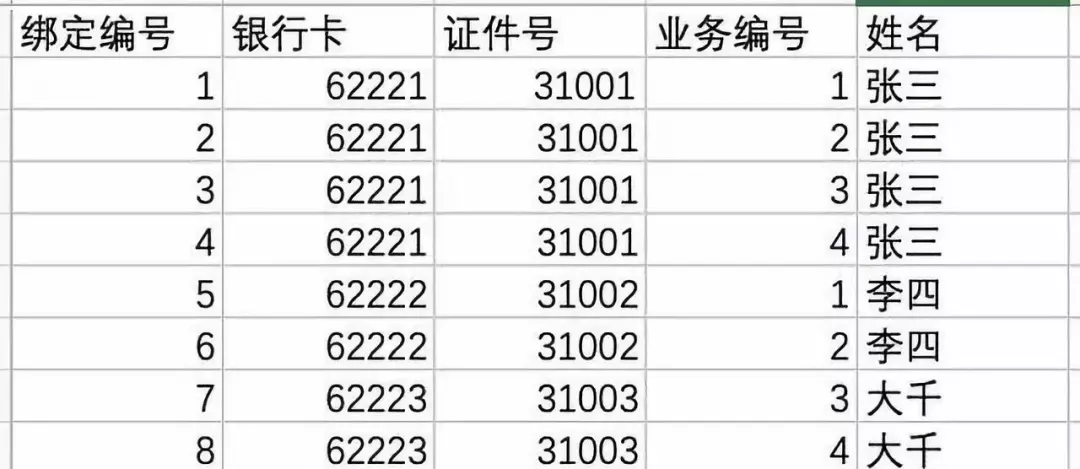
查询时,对银行卡做索引,业务编号做索引,证件号做索引。随着需求大增多,这张表的索引会达到10个以上。而且客户解约再签约,里面会保存两条数据,只是绑定的状态不同。
假设我们有5千万的客户,5个业务类型,每位客户平均2张卡,那么这张表的数据量将会达到惊人的5亿,事实上我们系统用户量还没有过百万时就已经不行了。这样的设计绝对是不行的,无论是插入,还是查询,都会让系统崩溃。
mysql数据库中的数据是以文件的形势存在磁盘上的,默认放在/mysql/data下面(可以通过my.cnf中的datadir来查看), 一张表主要对应着三个文件,一个是frm存放表结构的,一个是myd存放表数据的,一个是myi存表索引的。这三个文件都非常的庞大,尤其是.myd文件,快5个G了。下面进行第一次分区优化,Mysql支持的分区方式有四种:
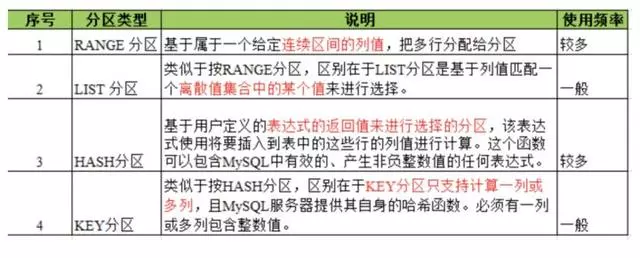
在我们的项目中,range分区和list分区没有使用场景,如果基于绑定编号做range或者list分区,绑定编号没有实际的业务含义,无法通过它进行查询,因此,我们就剩下 HASH 分区和 KEY 分区了,HASH分区仅支持int类型列的分区,且是其中的一列。
KEY 分区倒是可以支持多列,但也要求其中的一列必须是int类型;看我们的库表结构,发现没有哪一列是int类型的,如何做分区呢?增加一列,绑定时间列,将此列设置为int类型,然后按照绑定时间进行分区,将每一天绑定的用户分到同一个区里面去。
这次优化之后,我们的插入快了许多,但是查询依然很慢,为什么?
因为在做查询的时候,我们也只是根据银行卡或者证件号进行查询,并没有根据时间查询,相当于每次查询,mysql都会将所有的分区表查询一遍。
进行第二次方案优化,既然 HASH 分区和 KEY分区要求其中的一列必须是int类型的,那么创造出一个int类型的列出来分区是否可以?
分析发现,银行卡的那串数字有秘密。银行卡一般是16位到19位不等的数字串,我们取其中的某一位拿出来作为表分区是否可行呢,通过分析发现,在这串数字中,其中确实有一位是0到9随机生成的,我们基于银行卡号+随机位进行KEY分区,每次查询的时候,通过计算截取出这位随机位数字,再加上卡号,联合查询,达到了分区查询的目的,需要说明的是,分区后,建立的索引,也必须是分区列,否则Mysql还是会在所有的分区表中查询数据。
通过银行卡号查询绑定关系的问题解决了,那么证件号呢,如何通过证件号来查询绑定关系。
前面已经讲过,做索引一定是要在分区健上进行,否则会引起全表扫描。我们再创建了一张新表,保存客户的证件号绑定关系,每位客户的证件号都是唯一的,新的证件号绑定关系表里,证件号作为了主键,那么如何来计算这个分区健呢,客户的证件信息比较庞杂,有身份证号,港澳台通行证,机动车驾驶证等等,如何在无序的证件号里找到分区健。
为了解决这个问题,我们将证件号绑定关系表一分为二,其中的一张表专用于保存身份证类型的证件号,另一张表则保存其他证件类型的证件号,在身份证类型的证件绑定关系表中,我们将身份证号中的月数拆分出来作为了分区健,将同一个月出生的客户证件号保存在同一个区,这样分成了12个区,其他证件类型的证件号,数据量不超过10万,就没有必要进行分区了。
这样每次查询时,首先通过证件类型确定要去查询哪张表,再计算分区健进行查询。作了分区设计之后,保存2000万用户数据时银行卡表的数据保存文件就分成了10个小文件,证件表的数据保存文件分成了12个小文件,解决了这两个查询的问题,还剩下一个问题:业务编号怎么办?一个客户有多个签约业务,如何进行保存?这时候,采用分区的方案就不太合适了,它需要用到分表的方案。
分表
我们前面有提到过对于mysql,其数据文件是以文件形式存储在磁盘上的。当一个数据文件过大时,操作系统对大文件的操作就会比较麻烦耗时,且有的操作系统就不支持大文件,这个时候就必须分表了。
另外对于mysql常用的存储引擎是Innodb,它的底层数据结构是B+树。当其数据文件过大的时候,查询一个节点可能会查询很多层次,而这必定会导致多次IO操作进行装载进内存,肯定会耗时的。
除此之外还有Innodb对于B+树的锁机制。对每个节点进行加锁,那么当更改表结构的时候,这时候就会树进行加锁,当表文件大的时候,这可以认为是不可实现的。所以综上我们就必须进行分表与分库的操作。
如何进行分库分表,目前互联网上有许多的版本,比较知名的一些方案:阿里的TDDL,DRDS和cobar,京东金融的sharding-jdbc;民间组织的MyCAT;360的Atlas;美团的zebra;其他比如网易,58,京东等公司都有自研的中间件。
这么多的分库分表中间件方案归总起来,就两类:client模式和proxy模式。
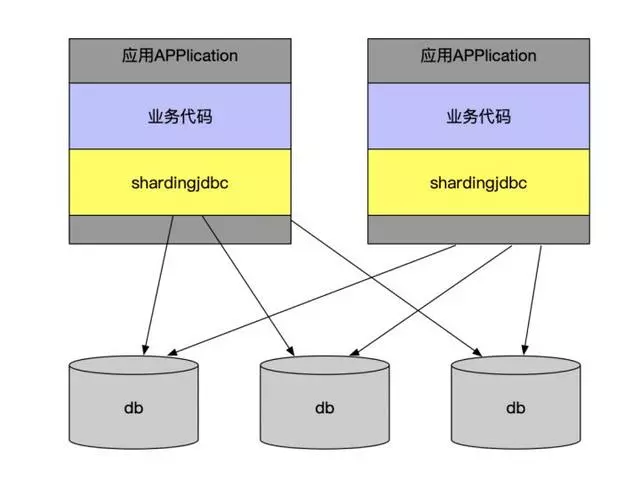
client模式

proxy模式
无论是client模式,还是proxy模式。几个核心的步骤是一样的:SQL解析,重写,路由,执行,结果归并。个人比较倾向于采用client模式,它架构简单,性能损耗也比较小,运维成本低。
如何对业务类型进行分库分表。分库分表最重要的一步,即sharding column的选取,sharding column选择的好坏将直接决定整个分库分表方案最终是否成功。而sharding column的选取跟业务强相关。
在我们的项目场景中,sharding column无疑最好的选择是业务编号。通过业务编号,将客户不同的绑定签约业务保存到不同的表里面去,根据业务编号路由到相应的表中进行查询,达到进一步优化sql的目的。
phper使用MySQL 针对千万级的大表要怎么优化?的更多相关文章
- MySQL 对于千万级的大表要怎么优化?
作者:哈哈链接:https://www.zhihu.com/question/19719997/answer/81930332来源:知乎著作权归作者所有,转载请联系作者获得授权. 第一优化你的sql和 ...
- MySQL 对于千万级的大表要怎么优化
转自知乎 作者:哈哈链接:http://www.zhihu.com/question/19719997/answer/81930332来源:知乎著作权归作者所有,转载请联系作者获得授权. 很多人第一反 ...
- 千万级的大表!MySQL这样优化更好
对于一个千万级的大表,现在可能更多的是亿级数据量,很多人第一反应是各种切分,可结果总是事半功倍,或许正是我们优化顺序的不正确.下面我们来谈谈怎样的优化顺序可以让效果更好. MySQL数据库一般都是按照 ...
- 记录一次MySQL两千万数据的大表优化解决过程,提供三种解决方案(转)
问题概述 使用阿里云rds for MySQL数据库(就是MySQL5.6版本),有个用户上网记录表6个月的数据量近2000万,保留最近一年的数据量达到4000万,查询速度极慢,日常卡死.严重影响业务 ...
- 转载:记录一次MySQL两千万数据的大表优化解决过程
地址:https://database.51cto.com/art/201902/592522.htm 虽然是广告文,但整体可读性尚可.
- mysql大表设计以及优化
MYSQL千万级数据量的优化方法积累https://m.toutiao.com/group/6583260372269007374/?iid=6583260372269007374 MySQL 千万级 ...
- Mysql千万级记录表分表策略
目前,比较流行的分表为2倍扩容. 表A(id, name, age, sex) 基于自增id分表, 通过触发器先同步A到B, 程序通过mod 2操作数据,然后drop掉触发器,在 删除两个A表的偶数i ...
- Mysql的行级锁与表级锁
在计算机科学中,锁是在执行多线程时用于强行限制资源访问的同步机制,即用于在并发控制中保证对互斥要求的满足. 在DBMS中,可以按照锁的粒度把数据库锁分为行级锁(INNODB引擎).表级锁(MYISAM ...
- Python批量删除mysql中千万级大量数据
场景描述 线上mysql数据库里面有张表保存有每天的统计结果,每天有1千多万条,这是我们意想不到的,统计结果咋有这么多.运维找过来,磁盘占了200G,最后问了运营,可以只保留最近3天的,前面的数据,只 ...
随机推荐
- Spring(Bean)3
bean的继承<!-- bean 的继承 作为模板来使用. 可以通过abstract="true"来指定把该bean配置为·抽象的. 通过abstract="tru ...
- swiper实现一个好看的轮播图
轮播是我们在编写页面中经常遇到的模块,所以网上也会有各种有有关轮播图的插件.今天忽然间看到了swiper上一个高颜值的轮播功能,顺便做一下分享. 首先页面在head内要先引用 swiper的css 和 ...
- flex布局实现瀑布流排版
网上有很多有关js(jq)实现瀑布流和有关瀑布流的插件很多,例如:插件(Masonry,Wookmark等等).按照正常的逻辑思维,瀑布流的排版(item列表)一般都是 由左到右,上而下排序的结果,单 ...
- 查看/设置JVM使用的垃圾收集器
一.设置垃圾收集器的参数 -XX:+UseSerialGC,虚拟机在Client模式下的默认值,Serial+Serial Old -XX:+UseParNewGC,ParNew+Serial Old ...
- ThinkPHP 实现数据库事务回滚示例代码
ThinkPHP提供了数据库的事务支持,如果要在应用逻辑中使用事务,可以参考下面的方法: 启动事务: $User->startTrans(); 提交事务: $User->commit( ...
- 《Windows内核安全与驱动开发》 3.2 内存与链表
<Windows内核安全与驱动开发>阅读笔记 -- 索引目录 <Windows内核安全与驱动开发> 3.2 内存与链表 1. 尝试生成一个链表头并将其初始化. 2. 尝试向内存 ...
- React - 组件:类组件
目录: 1. 类组件有自己的状态 2. 继承React.Component-会有生命周期和this 3. 内部需要一个render函数(类组件会默认调用render方法,但不会默认添加,需要手动填写r ...
- shell脚本编程基础--文本比较
1.概述 允许测试Linux文件系统上文件的目录和状态. 2.详解 2.1 检查目录 -d测试会检查指定的目录是否存在于系统中.当我们打算将文件写入目录或是准备切换到该目录时,先进行测试是比较好的做法 ...
- 机器学习笔记(九)---- 集成学习(ensemble learning)【华为云技术分享】
集成学习不是一种具体的算法,而是在机器学习中为了提升预测精度而采取的一种或多种策略.其原理是通过构建多个弱监督模型并使用一定策略得到一个更好更全面的强监督模型.集成学习简单的示例图如下: 通过训练得到 ...
- 在阿里云购买SSL证书,让网站支持HTTPS
SSL简介 引自:https://baike.baidu.com/item/ssl/320778?fr=aladdin SSL SSL(Secure Sockets Layer 安全套接层),及其继任 ...