redis系列之------字典
前言
字典, 又称符号表(symbol table)、关联数组(associative array)或者映射(map), 是一种用于保存键值对(key-value pair)的抽象数据结构。
在字典中, 一个键(key)可以和一个值(value)进行关联(或者说将键映射为值), 这些关联的键和值就被称为键值对。
字典中的每个键都是独一无二的, 程序可以在字典中根据键查找与之关联的值, 或者通过键来更新值, 又或者根据键来删除整个键值对, 等等。
字典经常作为一种数据结构内置在很多高级编程语言里面, 但 Redis 所使用的 C 语言并没有内置这种数据结构, 因此 Redis 构建了自己的字典实现。
字典在 Redis 中的应用相当广泛, 比如 Redis 的数据库就是使用字典来作为底层实现的, 对数据库的增、删、查、改操作也是构建在对字典的操作之上的。
因此,了解字典对我们了解Redis数据库有很大的帮助。同时可以跟Java的HashMap进行对比,看看孰好孰坏。
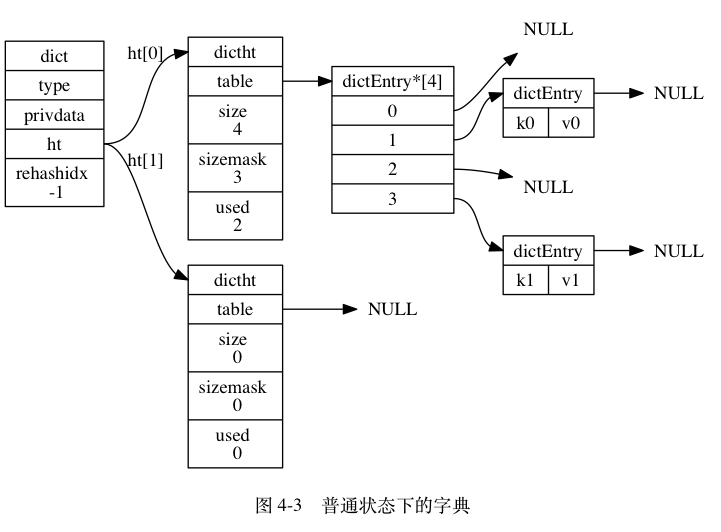
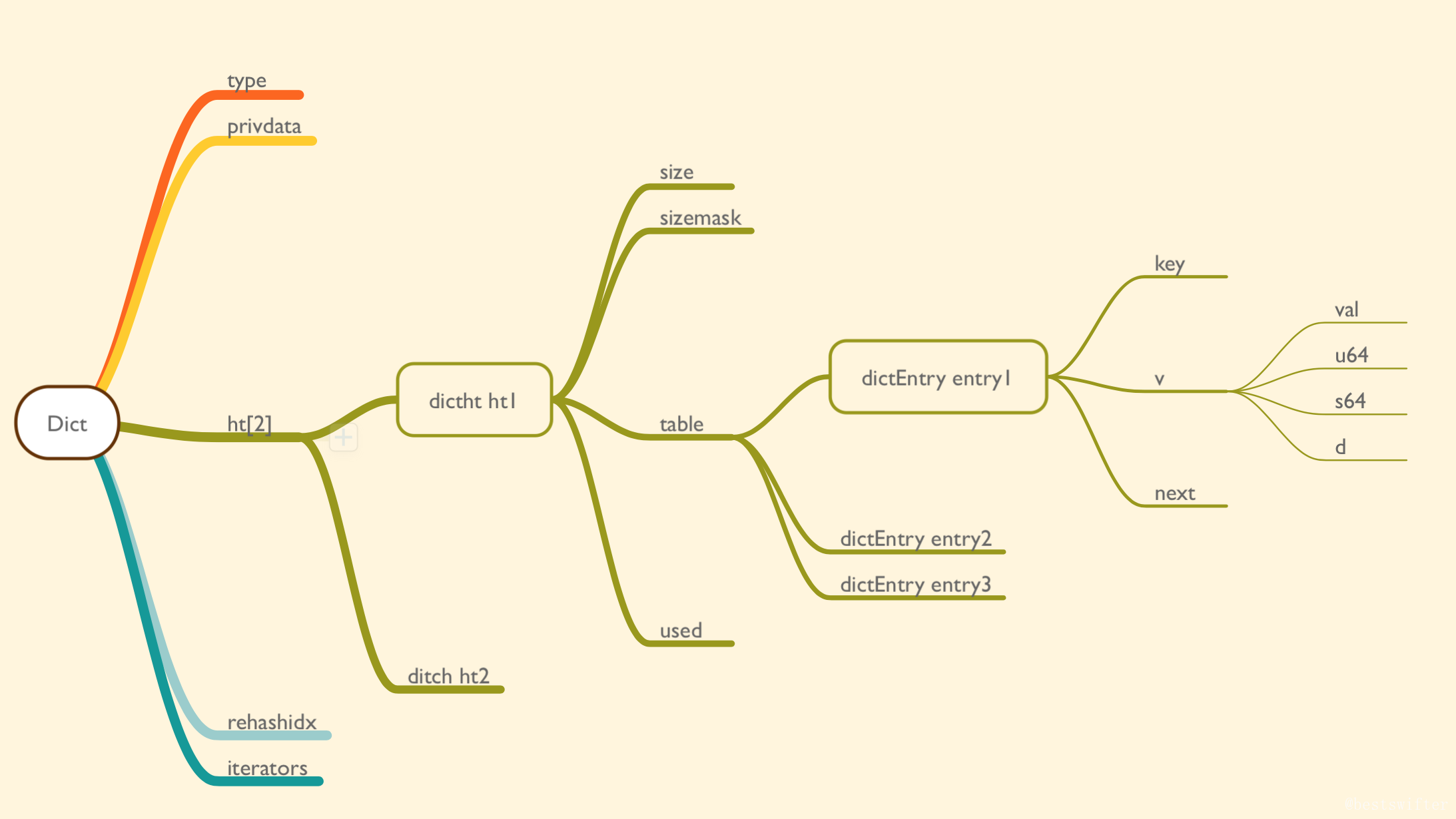
字典的定义
typedef struct dict {
// 类型特定函数
dictType *type;
// 私有数据
void *privdata;
// 哈希表
dictht ht[];
// rehash 索引
// 当 rehash 不在进行时,值为 -1
int rehashidx; /* rehashing not in progress if rehashidx == -1 */
} dict;
主要看ht,和rehashidx两个参数。
ht 属性是一个包含两个项的数组, 数组中的每个项都是一个 dictht 哈希表, 一般情况下, 字典只使用 ht[0] 哈希表, ht[1] 哈希表只会在对 ht[0] 哈希表进行 rehash 时使用。
除了 ht[1] 之外, 另一个和 rehash 有关的属性就是 rehashidx : 它记录了 rehash 目前的进度, 如果目前没有在进行 rehash , 那么它的值为 -1 。
typedef struct dictht {
// 哈希表数组
dictEntry **table;
// 哈希表大小
unsigned long size;
// 哈希表大小掩码,用于计算索引值
// 总是等于 size - 1
unsigned long sizemask;
// 该哈希表已有节点的数量
unsigned long used;
} dictht;
table 属性是一个数组, 数组中的每个元素都是一个指向 dict.h/dictEntry 结构的指针, 每个 dictEntry 结构保存着一个键值对。
size 属性记录了哈希表的大小, 也即是 table 数组的大小
sizemask 属性的值总是等于 size-1 , 这个属性和哈希值一起决定一个键应该被放到 table 数组的哪个索引上面。(不是很清楚,为什么要单独定义一个mask,而不直接size-1);
而 used 属性则记录了哈希表目前已有节点(键值对)的数量。
typedef struct dictEntry {
// 键
void *key;
// 值
union {
void *val;
uint64_t u64;
int64_t s64;
} v;
// 指向下个哈希表节点,形成链表
struct dictEntry *next;
} dictEntry;
key 属性保存着键值对中的键, 而 v 属性则保存着键值对中的值, 其中键值对的值可以是一个指针, 或者是一个 uint64_t 整数, 又或者是一个 int64_t 整数。
next 属性是指向另一个哈希表节点的指针, 这个指针可以将多个哈希值相同的键值对连接在一次, 以此来解决键冲突(collision)的问题。
可以明显的看出来,redis是通过链表来解决hash冲突的。
因此,redis的字典大概如下:
Rehash
随着操作的不断执行, 哈希表保存的键值对会逐渐地增多或者减少, 为了让哈希表的负载因子(load factor)维持在一个合理的范围之内, 当哈希表保存的键值对数量太多或者太少时, 程序需要对哈希表的大小进行相应的扩展或者收缩。
也就是我们常说的,扩容,再次hash。
Redis rehash过程:
- 为字典的
ht[1]哈希表分配空间。一般为原字典的两倍,即 ht[0] * 2; - 将保存在
ht[0]中的所有键值对 rehash 到ht[1]上面 - 当
ht[0]包含的所有键值对都迁移到了ht[1]之后 (ht[0]变为空表), 释放ht[0], 将ht[1]设置为ht[0], 并在ht[1]新创建一个空白哈希表, 为下一次 rehash 做准备。
但其实rehash是非常的耗时间的。假设ht[0]非常的大呢? 40W,400W,甚至4000W呢?
一次rehash甚至可能导致redis宕机,所以出现了渐进式hash。
渐进式Rehash
这个 rehash 动作并不是一次性、集中式地完成的, 而是分多次、渐进式地完成的。为了避免 rehash 对服务器性能造成影响, 服务器不是一次性将 ht[0] 里面的所有键值对全部 rehash 到 ht[1] , 而是分多次、渐进式地将 ht[0] 里面的键值对慢慢地 rehash 到 ht[1] 。
- 为
ht[1]分配空间, 让字典同时持有ht[0]和ht[1]两个哈希表。 - 在字典中维持一个索引计数器变量
rehashidx, 并将它的值设置为0, 表示 rehash 工作正式开始。 - 在 rehash 进行期间, 每次对字典执行添加、删除、查找或者更新操作时, 程序除了执行指定的操作以外, 还会顺带将
ht[0]哈希表在rehashidx索引上的所有键值对 rehash 到ht[1], 当 rehash 工作完成之后, 程序将rehashidx属性的值增一。 - 随着字典操作的不断执行, 最终在某个时间点上,
ht[0]的所有键值对都会被 rehash 至ht[1], 这时程序将rehashidx属性的值设为-1, 表示 rehash 操作已完成。
扩容代码大致如下:
int dictRehash(dict *d, int n) {
int empty_visits = n*; /* Max number of empty buckets to visit. */
// 判断是否正在扩容
if (!dictIsRehashing(d)) return ;
while(n-- && d->ht[].used != ) {
dictEntry *de, *nextde;
/* Note that rehashidx can't overflow as we are sure there are more
* elements because ht[0].used != 0 */
assert(d->ht[].size > (unsigned long)d->rehashidx);
// 找到一个不为空的桶,进行迁移
while(d->ht[0].table[d->rehashidx] == NULL) {
d->rehashidx++;
if (--empty_visits == ) return ;
}
// 找到这个桶第一个指针节点
de = d->ht[].table[d->rehashidx];
// 将这个桶中的所有的key节点转移到新的数组中。while循环链表
while(de) {
uint64_t h;
nextde = de->next;
/* Get the index in the new hash table */
h = dictHashKey(d, de->key) & d->ht[].sizemask;
de->next = d->ht[].table[h];
d->ht[].table[h] = de;
d->ht[].used--;
d->ht[].used++;
de = nextde;
}
// 旧的桶节点置为null,并且rehashidx+1
d->ht[].table[d->rehashidx] = NULL;
d->rehashidx++;
}
/* Check if we already rehashed the whole table... */
if (d->ht[].used == ) {
zfree(d->ht[].table);
d->ht[] = d->ht[];
_dictReset(&d->ht[]);
d->rehashidx = -;
return ;
}
/* More to rehash... */
return ;
}
在进行渐进式 rehash 的过程中, 字典会同时使用 ht[0] 和 ht[1] 两个哈希表, 所以在渐进式 rehash 进行期间, 字典的删除(delete)、查找(find)、更新(update)等操作会在两个哈希表上进行: 比如说, 要在字典里面查找一个键的话, 程序会先在 ht[0]里面进行查找, 如果没找到的话, 就会继续到 ht[1] 里面进行查找, 诸如此类。
另外, 在渐进式 rehash 执行期间, 新添加到字典的键值对一律会被保存到 ht[1] 里面, 而 ht[0] 则不再进行任何添加操作: 这一措施保证了 ht[0] 包含的键值对数量会只减不增, 并随着 rehash 操作的执行而最终变成空表。
所遇到问提
问题一:
要在字典里面查找一个键的话, 程序会先在 ht[0]里面进行查找, 如果没找到的话, 就会继续到 ht[1] 里面进行查找, 诸如此类。
这一点其实我比较有疑惑?为何要先去ht[0]中查找,找不到再去ht[1]中查找,这样岂不是效率低下,查找了两张表。不能根据hash值和rehashidx进行比较判断么?只查一张表不行么?
为此我翻阅了不少资料:
这是redis官方其他人的pull request:https://github.com/antirez/redis/pull/5692 暂时还没有merge
同时这是我和一位大佬的讨论:https://github.com/Junnplus/blog/issues/35 最终得出结论
还是看源码:(源码真是一个好东西)
for (table = ; table <= ; table++) {
// 找到key的index
idx = h & d->ht[table].sizemask;
// 拿到key值对应的value
he = d->ht[table].table[idx];
while(he) {
if (key==he->key || dictCompareKeys(d, key, he->key))
return he;
he = he->next;
}
if (!dictIsRehashing(d)) return NULL;
}
其实只有两种情况
- key在ht[0],还没有迁移
- key在ht[1],已经迁移了。
针对第一种情况,他在第一层的循环已经找到了key值,并且返回(第八行),不再继续后面操作,因此不存在效率问题。
第二种情况,看第五行,he此时为null,根本不会循环链表。然后第二次循环才能找到key。而第一次是做了一次hash,复杂度为O(1)。效率几乎是没有损失,因此也不存在效率问题。
综上:我得出的结论是。可以拿idx和rehashidx进行对比,同时也可以像redis这样写,不会损失效率。redis可能为了代码的简洁以及统一,不想写那么多的判断条件,因此没有比较idx和rehashidx。
当我认为提前结束会更好,毕竟不用后续判断了,也比较清楚。类似这个request:https://github.com/antirez/redis/pull/5692/files
问题二:
假如在redis准备进行rehash的时候,他需要为ht[1]申请一块内存,这块内存可是ht[0]的两倍哦,那次是计算机内存不存会如何?
梳理一下哈希表大小和内存申请大小的对应关系:
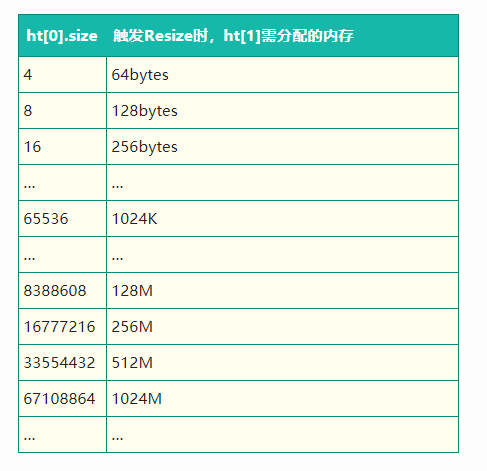
正常状态下,redis为ht[1]分配完内存后,会持续一段时间进行rehash。rehash完毕后,就会释放ht[0]内存了。类似如下图:
内存先上升,后下降。

但此时内存不存的话,Redis会进行大量的Key驱逐,也就是会淘汰掉很久未使用的key,跟LRU有点类似。
那么此时可能就会影响到了业务,这是非常大的问题呢。
那么针对在Redis满容驱逐状态下,如何避免因Rehash而导致Redis抖动的这种问题。
- 我们在Redis Rehash源码实现的逻辑上,加上了一个判断条件,如果现有的剩余内存不够触发Rehash操作所需申请的内存大小,即不进行Resize操作;
- 通过提前运营进行规避,比如容量预估时将Rehash占用的内存考虑在内,或者通过监控定时扩容。
参考文献:
《redis设计与实现》 http://redisbook.com/preview/dict/incremental_rehashing.html
《美团针对Redis Rehash机制的探索和实践》 https://tech.meituan.com/2018/07/27/redis-rehash-practice-optimization.html
《Redis源码分析》 https://github.com/Junnplus/blog/issues/35
redis系列之------字典的更多相关文章
- redis 系列6 数据结构之字典(下)
一.概述 接着上篇继续,这篇把数据结构之字典学习完, 这篇知识点包括:哈希算法,解决键冲突, rehash , 渐进式rehash,字典API. 1.1 哈希算法 当一个新的键值对 需要添加到字典里面 ...
- redis 系列5 数据结构之字典(上)
一. 概述 字典又称符号表(symbol table),关联数组(associative array), 映射(map),是一种用于保存键值对(key-value pair)的抽象数据结构.在字典中, ...
- Redis系列(1)之安装
Redis系列(1)之安装 由于项目的需要,最近需要研究下Redis.Redis是个很轻量级的NoSql内存数据库,它有多轻量级的呢,用C写的,源码只有3万行,空的数据库只占1M内存.它的功能很丰富, ...
- redis 系列14 有序集合对象
一. 有序集合概述 Redis 有序集合对象和集合对象一样也是string类型元素的集合,且不允许重复的成员.不同的是每个元素都会关联一个double类型的分数.redis正是通过分数来为集合中的成员 ...
- Python操作redis系列以 哈希(Hash)命令详解(四)
# -*- coding: utf-8 -*- import redis #这个redis不能用,请根据自己的需要修改 r =redis.Redis(host=") 1. Hset 命令用于 ...
- Redis 系列(04-2)Redis原理 - 内存回收
目录 Redis 系列(04-2)Redis原理 - 内存回收 Redis 系列目录 1. 过期策略 1.1 定时过期(主动淘汰) 1.2 惰性过期(被动淘汰) 1.3 定期过期 2. 淘汰策略 2. ...
- Redis 系列(02)数据结构
目录 Redis 系列(02)数据结构 Redis 系列目录 1. String 1.1 基本操作 1.2 数据结构 1.3 Redis数据存储结构 2. Hash 2.1 基本操作 2.2 数据结构 ...
- 【目录】redis 系列篇
随笔分类 - redis 系列篇 redis 系列27 Cluster高可用 (2) 摘要: 一. ASK错误 集群上篇最后讲到,对于重新分片由redis-trib负责执行,关于该工具以后再介绍.在进 ...
- Redis系列(五):Redis的过期键删除策略
本篇博客是Redis系列的第5篇,主要讲解下Redis的过期键删除策略. 本系列的前4篇可以点击以下链接查看: Redis系列(一):Redis简介及环境安装 Redis系列(二):Redis的5种数 ...
随机推荐
- js中的this介绍
今天跟大家一起简单的来了解一下js中一个有趣的东西,this. 在js中我们用面向对象的思想去编写的时候,各个模块之间的变量就不那么容易获取的到了,当然也可以通过闭包的方式拿到其他函数的变量,如果说每 ...
- jQuery - 03. each、prevaAll、nextAll、获取属性、修改属性attr/val/text()、jq.height/width、offset()./position()./scrol Left/Top 、事件绑定bind、delegate、on、事件解绑、事件对象、多库共存
each 方法 $ ( selector).each(function( index,element) { } ); 参数一表示当前元素在所有匹配元素中的索引号 参数二表示当前元素(DOM对象) ...
- 弄懂goroutine调度原理
goroutine简介 golang语言作者Rob Pike说,"Goroutine是一个与其他goroutines 并发运行在同一地址空间的Go函数或方法.一个运行的程序由一个或更多个go ...
- java中public,private,protected和default的区别
类中的数据成员和成员函数据具有的访问权限包括:public.private.protect.default(包访问权限) 作用域 当前类 同一package 子孙类 其他pac ...
- Python大佬告诉你:使用Python处理yaml格式的数据简单到爆
一.思考❓❔ 1.什么是yaml? 不是标记语言 对用户极其友好 数据序列化标准 跨语言 所有编程语言都支持 跨平台 所有平台都支持 Windows.linux.Mac 格式简单 比json小姐姐穿得 ...
- 【第九篇】uploadify上传文件
依然不多说,上代码 首先是给文件夹的位置 然后上代码 <div class="upload"> <div class="uploadswf"& ...
- 字节输入流InputStream
import java.io.File; import java.io.FileInputStream; import java.io.IOException; public class FileIn ...
- 你好,C语言
对于我来说,C语言就和陌生人一样,对他完全不了解,更不要提什么C++了,这就要我主动和他打招呼,深入认识了解它了哈.目前对于C语言的理解,只知道他的的功强大,能操作硬件,编写各类驱动,强悍的LINUX ...
- Android服务之混合方式开启服务
引言 前面介绍过了Android服务的两种开启方式:Start方式可以让服务在后台运行:bind方式能够调用到服务中的方法. 在实际的开发工作中,有很多需求是:既要在后台能够长期运行,又要在服务中操作 ...
- C# 反射基础用法
1.引用命名空间 using System.Reflection; 2.object[] parameters = { 参数 }; 调用方法的参数数组 3.Type t = Type.GetType( ...